【云原生&微服务四】SpringCloud之Ribbon和Erueka集成的细节全在这了(源码剖析)
文章目录
- 一、前言
- 二、Ribbon和Eureka
-
- 1、Ribbon如何与eureka整合,通过eureka client获取到对应的注册表?
-
- 1)为什么是DynamicServerListLoadBalancer的restOfInit()方法?
- 2)DynamicServerListLoadBalancer#restOfInit()
-
- 0> 初始化服务实例列表流程图
- 1> 初始化服务实例列表
- ServerList从哪来的?
- 2、 动态更新服务实例列表
-
- 1)流程图
- 2)流程解析
- 3、 如何根据负载均衡规则从`List`中选出一个Server?
-
- 1)轮询算法
- 4、如何发送网络HTTP请求?
-
- 1)流程图
- 2)流程解析
- 5、ping机制如何检查服务实例是否还存活?
-
- 1)哪里使用到了IPing的isAlive()方法?
- 三、总结 以及 后续文章
一、前言
在前面的文章,博主聊了Ribbon如何与SpringCloud、Eureka集成,Ribbon如何自定义负载均衡策略、Ribbon如何和SpringCloud集成:
- 【云原生&微服务一】SpringCloud之Ribbon实现负载均衡详细案例(集成Eureka、Ribbon)
- 【云原生&微服务二】SpringCloud之Ribbon自定义负载均衡策略(含Ribbon核心API)
- 【云原生&微服务三】SpringCloud之Ribbon是这样实现负载均衡的(源码剖析@LoadBalanced原理)
在【云原生&微服务三】SpringCloud之Ribbon是这样实现负载均衡的(源码剖析@LoadBalanced原理)一文中博主分析到了SpringCloud集成Ribbon如何获取到负载均衡器ILoadBalancer;本文我们接着分析如下问题:
- ZoneAwareLoadBalancer(属于ribbon)如何与eureka整合,通过eureka client获取到对应注册表?
- ZoneAwareLoadBalancer如何持续从Eureka中获取最新的注册表信息?
- 如何根据负载均衡器
ILoadBalancer从Eureka Client获取到的List中选出一个Server?- Ribbon如何发送网络HTTP请求?
- Ribbon如何用IPing机制动态检查服务实例是否存活?
PS: 文章中涉及到的SpringBoot相关知识点,比如自动装配,移步博主的SpringBoot专栏:Spring Boot系列。
PS2:Ribbon依赖Spring Cloud版本信息如下:
<dependencyManagement>
<dependencies>
<dependency>
<groupId>org.springframework.bootgroupId>
<artifactId>spring-boot-dependenciesartifactId>
<version>2.3.7.RELEASEversion>
<type>pomtype>
<scope>importscope>
dependency>
<dependency>
<groupId>org.springframework.cloudgroupId>
<artifactId>spring-cloud-dependenciesartifactId>
<version>Hoxton.SR8version>
<type>pomtype>
<scope>importscope>
dependency>
<dependency>
<groupId>com.alibaba.cloudgroupId>
<artifactId>spring-cloud-alibaba-dependenciesartifactId>
<version>2.2.5.RELEASEversion>
<type>pomtype>
<scope>importscope>
dependency>
dependencies>
dependencyManagement>
下面以请求http://localhost:9090/say/saint为入口进行debug。
二、Ribbon和Eureka
我们知道SpringCloud诞生之初,我们通常采用Eureka作为服务注册/发现中心、Ribbon作为负载均衡器,而Ribbon的诞生也正是因为要结合Eureka做负载均衡;而现在很多项目都是Nacos + OpenFeign的组合,不过OpenFeign的底层还是Ribbon,其很多便捷性体现在代理对象的封装,后续我们接着讨论。
1、Ribbon如何与eureka整合,通过eureka client获取到对应的注册表?
在博文:SpringCloud之Ribbon是这样实现负载均衡的(源码剖析@LoadBalanced原理)中我们知道了Ribbon默认的ILoadBalancer是ZoneAwareLoadBalancer;所以我们这里就看一下ZoneAwareLoadBalancer如何与eureka整合,通过eureka client获取到对应的注册表?
先看ZoneAwareLoadBalancer的类图:

ZoneAwareLoadBalancer的父类是DynamicServerListLoadBalancer,DynamicServerListLoadBalancer构造函数中会调用restOfInit()方法(其中会获取到所有的服务实例);
void restOfInit(IClientConfig clientConfig) {
boolean primeConnection = this.isEnablePrimingConnections();
// turn this off to avoid duplicated asynchronous priming done in BaseLoadBalancer.setServerList()
this.setEnablePrimingConnections(false);
// 感知新的服务实例的添加/移除,即动态维护服务实例列表
enableAndInitLearnNewServersFeature();
// 更新Eureka client 中所有服务的实例列表,即初始化服务实例列表
updateListOfServers();
if (primeConnection && this.getPrimeConnections() != null) {
this.getPrimeConnections()
.primeConnections(getReachableServers());
}
this.setEnablePrimingConnections(primeConnection);
LOGGER.info("DynamicServerListLoadBalancer for client {} initialized: {}", clientConfig.getClientName(), this.toString());
}
1)为什么是DynamicServerListLoadBalancer的restOfInit()方法?
第一次获取Eureka中服务实例列表的执行流程如下:

第一次从Ribbon的SpringClientFactory中获取GREETING-SERVICE服务对应的Spring子上下文时,获取不到,所以需要创建针对GREETING-SERVICE服务创建Spring子上下文;
最终进入到NamedContextFactory#createContext(String name)方法中,方法的最后会调用AnnotationConfigApplicationContext#refresh()方法,refresh()方法中会对ZoneAwareLoadBalancer进行初始化;又由于DynamicServerListLoadBalancer是ZoneAwareLoadBalancer的父类,所以初始化ZoneAwareLoadBalancer时也会执行DynamicServerListLoadBalancer的构造函数,进而会执行DynamicServerListLoadBalancer的restOfInit()方法;

2)DynamicServerListLoadBalancer#restOfInit()
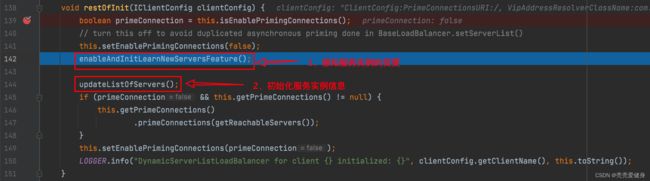
restOfInit()中主要做两件事:
- 启动一个定时任务,定时更新服务实例列表。
- 初始化服务实例列表
List,并感知服务实例信息的变更;
下面我们分开来看:
0> 初始化服务实例列表流程图

1> 初始化服务实例列表
updateListOfServers()方法负责初始化服务实例列表,代码执行流程如下:
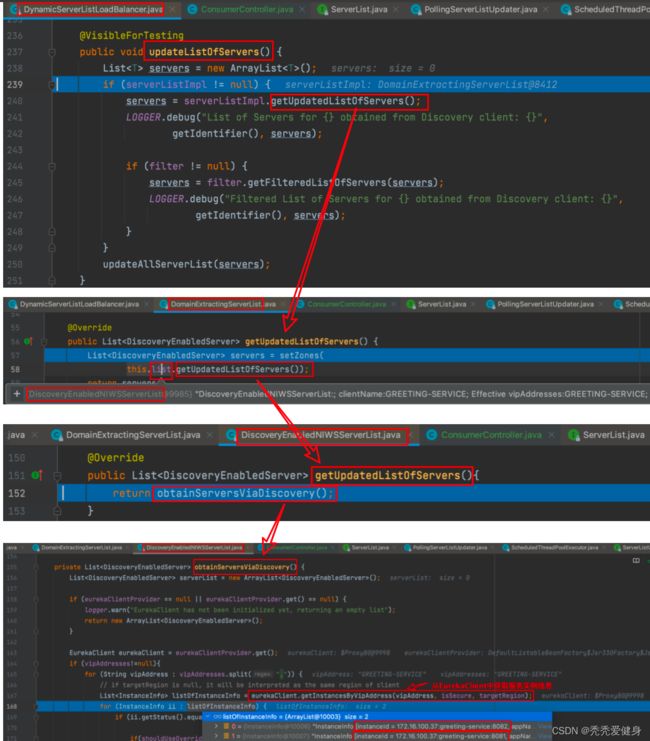
最终进入到DiscoveryEnabledNIWSServerList的obtainServersViaDiscovery()方法从Eureka Client本地缓存的服务注册表中获取到服务的全部实例信息;
我们debug过程中,知道了updateListOfServers()方法中涉及到的ServerList是,那么serverListImpl是从哪来的?

ServerList从哪来的?
serverListImpl是和Eureka相关的,我们去找eureka相关的jar包,最终找到spring-cloud-netflix-eureka-client jar包,其中有个org.springframework.cloud.netflix.ribbon.eureka目录,目录中有个EurekaRibbonClientConfiguration类:
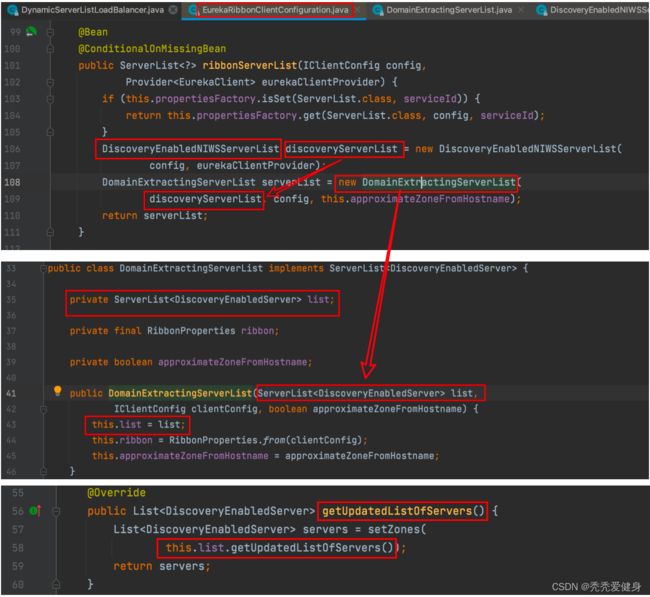
其中负责实例化ServerList为DomainExtractingServerList,然而我们调用DomainExtractingServerList的getUpdatedListOfServers()方法获取服务的所有实例时,实际是交给其组合的DiscoveryEnabledNIWSServerList类成员的getUpdatedListOfServers()方法去执行;
至此,我们知道了ZoneAwareLoadBalancer(属于ribbon)如何与eureka整合,通过eureka client获取到对应注册表?
- 其实就是从eureka client里去获取一下注册表,然后更新到LoadBalancer中去。
2、 动态更新服务实例列表
1)流程图
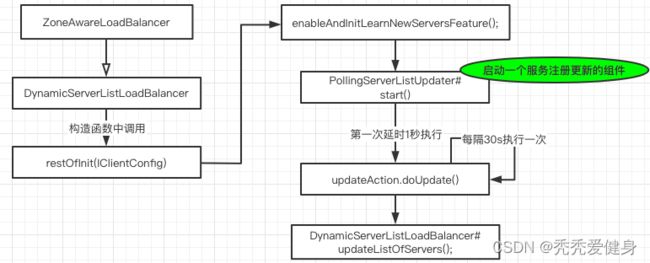
2)流程解析
enableAndInitLearnNewServersFeature()方法负责定时更新服务实例列表,代码执行逻辑如下:
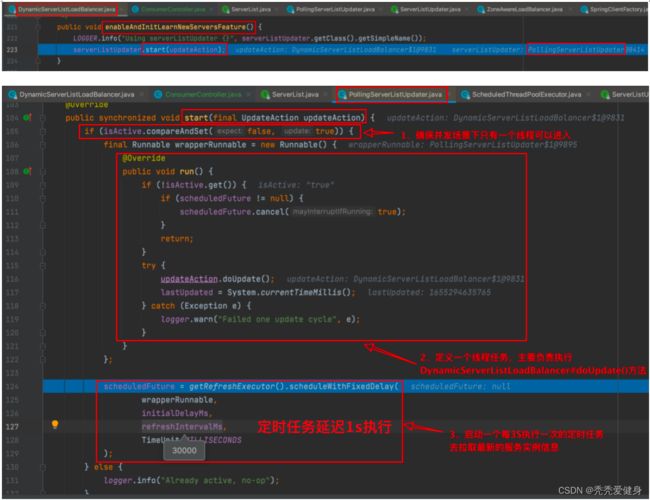
PollingServerListUpdater#start(UpdateAction)方法中会启动一个延迟1S并每间隔3S执行一次的定时任务去执行DynamicServerListLoadBalancer#doUpdate()方法去动态更新服务实例列表。
再看DynamicServerListLoadBalancer#doUpdate()方法:

方法内部其实就是调用初始化服务实例类别的那个方法:updateListOfServers(),也就是我们上面聊的。
至此,我们也就知道了ZoneAwareLoadBalancer如何持续从Eureka中获取最新的注册表信息?
3、 如何根据负载均衡规则从List中选出一个Server?
回到RibbonLoadBalancerClient#execute()方法中:

进入到getServer()方法,看如何选择一个服务的?
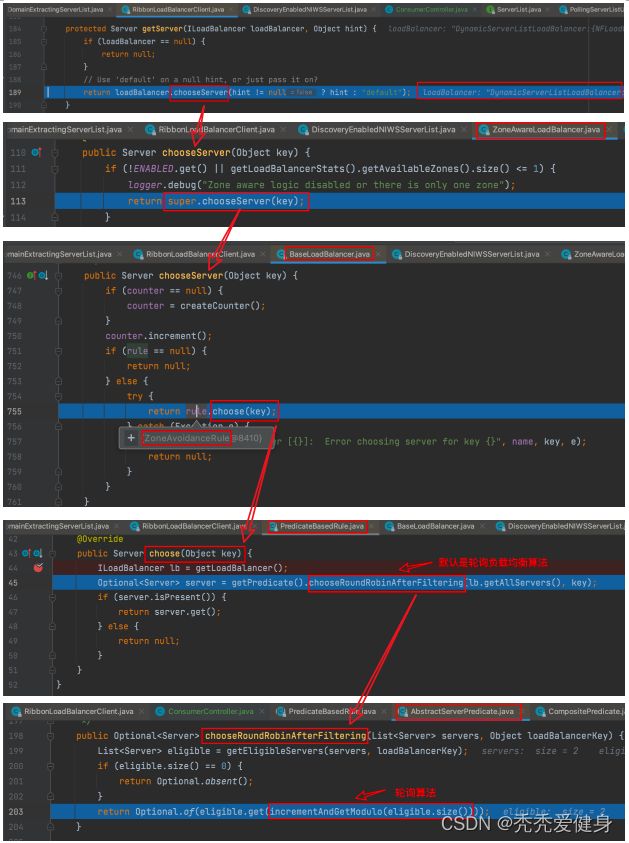
核心逻辑如下:
- BaseLoadBalancer的chooseServer()方法中,直接用IRule来选择了一台服务器;
- IRule是RibbonClientConfiguraiton中实例化的ZoneAvoidanceRule,调用了他的choose()方法来选择一个server,其实是用的父类PredicateBasedRule.choose()方法:
先执行过滤规则,过滤掉一批server,再根据我们自己指定的filter规则,然后用round robin轮询算法选择一个Server。
下面看看负载均衡的轮询算法是怎么做的?
1)轮询算法
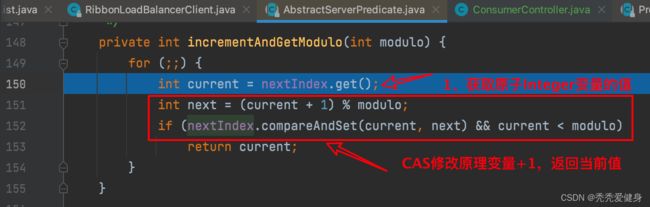
![]()
轮询算法很简单,重点在于通过AtomicInteger原子类型变量 + 死循环 CAS操作实现,每次返回原子类型变量nextIndex的当前值,因为原子类型变量nextIndex可能超过服务实例数,所以每次对原子类型变量nextIndex赋值时,都会对其做取余运算。
4、如何发送网络HTTP请求?
1)流程图
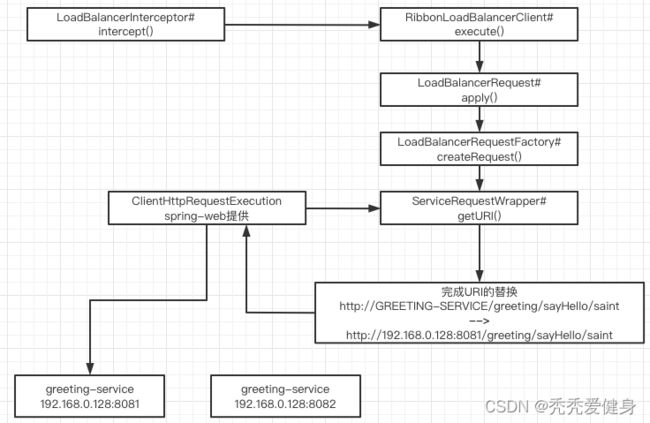
2)流程解析
getServer()方法选择出一个服务实例之后,进入到execute()重载方法去执行HTTP请求:
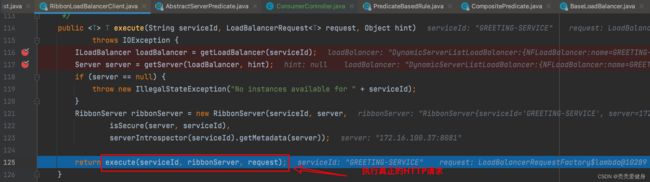
代码整体执行流程如下:

流程说明:
- 在
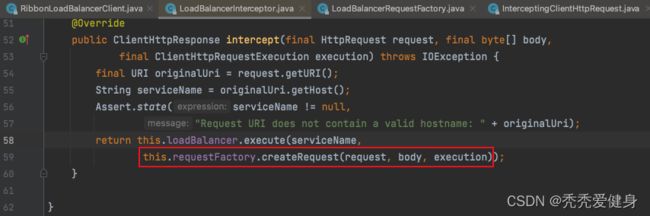
LoadBalancerInterceptor#intercept()方法中通过LoadBalancerRequestFactory工厂封装了HTTP请求为LoadBalancerRequest;
- 在RibbonLoadBalancerClient的execute()方法中,调用了
T returnVal = request.apply(serviceInstance);,进入到LoadBalancerRequest的apply()方法中,传入了选择出来的server,对这台server发起一个指定的一个请求。
- 将LoadBalancerRequest和server再次封装为了一个ServiceRequestWrapper;
- 将ServiceRequestWrappter交给
ClientHttpRequestExecution去执行。其实就是spring-web下的负责底层的http请求的组件,从ServiceRequestWrapper中获取出来了对应的真正的请求URL地址,然后发起了一次请求。- 其中
ServiceRequestWrapper#getURI()方法,基于选择出来的server的地址,重构了请求URI;即:将服务名替换为具体的IP:Port地址。
5、ping机制如何检查服务实例是否还存活?
在RibbonClientConfiguration类中会注入IPing类型的实例DummyPing,其中isAlive()方法直接返回TRUE;
public class DummyPing extends AbstractLoadBalancerPing {
public DummyPing() {
}
public boolean isAlive(Server server) {
return true;
}
}
这里是Ribbon默认的IPing,但是Eureka和Ribbon整合之后,EurekaRibbonClientConfiguration(spring-cloud-netflix-eureka-client包下)类中新定义了一个IPing。
@Bean
@ConditionalOnMissingBean
public IPing ribbonPing(IClientConfig config) {
if (this.propertiesFactory.isSet(IPing.class, serviceId)) {
return this.propertiesFactory.get(IPing.class, config, serviceId);
}
NIWSDiscoveryPing ping = new NIWSDiscoveryPing();
ping.initWithNiwsConfig(config);
return ping;
}
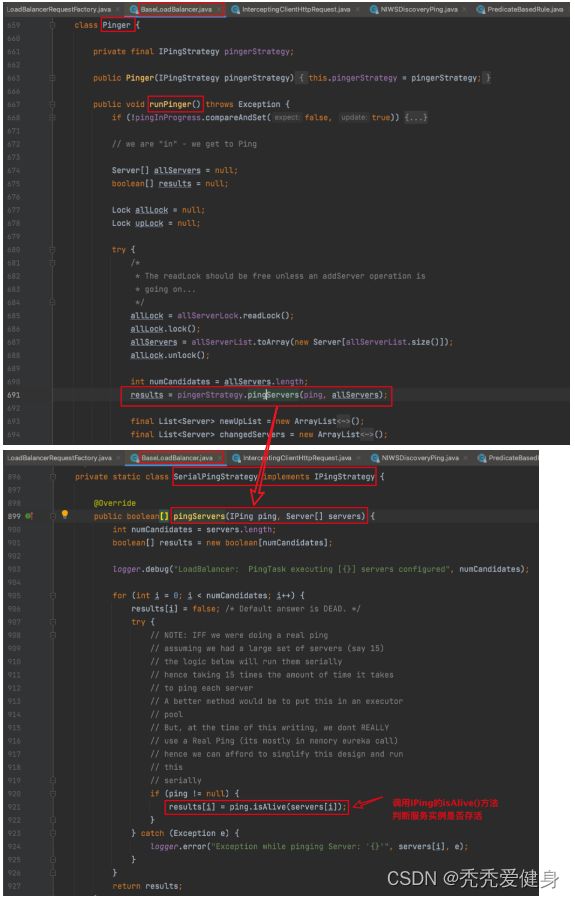
IPing的实例为NIWSDiscoveryPing;NIWSDiscoveryPing的isAlive()方法会检查某个server对应的eureka client中的InstanceInfo的状态,看看服务实例的status是否还正常;
public boolean isAlive(Server server) {
boolean isAlive = true;
if (server!=null && server instanceof DiscoveryEnabledServer){
DiscoveryEnabledServer dServer = (DiscoveryEnabledServer)server;
// 获取服务实例信息
InstanceInfo instanceInfo = dServer.getInstanceInfo();
if (instanceInfo!=null){
// 获取实例状态
InstanceStatus status = instanceInfo.getStatus();
if (status!=null){
// 服务实例状态是否为UP
isAlive = status.equals(InstanceStatus.UP);
}
}
}
return isAlive;
}
1)哪里使用到了IPing的isAlive()方法?
在ZoneAwareLoadBalancer实例构造时(进入到父类BaseLoadBalancer中),会启动一个定时调度的任务,每隔10s,就用IPing组件对server list中的每个server都执行一下isAlive()方法,判断服务实例是否还存活。
public BaseLoadBalancer() {
this.name = DEFAULT_NAME;
this.ping = null;
setRule(DEFAULT_RULE);
// 启动一个每10s执行一次的定时任务,最IPing#isAlive()操作
setupPingTask();
lbStats = new LoadBalancerStats(DEFAULT_NAME);
}
void setupPingTask() {
if (canSkipPing()) {
return;
}
if (lbTimer != null) {
lbTimer.cancel();
}
lbTimer = new ShutdownEnabledTimer("NFLoadBalancer-PingTimer-" + name,
true);
// 执行BaseLoadBalancer的内部类PingTask#run(),默认每10s执行一次
lbTimer.schedule(new PingTask(), 0, pingIntervalSeconds * 1000);
// 快速进行一次IPing
forceQuickPing();
}
class PingTask extends TimerTask {
public void run() {
try {
new Pinger(pingStrategy).runPinger();
} catch (Exception e) {
logger.error("LoadBalancer [{}]: Error pinging", name, e);
}
}
}
进入到PingTask#run()方法之后,下面看一下Pinger(pingStrategy).runPinger()的执行流程:
三、总结 以及 后续文章
到这里针对Ribbon的整个执行流程我们也就讨论完了,大体执行流程图下:
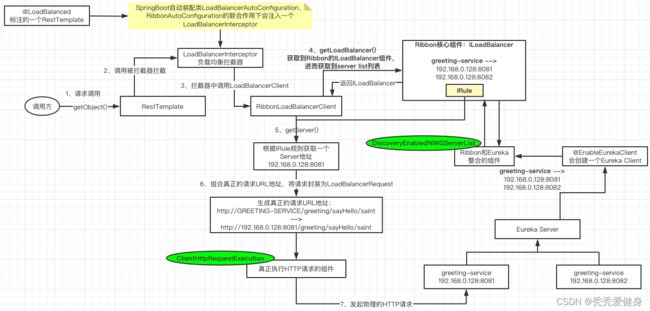
后文章,我们将讨论Ribbon内置的那些负载均衡算法是如何实现的?