coggle11月打卡—pytorch与CV竞赛
文章目录
-
- 任务1:PyTorch张量计算与Numpy的转换
- 任务2:梯度计算和梯度下降过程
-
- 1、学习自动求梯度原理
-
- 1.1 pytorch自动求导初步认识
- 1.2 tensor的创建与属性设置
- 1.3 函数求导方法——y.backward()
- 1.4 查看求得的导数的值——x.grad
- 1.5 总结
- 2、pytorch搭建线性回归模型
- 任务3:PyTorch全连接层原理和使用
-
- 1、全连接神经网络介绍
- 2、三层FC实现MNIST手写数字分类
- 任务4:PyTorch激活函数原理和使用
-
- 1、ReLU
-
- 1.1 原理介绍
- 1.2 pytorch实现:
- 2、Sigmoid
-
- 2.1 原理介绍
- 2.1 pytorch实现:
- 3、Tanh
-
- 3.1 原理介绍
- 3.2 pytorch实现:
- 4、LeakyReLU
-
- 4.1 原理介绍
- 4.2 pytorch实现:
- 5、PReLU
-
- 5.1 原理介绍
- 5.2 pytorch实现:
- 6、RReLU
-
- 6.1 原理介绍
- 6.2 pytorch实现:
- 7、ELU
-
- 7.1 原理介绍
- 7.2 pytorch实现:
- 任务5:PyTorch卷积层原理和使用
- 任务6:PyTorch常见的损失函数和优化器使用
-
- 1、损失函数
- 2、KL散度
- 3、平均绝对误差(L1范数)
- 4、均方误差损失(L2范数)
- 5、铰链损失函数
- 6、余弦相似度
- 7、优化器
- 任务7:PyTorch池化层和归一化层
-
- 1、池化层
-
- 1.1 池化层的来源
- 1.2 池化层的作用
- 2、归一化层
-
- 2.1 普通数据归一化
- 2.2 层归一化
- 2.3 BN层的添加位置
- 2.4 BN层的效果
- 2.5 BN算法
- 3、实现最大池化和平均池化
-
- 3.1 MaxPool
- 3.2 AvgPool2d
- 任务8:使用PyTorch搭建VGG网络
-
- 1、VGG原理
- 2、VGG优缺点
- 3、pytorch实战VGG篇
-
- 3.1 数据预处理:
- 3.2 搭建卷积神经网络
- 3.3 训练与测试
- 3.4 结果分析
- 4、打印出VGG 11层模型 每层特征图的尺寸,以及参数量。
- 任务9:使用PyTorch搭建ResNet网络
-
- 1、理解ResNet网络的原理
-
- 1.1 ResNet要解决的是什么问题?
- 1.2 ResNet 网络结构
- 2、使用pytorch搭建ResNet网络模型
-
- 2.1 搭建残差卷据神经网络
- 2.2 训练与测试
- 2.3 结果分析
- 3、打印出ResNet 18模型 每层特征图的尺寸,以及参数量
- 4、参考资料
- 任务10:使用PyTorch完成Fashion-MNIST分类
-
- 1、搭建4层卷积 + 2层全连接的分类模型
- 2、在训练过程中记录下每个epoch的训练集精度和测试集精度
- 任务11:人脸关键点检测
-
- 1、怎么加载和保存模型
- 2、什么是状态字典(state_dict)
- 3、预测时加载和保存模型(推荐)
- 4、使用自己搭建的卷积+全连接网络的训练结果:
- 5、使用ResNet18进行人脸关键点检测
- 任务12:使用PyTorch搭建对抗生成网络
-
- 1、GAN理论
-
- 1.1 GAN的直观理解
- 1.2 鉴别器
- 1.3鉴别器训练数据
- 1.4生成器
- 1.5随机输入
- 1.6 使用鉴别器训练生成器
- 2、DCGAN
-
- 2.1 模型结构需要做如下几点变化
- 2.2 DCGAN的网络结构如下:
- 3、使用DCGAN生成任务11中的人脸
-
- 3.1 代码脚本参数介绍
- 3.2 模型代码
- 3.3 训练代码
- 3.4 结果分析
任务1:PyTorch张量计算与Numpy的转换

任务2:梯度计算和梯度下降过程
1、学习自动求梯度原理
https://pytorch.org/tutorials/beginner/basics/autogradqs_tutorial.html
构建深度学习模型的基本流程就是:搭建计算图,求的损失函数,然后计算损失函数对模型参数的导数,再利用梯度下降等方法来更新参数。搭建计算图的过程,称为”正向传播“,这个是需要我们自己动手完成的额,因为我们需要设计我们的模型结构,由于损失函数求导的过程,称为”反向传播“,求导是件辛苦的事情,所以自动求导基本上就是各种深度学习框架的基本功能和最重要的功能之一,pytorch也不例外。
1.1 pytorch自动求导初步认识
比如有一个函数, y = x 2 y=x^2 y=x2,在x=3的时候,它的导数是6, 我们通过代码来计算这样一个过程。
x = torch.tensor(3.0, requires_grad=True)
y = torch.pow(x, 2)
# 判断x,y是不是都是可导的
print(x.requires_grad)
print(y.requires_grad)
# 求导,通过backward函数来实现
y.backward()
# 计算导数
print(x.grad)
# 输出
True
True
tensor(6.)
# 和我们口头算的一样
1.2 tensor的创建与属性设置
先看下官网上的tensor的定义
tensor(data, dtype=None, device=None, requires_grad=False) -> Tensor
参数:
data: (array_like): tensor的初始值. 可以是列表,元组,numpy数组,标量等;
dtype: tensor元素的数据类型
device: 指定CPU或者是GPU设备,默认是None
requires_grad:是否可以求导,即求梯度,默认是False,即不可导的
-
tensor对象的requires_grad属性
每一个tensor都有一个requires_grad属性,表示这个tensor是否是可求导的,如果是true则可以求导,否则不能求导,语法格式为:
x.requires_grad 判断一个tensor是否可以求导,返回布尔值。
需要注意的是,只有当所有的“叶子变量”,即所谓的leaf variable都是不可求导的,那函数y才是不能求导的,什么是leaf variable呢?这其实涉及到“计算图”相关的知识,想了解的同学可以上官方文档查看。
1.3 函数求导方法——y.backward()
上面只演示了简单函数的求导法则,
需要注意的是:如果出现了复合函数,比如 y是x的函数,z是y的函数,f是z的函数,那么在求导的时候,会使用 f.backwrad()只会默认求f对于叶子变量leaf variable的导数值,而对于中间变量y、z的导数值是不知道的,直接通过x.grad是知道的、y.grad、z.grad的值为none。
下面来看一下这个函数backward的定义:
backward(gradient=None, retain_graph=None, create_graph=False)
它的三个参数都是可选的,上面的示例中还没有用到任何一个参数,关于这三个参数,我后面会详细说到,这里先跳过。
1.4 查看求得的导数的值——x.grad
通过tensor的grad属性查看所求得的梯度值。
1.5 总结
(1)torch.tensor()设置requires_grad关键字参数
(2)查看tensor是否可导,x.requires_grad 属性
(3)设置叶子变量 leaf variable的可导性,x.requires_grad_()方法
(4)自动求导方法 y.backward() ,直接调用backward()方法,只会计算对计算图叶节点的导数。
(5)查看求得的到数值, x.grad 属性
易错点:
为什么上面的标量x的值是3.0和4.0,而不是整数呢?这是因为,要想使x支持求导,必须让x为浮点类型,也就是我们给初始值的时候要加个点:“.”。不然的话,就会报错。 即,不能定义[1,2,3],而应该定义成[1.,2.,3.],前者是整数,后者才是浮点数,浮点数才能求导。
2、pytorch搭建线性回归模型
- 使用numpy创建一个y=10*x+4+noise(0,1)的数据,其中x是0到100的范围,以0.01进行等差数列
- 使用pytroch定义w和b,并使用随机梯度下降,完成回归拟合。
使用pytorch搭建简单的线性回归模型,主要是需要以下的四部分:
- 1.准备数据
- 2.设计模型: 这里的模型就是算 y的预测值的。
- 3.构造损失函数和优化器
- 4.写训练周期
代码如下:
import torch
class LinearRegression(torch.nn.Module):
"""Linear Regression Module, the input features and output features are defaults bath 1
"""
def __init__(self):
super().__init__()
self.linear = torch.nn.Linear(1, 1)
def forward(self, x):
# 前馈函数:必须实现,反馈函数自动实现
# 因为:实例化这个类时,就会调用__call__*()这份方法,而这个方法
# 就写死了一定会调用forward这个方法,所以forward必须覆盖
out = self.linear(x)
return out
# 准备数据
def CreateLinearData(nums_data, if_plot=False):
"""
Create data for linear model
:param nums_data: the number of data points
:param if_plot: whether to plot the figure
:return: x with shape(nums_data, 1)
"""
x = torch.linspace(0,1,nums_data)
x = torch.unsqueeze(x, dim=1)
k = 10
y = k * x + torch.rand(x.size())
# if if_plot:
# plt.scatter(x.numpy(), y.numpy(), c=x.numpy())
# plt.show()
data = {"x" : x, "y" : y}
return data
if __name__ == "__main__":
# 创建数据
data = CreateLinearData(10000)
x = data['x']
y = data['y']
# 实例化模型
model = LinearRegression()
# 定义损失函数
# 实例化最小而成损失函数,继承自module.MSELoss()
loss_function = torch.nn.MSELoss(size_average=True)
# 定义优化器
# 随机梯度下降,参数传入, LinearRegression的权重和学习率
optimizer = torch.optim.SGD(model.parameters(), lr=0.01)
# 开始训练模型
for epoch in range(10000):
y_pre = model(x)
loss = loss_function(y_pre, y)
if epoch % 500 == 0:
print("Epoch:{}, loss is {}".format(epoch, loss))
# 梯度归0
optimizer.zero_grad()
# 对损失函数反向传播(为了求得参数的梯度)
loss.backward()
# 使用优化器进行梯度更新
optimizer.step()
print("w=", model.linear.weight.item())
print("b=", model.linear.bias.item())
结果如下:
Epoch:0, loss is 46.41630172729492
Epoch:500, loss is 1.2799032926559448
Epoch:1000, loss is 0.4037501811981201
Epoch:1500, loss is 0.16875039041042328
Epoch:2000, loss is 0.10571807622909546
Epoch:2500, loss is 0.08881229907274246
Epoch:3000, loss is 0.08427787572145462
Epoch:3500, loss is 0.08306160569190979
Epoch:4000, loss is 0.08273540437221527
Epoch:4500, loss is 0.08264791965484619
Epoch:5000, loss is 0.08262445032596588
Epoch:5500, loss is 0.08261816203594208
Epoch:6000, loss is 0.08261647075414658
Epoch:6500, loss is 0.08261602371931076
Epoch:7000, loss is 0.08261589705944061
Epoch:7500, loss is 0.08261585235595703
Epoch:8000, loss is 0.08261585235595703
Epoch:8500, loss is 0.08261585235595703
Epoch:9000, loss is 0.08261585235595703
Epoch:9500, loss is 0.08261585235595703
w= 10.000533103942871
b= 0.5008552670478821
任务3:PyTorch全连接层原理和使用
1、全连接神经网络介绍
全连接神经网络是一种最基本的神经网络结构,英文为Full Connection,所以一般简称FC。FC的神经网络中除输入层之外的每个节点都和上一层的所有节点有连接。
神经网络的第一层为输入层,最后一层为输出层,中间所有的层都为隐藏层。在计算神经网络层数的时候,一般不把输入层算做在内,所以上面这个神经网络为2层。其中输入层有3个神经元,隐层有4个神经元,输出层有2个神经元。
2、三层FC实现MNIST手写数字分类
先用 PyTorch 实现最简单的三层全连接神经网络,然后添加激活层查看试验结果, 最后再加上批标准化验证是否能够更加有效。
搭建如下的三种网络:
from torch import nn
class SimpleNet(nn.Module):
"""
定义了一个简单的三层全连接神经网络,每一层都是线性的(而且没有添加激活函数等
"""
def __init__(self, in_dim, n_hidden_1, n_hidden_2, out_dim):
# super(self.SimpleNet, self).__init__()
super().__init__()
self.layer1 = nn.Linear(in_dim, n_hidden_1)
self.layer2 = nn.Linear(n_hidden_1, n_hidden_2)
self.layer3 = nn.Linear(n_hidden_2, out_dim)
def forward(self, x):
x = self.layer1(x)
x = self.layer2(x)
x = self.layer3(x)
return x
class ActivationNet(nn.Module):
"""
在上面的SimpleNet的基础上,在每层的输出部分添加了激活函数
"""
def __init__(self, in_dim, n_hidden_1, n_hidden_2, out_dim):
# super(ActivationNet, self).__init__()
super().__init__()
self.layer1 = nn.Sequential(nn.Linear(in_dim, n_hidden_1), nn.ReLU(True))
self.layer2 = nn.Sequential(nn.Linear(n_hidden_1, n_hidden_2), nn.ReLU(True))
self.layer3 = nn.Sequential(nn.Linear(n_hidden_2, out_dim))
# 这里的Sequential()函数的功能是将网络的层组合到一起
def forward(self, x):
x = self.layer1(x)
x = self.layer2(x)
x = self.layer3(x)
return x
class BatchNet(nn.Module):
"""
在上面的ActivationNet的基础上,增加了一个加快收敛速度的方法——批归一化
"""
def __init(self, in_dim, n_hidden_1, n_hidden_2, out_dim):
# super(BatchNet, self).__init()
super().__init__()
self.layer1 = nn.Sequential(nn.Linear(in_dim, n_hidden_1), nn.BatchNorm1d(n_hidden_1), nn.ReLU(True))
self.layer2 = nn.Sequential(nn.Linear(n_hidden_1, n_hidden_2), nn.BatchNorm1d(n_hidden_2), nn.ReLU(True))
self.layer3 = nn.Sequential(nn.Linear(n_hidden_2, out_dim))
def forward(self, x):
x = self.layer1(x)
x = self.layer2(x)
x = self.layer3(x)
return x
在torchvision中提供了transforms用于帮助我们对图片进行预处理和标准化。其中我们需要用到的有两个:
ToTensor()和Normalize()。前者用于将图片转换成Tensor格式的数据,并且进行了表转化处理,后者用均值和标准偏差对张量图像进行归一化:给定均值:(M1,…,Mn)和标准差:(S1,…,Sn)用于n个通道,该变换将标准化输入torch.* Tensor 的每一个通道。其处理公式为:
![input[channel] = (input[channel] - mean[channel]) / std[channel]](http://img.e-com-net.com/image/info8/282d28da194c49dd8f636d7f1ad4f11b.gif)
而Compose函数可以将上述两个操作合并到一起进行。
data_df = transforms.Compose(
[transforms.ToTensor(),
transforms.Normalize([0.5],[0.5])]
)
pytorch提供了一些常用数据集,所以我们定义数据集下载器如下:
# 数据集下载器
train_dataset = datasets.MNIST(
root="./data", train=True, transform=data_df, download=True
)
test_dataset = datasets.MNIST(
root="./data", train=False, transform=data_df, download=True
)
train_loader = DataLoader(train_dataset, batch_size=batch_size, shuffle=True)
test_loader = DataLoader(test_dataset, batch_size=batch_size, shuffle=False)
然后选择相应的神经网络模型来及逆行训练和测试,我们这里定义的神经网络输入层为28*28, 因为我们处理后的图片像素是28 *28,两个隐层分别为300和100,最后输出层为10.因为我们识别0~9个数字,所以需要分为10类。损失函数和优化器这里采用了交叉熵和随机梯度下降。
# 选择模型
model = net.SimpleNet(28*28, 300, 100, 10)
if torch.cuda.is_available():
model = model.cuda()
# 定义损失韩式和优化器
criterion = nn.CrossEntropyLoss()
optimizer = optim.SGD(model.parameters(), lr=learning_rate)
# 训练模型
epoch = 0
for data in train_loader:
img, label = data
img = img.view(img.size(0), -1)
if torch.cuda.is_available():
img = img.cuda()
label = label.cuda()
else:
img = Variable(img)
label = Variable(label)
out = model(img)
loss = criterion(out, label)
optimizer.zero_grad()
loss.backward()
optimizer.step()
epoch += 1
if epoch % 50 == 0:
print("epoch: {}, loss: {:.4}".format(epoch, loss.data.item()))
# 模型评估
model.eval()
eval_loss = 0
eval_acc = 0
for data in test_loader:
img, label = data
img = img.view(img.size(0), -1)
if torch.cuda.is_available():
# volatile=True表示前向传播时不会保留缓存。测试集不需要做反向传播,所以可以在前向传播时释放掉内存,节约内存空间c
img = Variable(img, volatile=True).cuda()
label = Variable(label, volatile=True).cuda()
else:
img = Variable(img, volatile=True)
label = Variable(label, volatile=True)
out = model(img)
loss = criterion(out, label)
eval_loss += loss.data.item() * label.size(0)
_, pred = torch.max(out, 1)
num_correct = (pred == label).sum()
eval_acc += num_correct.item()
print('Test Loss: {:.6f}, Acc: {:.6f}'.format(
eval_loss / (len(test_dataset)),
eval_acc / (len(test_dataset))
))
3、结果测试:
epoch: 50, loss: 1.581
epoch: 100, loss: 0.9532
epoch: 150, loss: 0.6912
epoch: 200, loss: 0.5292
epoch: 250, loss: 0.539
epoch: 300, loss: 0.3006
epoch: 350, loss: 0.3295
epoch: 400, loss: 0.2163
epoch: 450, loss: 0.3771
epoch: 500, loss: 0.3214
epoch: 550, loss: 0.3469
epoch: 600, loss: 0.4078
epoch: 650, loss: 0.2921
epoch: 700, loss: 0.543
epoch: 750, loss: 0.3144
epoch: 800, loss: 0.2715
epoch: 850, loss: 0.27
epoch: 900, loss: 0.3537
Test Loss: 0.340433, Acc: 0.900500
任务4:PyTorch激活函数原理和使用
原理介绍:
1、ReLU
1.1 原理介绍
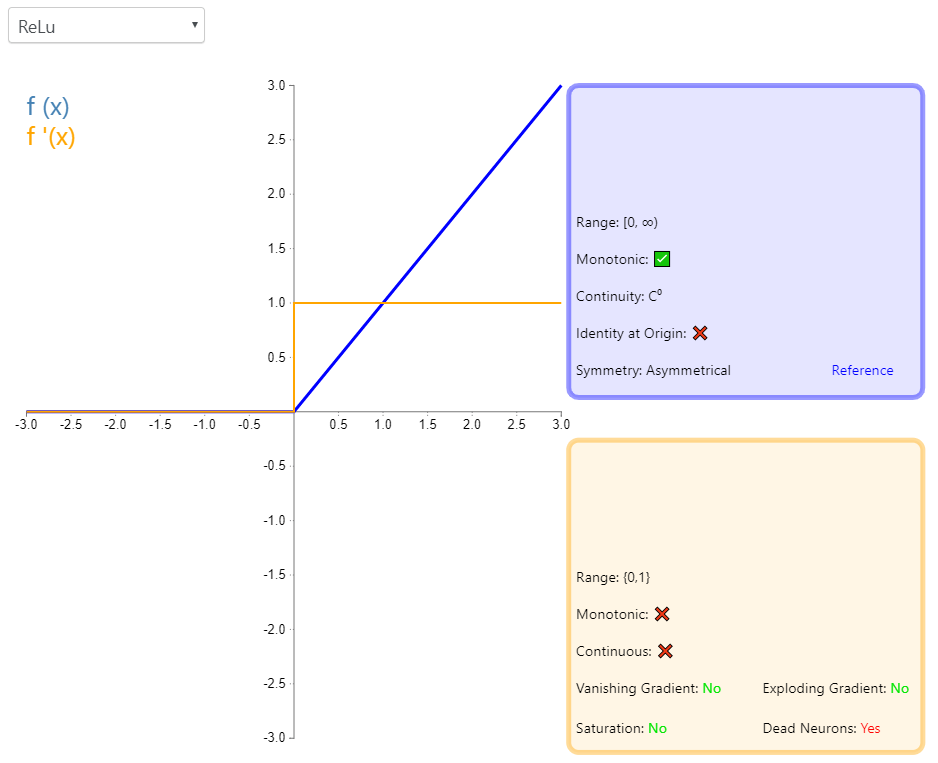
公式:
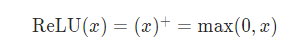
1.2 pytorch实现:
import torch
import torch.nn as nn
# pytorch实现ReLU
m = nn.ReLU()
input_x = torch.randn(2)
output_y = m(input_x)
output_y
>>>tensor([0.7326, 0.3741])
2、Sigmoid
2.1 原理介绍
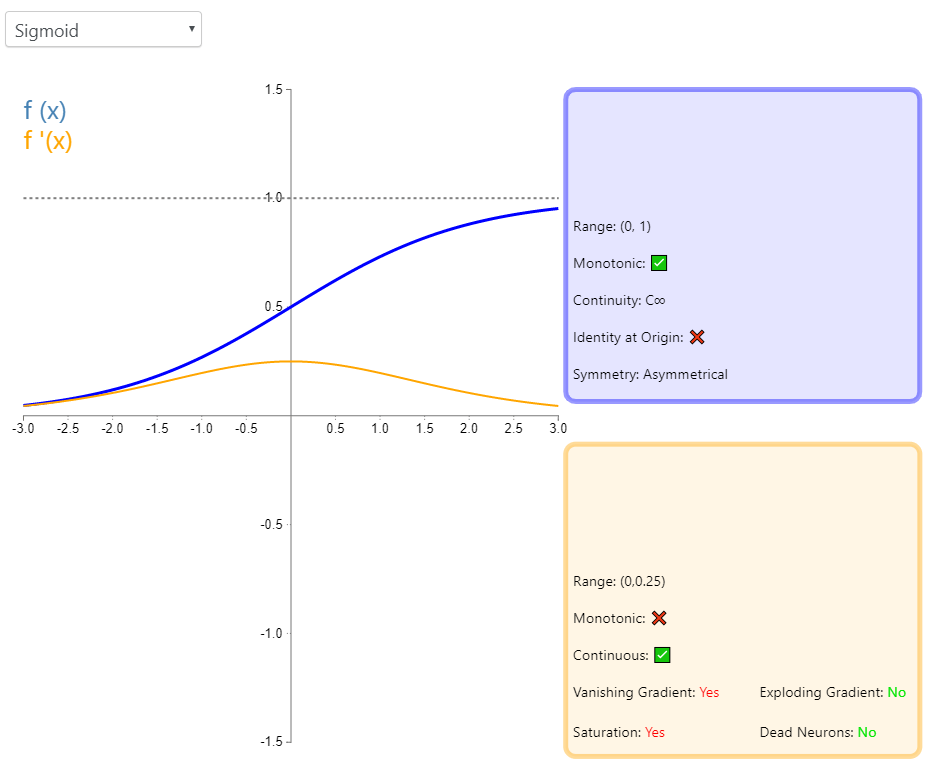
公式:

2.1 pytorch实现:
# 实现sigmoid
m = nn.Sigmoid()
input_x = torch.randn(2)
output_y = m(input_x)
output_y
>>>tensor([0.5115, 0.5444])
3、Tanh
3.1 原理介绍
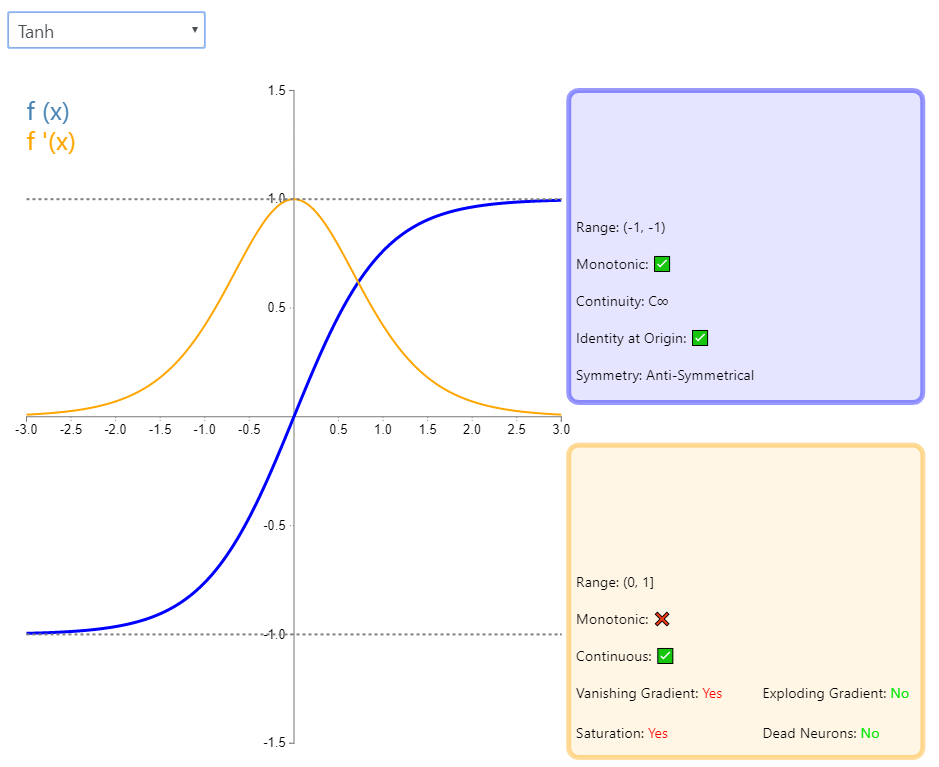
公式:

3.2 pytorch实现:
# tanh
m = nn.Tanh()
input_x = torch.randn(2)
output_y = m(input_x)
output_y
>>>tensor([ 0.0494, -0.9419])
4、LeakyReLU
4.1 原理介绍
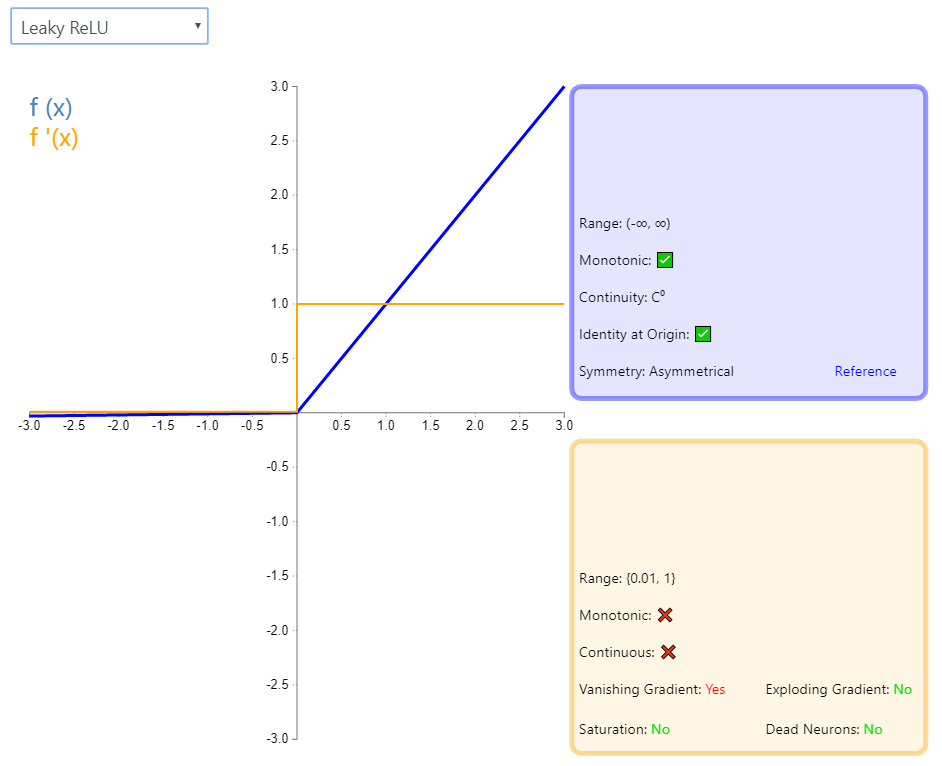
注意:LeakyReLU对负值输入有一个非常小的斜率。由于导数总是不为零,这可以减轻对死亡神经元的影响,从而允许基于梯度的学习发生(无论多慢)。
公式:
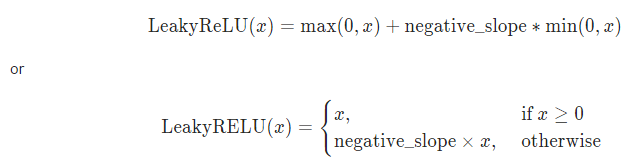
4.2 pytorch实现:
# LeakyReLU
m = nn.LeakyReLU(0.1)
input_x = torch.randn(2)
output_y = m(input_x)
output_y
>>>
tensor([ 0.8374, -0.0368])
5、PReLU
5.1 原理介绍
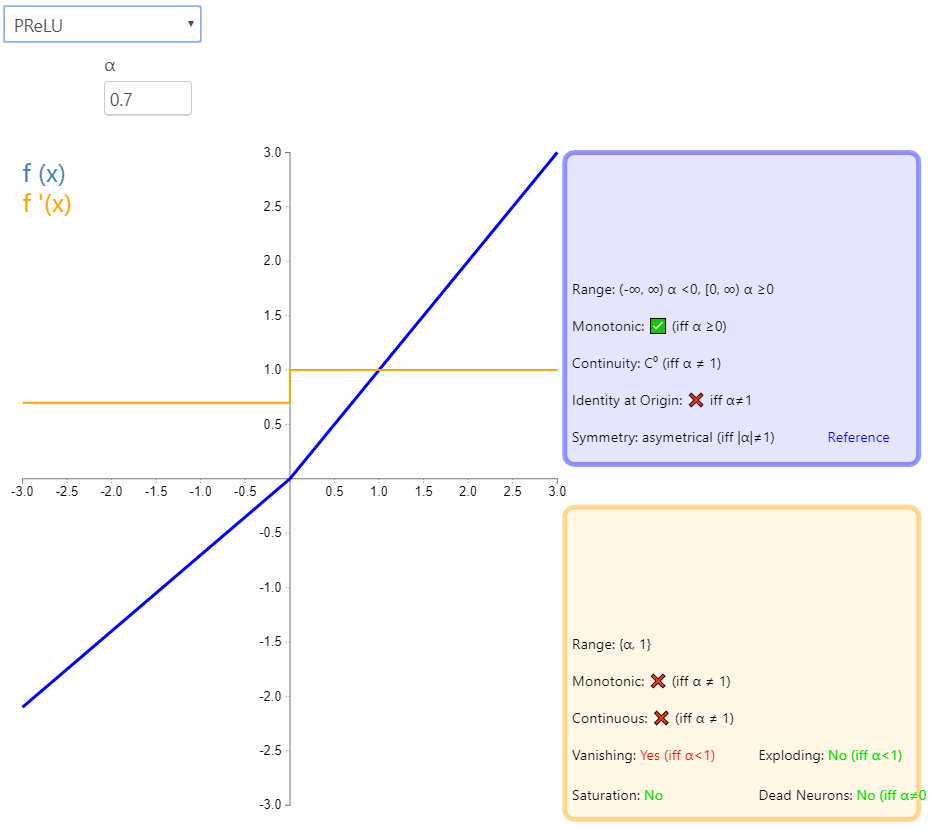
公式:

5.2 pytorch实现:
# PReLU
m = nn.PReLU()
input_x = torch.randn(2)
output_y = m(input_x)
output_y
>>>
tensor([-0.1766, -0.2993], grad_fn=<PreluBackward>)
6、RReLU
6.1 原理介绍
公式:
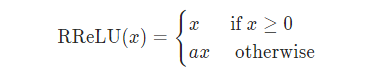
6.2 pytorch实现:
# RReLU
m = nn.RReLU(0.1, 0.3)
input_x = torch.randn(2)
output_y = m(input_x)
output_y
>>>tensor([1.2588, 1.0758])
7、ELU
7.1 原理介绍
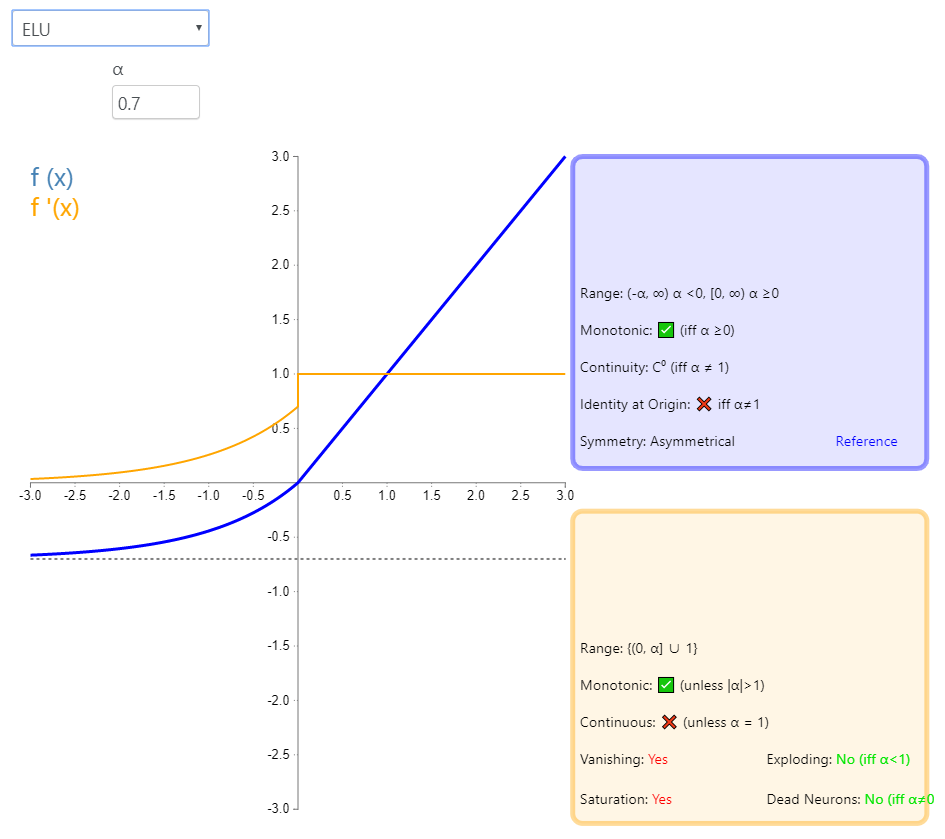
公式:
![]()
7.2 pytorch实现:
# ELU
m = nn.ELU()
input_x = torch.randn(2)
output_y = m(input_x)
output_y
>>>tensor([-0.0037, -0.6039])
任务5:PyTorch卷积层原理和使用
如果有一张1✖224✖224大小的图片,第一层就为卷积层,代码如下:
nn.Conv2d(
in_channels=1, # 输入通道数
out_channels=32, # 输出通道数,即卷积核数
kernel_size=5, # 卷积核的大小
stride=1,
padding=2 # padding=(kernel_size-1)/2
)
卷积层参数个数计算方法:
先整理以下此环境中对应的数据信息
信息列表
Filter个数:32
原始图像shape:1✖224✖224
卷积核大小为:5✖5
一个卷积核的参数:5✖5✖1
32个卷积核的参数总额:(加上bias)5✖5✖1 ✖32 + 32 = 832
weight * x + bias根据这个公式,即可算的最终的参数总额为:832
总结
在卷积层中,每个卷积核都能够学习到一个特征,那么这个特征其实就是卷积核对应学习到的参数:矩阵中每个单元weight,以及整个卷积核对应的一个bias
解决这个问题最根本还是需要理解最本质的一个公式:weight * x + bias
任务6:PyTorch常见的损失函数和优化器使用
1、损失函数
损失函数可以当作是nn的某一个特殊层,也是nn.Module的子类。但是在实际使用中,通常将这些loss function专门提取出来,和主模型互相独立。
- 交叉熵损失函数
在分类问题模型中(比如逻辑回归,神经网络等),这些模型的最后通常都会经过一个sigmoid函数(或者是softmax函数),输出一个类概率值(其他文章中也将其视为概率值),这个概率值反映了预测为正类的可能性。而对于预测的概率分布和真是的概率分布之间,使用交叉熵损失函数计算他们之间的差距。
二分类交叉熵损失函数公式:
L = 1 N ∑ i L i = 1 L ∑ i − [ y i ⋅ l o g ( p i ) + ( 1 − y i ) ⋅ l o g ( 1 − p i ) ] L=\frac{1}{N}\sum_iL_i=\frac{1}{L}\sum_i-[y_i·log(p_i)+(1-y_i)·log(1-p_i)] L=N1i∑Li=L1i∑−[yi⋅log(pi)+(1−yi)⋅log(1−pi)]
y i y_i yi表示样本标签,正类为1,负类为0, p i p_i pi表示样本 i i i预测为正的概率
多分类下的交叉熵损失函数公式:
L = 1 N ∑ i L i = 1 N ∑ i − ∑ c = 1 M y i c l o g ( p i c ) L=\frac{1}{N}\sum_iL_i=\frac{1}{N}\sum_i-\sum_{c=1}^My_{ic}log(p_{ic}) L=N1i∑Li=N1i∑−c=1∑Myiclog(pic)
M M M表示类别的数量, y i c y_{ic} yic表示类别(0~任意数字等), p i c p_{ic} pic表示对于观测样本 i i i属于类别 c c c的预测概率
- BCELoss
BCELoss是CrossEntropyLoss的一个特例,只用于二分类问题。BCELoss前面需要加上Sigmoid函数
torch.nn.BCELoss(weight:Optional[torch.Tensor]=None, size_average=None, reduce=None, reduction: str = 'mean')
参数:
1、weight:每个分类的缩放权重,传入的大小必须和类别数量一致
2、size_average:bool类型,为True时,返回的loss为平均值,为False时,返回的各样loss之和。
3、reduce:bool类型,返回值是否为标量,默认为True
4、reduction:string类型,‘none’|‘mean’|‘sum’三种参数值
5、pos_weight:正样本的权重,当p>1,提高召回率,当p<1,提高精确度。可达到权衡召回率和精确度的作用。
- NLLLoss
多分类的交叉熵函数,使用前需要对input进行log_softmax处理。
torch.nn.NLLLoss(weight=None, size_average=None, ignore_index=-100, reduce=None, reduction='mean')
CrossEntropyLoss
相当于整合了log_softmax和NLLLoss()
torch.nn.CrossEntropyLoss(weight: Optional[torch.Tensor]= None, size_average=None, ignore_index: int = -100, reduce=None, reduction: str = 'mean')
参数:
1、weight:每个分类的缩放权重,传入的大小必须和类别数量一至
2、size_average:bool类型,为True时,返回的loss为平均值,为False时,返回的各样本的loss之和
3、ignore_index:忽略某一类别,不计算其loss,其loss会为0,并且,在采用size_average时,不会计算那一类的4、loss,除的时候的分母也不会统计那一类的样本
5、reduce:bool类型,返回值是否为标量,默认为True
6、reduction:string类型,‘none’ | ‘mean’ | 'sum’三种参数值
2、KL散度
KL散度简介:
KL散度(相对熵)使用来衡量两个概率分布之间的差异。
D ( P ∣ ∣ Q ) = ∑ P ( x ) l o g P ( x ) Q ( x ) D(P||Q)=\sum P(x)log \frac{P(x)}{Q(x)} D(P∣∣Q)=∑P(x)logQ(x)P(x)
KLDivLoss
torch.nn.KLDivLoss(size_average=None, reduce=None, reduction: str = 'mean', log_target: bool = False)
参数:
.size_average: bool类型,为True时,返回的loss为平均值,为False时,返回个样本的loss之和
reduce:bool类型,返回值是否为标量,默认为True
reduction-三个值,none: 不使用约简;mean:返回loss和的平均值;sum:返回loss的和。默认:mean
log_target:默认False,指定是否在日志空间中传递目标
3、平均绝对误差(L1范数)
L1范数简介:
L1范数损失函数,也被称为最小绝对偏差(LAD),最小绝对值误差(LAE)。总的来说,它是目标值 Y i Y_i Yi与估计值 f ( x i ) f(x_i) f(xi)的绝对差值的总和 S S S最小化:
S = ∑ i = 1 n ∣ Y i − f ( X i ) ∣ S=\sum_{i=1}^n|Y_i-f(X_i)| S=i=1∑n∣Yi−f(Xi)∣
缺点:
- 梯度恒定,不论预测值是否接近真实值,这很容易导致三,或者错过极值点
- 导数不连续,导致求导困难,这也是L1损失函数不广泛使用的主要原因。
优点:
- 收敛速度比L2损失函数要快,L1性能能提供更大且更稳定的梯度
- 对异常的离群点有更好的鲁棒性
L1Loss
torch.nn.L1Loss(size_average=None, reduce=None, reduction: str = 'mean')
参数:
- size_average:bool类型,为True时,返回的loss为平均值,为False时,返回的各样本的loss之和
- reduce:bool类型,返回值是否为标量,默认为True
- reduction-三个值,none: 不使用约简;
- mean:返回loss和的平均值;sum:返回loss的和。默认:mean
l1_loss
torch.nn.functional.l1_loss(input, target, size_average=None, reduce=None, reduction='mean')
4、均方误差损失(L2范数)
L2范数简介
L2范数损失函数,也被称为最小平方误差(LSE)。总的来说,它是把目标值 Y i Y_i Yi与估计值 f ( x i ) f(x_i) f(xi)差距的平方和S最小化:
S = ∑ i = 1 n ( Y i − f ( x i ) ) 2 S = \sum_{i=1}^n(Y_i-f(x_i))^2 S=i=1∑n(Yi−f(xi))2
缺点:
- 收敛速度比L1慢,因为梯度会随着预测值接近真实值而不断减小。
- 对异常数据比L1敏感,这是平方项引起的,异常数据会引起很大的损失。
优点:
- 它使训练更容易,因为它的梯度会随着预测值接近真实值而不断减小,那么它不会轻易错过极值点,但也容易陷入局部最优。
- 它的导数具有封闭解,优化和编程非常容易,所以很多回归任务都是用MSE做损失函数。
MSELoss
torch.nn.MSELoss(size_average=None, reduce=None, reduction: str = 'mean')
参数:
- size_average: bool类型,为True时,返回的loss为平均值,为False时,返回的个样本的loss参数
- reduce:bool类型,返回值是否为标量,默认为True
- reduction:三个值,none:不使用约简;mean:返回loss和的平均值;sum:返回loss的和。默认:mean
mse_loss
torch.nn.functional.mse_loss(input, target, size_average=None, reduce=None, reduction='mean')
5、铰链损失函数
Hinge loss简介
有人把hinge loss称为铰链损失函数,它可用于“最大间隔(max-margin)”分类,其最著名的应用是作为SVM的损失函数。
L i = ∑ j ≠ y i m a x ( 0 , s j − s y i + △ ) L_i=\sum_{j\neq y_i}max(0,s_j-s_{yi}+\triangle) Li=j=yi∑max(0,sj−syi+△)
HingeEmbeddingLoss
torch.nn.HingeEmbeddingLoss(margin: float = 1.0, size_average=None, reduce=None, reduction: str = 'mean')
参数:
- margin:float类型,默认为1.
- size_average:bool类型,为True时,返回的loss为平均值,为False时,返回的各样本的loss之和
- reduce:bool类型,返回值是否为标量,默认为True
- reduction-三个值,none: 不使用约简;mean:返回loss和的平均值;sum:返回loss的和。默认:mean
6、余弦相似度
余弦相似度是机器学习中的一个重要概念,在Mahout等MLib中有几种常用的相似度计算方法,如欧氏距离,皮尔逊相似度,余弦相似度,Tanimoto相似度等。其中,余弦相似度是其最重要的一种。余弦相似度用向量空间中的两个向量夹角的余弦值作为衡量两个个体间差异的大小,相比于距离度量,余弦相似度更注重两个向量在方向上的差异,而非距离或长度上。
余弦相似度更多的是从方向上区分差异,而非绝对的数值奴敏感,更多的用于使用用户对内容评分来区分用户兴趣的相似度和差异,同时修正了用户间可能存在的度量标准不统一的问题(因为余弦相似度对绝数值不敏感),公式如下:
s i m ( X , Y ) = c o s θ = x ⃗ ⋅ y ⃗ ∣ ∣ x ∣ ∣ ⋅ ∣ ∣ y ∣ ∣ sim(X,Y)=cos \theta=\frac{\vec{x}·\vec{y}}{||x||·||y||} sim(X,Y)=cosθ=∣∣x∣∣⋅∣∣y∣∣x⋅y
CosineEmbeddingLoss
torch.nn.CosineEmbeddingLoss(margin: float = 0.0, size_average=None, reduce=None, reduction: str = 'mean')
参数:
margin:float类型,应为-1到1之间的数字,建议为0到0.5,默认值为0
size_average:bool类型,为True时,返回的loss为平均值,为False时,返回的各样本的loss之和
reduce:bool类型,返回值是否为标量,默认为True
reduction-三个值,none: 不使用约简;mean:返回loss和的平均值;sum:返回loss的和。默认:mean
7、优化器
所有的优化方法都封装在torch.optim中,它的设计很灵活,可以扩展为自定义的优化方法,所有的优化方法都是继承了基类optimi.Optiizer。并实现了自己的优化步骤。关于优化器需要掌握:
- 优化方法基本使用:
import optim
optimizer = optim.SGD(params=ne.parameters(), lr=0.1)
optimizerzero_grad() # 梯度清0
output = net(input)
loss.backward(output)
optimizer.step()
# 0.1的SGD优化器
Epoch:0, loss is 40.793758392333984
Epoch:200, loss is 0.11443594843149185
Epoch:400, loss is 0.08399596810340881
Epoch:600, loss is 0.08384328335523605
Epoch:800, loss is 0.08384252339601517
w= 10.006535530090332
b= 0.49600955843925476
# 0.5的SGD优化器
Epoch:0, loss is 31.053300857543945
Epoch:200, loss is 0.08398652076721191
Epoch:400, loss is 0.08398653566837311
Epoch:600, loss is 0.08398653566837311
Epoch:800, loss is 0.08398653566837311
w= 10.009859085083008
b= 0.4981590509414673
# 0.01的SGD优化器
Epoch:200, loss is 2.461658477783203
Epoch:400, loss is 1.4879323244094849
Epoch:600, loss is 0.913299024105072
Epoch:800, loss is 0.5738411545753479
w= 8.139299392700195
b= 1.4975601434707642
任务7:PyTorch池化层和归一化层
1、池化层
1.1 池化层的来源
池化层是深度学习中常用组件之一,在当前大部分神经网络结构中都会使用池化层,池化层最早来源于LeNet一文,当时被称为SumSample。在AlexNet之后采用Pooling命名,后面延续了该命名。
1.2 池化层的作用
池化层模拟的是人的视觉系统对数据进行降维,使用数据更高层次的特征维度进行学习。通过对特征实施池化,可以达到如下的效果:
- 降低信息冗余,通过相关的池化操作,例如最大值池化,可将局部无用的信息排除。
- 提升模型的尺寸不变性,旋转不变性:对某个区域做了池化,即使图像平移/旋转接像素,得到的输出值也基本一样
- 防止过拟合。在图像深度学习中图像尺寸太大,引入吃u哈可以减少参数矩阵的参数,减少最后全连接中的参数数量。
2、归一化层
2.1 普通数据归一化
Batch Normalization,批归一化,和普通的数据标准化类似,就是将分散的数据统一的一种做法,也是优化神经网络的一种方法,具有同意规格的数据,能让机器学习更容易学习到数据之中的规律。
2.2 层归一化
在神经网络中, 数据分布对训练会产生影响. 比如某个神经元 x 的值为1, 某个 Weights 的初始值为 0.1, 这样后一层神经元计算结果就是 Wx = 0.1; 又或者 x = 20, 这样 Wx 的结果就为 2. 现在还不能看出什么问题, 但是, 当我们加上一层激励函数, 激活这个 Wx 值的时候, 问题就来了. 如果使用 像 tanh 的激励函数, Wx 的激活值就变成了 ~0.1 和 ~1, 接近于 1 的部已经处在了 激励函数的饱和阶段, 也就是如果 x 无论再怎么扩大, tanh 激励函数输出值也还是 接近1. 换句话说, 神经网络在初始阶段已经不对那些比较大的 x 特征范围 敏感了. 这样很糟糕, 想象我轻轻拍自己的感觉和重重打自己的感觉居然没什么差别, 这就证明我的感官系统失效了. 当然我们是可以用之前提到的对数据做 normalization 预处理, 使得输入的 x 变化范围不会太大, 让输入值经过激励函数的敏感部分. 但刚刚这个不敏感问题不仅仅发生在神经网络的输入层, 而且在隐藏层中也经常会发生
只是这时候 x 换到了隐藏层当中, 我们能不能对隐藏层的输入结果进行像之前那样的normalization 处理呢? 答案是可以的, 因为大牛们发明了一种技术, 叫做 batch normalization, 正是处理这种情况.
2.3 BN层的添加位置

Batch normalization 的 batch 是批数据, 把数据分成小批小批进行 stochastic gradient descent. 而且在每批数据进行前向传递 forward propagation 的时候, 对每一层都进行 normalization 的处理
2.4 BN层的效果
Batch normalization 也可以被看做一个层面. 在一层层的添加神经网络的时候, 我们先有数据 X, 再添加全连接层, 全连接层的计算结果会经过 激励函数 成为下一层的输入, 接着重复之前的操作. Batch Normalization (BN) 就被添加在每一个全连接和激励函数之间.
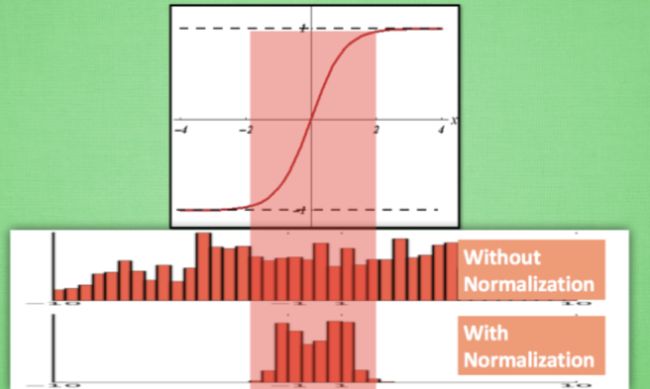
之前说过, 计算结果在进入激励函数前的值很重要, 如果我们不单单看一个值, 我们可以说, 计算结果值的分布对于激励函数很重要. 对于数据值大多分布在这个区间的数据, 才能进行更有效的传递. 对比这两个在激活之前的值的分布. 上者没有进行 normalization, 下者进行了 normalization, 这样当然是下者能够更有效地利用 tanh 进行非线性化的过程.
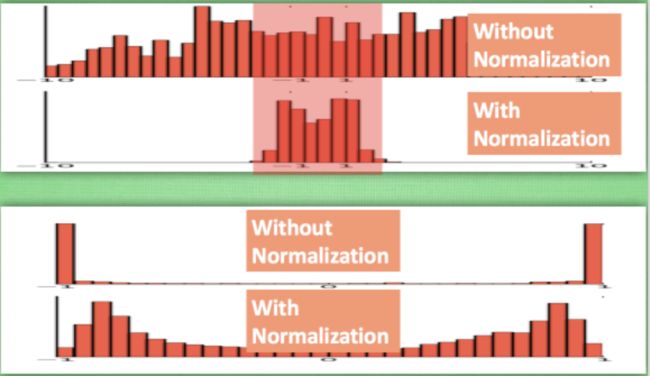
没有 normalize 的数据 使用 tanh 激活以后, 激活值大部分都分布到了饱和阶段, 也就是大部分的激活值不是-1, 就是1, 而 normalize 以后, 大部分的激活值在每个分布区间都还有存在. 再将这个激活后的分布传递到下一层神经网络进行后续计算, 每个区间都有分布的这一种对于神经网络就会更加有价值. Batch normalization 不仅仅 normalize 了一下数据, 他还进行了反 normalize 的手续. 为什么要这样呢?
2.5 BN算法

我们引入一些 batch normalization 的公式. 这三步就是我们在刚刚一直说的 normalization 工序, 但是公式的后面还有一个反向操作, 将 normalize 后的数据再扩展和平移. 原来这是为了让神经网络自己去学着使用和修改这个扩展参数 gamma, 和 平移参数 β, 这样神经网络就能自己慢慢琢磨出前面的 normalization 操作到底有没有起到优化的作用, 如果没有起到作用, 我就使用 gamma 和 belt 来抵消一些 normalization 的操作.
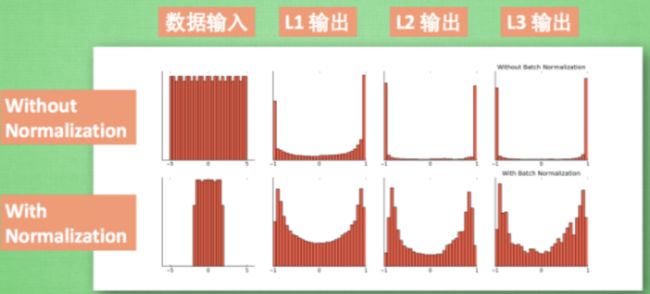
最后我们来看看一张神经网络训练到最后, 代表了每层输出值的结果的分布图. 这样我们就能一眼看出 Batch normalization 的功效啦. 让每一层的值在有效的范围内传递下去。
3、实现最大池化和平均池化
3.1 MaxPool
torch.nn.MaxPool2d(kernel_size, stride=None, padding=0, dilation=1, return_indices=False, ceil_mode=False)
实现简单的卷积神经网络(其中使用到池化层和归一化层)
使用nn.MAxPool2d()
from torch import nn
class CNN(nn.Module):
def __init__(self):
super().__init__()
self.layer1 = nn.Sequential(
nn.Conv2d(1,25, kernel_size=3),
nn.BatchNorm2d(25),
nn.ReLU(inplace=True)
)
self.layer2 = nn.Sequential(
nn.MaxPool2d(kernel_size=2, stride=2)
)
self.layer3 = nn.Sequential(
nn.Conv2d(25, 50, kernel_size=3),
nn.BatchNorm2d(50),
nn.ReLU(inplace=True)
)
self.layer4 = nn.Sequential(nn.MaxPool2d(kernel_size=2, stride=2))
self.fc = nn.Sequential(
nn.Linear(50 *5 * 5, 1024),
nn.ReLU(inplace=True),
nn.Linear(1024, 128),
nn.ReLU(inplace=True),
nn.Linear(128, 10)
)
def forward(self, x):
x = self.layer1(x)
x = self.layer2(x)
x = self.layer3(x)
x = self.layer4(x)
x = x.view(x.size(0), -1)
x = self.fc(x)
return x
3.2 AvgPool2d
nn.AvgPool2d
torch.nn.AvgPool2d(kernel_size, stride=None, padding=0, ceil_mode=False, count_include_pad=True)
from torch import nn
class CNN(nn.Module):
def __init__(self):
super().__init__()
self.layer1 = nn.Sequential(
nn.Conv2d(1,25, kernel_size=3),
nn.BatchNorm2d(25),
nn.ReLU(inplace=True)
)
self.layer2 = nn.Sequential(
nn.AvgPool2d(kernel_size=2, stride=2)
)
self.layer3 = nn.Sequential(
nn.Conv2d(25, 50, kernel_size=3),
nn.BatchNorm2d(50),
nn.ReLU(inplace=True)
)
self.layer4 = nn.Sequential(nn.MaxPool2d(kernel_size=2, stride=2))
self.fc = nn.Sequential(
nn.Linear(50 *5 * 5, 1024),
nn.ReLU(inplace=True),
nn.Linear(1024, 128),
nn.ReLU(inplace=True),
nn.Linear(128, 10)
)
def forward(self, x):
x = self.layer1(x)
x = self.layer2(x)
x = self.layer3(x)
x = self.layer4(x)
x = x.view(x.size(0), -1)
x = self.fc(x)
return x
任务8:使用PyTorch搭建VGG网络
1、VGG原理
VGG16相比AlexNet一个改建是采用连续的几个3* 3 卷积核来代替AlexNet张的较大卷积核(11* 11, 7* 7,5* 5)。对于给定的感受野(与输出有关的输入图片的局部大小),采用堆积的小卷积是由于采用大的卷积核,因为多层非线性层可以增加网络深度来保证学习更复杂的模式,而且代价还比较小(参数更少)。
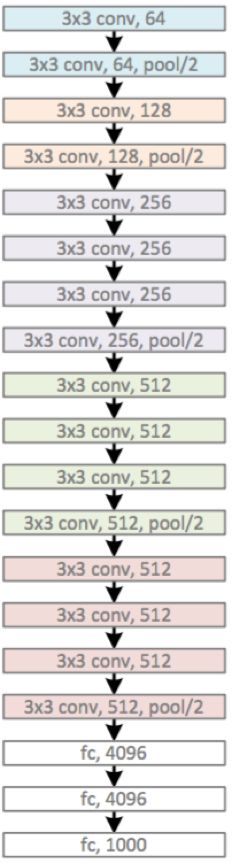
简单来说,在VGG中,使用了3个3 * 3 的卷积核来代替7 * 7 卷积核,使用了2个3x3卷积核来代替5*5卷积核,这样做的主要目的是在保证具有相同感知野的条件下,提升了网络的深度,在一定程度上提升了神经网络的效果。
比如,3个步长为1的3 * 3卷积核的一层层叠加可堪称一个大小为7的感受野(其实就表示3个3* 3连续卷积相当于一个 7* 7卷积),其参数总量为 3x(9xC^2)

VGG块
VGG块的组成规律是:连续使用数个相同的填充(padding=1)为1,窗口形状为3✖3的卷积层后接上一个步幅为2,窗口形状为2✖2的最大池化层。卷积层保持输入的高度和宽度不变,而池化层则对其减半,我们使用vgg_block函数来实现这个基础的VGG块,它可以指定卷积层的数量和输入输出通道数。
对于给定的感受野(与输出相关的输入图片的局部大小),采用堆积的小卷积核优于采用大的卷积核,因为可以增加网络深度来保证学习更复杂的模式,而且代价还比较小(参数更少)。例如:在VGG中,使用了3个3✖3卷积核来代替7✖7卷积核,使用2个3✖3卷积核来代替5✖5卷积核,这样做的主要目的是在保证具有相同感受野的条件下,提升了网络的深度,在一定程度上提升了神经网络的效果。
2、VGG优缺点
优点:
- VGGNet的结构非常简洁,整个网络都使用了同样大小的卷积核尺寸(3✖3)和最大化尺寸(2✖2)
- 几个小滤波器(3✖3)卷积层的组合比一个大滤波器(5✖5或7✖7)卷积层好
- 验证了不断加深网络结构可以提升性能
缺点: - VGG耗费更多计算资源,并且使用了更多的参数(这里不是3✖3卷积的锅),导致更多的内存占用(149M)。其中绝大多数的参数都是来自第一个全连接层。VGG可是有3个全连接层。
PS:有的文章称:发现这些全连接层即使被去除,对于性能也没有什么影响,这样就限制降低了参数质量。
注:很多pretrained的方法就是使用VGG的model(主要是16和19),VGG相对其他的方法,参数空间很大,最终的model有500多m,AlexNet只有200m,GoogLeNet更少,所以train一个vgg模型通常要花费更长的时间,所幸有公开的pretrained model让我们很方便的使用。
3、pytorch实战VGG篇
3.1 数据预处理:
数据集下载:http://download.tensorflow.org/example_images/flower_photos.tgz
将数据集执行split_data.py脚本自动将数据集划分成训练集train和验证集val
|—— flower_data
|———— flower_photos(解压的数据集文件夹,3670个样本)
|———— train(生成的训练集,3306个样本)
|———— val(生成的验证集,364个样本)
————————————————
- split_data.py 分割数据集
import random
def mkfile(file):
if not os.path.exists(file):
os.makedirs(file)
file = "flower_data/flower_photos"
flower_class = [cla for cla in os.listdir(file) if ".txt" not in cla]
mkfile("flower_data/train")
mkfile("flower_data/val")
for cla in flower_class:
# 每一个类别都创建一个train和val文件夹
mkfile("flower_data/train/" + cla)
mkfile("flower_data/val/" + cla)
split_rate = 0.1
for cla in flower_class:
# 利用字符串拼接出照片的路径
cla_path = file + "/" + cla + "/"
# 列出所有的照片
images = os.listdir(cla_path)
num = len(images)
eval_index = random.sample(images, k=int(num*split_rate))
for index, image in enumerate(images):
if image in eval_index:
image_path = cla_path + image
new_path = "flower_data/val/" + cla
copy(image_path, new_path)
else:
image_path = cla_path + image
new_path = "flower_data/train/" + cla
copy(image_path, new_path)
print("processing done!")
3.2 搭建卷积神经网络
- model.py创建网络架构
import torch.nn as nn
import torch.utils.model_zoo as model_zoo
import torch
from torch.nn import functional as F
# 对外暴露接口,当导入模块时,只枚举列表里面的
__all__ = ['vgg19']
# 预训练模型下载地址
model_urls = {
'vgg19': 'https://downloa.pytorch.org/models/vgg19-dcbb9e9d.pth',
}
# 可以定义不同的VGG结构,这样写可以有效节约代码空间,下面以VGG19为例
cfg = {
'E': [64, 64, 'M', 128, 128, 'M', 256, 256, 256, 256, 'M', 512, 512, 512, 512, 'M', 512, 512, 512, 512]
}
class VGG(nn.Module):
def __init__(self, features, num_classes=1000, init_weights=False):
super(VGG, self).__init__()
self.features = features
self.classifier = nn.Sequential(
nn.Dropout(p=0.5),
nn.Linear(512 * 7 * 7, 2048),
nn.ReLU(True),
nn.Dropout(p=0.5),
nn.Linear(2048, 2048),
nn.ReLU(True),
nn.Linear(2048, num_classes)
)
if init_weights:
# 初始化权重
self._initialize_weights()
def forward(self, x):
# N * 3 * 224 * 224
x = self.features(x)
# N * 512 * 7 * 7
x = torch.flatten(x, start_dim=1)
# N * 512 * 7 * 7
x = self.classifier(x)
return x
def _initialize_weights(self):
for m in self.modules(): # 遍历网络的每一个子模块
if isinstance(m, nn.Conv2d):
# nnn.init.kaiming-normal_()
nn.init.xavier_uniform_(m.weight) # 初始化全中国参数
if m.bias is not None: # 如果采用了偏置的话,置为0
nn.init.constant_(m.bias, 0)
elif isinstance(m, nn.Linear):
nn.init.xavier_uniform_(m.weight)
nn.init.constant_(m.bias, 0)
def make_features(cfg):
layers = []
in_channels = 3
for v in cfg:
if v == "M":
layers += [nn.MaxPool2d(kernel_size=2, stride=2)]
else:
conv2d = nn.Conv2d(in_channels, v, kernel_size=3, padding=1)
layers += [conv2d, nn.ReLU(True)]
in_channels = v
return nn.Sequential(*layers)
cfgs = {
# 论文中的A B C D E
'vgg11': [64, 'M', 128, 'M', 256, 256, 'M', 512, 512, 'M', 512, 512, 'M'],
'vgg13': [64, 64, 'M', 128, 128, 'M', 256, 256, 'M', 512, 512, 'M', 512, 512, 'M'],
'vgg16': [64, 64, 'M', 128, 128, 'M', 256, 256, 256, 'M', 512, 512, 512, 'M', 512, 512, 512, 'M'],
'vgg19': [64, 64, 'M', 128, 128, 'M', 256, 256, 256, 256, 'M', 512, 512, 512, 512, 'M', 512, 512, 512, 512, 'M'],
}
def vgg(model_name="vgg16", **kwargs):
try:
cfg = cfgs[model_name]
except:
print("Warning: model number{} not in cfgs dict!".format(model_name))
exit(-1)
model = VGG(make_features(cfg), **kwargs)
return model
3.3 训练与测试
- train.py 训练网络
import torch.nn as nn
from torchvision import transforms, datasets
import json
import os
import torch.optim as optim
from model import vgg
import torch
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
print(device)
if __name__ == "__main__":
data_trasform = {
"train": transforms.Compose([transforms.RandomResizedCrop(224),
transforms.RandomHorizontalFlip(),
transforms.ToTensor(),
transforms.Normalize((0.5,0.5,0.5),(0.5,0.5,0.5))]),
# 为啥val和train的处理是不一样的?
"val": transforms.Compose([transforms.Resize((224, 224)),
transforms.ToTensor(),
transforms.Normalize((0.5,0.5,0.5),(0.5,0.5,0.5))])
}
# data_root = "E://"
data_root = os.getcwd()
image_path = data_root + "/flower_data/"
train_dataset = datasets.ImageFolder(root=image_path+"train",
transform=data_trasform["train"])
train_num = len(train_dataset)
# 这个是啥?-> 哈?
flower_list = train_dataset.class_to_idx
cla_dict = dict((val,key) for key, val in flower_list.items())
# write dict into json file
# json.dumps()将字典形式的数据转化为字符串
# json.loads()用于将字符串形式的数据转化为字典
json_str = json.dumps(cla_dict, indent=4)
with open("class_indices.json", "w") as json_file:
json_file.write(json_str)
batch_size=32
train_loader = torch.utils.data.DataLoader(train_dataset
, batch_size=batch_size
, shuffle=True
, num_workers=2
, pin_memory=True)
validate_dataset = datasets.ImageFolder(root=image_path + "val"
, transform=data_trasform["val"]
)
val_num = len(validate_dataset)
validate_loader = torch.utils.data.DataLoader(validate_dataset,
batch_size=batch_size
, shuffle=True
, num_workers=2
, pin_memory=True)
# test_data_iter = iter(valodate_laoder)
# test_image, test_label = test_data_iter.next()
model_name = "vgg16"
net = vgg(model_name=model_name, num_classes=5, init_weights=True)
net.to(device)
loss_function = nn.CrossEntropyLoss()
optimizer = optim.Adam(net.parameters(), lr=1e-4)
best_acc = 0.0
save_path = "./{}Net.pth".format(model_name)
for epoch in range(30):
# train
net.train()
running_loss = 0.0
for step, data in enumerate(train_loader, start=0):
images, labels = data
# 梯度清0
optimizer.zero_grad()
# 将神经网络的输出连接到GPU上
outputs = net(images.to(device))
loss = loss_function(outputs, labels.to(device))
# 反向传播
loss.backward()
# 更新梯度
optimizer.step()
running_loss += loss.item()
# 打印训练过程
rate = (step+1) / len(train_loader)
a = "*" * int(rate*50)
b = "." * int((1-rate)*50)
print("\rtrain loss: {:^3.0f}%[{}->{}]{:.3f}".format(int(rate * 100), a, b, loss), end="")
# validate
net.eval()
acc = 0.0 # accumulate accurate number /epoch
with torch.no_grad():
# 验证的情况下需要开启no_grad()
for val_data in validate_loader:
val_images, val_labels = val_data
optimizer.zero_grad()
outputs = net(val_images.to(device))
predict_y = torch.max(outputs, dim=1)[1]
acc += (predict_y == val_labels.to(device)).sum().item()
val_accurate = acc / val_num
if val_accurate > best_acc:
best_acc = val_accurate
torch.save(net.state_dict(), save_path)
print(step)
print('[epoch %d] train_loss: %.3f test_accuracy: %.3f' %
(epoch + 1, running_loss / (step+1), val_accurate))
print('Finished Training')
训练网络的代码每次写都大同小异,因此这里不做过多的注释。
- predict.py 预测
import torch
from model import vgg
from PIL import Image
from torchvision import transforms
import matplotlib.pyplot as plt
import json
import os
os.environ["KMP_DUPLICATE_LIB_OK"] = "TRUE"
data_transform = transforms.Compose(
[transforms.Resize((224,224)),
transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5),(0.5,0.5,0.5))]
)
# load image
img = Image.open("./tulip.jpg")
plt.imshow(img)
# [N, C, H ,W]
img = data_transform(img)
# expand batch dimension
img = torch.unsqueeze(img ,dim=0)
# read class_indict
try:
json_file = open("./class_indices.json","r")
class_indict = json.load(json_file)
except Exception as e:
print(e)
exit(-1)
# creat model
model = vgg(model_name="vgg16", num_classes=5)
# load model weigths
model_weigth_path = "./vgg16Net.pth"
model.load_state_dict(torch.load(model_weigth_path))
model.eval()
with torch.no_grad():
# predict class
output = torch.squeeze(model(img))
predict = torch.softmax(output, dim=0)
predict_cla = torch.argmax(predict).numpy()
print(class_indict[str(predict_cla)])
plt.show()
# 注意:上面只是使用一张图片作为测试用例,因此模型的泛化能力还不清楚,准确率也不清楚。
3.4 结果分析
训练结果:
train loss: 100%[->]1.102
[epoch 1] train_loss: 1.500 test_accuracy: 0.401
train loss: 100%[->]1.125
[epoch 2] train_loss: 1.333 test_accuracy: 0.401
train loss: 100%[->]1.289
[epoch 3] train_loss: 1.322 test_accuracy: 0.404
train loss: 100%[->]1.273
[epoch 4] train_loss: 1.305 test_accuracy: 0.407
train loss: 100%[->]1.540
[epoch 5] train_loss: 1.285 test_accuracy: 0.459
train loss: 100%[->]1.181
[epoch 6] train_loss: 1.190 test_accuracy: 0.473
train loss: 100%[->]0.895
[epoch 7] train_loss: 1.146 test_accuracy: 0.503
train loss: 100%[->]1.354
[epoch 8] train_loss: 1.104 test_accuracy: 0.522
train loss: 100%[->]1.542
[epoch 9] train_loss: 1.095 test_accuracy: 0.500
train loss: 100%[->]0.818
[epoch 10] train_loss: 1.058 test_accuracy: 0.566
train loss: 100%[->]0.641
[epoch 11] train_loss: 1.002 test_accuracy: 0.615
train loss: 100%[->]0.612
[epoch 12] train_loss: 0.923 test_accuracy: 0.657
train loss: 100%[->]0.489
[epoch 13] train_loss: 0.919 test_accuracy: 0.659
train loss: 100%[->]0.302
[epoch 14] train_loss: 0.864 test_accuracy: 0.668
train loss: 100%[->]0.596
[epoch 15] train_loss: 0.884 test_accuracy: 0.654
train loss: 100%[->]0.780
[epoch 16] train_loss: 0.836 test_accuracy: 0.615
train loss: 100%[->]0.979
[epoch 17] train_loss: 0.858 test_accuracy: 0.665
train loss: 100%[->]1.077
[epoch 18] train_loss: 0.820 test_accuracy: 0.695
train loss: 100%[->]1.745
[epoch 19] train_loss: 0.785 test_accuracy: 0.701
train loss: 100%[->]0.329
[epoch 20] train_loss: 0.796 test_accuracy: 0.712
train loss: 100%[->]1.188
[epoch 21] train_loss: 0.766 test_accuracy: 0.717
train loss: 100%[->]0.541
[epoch 22] train_loss: 0.766 test_accuracy: 0.714
train loss: 100%[->]0.743
[epoch 23] train_loss: 0.750 test_accuracy: 0.731
train loss: 100%[->]0.696
[epoch 24] train_loss: 0.763 test_accuracy: 0.736
train loss: 100%[->]0.657
[epoch 25] train_loss: 0.747 test_accuracy: 0.745
train loss: 100%[->]0.358
[epoch 26] train_loss: 0.722 test_accuracy: 0.731
train loss: 100%[->]0.653
[epoch 27] train_loss: 0.745 test_accuracy: 0.725
train loss: 100%[->]0.487
[epoch 28] train_loss: 0.728 test_accuracy: 0.750
train loss: 100%[->]1.140
[epoch 29] train_loss: 0.716 test_accuracy: 0.720
train loss: 100%[->]1.415
[epoch 30] train_loss: 0.689 test_accuracy: 0.717
Finished Training
4、打印出VGG 11层模型 每层特征图的尺寸,以及参数量。
主要使用torchsummary的summary来可视化模型
在python3环境下安装torchsummary,直接pip install torchsummary即可,包很小,很快就可以下载好。
使用下面代码可视化模型:
from torchsummary import summary
from model import vgg # 从我们前面编写的model.py中导入vgg模型
# 定义模型,mode_name="vgg11"
model_name = "vgg11"
model = vgg(model_name=model_name, num_classes=5, init_weights=True)
mdoel = model.cuda() # 将模型移动到GPU上
summary(model, (3,224,224)) # 打印出模型细节
summary详解:传入你的model以及model输入tensor的尺寸就可以了,因为在这里是做了一个前向的运算的。
from torchsummary import summary
summary(your_model, input_size=(channels, H, W))

任务9:使用PyTorch搭建ResNet网络
1、理解ResNet网络的原理
1.1 ResNet要解决的是什么问题?
ResNet要解决的是神经网络的“退化”问题。
什么是退化?
我们知道,对浅层网络逐渐叠加layers,模型在训练集和测试机上的性能会更好,因为模型的表现力更强了,可以对潜在的映射关系拟合得很好。而“退化”指的是,给网络叠加更多的层后,性能快速下降的情况。
训练集上的性能下降,可以排除过拟合,BN层的引入也基本上解决了plain net的梯度消失和梯度爆炸问题。如果不是过拟合以及梯度消失导致的,那原因是什么?
按道理,给网络叠加更多层,浅层网络的解空间是包含在深层网络的解空间中的,深层网络的解空间至少存在不差于浅层网络的解答,因为只需将增加的层变成恒等映射,其他层的权重原封不动copy浅层网络,就可以获得与浅层网络同样的性能。更好的解释明明存在,为什么找不到,找到的反而是更差的解?
显然,这是个优化问题,反映出结构相似的问题,其优化难度是不一样的,且难度的增长并不是线性的,越深的模型越难以优化。
有两种解决思路:
- 调整求解方法,比如更好的初始化,更好的梯度下降算法等
- 调整模型结构,让模型更易于优化——改变模型解耦实际上是该百年了error surface的形态。
ResNet的作者从后者入手,探求更好的模型,将堆叠几层的alyer称之为一个block,对于某个block,其可以拟合的函数为 F ( x ) F(x) F(x),如果期待的潜力ing设为 H ( x ) , H(x), H(x),与其让 F ( x ) F(x) F(x)直接学习潜在的映射,不如去学习残差 H ( x ) − x H(x)-x H(x)−x,即 F ( x ) : = H ( x ) − x F(x):=H(x)-x F(x):=H(x)−x,这样原本前向路径上就变成了 F ( x ) + x F(x)+x F(x)+x,用 F ( x ) + x F(x)+x F(x)+x来拟合 H ( x ) H(x) H(x)。作者认为这样可能更易于优化,因为相比于让 F ( x ) F(x) F(x)学习成恒等映射,让 F ( x ) F(x) F(x)学习称为0更加容易——后者通过L2正则化就可以轻松实现。这样,对于冗余的block,只需要 F ( x ) → 0 F(x)\rightarrow 0 F(x)→0就可以得到恒等映射,性能不减。
Residual Block的设计
F(x)+xF(x)+x构成的block称之为Residual Block,即残差块,如下图所示,多个相似的Residual Block串联构成ResNet。

一个残差块有2条路径F(x)F(x)和xx,F(x)F(x)路径拟合残差,不妨称之为残差路径,xx路径为identity mapping恒等映射,称之为”shortcut”。图中的⊕⊕为element-wise addition,要求参与运算的F(x)F(x)和xx的尺寸要相同。所以,随之而来的问题是,
- 残差路径如何设计?
- shortcut路径如何设计?
- Residual Block之间怎么连接?
在原论文中,残差路径可以大致分成2种,一种有bottleneck结构,即下图右中的1×11×1 卷积层,用于先降维再升维,主要出于降低计算复杂度的现实考虑,称之为“bottleneck block”,另一种没有bottleneck结构,如下图左所示,称之为“basic block”。basic block由2个3×33×3卷积层构成,bottleneck block由1×11×1

shortcut路径大致也可以分成2种,取决于残差路径是否改变了feature map数量和尺寸,一种是将输入xx原封不动地输出,另一种则需要经过1×11×1卷积来升维 or/and 降采样,主要作用是将输出与F(x)F(x)路径的输出保持shape一致,对网络性能的提升并不明显,两种结构如下图所示,
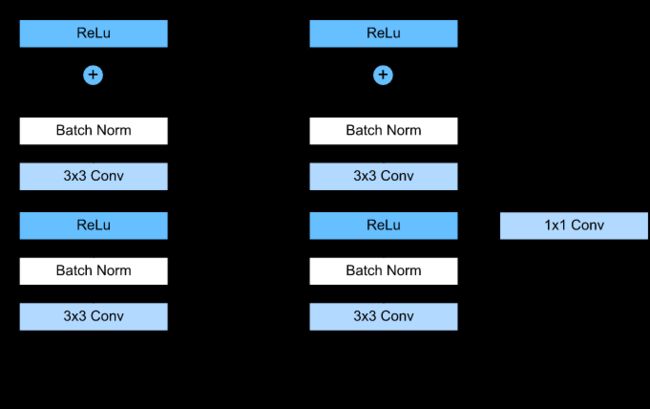
至于Residual Block之间的衔接,在原论文中,F(x)+xF(x)+x经过ReLUReLU后直接作为下一个block的输入xx。
对于F(x)F(x)路径、shortcut路径以及block之间的衔接,在论文Identity Mappings in Deep Residual Networks中有更进一步的研究,具体在文章后面讨论。
1.2 ResNet 网络结构
ResNet为多个Residual Block的串联,下面直观看一下ResNet-34与34-layer plain net和VGG的对比,以及堆叠不同数量Residual Block得到的不同ResNet。


ResNet的设计有如下特点:
- 与plain net相比,ResNet多了很多“旁路”,即shortcut路径,其首尾圈出的layers构成一个Residual Block;
- ResNet中,所有的Residual Block都没有pooling层,降采样是通过conv的stride实现的;
- 分别在conv3_1、conv4_1和conv5_1 Residual Block,降采样1倍,同时feature map数量增加1倍,如图中虚线划定的block;
- 通过Average Pooling得到最终的特征,而不是通过全连接层;
- 每个卷积层之后都紧接着BatchNorm layer,为了简化,图中并没有标出;
ResNet结构非常容易修改和扩展,通过调整block内的channel数量以及堆叠的block数量,就可以很容易地调整网络的宽度和深度,来得到不同表达能力的网络,而不用过多地担心网络的“退化”问题,只要训练数据足够,逐步加深网络,就可以获得更好的性能表现。
下面为网络的性能对比,

2、使用pytorch搭建ResNet网络模型
2.1 搭建残差卷据神经网络
model.py模型搭建
- 搭建BasicBlock与Bottlenet
参照上面这两个结构,基本上就可以得到下面的代码。
首先的BasicBlock,每一个BaiscBlock都有两个3✖3的卷积,kernel_size=3, padding=1, stride默认为1,在第一层Conv后添加ReLU激活函数,第二层Conv的激活函数需要等到与residual相加后才可以添加ReLU。
而对于Bottlenet,同样的,上面结构中显示,我们需要先连接一个1✖1的卷积(进行尺度缩小),继而连接3✖3的卷积(进行卷积操作),最后连接一个1✖1的卷积(尺度放大,至少是放大到原始输入相同)。
def conv3x3(in_channels, out_channels, stride=1):
return nn.Conv2d(
in_channels, # 输入深度(通道)
out_channels, # 输出深度
kernel_size=3, # 滤波器(过滤器)大小为3*3
stride=stride, # 步长,默认为1
padding=1, # 0填充最边缘的一层
bias=False # 不设置偏置
)
class BasicBlock(nn.Module):
expansion = 1 # 是对输出的深度的倍乘,等于1即忽略
def __init__(self, in_channels, out_channels, stride=1, downsample=None,):
super().__init__()
self.conv1 = conv3x3(in_channels, out_channels, stride) # 定义一个3*3卷积核
self.bn1 = nn.BatchNorm2d(out_channels) # 批标准化
self.relu = nn.ReLU(True) # 设置激活函数
self.conv2 = conv3x3(out_channels, out_channels)
self.bn2 = nn.BatchNorm2d(out_channels)
self.downsample = downsample # 这是论文种提到的shortcup操作
self.stride = stride
def forward(self, x):
residual = x # 获得上一层的输出
out = self.conv1(x)
out = self.bn1(out)
out = self.relu(out)
out = self.conv2(out)
out = self.bn2(out)
if self.downsample is not None: # 当short cut 存在的时候
residual = self.downsample(x)
# 我们将上一层的输出x输入进这个downsample所拥有的一些操作(卷积等)
# 简单说,这个目的就是为了应对上下层输出输入深度不一致的问题
out += residual
out = self.relu(out)
return out
class Bottleneck(nn.Module):
# 由于bottleneck译为瓶颈,所以我们这里就称它为瓶颈块
expansion = 4
# 若我们输入深度为64,那么扩张4倍后就变为了256
# 其目的在于使得当前块的输出深度与下一个块的输入深度保持一直
# 那么为什么是4呢?这是因为再设计网络的时候就规定了的
def __init__(self, in_channels, out_channels, stride=1, downsample=None):
super().__init__()
self.conv1 = nn.Conv2d(in_channels, out_channels, kernel_size=1, bias=False)
self.bn1 = nn.BatchNorm2d(out_channels)
# 这是1*1卷积层,是为了降维,把输出深度降到与3*3卷积层的输入深度一致
self.conv2 = conv3x3(out_channels, out_channels)
self.bn2 = nn.BatchNorm2d(out_channels)
# 这层3*3卷积层的channels是下面的_make_layers中的第二个参数规定的
self.cnv3 = nn.Conv2d(out_channels, out_channels*self.expansion, kernel_size=1, bias=False)
self.bn3 = nn.BatchNorm2d(out_channels*self.expansion)
# 这层1*1卷积层,是在升维,4倍的升
self.relu = nn.ReLU(True)
self.downsample = downsample
self.stride = stride
def forward(self, x):
residual = x
out = self.conv1(x)
out = self.bn1(out)
out = self.relu(out) # 连接一个激活函数
out = self.conv2(out)
out = self.bn2(out)
out = self.relu(out)
out = self.conv3(out)
out = self.bn3(out)
if self.downsample is not None:
residual = self.downsample(x)
out += residual
out = self.relu(out)
return out
- ResNet(nn.Module)
ResNet 共有五个阶段,其中第一阶段为一个 7*7 的卷积,stride = 2,padding = 3,然后经过 BN、ReLU 和 maxpooling(图中红色框中的部分),此时特征图的尺寸已成为输入的 1/4(经过了两次stride=2操作)。
接下来是四个阶段,也就是代码中 layer1,layer2,layer3,layer4。这里用 _make_layer 函数产生四个 Layer,需要用户输入每个 layer 的 block 数目( 即layers列表 )以及采用的 block 类型(基础版 BasicBlock 还是 Bottleneck 版)
_make_layer 方法的第一个输入参数 block 选择要使用的模块是 BasicBlock 还是 Bottleneck 类,第二个输入参数 planes 是该模块的输出通道数,第三个输入参数 blocks 是每个 blocks 中包含多少个 residual 子结构。
class ResNet(nn.Module):
"""
ResNet主体部分实现
"""
def __init__(self, block, layers, num_classes=10, include_top=True):
"""
初始化模块
:param block: 为上边的基础块BasicBlock或瓶颈块Bottleneck,但它其实就是一个对象
:param layers: 每个大layers中的block个数,设为blocks更好,但实际上每一个block实际上也是一些小layer
:param num_classes:表示最终分类的种类数
:param include_top:为了以后在ResNet基础上搭建更加复杂的网络。
let you select if you want the final dense layers or not.
:return:
"""
super(ResNet, self).__init__()
self.include_top = include_top
self.in_channels = 64 # 输入深度为64,我认为把这个理解为每个残差块的输入深度最好
self.conv1 = nn.Conv2d(3, 64, kernel_size=7, stride=2, padding=3, bias=False)
# 输入深度为3(正好是彩色图片的三个通道),输出深度为64,滤波器为7*7,步长为2,填充3层,特征图缩小1/2
# 因为stride=2,在计算输出特征图尺寸的时候stride放在分母位置上,所以stride=2时候,特征图缩小1/2
self.bn1 = nn.BatchNorm2d(64)
self.relu = nn.ReLU(inplace=True) # 设置激活函数
self.maxpool = nn.MaxPool2d(kernel_size=3, stride=2, padding=1) # 最大池化
# 再经过最大池化后,特征图的尺寸已称为输入的1/4
# 下面的每一个layer都是一个大layer
# 并且第二个参数是残差块中3*3卷积层的输入输出深度
self.layer1 = self._make_layer(block, 64, layers[0]) # 特征图大小不变
self.layer2 = self._make_layer(block, 128, layers[1], stride=2) # 特征图缩小1/2
self.layer3 = self._make_layer(block, 256, layers[2], stride=2)
self.layer4 = self._make_layer(block, 512, layers[3], stride=2)
# 这里只设置了4个大layer,是原论文设计网络时规定的,我们也可以视情况自己网上加
# 这里可以把4个大layer和上面的一起看成是5个阶段。
if self.include_top:
# AdaptiveAvgPool2d自适应平均池化-->只需要输入 自适应平均池化后的特征图大小即可,其他像kernel_size,stride的不用输入
# self.avgpool = nn.AvgPool2d(7, stride=1) # 平均池化,滤波器为7*7,步长为1,特征图大小变为1*1
# self.fc = nn.Linear(512*block.expansion, num_classes) # 全连接层
self.avgpool = nn.AdaptiveAvgPool2d((1, 1)) # output size = (1, 1)
self.fc = nn.Linear(512 * block.expansion, num_classes)
# 这里进行的是网络的参数初始化,可以看出卷积层和批标准化层的初始化方法是不一样的
for m in self.modules():
# self.modules()采用深度优先遍历的方式,存储了网络的所有模块,包括本身和儿子
if isinstance(m, nn.Conv2d):
nn.init.kaiming_normal_(m.weight, mode="fan_out", nonlinearity="relu")
# kaiming_normal_:初始化(这里是n.init初始化函数的源码,有好几种初始化方法)
# 可能在其他的博客中是使用kaiming_normal(),
# 但是好像新版的torch使用kaiming_normal()会爆warning,并提醒你使用kaiming_normal_()
elif isinstance(m,nn.BatchNorm2d):
nn.init.constant_(m.weight, 1)
nn.init.constant_(m.bias, 0)
def _make_layer(self, block, out_channels, blocks, stride=1):
# 这里的blocks就是该大layer中的残差块数
downsample = None # shortcut内部的跨层实现
if stride != 1 or self.in_channels != out_channels * block.expansion:
# 判断步长是否为1,判断当前块的输入深度和当前卷积层深度的乘以残差块的扩张
downsample = nn.Sequential(
nn.Conv2d(self.in_channels, out_channels*block.expansion, kernel_size=1, stride=stride, bias=False),
nn.BatchNorm2d(out_channels*block.expansion)
)
# 一旦判断条件成立,那么给downsample赋予一层1*1卷积层和一批标准池化层。并且这一步将伴随这特征图缩小1/2
# 而为何要在shortcut中再进行卷积操作呢?是因为再残差块之间,比如
layers = []
layers.append(block(self.in_channels, out_channels, stride, downsample))
# block()生成上面定义的基础快和瓶颈块的对象,并将downsample传递给block
self.in_channels = out_channels * block.expansion # 改变下面的残差块的输入深度
# 这使得该阶段下面的blocks-1个block,即下面想你换内构造的block与下一阶段的第一个block在输入深度上是相同的。
for i in range(1, blocks): # 这里面的所有block
layers.append(block(self.in_channels, out_channels))
return nn.Sequential(*layers) # 这里表示将layers中所有的block按顺序拼接在一起
def forward(self, x):
out = self.conv1(x)
out = self.bn1(out)
out = self.relu(out)
out = self.maxpool(out)
out = self.layer1(out)
out = self.layer2(out)
out = self.layer3(out)
out = self.layer4(out)
if self.include_top:
out = self.avgpool(out)
out = torch.flatten(out, 1)
# out = out.view(out.size(0), -1) # 将原来的多维输出拉回一维,和使用torch.flatten()是一样的效果
out = self.fc(out)
return out
- ResNet18, ResNet34, ResNet50, ResNet101, ResNet152搭建
根据原论文中提供的网络结构,我们搭建如下的几种残差神经网络
__all__ = ['ResNet','resnet18','resnet34','resnet50','resnet101','resnet152']
# 预训练模型下载地址
model_urls = {
'resnet18': 'https://s3.amazonaws.com/pytorch/models/resnet18-5c106cde.pth',
'resnet34': 'https://s3.amazonaws.com/pytorch/models/resnet34-333f7ec4.pth',
'resnet50': 'https://s3.amazonaws.com/pytorch/models/resnet50-19c8e357.pth',
'resnet101': 'https://s3.amazonaws.com/pytorch/models/resnet101-5d3b4d8f.pth',
'resnet152': 'https://s3.amazonaws.com/pytorch/models/resnet152-b121ed2d.pth',
}
def resnet18(pretrained=False, num_classes=10, include_top=True):
"""
定义ResNet18网络
:param pretrained: 若为True,则返回在ImageNet数据集上预先训练的模型
:param num_classes: 应该只包括两个参数,一个是输入x,一个是输出分类个数num_classes
:return:
"""
model = ResNet(BasicBlock, [2,2,2,2], num_classes, include_top)
if pretrained:
model.load_state_dict(model_zoo.load_url(model_urls['resnet18']))
return model
def resnet34(pretrained=False, num_classes=10,include_top=True):
model = ResNet(BasicBlock, [3,4,6,3], num_classes, include_top)
if pretrained:
model.load_state_dict(model_zoo.load_url(model_urls['resnet34']))
return model
def resnet50(pretrained=False, num_classes=10,include_top=True):
model = ResNet(Bottleneck,[3,4,6,3], num_classes,include_top)
if pretrained:
model.load_state_dict(model_zoo.load_url(model_urls['resnet50']))
return model
def resnet101(pretrained=False, num_classes=10,include_top=True):
model = ResNet(Bottleneck, [3, 4, 23, 3], num_classes,include_top)
# block对象为 瓶颈块Bottleneck
# layers列表 [3,4,23,3]
# 这表示layer1、layer2、layer3、layer4分别由3、4、23、3个Bottleneck组成
if pretrained:
model.load_state_dict(model_zoo.load_url(model_urls['resnet101']))
return model
def resnet152(pretrained=False, num_classes=10,include_top=True):
model = ResNet(Bottleneck, [3, 8, 36, 3], num_classes,include_top)
# block对象为 瓶颈块Bottleneck
# layers列表 [3,8,36,3]
# 这表示layer1、layer2、layer3、layer4分别由3、8、36、3个Bottleneck组成
if pretrained:
model.load_state_dict(model_zoo.load_url(model_urls['resnet152']))
return model
这里可以直接调用上面的 ResNet 对象,输入 block 类型和 block 数目,这里可以看到 resnet18 和 resnet34 用的是 BasicBlock,因为此时网络还不深,不太需要考虑模型的效率,而当网络加深到 52,101,152 层时则有必要引入 Bottleneck 结构,方便模型的存储和计算。
另外是否加载预训练权重是可选的,具体就是调用 model_zoo 加载指定链接地址的序列化文件,反序列化为权重文件。
pretrained 参数默认是 False,**kwargs 可以将不定数量的参数传递给一个函数,对应的还有 *args,用于传递非键值对的可变数量的参数列表,而 **kwargs 允许将一个不定长度的键值对作为参数传递给一个函数。
如果参数 pretrained 是 True,那么会通过 model_zoo.py 中的 load_url 函数根据上面 model_urls 字典下载或导入相应的预训练模型。
最后用 model 的 load_state_dict 方法用预训练的模型参数来初始化你构建的网络结构,该方法有一个重要参数是 strict,默认值为 True,表示预训练模型的层和你的网络结构层严格对应相等(比如维度和层名)。
2.2 训练与测试
train.py
载入预训练模型方法有两种,一种直接在net = resnet34()中添加num_class参数如net = resnet34(num_class=5),
另外一种使用默认num_class再另外添加一个全连接层net.fc = nn.Linear(inchannel, 5)
from tkinter import Variable
import torch
import torch.nn as nn
from torchsummary import summary
from torchvision import transforms, datasets
import json
import os
import matplotlib.pyplot as plt
import torch.optim as optim
from model import resnet18, resnet34, resnet101
os.environ["CUDA_ViSIBLE_DEVICES"] = "0,2,3"
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
# print(device)
if __name__ == "__main__":
# 注意这里的Normalize的参数跟前几个模型不一样
data_transform = {
"train": transforms.Compose([transforms.RandomResizedCrop(224),
transforms.RandomHorizontalFlip(),
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])]),
"val": transforms.Compose([transforms.Resize(256), # 将最小边进行缩放
transforms.CenterCrop(224),
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])])}
data_root = os.getcwd()
image_path = data_root + "/flower_data/"
train_dataset = datasets.ImageFolder(root=image_path+"train",
transform=data_transform["train"])
train_num = len(train_dataset)
# {'daisy:0, 'dandelion':1, 'roses':2, 'sunflower':3, 'tulip':4}
flower_list = train_dataset.class_to_idx
cla_dict = dict((val, key) for key, val in flower_list.items())
# write divt into json file
json_str = json.dumps(cla_dict, indent=4)
with open("class_indices.json","w") as json_file:
json_file.write(json_str)
batch_size = 32 # 由于本人电脑配置较高,因此将batch_size调到了32
# shuffle=True随机打乱
train_loader = torch.utils.data.DataLoader(train_dataset,
batch_size=batch_size,
shuffle=True,
num_workers=2,
pin_memory=True)
# 按照上面相同的方法构建验证集
validate_dataset = datasets.ImageFolder(root=image_path+"val",
transform=data_transform["val"]
)
val_num = len(validate_dataset)
validate_loader = torch.utils.data.DataLoader(validate_dataset,
batch_size=batch_size,shuffle=True,
num_workers=2, # 为了加快训练速度,这里使用多线程方式读取数据集
pin_memory=True)
try:
net = resnet18()
except RuntimeError as exception:
if "out of memory" in str(exception):
print("WARNING: out of memory")
if hasattr(torch.cuda, "empty_cache"):
torch.cuda.empty_cache()
else:
raise exception
# 加载pretrained weights
model_weight_path = "./resnet18-pre.pth" # 保存训练后的权重路径
# missing_key, unexpected_keys = net.load_state_dict(torch.load(model_weight_path), strict=False)
inchannels = net.fc.in_features
net.fc = nn.Linear(inchannels,5)
net.to(device)
loss_function = nn.CrossEntropyLoss()
optimizer = optim.Adam(net.parameters(), lr=1e-4)
best_acc = 0.0
save_path = "./resNet18.pth"
for epoch in range(30):
# train
net.train()
running_loss = 0.0
for step, data in enumerate(train_loader, start=0):
images, labels = data
optimizer.zero_grad()
if hasattr(torch.cuda, "empty_cache"):
torch.cuda.empty_cache()
logits = net(images.to(device))
loss = loss_function(logits, labels.to(device))
loss.backward()
optimizer.step()
# print statistics
running_loss += loss.item()
# print train process
rate = (step + 1) / len(train_loader)
a = "*" * int(rate * 50)
b = "." * int((1 - rate) * 50)
print("\rtrain loss: {:^3.0f}%[{}->{}]{:.4f}".format(int(rate * 100), a, b, loss), end="")
print()
with torch.no_grad():
# validate
net.eval()
acc = 0.0 # accumulate accurate number / epoch
with torch.no_grad():
# validate
for val_data in validate_loader:
val_images, val_labels = val_data
outputs = net(val_images.to(device))
# loss = loss_function(outputs, test_labels)
predict_y = torch.max(outputs, dim=1)[1]
acc += (predict_y == val_labels.to(device)).sum().item()
val_accurate = acc / val_num
if val_accurate > best_acc:
best_acc = val_accurate
torch.save(net.state_dict(), save_path)
print('[epoch %d] train_loss: %.3f test_accuracy: %.3f' %
(epoch + 1, running_loss / (step+1), val_accurate))
print('Finished Training')
2.3 结果分析
结果如下:
train loss: 100%[**************************************************->]0.7879
[epoch 1] train_loss: 1.199 test_accuracy: 0.560
train loss: 100%[**************************************************->]0.8152
[epoch 2] train_loss: 1.006 test_accuracy: 0.684
train loss: 100%[**************************************************->]1.2782
[epoch 3] train_loss: 0.938 test_accuracy: 0.626
train loss: 100%[**************************************************->]0.7876
[epoch 4] train_loss: 0.880 test_accuracy: 0.662
train loss: 100%[**************************************************->]0.9382
[epoch 5] train_loss: 0.846 test_accuracy: 0.720
train loss: 100%[**************************************************->]0.6175
[epoch 6] train_loss: 0.790 test_accuracy: 0.654
train loss: 100%[**************************************************->]0.4659
[epoch 7] train_loss: 0.792 test_accuracy: 0.681
train loss: 100%[**************************************************->]1.1074
[epoch 8] train_loss: 0.753 test_accuracy: 0.739
train loss: 100%[**************************************************->]0.7651
[epoch 9] train_loss: 0.733 test_accuracy: 0.690
train loss: 100%[**************************************************->]0.6678
[epoch 10] train_loss: 0.713 test_accuracy: 0.728
train loss: 100%[**************************************************->]1.0876
[epoch 11] train_loss: 0.690 test_accuracy: 0.769
train loss: 100%[**************************************************->]0.6061
[epoch 12] train_loss: 0.686 test_accuracy: 0.769
train loss: 100%[**************************************************->]0.9724
[epoch 13] train_loss: 0.636 test_accuracy: 0.777
train loss: 100%[**************************************************->]0.5053
[epoch 14] train_loss: 0.620 test_accuracy: 0.780
train loss: 100%[**************************************************->]1.3497
[epoch 15] train_loss: 0.606 test_accuracy: 0.755
train loss: 100%[**************************************************->]0.7004
[epoch 16] train_loss: 0.603 test_accuracy: 0.788
train loss: 100%[**************************************************->]0.8017
[epoch 17] train_loss: 0.593 test_accuracy: 0.794
train loss: 100%[**************************************************->]0.6171
[epoch 18] train_loss: 0.572 test_accuracy: 0.742
train loss: 100%[**************************************************->]1.0117
[epoch 19] train_loss: 0.563 test_accuracy: 0.761
train loss: 100%[**************************************************->]1.0271
[epoch 20] train_loss: 0.574 test_accuracy: 0.802
train loss: 100%[**************************************************->]0.9583
[epoch 21] train_loss: 0.547 test_accuracy: 0.797
train loss: 100%[**************************************************->]0.6646
[epoch 22] train_loss: 0.505 test_accuracy: 0.832
train loss: 100%[**************************************************->]0.9166
[epoch 23] train_loss: 0.526 test_accuracy: 0.821
train loss: 100%[**************************************************->]0.0786
[epoch 24] train_loss: 0.507 test_accuracy: 0.849
train loss: 100%[**************************************************->]0.6085
[epoch 25] train_loss: 0.511 test_accuracy: 0.772
train loss: 100%[**************************************************->]0.3527
[epoch 26] train_loss: 0.486 test_accuracy: 0.827
train loss: 100%[**************************************************->]0.5823
[epoch 27] train_loss: 0.462 test_accuracy: 0.841
train loss: 100%[**************************************************->]0.4524
[epoch 28] train_loss: 0.484 test_accuracy: 0.846
train loss: 100%[**************************************************->]0.3210
[epoch 29] train_loss: 0.466 test_accuracy: 0.808
train loss: 100%[**************************************************->]0.3496
[epoch 30] train_loss: 0.424 test_accuracy: 0.830
Finished Training
3、打印出ResNet 18模型 每层特征图的尺寸,以及参数量
与可视化vgg11网络相同的操作,我们试着可视化resnet18,结果如下:(因为网络有点深,直接截图的话不清晰,所以将可视化后的网络结构上传到github上,方便查看。
resnet18的网络结构图
如果github打不开的话,那也可以凑合看下面这张截图(有点糊)

4、参考资料
[1] ResNet详解与分析
[2] Pytorch实现ResNet代码解析
[3] PyTorch实现ResNet亲身实践
[4] 使用pytorch搭建ResNet网络
任务10:使用PyTorch完成Fashion-MNIST分类
1、搭建4层卷积 + 2层全连接的分类模型
model.py
class FashionNet(nn.Module):
"""搭建识别Fashion MNIST数据集的网络"""
def __init__(self, in_channels, num_classes=10):
super(FashionNet, self).__init__()
# 搭建4层卷积 + 2层全连接的分类模型。
# 第一个卷积,原始特征图为1*28*28->64*26*26
self.conv1 = nn.Conv2d(in_channels,64, kernel_size=3, padding=1, stride=1)
self.bn1 = nn.BatchNorm2d(64)
# 第二个卷积
self.conv2 = nn.Conv2d(64, 128, kernel_size=3, stride=2, padding=1)
self.bn2 = nn.BatchNorm2d(128)
# 第三个卷积
self.conv3 = nn.Conv2d(128, 256, kernel_size=3, padding=1, stride=2)
self.bn3 = nn.BatchNorm2d(256)
# 第四个卷积
self.conv4 = nn.Conv2d(256, 512, kernel_size=3, padding=1, stride=1)
self.bn4 = nn.BatchNorm2d(512)
# 全连接层
self.fc1 = nn.Linear(512*5*5, 1000)
self.fc2 = nn.Linear(1000, 10)
self.relu = nn.ReLU(True)
self.maxpool = nn.MaxPool2d(kernel_size=2, stride=1, padding=0)
def forward(self, x):
x = self.conv1(x)
x = self.bn1(x)
x = self.relu(x)
x = self.maxpool(x)
x = self.conv2(x)
x = self.bn2(x)
x = self.relu(x)
x = self.maxpool(x)
x = self.conv3(x)
x = self.bn3(x)
x = self.relu(x)
x = self.maxpool(x)
x = self.conv4(x)
x = self.bn4(x)
x = self.relu(x)
x = self.maxpool(x)
x = torch.flatten(x, start_dim=1)
x = self.fc1(x)
x = self.relu(x)
x = self.fc2(x)
# x = F.log_softmax(x, dim=1)
return x
def fashionnet(num_classes=10):
return FashionNet(in_channels=1, num_classes=num_classes)
sumary可视化网络结构

2、在训练过程中记录下每个epoch的训练集精度和测试集精度
train.py
import torch.nn as nn
from torchvision import transforms
import os
import torch.optim as optim
import torch
from torchvision.datasets import FashionMNIST
from model import fashionnet
os.environ["CUDA_ViSIBLE_DEVICES"] = "0,2,3"
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
# print(device)
if __name__ == "__main__":
data_transform = {
"train": transforms.Compose([transforms.ToTensor(),
transforms.Normalize((0.5,), (0.5,))]),
"val": transforms.Compose([transforms.ToTensor(),
transforms.Normalize((0.5,), (0.5,))])}
root_path = os.getcwd()
image_path = root_path + "/data/FashionMNIST/FashionMNIST"
# 数据集准备
batch_size=128
train_dataset = FashionMNIST(root="./data/FashionMNIST",
train=True,
transform=data_transform["train"],
download=False)
train_loader =torch.utils.data.DataLoader(dataset=train_dataset,
batch_size=batch_size,
shuffle=True,
num_workers=4,
pin_memory=True)
train_num = len(train_dataset)
# 验证数据集
validate_dataset = FashionMNIST(root="./data/FashionMNIST",
train=False,
download=False,
transform=data_transform["val"])
validate_loader = torch.utils.data.DataLoader(dataset=validate_dataset,
batch_size=batch_size,
shuffle=True,
num_workers=4,
pin_memory=True)
val_num = len(validate_dataset)
# 加载模型
net = fashionnet()
# 挂载到GPU上
net.to(device)
# 再定义optimizer和loss_function
optimizer = optim.Adam(net.parameters(), lr=1e-4)
loss_function = nn.CrossEntropyLoss()
# 开始训练
best_acc = 0.0
save_path = "./FashionNet.pth"
epochs = 25
for epoch in range(epochs):
net.train()
running_loss = 0.0
for step, data in enumerate(train_loader):
images, labels = data
# 梯度清0
optimizer.zero_grad()
# 将神经网络的输出也挂到GPU上
outputs = net(images.to(device))
loss = loss_function(outputs, labels.to(device))
# 然后反向传播
loss.backward()
optimizer.step()
running_loss += loss.item()
# 打印训练过程
rate = (step + 1) / len(train_loader)
a = "*" * int(rate * 50)
b = "." * int((1 - rate) * 50)
print("\rtrain loss: {:^3.0f}%[{}->{}]{:.3f}".format(int(rate * 100), a, b, loss), end="")
# validate
net.eval()
acc_num = 0.0
# 开启no_grad()
with torch.no_grad():
for val_data in validate_loader:
val_images, val_labels = val_data
optimizer.zero_grad()
outputs = net(val_images.to(device))
predict_y = torch.max(outputs, dim=1)[1]
acc_num += (predict_y == val_labels.to(device)).sum().item()
val_accurate = acc_num / val_num
if val_accurate > best_acc:
best_acc = val_accurate
torch.save(net.state_dict(), save_path)
# 打印validate的信息
print('[epoch %d] train_loss: %.3f test_accuracy: %.3f' %
(epoch + 1, running_loss / (step), val_accurate))
print("Done!")
训练结果
train loss: 100%[**************************************************->]0.259[epoch 1] train_loss: 0.389 test_accuracy: 0.891
train loss: 100%[**************************************************->]0.152[epoch 2] train_loss: 0.250 test_accuracy: 0.900
train loss: 100%[**************************************************->]0.176[epoch 3] train_loss: 0.202 test_accuracy: 0.894
train loss: 100%[**************************************************->]0.217[epoch 4] train_loss: 0.165 test_accuracy: 0.914
train loss: 100%[**************************************************->]0.260[epoch 5] train_loss: 0.137 test_accuracy: 0.913
train loss: 100%[**************************************************->]0.118[epoch 6] train_loss: 0.113 test_accuracy: 0.917
train loss: 100%[**************************************************->]0.052[epoch 7] train_loss: 0.091 test_accuracy: 0.911
train loss: 100%[**************************************************->]0.120[epoch 8] train_loss: 0.078 test_accuracy: 0.909
train loss: 100%[**************************************************->]0.161[epoch 9] train_loss: 0.064 test_accuracy: 0.911
train loss: 100%[**************************************************->]0.037[epoch 10] train_loss: 0.056 test_accuracy: 0.912
train loss: 100%[**************************************************->]0.060[epoch 11] train_loss: 0.047 test_accuracy: 0.904
train loss: 100%[**************************************************->]0.021[epoch 12] train_loss: 0.037 test_accuracy: 0.912
train loss: 100%[**************************************************->]0.099[epoch 13] train_loss: 0.034 test_accuracy: 0.910
train loss: 100%[**************************************************->]0.025[epoch 14] train_loss: 0.038 test_accuracy: 0.920
train loss: 100%[**************************************************->]0.033[epoch 15] train_loss: 0.029 test_accuracy: 0.907
train loss: 100%[**************************************************->]0.056[epoch 16] train_loss: 0.027 test_accuracy: 0.919
train loss: 100%[**************************************************->]0.003[epoch 17] train_loss: 0.020 test_accuracy: 0.920
train loss: 100%[**************************************************->]0.079[epoch 18] train_loss: 0.033 test_accuracy: 0.922
train loss: 100%[**************************************************->]0.055[epoch 19] train_loss: 0.022 test_accuracy: 0.909
train loss: 100%[**************************************************->]0.013[epoch 20] train_loss: 0.019 test_accuracy: 0.911
train loss: 100%[**************************************************->]0.054[epoch 21] train_loss: 0.019 test_accuracy: 0.921
train loss: 100%[**************************************************->]0.022[epoch 22] train_loss: 0.019 test_accuracy: 0.914
train loss: 100%[**************************************************->]0.053[epoch 23] train_loss: 0.019 test_accuracy: 0.922
train loss: 100%[**************************************************->]0.045[epoch 24] train_loss: 0.019 test_accuracy: 0.921
train loss: 100%[**************************************************->]0.009[epoch 25] train_loss: 0.021 test_accuracy: 0.918
Done!
任务11:人脸关键点检测
1、怎么加载和保存模型
这里主要有三个核心参数:
- torch.save():将序列化的对象保存到硬盘。它还利用了python的
pickle来实现序列化。模型、张量以及字典都可以用该函数进行保存; - torch.load:采用
pickle将反序列化的对象从存储中加载进来。 - torch.nn.Module.load_state_dict:采用一个反序列化的
state_dict加载一个模型的参数字典。
2、什么是状态字典(state_dict)
在pytorch中,一个模型(torch.nn.Module)的可学习参数(也就是权重和偏置值)是包含在模型参数(model.paramaters())
中的,一个状态字典就是一个简单的python的字典,其键值对是对每一个网络层和其对应的参数张量。模型的状态字典值包含带有可学习参数的网络层(比如卷积层,全连接层等)和注册的缓存(batchnorm和running_mean)。优化器对象(torch.optim)也是同样有一个状态字典,包含优化器状态的信息以及使用的超参数。
由于状态字典也是python的字典,因此对pytorch模型和优化器的保存,更新,替换,回复都很容易实现。
3、预测时加载和保存模型(推荐)
- 保存模型(其实只保存了模型的可学习参数)
torch.save(model.state_dict, path)
- 加载的代码
model = YourModel(*args, **kwargs)
mode.load_state_dict(torch.load(path))
model.eval() # 开始validate
通常会用 .pt 或者 .pth 后缀来保存模型。
当需要为预测保存一个模型的时候,只需要保存训练模型的可学习参数即可。采用torch.save()来保存模型的状态字典的做法可以更方柏霓快捷地加载模型。通常会用.pth或者.pt后缀来保存模型。
记住:
1、在进行预测之前,必须调用model.eval()来讲dropout和batch normalization层设置为验证模型,否则,只会生成前后不一致地预测结果。
2、load_state_dict()方法必须传入一个字典对象,而不是对象的保存路径,也就是说必须反序列化字典对象,然后再调用该方法,也是例子中的torch.load(),而不是直接,model.load_state_dict(path)
4、使用自己搭建的卷积+全连接网络的训练结果:
model.py
def maxpool2x2():
return nn.MaxPool2d(
kernel_size=2,
padding=0,
stride=1
)
def conv3x3(in_channels, out_channels, stride=1):
return nn.Conv2d(
in_channels, # 输入深度(通道)
out_channels, # 输出深度
kernel_size=3, # 滤波器(过滤器)大小为3*3
stride=stride, # 步长,默认为1
padding=1, # 0填充最边缘的一层
bias=False # 不设置偏置
)
class FaceKeyPointsModel(nn.Module):
def __init__(self, in_channels, num_classes=8):
super(FaceKeyPointsModel, self).__init__()
self.in_channels = in_channels
# 第一层
self.layer1 = nn.Sequential(
nn.Conv2d(self.in_channels, 64, kernel_size=5, stride=2, padding=2, bias=False),
nn.BatchNorm2d(64),
nn.ReLU(True),
maxpool2x2()
)
# 第二层
self.layer2 = nn.Sequential(
conv3x3(64, 128, 2),
nn.BatchNorm2d(128),
nn.ReLU(True),
maxpool2x2()
)
# 第三层卷积
self.layer3 = nn.Sequential(
conv3x3(128, 256, 2),
nn.BatchNorm2d(256),
nn.ReLU(True),
maxpool2x2()
)
# 第四层卷积
self.layer4 = nn.Sequential(
conv3x3(256, 512, 2),
nn.BatchNorm2d(512),
nn.ReLU(True),
maxpool2x2()
)
# 全连接
self.layer5 = nn.Sequential(nn.Linear(512*5*5, 1000),
nn.ReLU(True))
self.layer6 = nn.Linear(1000, num_classes)
def forward(self, x):
x = self.layer1(x)
x = self.layer2(x)
x = self.layer3(x)
x = self.layer4(x)
# print(x.shape)
x = torch.flatten(x, start_dim=1)
x = self.layer5(x)
x = self.layer6(x)
return x
train.py
import os, sys, codecs, glob
from PIL import Image, ImageDraw
import numpy as np
import pandas as pd
import cv2
import torch
# torch.backends.cudnn.benchmark = False
import torchvision.models as models
import torchvision.transforms as transforms
from torchvision import datasets, models
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
from torch.autograd import Variable
from torch.utils.data.dataset import Dataset
from model import resnet18, FaceKeyPointsModel
import time
import torchvision
from sklearn.metrics import mean_absolute_error
os.environ["CUDA_ViSIBLE_DEVICES"] = "0,2,3"
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
def train(train_loader, model, criterion, optimizer, epoch):
model.train()
for i, (input, target) in enumerate(train_loader):
input = input.cuda(non_blocking=True).float()
target = target.cuda(non_blocking=True).float()
output = model(input)
loss = criterion(output, target)
optimizer.zero_grad()
torch.nn.utils.clip_grad_norm_(model.parameters(), 1.0)
loss.backward()
optimizer.step()
if i % 200 == 0:
print(loss.item())
def validate(val_loader, model):
model.eval()
val_feats = []
with torch.no_grad():
end = time.time()
for i, (input, target) in enumerate(val_loader):
input = input.cuda().float()
target = target.cuda().float()
output = model(input)
val_feats.append(output.data.cpu().numpy())
return val_feats
if __name__ == "__main__":
train_df = pd.read_csv("人脸关键点检测挑战赛_数据集/train.csv")
train_df = train_df.fillna(48)
train_img = np.load("人脸关键点检测挑战赛_数据集/train.npy")
test_img = np.load("人脸关键点检测挑战赛_数据集/test.npy")
train_datasets = FaceDatasets(train_img[:, :, :-500],
keypoints=train_df.values[:-500],
transform=data_transforms["train"],
)
validate_datasets = FaceDatasets(train_img[:, :, -500:],
keypoints=train_df.values[-500:],
transform=data_transforms['val'],
)
train_loader = torch.utils.data.DataLoader(train_datasets,
batch_size=batch_size,
shuffle=True,
num_workers=3,
pin_memory=True
)
validate_loader = torch.utils.data.DataLoader(validate_datasets,
batch_size=batch_size,
shuffle=False,
num_workers=3,
pin_memory=True
)
net = FaceKeyPointsModel(in_channels=3, num_classes=8)
criterion = nn.MSELoss().cuda()
optimizer = torch.optim.Adam(net.parameters(), 1e-3)
scheduler = optim.lr_scheduler.StepLR(optimizer, step_size=10, gamma=0.85)
best_acc = 0.0
for epoch in range(10):
print('Epoch: ', epoch)
train(train_loader, net, criterion, optimizer, epoch)
val_feats = validate(validate_loader, net)
scheduler.step()
val_feats = np.vstack(val_feats) * 96
print('Val', mean_absolute_error(val_feats, train_df.values[-500:]))
结果
Epoch: 0
0.6472401022911072
Val 9.459882254012292
Epoch: 1
0.016693785786628723
Val 4.437139231219895
Epoch: 2
0.004081512801349163
Val 3.8498797871725197
Epoch: 3
0.002172782551497221
Val 3.227288646108359
Epoch: 4
0.002038501901552081
Val 3.2114947169274934
Epoch: 5
0.0021994602866470814
Val 3.5047704920275518
Epoch: 6
0.002044716849923134
Val 3.639293635908415
Epoch: 7
0.002928667701780796
Val 3.0777315674539083
Epoch: 8
0.002490787301212549
Val 3.0581620042799473
Epoch: 9
0.0019577781204134226
Val 5.478847382790466
5、使用ResNet18进行人脸关键点检测
train.py
use_gpu = torch.cuda.is_available()
class FaceDatasets(Dataset):
def __init__(self, img, keypoints, transform=None):
self.img = img
self.transform = transform
self.keypoints = keypoints
def __getitem__(self, index):
img = Image.fromarray(self.img[:, :, index]).convert("RGB")
if self.transform is not None:
img = self.transform(img)
return img, self.keypoints[index] / 96.0
def __len__(self):
return self.img.shape[-1]
def train(train_loader, model, criterion, optimizer, epoch):
model.train()
for i, (input, target) in enumerate(train_loader):
input = input.cuda(non_blocking=True).float()
target = target.cuda(non_blocking=True).float()
output = model(input)
loss = criterion(output, target)
optimizer.zero_grad()
torch.nn.utils.clip_grad_norm_(model.parameters(), 1.0)
loss.backward()
optimizer.step()
if i % 200 == 0:
print(loss.item())
def validate(val_loader, model):
model.eval()
val_feats = []
with torch.no_grad():
end = time.time()
for i, (input, target) in enumerate(val_loader):
input = input.cuda().float()
target = target.cuda().float()
output = model(input)
val_feats.append(output.data.cpu().numpy())
return val_feats
if __name__ == "__main__":
train_df = pd.read_csv("人脸关键点检测挑战赛_数据集/train.csv")
train_df = train_df.fillna(48)
train_img = np.load("人脸关键点检测挑战赛_数据集/train.npy")
test_img = np.load("人脸关键点检测挑战赛_数据集/test.npy")
batch_size = 128
data_transforms = {
'train': transforms.Compose([
# 随机在图像上裁剪出224*224大小的图像
transforms.RandomResizedCrop(224),
# 将图像随机翻转
transforms.RandomHorizontalFlip(),
# 将图像数据,转换为网络训练所需的tensor向量
transforms.ToTensor(),
# 图像归一化处理
# 个人理解,前面是3个通道的均值,后面是3个通道的方差
# transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])
]),
'val': transforms.Compose([
transforms.Resize(256),
transforms.CenterCrop(224),
transforms.ToTensor(),
# transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])
]),
}
train_datasets = FaceDatasets(train_img[:, :, :-500],
keypoints=train_df.values[:-500],
transform=data_transforms["train"],
)
validate_datasets = FaceDatasets(train_img[:, :, -500:],
keypoints=train_df.values[-500:],
transform=data_transforms['val'],
)
train_loader = torch.utils.data.DataLoader(train_datasets,
batch_size=batch_size,
shuffle=True,
num_workers=3,
pin_memory=True
)
validate_loader = torch.utils.data.DataLoader(validate_datasets,
batch_size=batch_size,
shuffle=False,
num_workers=3,
pin_memory=True
)
# 搭建网络
net = models.resnet18(pretrained=True)
# 将网络模型的各层的梯度更新置为False
for param in net.parameters():
param.requires_grad = False
# 修改网络模型的最后一个全连接层
# 获取最后一个全连接层的输入通道数
num_ftrs = net.fc.in_features
# 修改最后一个全连接层的的输出数为2
net.fc = nn.Linear(num_ftrs, 8)
# 是否使用gpu
if use_gpu:
model_ft = net.cuda()
criterion = nn.MSELoss().cuda()
optimizer = torch.optim.Adam(net.parameters(), 1e-3)
scheduler = optim.lr_scheduler.StepLR(optimizer, step_size=10, gamma=0.85)
best_acc = 0.0
for epoch in range(10):
print('Epoch: ', epoch)
train(train_loader, net, criterion, optimizer, epoch)
val_feats = validate(validate_loader, net)
scheduler.step()
val_feats = np.vstack(val_feats) * 96
print('Val', mean_absolute_error(val_feats, train_df.values[-500:]))
10个epochs的结果
使用resnet18网络的结果
Epoch: 0
0.7966814637184143
Val 35.717016200591
Epoch: 1
0.08880335092544556
Val 23.067112537300595
Epoch: 2
0.06346835941076279
Val 16.61725554367755
Epoch: 3
0.045638248324394226
Val 14.24792686296431
Epoch: 4
0.03386169672012329
Val 12.661923010819843
Epoch: 5
0.027442481368780136
Val 11.616523916318673
Epoch: 6
0.02400122955441475
Val 10.580833553860035
Epoch: 7
0.018101878464221954
Val 9.782165881970197
Epoch: 8
0.01734195277094841
Val 9.15092196332844
Epoch: 9
0.01462375558912754
Val 8.583864261148884
任务12:使用PyTorch搭建对抗生成网络
1、GAN理论
1.1 GAN的直观理解
GAN中包含“对抗”一词,即需要对抗的双方,生成器作为乙方和判别器作为另外一方,二者进行博弈。
1.2 鉴别器
GAN中的鉴别器只是一个分类器。它试图将真实数据与生成器创建的数据区分开来。它可以使用适合其分类数据类型的其他网络架构。
1.3鉴别器训练数据
判别器的训练数据有两个来源:
- 真实数据实例,例如人物的真实照片。鉴别器子啊训练期间使用这些实例作为正例。
- 生成器创建的假数据实例。判别器在训练期间使用这些实例作为反例。
训练鉴别器:
鉴别器连接到两个损失函数。在判别器训练期间,判别器忽略生成器,只使用判别器损失,我们在生成器训练期间使用生成器损失。
在判别器训练期间:
-
- 判别器对生成器的真实数据和假数据进行分类。
- 判别器损失惩罚函数将真实实例错误分类为假或假实例为真实。
- 判别器通过判别器网络的判别器损失的反向传播来更新其权重。
1.4生成器
GAN的生成器部分通过结合来自判别器的反馈来学习创建假数据。它学习让盘背鳍将其输出分类为真实的。
生成器训练需要生成器和判别器之间。训练生成器的GAN部分包括:
-
- 随机输入
- 生成器网络,将随机输入转换为数据实例
- 鉴别器网络,对生成的数据进行分类
- 鉴别器输出
- 判别器损失,由于未能欺骗判别器而惩罚生成器。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-oYwuMD7t-1638104272972)(https://developers.google.com/machine-learning/gan/images/gan_diagram_generator.svg)]图 1:生成器训练中的反向传播。
1.5随机输入
神经网络需要某种形式的输入,筒仓我们输入我们想要做的事情的数据,比如我们想要分类或做出预测的实例。但是我们使用什么作为输出全新数据实例的网络的输入呢?
在最基本的形式中,GAN将随机噪声作为输入然后,生成器将此噪声转换为有意义的输出。通过引入噪声,我们可以让GAN产生各种各样的数据,从目标分布的不同位置采样。实验表面那个,噪声的分布并不重要,因此我们可以选择易于从中采样的东西,例如均匀分布,为了方便期间,采样噪声的空间的维度筒仓小于输出空间的维度。
1.6 使用鉴别器训练生成器
为了训练神经网络,我们改变网络的权重以减少其输出的错误或损失,然而,在我们的GAN中,生成器与我们试图影响的损失没有直接联系。生成器输入鉴别器网络,鉴别器产生我们试图影响的输出。生成器损失惩罚生成器判别器网络分类为假的样本。
这个额外的网络快必须包含在反向传播中,反向传播通过计算权重对输出的影响在正确的方向上调整权重——如果改变权重,输出将如何变化。但是生成器权重的影响取决于它输入的鉴别器权重的影响,所以反向传播从输出开始,然后通过鉴别器流回判别器。
同时,我们不希望判别器在生成器训练期间发生变化,试图击中移动的目标会使生成器的难题变得更加困难。
因此,我们使用以下过程训练生成器;
1、采用随机噪声
2、从采样的随机噪声生成生成器的输出
3、获取生成器输出的鉴别器“真实”或“虚假”分类
4、计算鉴别器分类的损失
5、通过鉴别器和生成器进行反向传播以获得梯度
2、DCGAN
卷积神经网络在监督学习中的各项指标都有很好的表现,但是在无监督领域,却比较少,本节介绍的算法将监督学习中的CNN与无监督学习中的GAN结合到了一起。
在非CNN条件下,LAPGAN在图像分辨率提升领域也取得了好的效果。
与其将DCGAN堪称是CNN的扩展,不如将器看成GAN的扩展到CNN领域。
GAN无需特定的coss function的优势和学习过程也可以学习到好的特征表示,但是GNA训练起来不稳定,经常会使得生成器产生没有意义的输出。
而该DCGAN的贡献为:
- 为CNN的网络拓扑结构设置了一系列的限制来使得它可以稳定的训练
- 使用到的特征表示来进行图像分类,得到比较好的效果来验证生成图像的特征表示的表达能力
- 对GAN学习到的filter进行了定型的分析
- 展示了生成的特征表示的向量的计算特性。
模型结构
2.1 模型结构需要做如下几点变化
- 将pooling层的convolutions代替,其中,在discriminator 上用strided convolutions代替,在generor上用fractional-strided convolutions代替。
- 在generator和discriiminator上都使用batchnorm
- 解决初始化差的问题
- 帮助梯度传播到每一层
- 防止generator把所有的样本都收敛到同一个点
- 直接把BN应用到所有层会导致样本震荡和模型不稳定,通过在generator输出层和discriminator输入层不采用BN可以防止这种现象。
- 移除全连接层
- global pooling增加了模型的稳定性,但是伤害了收敛速度
- 在generator的除了输出层外的所有层使用ReLu,在输出层采用tanh
- 在discriminator的所有层上使用LeakyReLU。
2.2 DCGAN的网络结构如下:

3、使用DCGAN生成任务11中的人脸
3.1 代码脚本参数介绍
- nz 初始噪声向量的大小(Szie of latent z vector)
- ngf 生成网络中基础的feature数目(随着网络层数增加,feature数目翻倍)
- ndf 判别网络中基础feature数目(随着网络层数增加,feature数目翻倍)
- niter 网络训练过程中epoch数目
- beta1 使用Adam优化算法张的 β 1 \beta_1 β1参数值
3.2 模型代码
# 定义生成器网络G
class NetG(nn.Module):
def __init__(self, ngf, nz):
super(NetG, self).__init__()
# layer1输入的是一个100x1x1的随机噪声, 输出尺寸(ngf*8)x4x4
self.layer1 = nn.Sequential(
nn.ConvTranspose2d(nz, ngf * 8, kernel_size=4, stride=1, padding=0, bias=False),
nn.BatchNorm2d(ngf * 8),
nn.ReLU(inplace=True)
)
# layer2输出尺寸(ngf*4)x8x8
self.layer2 = nn.Sequential(
nn.ConvTranspose2d(ngf * 8, ngf * 4, 4, 2, 1, bias=False),
nn.BatchNorm2d(ngf * 4),
nn.ReLU(inplace=True)
)
# layer3输出尺寸(ngf*2)x16x16
self.layer3 = nn.Sequential(
nn.ConvTranspose2d(ngf * 4, ngf * 2, 4, 2, 1, bias=False),
nn.BatchNorm2d(ngf * 2),
nn.ReLU(inplace=True)
)
# layer4输出尺寸(ngf)x32x32
self.layer4 = nn.Sequential(
nn.ConvTranspose2d(ngf * 2, ngf, 4, 2, 1, bias=False),
nn.BatchNorm2d(ngf),
nn.ReLU(inplace=True)
)
# layer5输出尺寸 3x96x96
self.layer5 = nn.Sequential(
nn.ConvTranspose2d(ngf, 3, 5, 3, 1, bias=False),
nn.Tanh()
)
# 定义NetG的前向传播
def forward(self, x):
out = self.layer1(x)
out = self.layer2(out)
out = self.layer3(out)
out = self.layer4(out)
out = self.layer5(out)
# out = out.squeeze(-1)
return out
# 定义鉴别器网络D
class NetD(nn.Module):
def __init__(self, ndf):
super(NetD, self).__init__()
# layer1 输入 3 x 96 x 96, 输出 (ndf) x 32 x 32
self.layer1 = nn.Sequential(
nn.Conv2d(3, ndf, kernel_size=5, stride=3, padding=1, bias=False),
nn.BatchNorm2d(ndf),
nn.LeakyReLU(0.2, inplace=True)
)
# layer2 输出 (ndf*2) x 16 x 16
self.layer2 = nn.Sequential(
nn.Conv2d(ndf, ndf * 2, 4, 2, 1, bias=False),
nn.BatchNorm2d(ndf * 2),
nn.LeakyReLU(0.2, inplace=True)
)
# layer3 输出 (ndf*4) x 8 x 8
self.layer3 = nn.Sequential(
nn.Conv2d(ndf * 2, ndf * 4, 4, 2, 1, bias=False),
nn.BatchNorm2d(ndf * 4),
nn.LeakyReLU(0.2, inplace=True)
)
# layer4 输出 (ndf*8) x 4 x 4
self.layer4 = nn.Sequential(
nn.Conv2d(ndf * 4, ndf * 8, 4, 2, 1, bias=False),
nn.BatchNorm2d(ndf * 8),
nn.LeakyReLU(0.2, inplace=True)
)
# layer5 输出一个数(概率)
self.layer5 = nn.Sequential(
nn.Conv2d(ndf * 8, 1, 4, 1, 0, bias=False),
nn.Sigmoid()
)
# 定义NetD的前向传播
def forward(self, x):
out = self.layer1(x)
out = self.layer2(out)
out = self.layer3(out)
out = self.layer4(out)
out = self.layer5(out)
out = out.view(64)
# out = out.squeeze(-1)
return out
3.3 训练代码
import argparse
import torch
import torchvision
import torchvision.utils as vutils
import torch.nn as nn
from random import randint
from model import NetD, NetG
import pandas as pd
import numpy as np
from torch.utils.data.dataset import Dataset
from PIL import Image
class FaceDatasets(Dataset):
def __init__(self, img, transform=None):
self.img = img
self.transform = transform
def __getitem__(self, index):
img = Image.fromarray(self.img[:, :, index]).convert('RGB')
if self.transform is not None:
img = self.transform(img)
return img
def __len__(self):
return self.img.shape[-1]
if __name__ == "__main__":
parser = argparse.ArgumentParser()
parser.add_argument('--batchSize', type=int, default=64)
parser.add_argument('--imageSize', type=int, default=96)
parser.add_argument('--nz', type=int, default=100, help='size of the latent z vector')
parser.add_argument('--ngf', type=int, default=64)
parser.add_argument('--ndf', type=int, default=64)
parser.add_argument('--epoch', type=int, default=500, help='number of epochs to train for')
parser.add_argument('--lr', type=float, default=0.0002, help='learning rate, default=0.0002')
parser.add_argument('--beta1', type=float, default=0.5, help='beta1 for adam. default=0.5')
# parser.add_argument('--data_path', default='data/', help='folder to train data')
parser.add_argument('--outf', default='imgs/', help='folder to output images and model checkpoints')
opt = parser.parse_args()
# 定义是否使用GPU
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
# 图像读入与预处理
transforms = torchvision.transforms.Compose([
# torchvision.transforms.Scale(opt.imageSize),
torchvision.transforms.ToTensor(),
torchvision.transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5)),
])
train_img = np.load("人脸关键点检测挑战赛_数据集/train.npy")
# 开始搭建train_loader和test_loader
datasets = FaceDatasets(train_img,
transform=transforms
)
dataloader = torch.utils.data.DataLoader(datasets,
batch_size=opt.batchSize,
shuffle=True,
num_workers=1,
drop_last=True,
pin_memory=True
)
netG = NetG(opt.ngf, opt.nz).to(device)
netD = NetD(opt.ndf).to(device)
criterion = nn.BCELoss()
optimizerG = torch.optim.Adam(netG.parameters(), lr=opt.lr, betas=(opt.beta1, 0.999))
optimizerD = torch.optim.Adam(netD.parameters(), lr=opt.lr, betas=(opt.beta1, 0.999))
label = torch.FloatTensor(opt.batchSize)
real_label = 1
fake_label = 0
for epoch in range(1, opt.epoch + 1):
for i, imgs in enumerate(dataloader):
# 固定生成器G,训练鉴别器D
optimizerD.zero_grad()
## 让D尽可能的把真图片判别为1
imgs = imgs.to(device)
output = netD(imgs)
# print(output.shape)
# print(output)
label.data.fill_(real_label)
label = label.to(device)
errD_real = criterion(output, label)
errD_real.backward()
## 让D尽可能把假图片判别为0
label.data.fill_(fake_label)
noise = torch.randn(opt.batchSize, opt.nz, 1, 1)
noise = noise.to(device)
fake = netG(noise) # 生成假图
output = netD(fake.detach()) # 避免梯度传到G,因为G不用更新
errD_fake = criterion(output, label)
errD_fake.backward()
errD = errD_fake + errD_real
optimizerD.step()
# 固定鉴别器D,训练生成器G
optimizerG.zero_grad()
# 让D尽可能把G生成的假图判别为1
label.data.fill_(real_label)
label = label.to(device)
output = netD(fake)
errG = criterion(output, label)
errG.backward()
optimizerG.step()
print('[%d/%d][%d/%d] Loss_D: %.3f Loss_G %.3f'
% (epoch, opt.epoch, i, len(dataloader), errD.item(), errG.item()))
vutils.save_image(fake.data,
'%s/fake_samples_epoch_%03d.png' % (opt.outf, epoch),
normalize=True)
torch.save(netG.state_dict(), '%s/netG_%03d.pth' % (opt.outf, epoch))
torch.save(netD.state_dict(), '%s/netD_%03d.pth' % (opt.outf, epoch))
3.4 结果分析
下面是训练了50个epoch的结果
[498/500][49/78] Loss_D: 0.018 Loss_G 7.421
[498/500][50/78] Loss_D: 0.015 Loss_G 7.651
[498/500][51/78] Loss_D: 0.011 Loss_G 7.058
[498/500][52/78] Loss_D: 0.114 Loss_G 5.318
[498/500][53/78] Loss_D: 0.066 Loss_G 7.454
[498/500][54/78] Loss_D: 0.039 Loss_G 7.673
[498/500][55/78] Loss_D: 0.009 Loss_G 8.330
[498/500][56/78] Loss_D: 0.010 Loss_G 8.439
[498/500][57/78] Loss_D: 0.009 Loss_G 8.173
[498/500][58/78] Loss_D: 0.006 Loss_G 8.076
[498/500][59/78] Loss_D: 0.025 Loss_G 8.596
[498/500][60/78] Loss_D: 0.006 Loss_G 8.543
[498/500][61/78] Loss_D: 0.021 Loss_G 7.424
[498/500][62/78] Loss_D: 0.016 Loss_G 7.556
[498/500][63/78] Loss_D: 0.013 Loss_G 7.664
[498/500][64/78] Loss_D: 0.128 Loss_G 4.290
[498/500][65/78] Loss_D: 0.076 Loss_G 7.579
[498/500][66/78] Loss_D: 0.021 Loss_G 8.278
[498/500][67/78] Loss_D: 0.014 Loss_G 9.213
[498/500][68/78] Loss_D: 0.025 Loss_G 9.044
[498/500][69/78] Loss_D: 0.032 Loss_G 7.167
[498/500][70/78] Loss_D: 0.008 Loss_G 7.057
[498/500][71/78] Loss_D: 0.026 Loss_G 7.060
[498/500][72/78] Loss_D: 0.035 Loss_G 8.350
[498/500][73/78] Loss_D: 0.023 Loss_G 8.420
[498/500][74/78] Loss_D: 0.009 Loss_G 8.109
[498/500][75/78] Loss_D: 0.024 Loss_G 7.367
[498/500][76/78] Loss_D: 0.011 Loss_G 7.643
[498/500][77/78] Loss_D: 0.006 Loss_G 7.988
[499/500][0/78] Loss_D: 0.007 Loss_G 8.018
[499/500][1/78] Loss_D: 0.018 Loss_G 7.004
[499/500][2/78] Loss_D: 0.009 Loss_G 7.817
[499/500][3/78] Loss_D: 0.013 Loss_G 7.081
[499/500][4/78] Loss_D: 0.020 Loss_G 7.179
[499/500][5/78] Loss_D: 0.005 Loss_G 8.094
[499/500][6/78] Loss_D: 0.005 Loss_G 8.244
[499/500][7/78] Loss_D: 0.028 Loss_G 6.780
[499/500][8/78] Loss_D: 0.024 Loss_G 6.450
[499/500][9/78] Loss_D: 0.013 Loss_G 7.475
[499/500][10/78] Loss_D: 0.005 Loss_G 8.474
[499/500][11/78] Loss_D: 0.052 Loss_G 6.240
[499/500][12/78] Loss_D: 0.019 Loss_G 5.750
[499/500][13/78] Loss_D: 0.025 Loss_G 6.575
[499/500][14/78] Loss_D: 0.056 Loss_G 5.961
[499/500][15/78] Loss_D: 0.043 Loss_G 7.514
[499/500][16/78] Loss_D: 0.013 Loss_G 7.867
[499/500][17/78] Loss_D: 0.012 Loss_G 8.728
[499/500][18/78] Loss_D: 0.035 Loss_G 7.416
[499/500][19/78] Loss_D: 0.008 Loss_G 6.760
[499/500][20/78] Loss_D: 0.015 Loss_G 6.649
[499/500][21/78] Loss_D: 0.042 Loss_G 6.345
[499/500][22/78] Loss_D: 0.028 Loss_G 6.747
[499/500][23/78] Loss_D: 0.012 Loss_G 7.803
[499/500][24/78] Loss_D: 0.012 Loss_G 7.767
[499/500][25/78] Loss_D: 0.007 Loss_G 7.714
[499/500][26/78] Loss_D: 0.004 Loss_G 8.186
[499/500][27/78] Loss_D: 0.038 Loss_G 6.955
[499/500][28/78] Loss_D: 0.010 Loss_G 7.156
[499/500][29/78] Loss_D: 0.051 Loss_G 5.225
[499/500][30/78] Loss_D: 0.048 Loss_G 5.354
[499/500][31/78] Loss_D: 0.022 Loss_G 6.570
[499/500][32/78] Loss_D: 0.054 Loss_G 8.233
[499/500][33/78] Loss_D: 0.035 Loss_G 8.219
[499/500][34/78] Loss_D: 0.016 Loss_G 8.438
[499/500][35/78] Loss_D: 0.005 Loss_G 8.135
[499/500][36/78] Loss_D: 0.002 Loss_G 9.578
[499/500][37/78] Loss_D: 0.004 Loss_G 8.173
[499/500][38/78] Loss_D: 0.012 Loss_G 8.107
[499/500][39/78] Loss_D: 0.015 Loss_G 7.444
[499/500][40/78] Loss_D: 0.005 Loss_G 8.061
[499/500][41/78] Loss_D: 0.017 Loss_G 6.954
[499/500][42/78] Loss_D: 0.019 Loss_G 6.287
[499/500][43/78] Loss_D: 0.016 Loss_G 6.538
[499/500][44/78] Loss_D: 0.014 Loss_G 7.311
[499/500][45/78] Loss_D: 0.009 Loss_G 7.332
[499/500][46/78] Loss_D: 0.026 Loss_G 6.767
[499/500][47/78] Loss_D: 0.011 Loss_G 7.127
[499/500][48/78] Loss_D: 0.098 Loss_G 4.589
[499/500][49/78] Loss_D: 0.095 Loss_G 8.252
[499/500][50/78] Loss_D: 0.015 Loss_G 9.481
[499/500][51/78] Loss_D: 0.041 Loss_G 9.096
[499/500][52/78] Loss_D: 0.071 Loss_G 5.714
[499/500][53/78] Loss_D: 0.028 Loss_G 6.818
[499/500][54/78] Loss_D: 0.031 Loss_G 7.822
[499/500][55/78] Loss_D: 0.014 Loss_G 8.693
[499/500][56/78] Loss_D: 0.005 Loss_G 8.379
[499/500][57/78] Loss_D: 0.012 Loss_G 8.405
[499/500][58/78] Loss_D: 0.007 Loss_G 8.244
[499/500][59/78] Loss_D: 0.005 Loss_G 8.474
[499/500][60/78] Loss_D: 0.004 Loss_G 8.355
[499/500][61/78] Loss_D: 0.020 Loss_G 7.482
[499/500][62/78] Loss_D: 0.007 Loss_G 7.151
[499/500][63/78] Loss_D: 0.016 Loss_G 6.854
[499/500][64/78] Loss_D: 0.008 Loss_G 8.016
[499/500][65/78] Loss_D: 0.016 Loss_G 7.516
[499/500][66/78] Loss_D: 0.014 Loss_G 7.006
[499/500][67/78] Loss_D: 0.009 Loss_G 7.264
[499/500][68/78] Loss_D: 0.013 Loss_G 6.936
[499/500][69/78] Loss_D: 0.010 Loss_G 7.508
[499/500][70/78] Loss_D: 0.047 Loss_G 7.965
[499/500][71/78] Loss_D: 0.010 Loss_G 8.324
[499/500][72/78] Loss_D: 0.014 Loss_G 7.879
[499/500][73/78] Loss_D: 0.024 Loss_G 7.046
[499/500][74/78] Loss_D: 0.039 Loss_G 7.221
[499/500][75/78] Loss_D: 0.068 Loss_G 5.925
[499/500][76/78] Loss_D: 0.016 Loss_G 5.851
[499/500][77/78] Loss_D: 0.066 Loss_G 8.415
[500/500][0/78] Loss_D: 0.004 Loss_G 9.285
[500/500][1/78] Loss_D: 0.007 Loss_G 9.458
[500/500][2/78] Loss_D: 0.004 Loss_G 8.646
[500/500][3/78] Loss_D: 0.002 Loss_G 8.730
[500/500][4/78] Loss_D: 0.019 Loss_G 8.497
[500/500][5/78] Loss_D: 0.576 Loss_G 1.100
[500/500][6/78] Loss_D: 3.014 Loss_G 30.766
[500/500][7/78] Loss_D: 9.210 Loss_G 11.615
[500/500][8/78] Loss_D: 0.094 Loss_G 6.488
[500/500][9/78] Loss_D: 0.239 Loss_G 10.471
[500/500][10/78] Loss_D: 0.179 Loss_G 9.458
[500/500][11/78] Loss_D: 0.132 Loss_G 7.258
[500/500][12/78] Loss_D: 0.225 Loss_G 9.965
[500/500][13/78] Loss_D: 0.121 Loss_G 8.422
[500/500][14/78] Loss_D: 0.121 Loss_G 8.303
[500/500][15/78] Loss_D: 0.159 Loss_G 9.212
[500/500][16/78] Loss_D: 0.029 Loss_G 9.878
[500/500][17/78] Loss_D: 0.475 Loss_G 3.423
[500/500][18/78] Loss_D: 0.222 Loss_G 6.371
[500/500][19/78] Loss_D: 0.464 Loss_G 16.022
[500/500][20/78] Loss_D: 0.003 Loss_G 19.539
[500/500][21/78] Loss_D: 0.009 Loss_G 19.039
[500/500][22/78] Loss_D: 0.234 Loss_G 17.381
[500/500][23/78] Loss_D: 0.098 Loss_G 12.499
[500/500][24/78] Loss_D: 0.018 Loss_G 9.746
[500/500][25/78] Loss_D: 0.065 Loss_G 12.957
[500/500][26/78] Loss_D: 0.048 Loss_G 11.633
[500/500][27/78] Loss_D: 0.013 Loss_G 9.563
[500/500][28/78] Loss_D: 0.019 Loss_G 10.093
[500/500][29/78] Loss_D: 0.049 Loss_G 9.958
[500/500][30/78] Loss_D: 0.100 Loss_G 8.828
[500/500][31/78] Loss_D: 0.050 Loss_G 8.025
[500/500][32/78] Loss_D: 0.062 Loss_G 9.774
[500/500][33/78] Loss_D: 0.054 Loss_G 9.882
[500/500][34/78] Loss_D: 0.094 Loss_G 8.264
[500/500][35/78] Loss_D: 0.019 Loss_G 8.648
[500/500][36/78] Loss_D: 0.068 Loss_G 8.179
[500/500][37/78] Loss_D: 0.146 Loss_G 8.455
[500/500][38/78] Loss_D: 0.032 Loss_G 7.480
[500/500][39/78] Loss_D: 0.038 Loss_G 9.552
[500/500][40/78] Loss_D: 0.031 Loss_G 8.429
[500/500][41/78] Loss_D: 0.082 Loss_G 9.073
[500/500][42/78] Loss_D: 0.015 Loss_G 9.603
[500/500][43/78] Loss_D: 0.014 Loss_G 9.182
[500/500][44/78] Loss_D: 0.020 Loss_G 8.341
[500/500][45/78] Loss_D: 0.080 Loss_G 7.722
[500/500][46/78] Loss_D: 0.017 Loss_G 7.004
[500/500][47/78] Loss_D: 0.170 Loss_G 10.867
[500/500][48/78] Loss_D: 0.008 Loss_G 9.795
[500/500][49/78] Loss_D: 0.061 Loss_G 8.462
[500/500][50/78] Loss_D: 0.013 Loss_G 8.625
[500/500][51/78] Loss_D: 0.014 Loss_G 7.732
[500/500][52/78] Loss_D: 0.018 Loss_G 7.420
[500/500][53/78] Loss_D: 0.050 Loss_G 7.003
[500/500][54/78] Loss_D: 0.057 Loss_G 8.231
[500/500][55/78] Loss_D: 0.022 Loss_G 8.112
[500/500][56/78] Loss_D: 0.034 Loss_G 8.053
[500/500][57/78] Loss_D: 0.091 Loss_G 7.240
[500/500][58/78] Loss_D: 0.017 Loss_G 7.240
[500/500][59/78] Loss_D: 0.072 Loss_G 6.420
[500/500][60/78] Loss_D: 0.056 Loss_G 7.908
[500/500][61/78] Loss_D: 0.006 Loss_G 8.397
[500/500][62/78] Loss_D: 0.030 Loss_G 7.351
[500/500][63/78] Loss_D: 0.017 Loss_G 7.349
[500/500][64/78] Loss_D: 0.008 Loss_G 8.668
[500/500][65/78] Loss_D: 0.015 Loss_G 7.215
[500/500][66/78] Loss_D: 0.062 Loss_G 7.021
[500/500][67/78] Loss_D: 0.029 Loss_G 7.464
[500/500][68/78] Loss_D: 0.054 Loss_G 8.439
[500/500][69/78] Loss_D: 0.016 Loss_G 8.463
[500/500][70/78] Loss_D: 0.035 Loss_G 7.721
[500/500][71/78] Loss_D: 0.105 Loss_G 10.029
[500/500][72/78] Loss_D: 0.230 Loss_G 7.834
[500/500][73/78] Loss_D: 0.011 Loss_G 6.331
[500/500][74/78] Loss_D: 0.017 Loss_G 6.939
[500/500][75/78] Loss_D: 0.028 Loss_G 7.227
[500/500][76/78] Loss_D: 0.043 Loss_G 7.918
[500/500][77/78] Loss_D: 0.086 Loss_G 7.293
效果一般!