基于Tensorflow的神经网络模型搭建——气温预测
基于Tensorflow的神经网络模型搭建
环境:
Anaconda3
python 3.8.10
TensorFlow 2.3.0
numpy 1.22.4
Pycharm 2022.1
文章目录
- 基于Tensorflow的神经网络模型搭建
-
- 回归问题预测
-
- 导包
- 读取文件
- 日期格式处理
- 特征可视化展示
- 数据预处理
- 基于Kras构建网络模型
-
- 构造网络模型
- 配置网络参数
- 调参
-
- kernel_initializer
- kernel_regularizer
- 模型预测
- 测试结果
回归问题预测
- Tensorflow2.x 版本中将使用大量的Keras的简介建模方法
导包
import tensorflow as tf
import numpy as np
import matplotlib.pyplot as plt
import datetime
import pandas as pd
from sklearn import preprocessing
from tensorflow.keras import layers
import tensorflow.keras
import warnings
warnings.filterwarnings('ignore')
------------------------------------------------------
# 忽略
import os
os.environ['TF_CPP_MIN_LOG_LEVEL'] = '2'
至于为什么加入忽略,这里不多赘述,想要研究到底为什么的小伙伴可以自行步入下面的链接
从源码求证tensorflow中os.environ"TF_CPP_MIN_LOG_LEVEL"]的值的含义
读取文件
文件如下,需要请自行下载:
链接:https://pan.baidu.com/s/1o0IyPFJNrurLRCUbji6_EA?pwd=knsw 提取码:knsw
tips:csv颜色插件如图,需要请自行搜索并应用

features = pd.read_csv('temps.csv')
features.head()
print('数据维度:', features.shape)
![]()
"""
表中数据说明:
year,month,day,week分别代表具体时间
temp_2:前天的最高温度
temp_1:昨天的最高温度
average:历史中,每一年平均最高温度值
actual:标签值,当天真实最高温度
friend:你哥们预测的
"""
日期格式处理
为方便时间数据的处理和展示等操作,这里使用 datetime 对其进行格式更改
import datetime
# 分别得到年、月、日
years = features['year']
months = features['month']
days = features['day']
# datetime格式
dates = [str(int(year)) + '-' + str(int(month)) + '-' + str(int(day)) for year, month, day in
zip(years, months, days)]
dates = [datetime.datetime.strptime(date, '%Y-%m-%d') for date in dates]
特征可视化展示
tips:
拿到自己的数据之后需要做的事:
1、数据处理
2、检查数据有无异常值
# 画图
plt.style.use('fivethirtyeight')
# 设置布局
fig, ((ax1, ax2), (ax3, ax4)) = plt.subplots(nrows=2, ncols=2, figsize=(10, 10))
fig.autofmt_xdate(rotation=45)
# 标签值
ax1.plot(dates, features['actual'])
ax1.set_xlabel('')
ax1.set_ylabel('Temperature')
ax2.set_title('Max Temp')
# 昨天
ax2.plot(dates, features['temp_1'])
ax2.set_xlabel('')
ax2.set_ylabel('Temperature')
ax2.set_title('Previous Max Temp')
# 前天
ax3.plot(dates, features['temp_2'])
ax3.set_xlabel('')
ax3.set_ylabel('Temperature')
ax3.set_title('Two Days Prior Max Temp')
# friend
ax4.plot(dates, features['friend'])
ax4.set_xlabel('')
ax4.set_ylabel('Temperature')
ax4.set_title('Friend Estimate')
plt.tight_layout(pad=2)
plt.show()

数据预处理
由于数据中 week 这一列的数据是字符串形式,需要对其进行预处理
# 独热编码
features = pd.get_dummies(features)
# features.head(5)
# 标签
labels = np.array(features['actual'])
# 在特征中去掉标签
features = features.drop('actual', axis=1)
# 名字单独保存
features_list = list(features.columns)
# 转换成合适格式
features = np.array(features)
input_features = preprocessing.StandardScaler().fit_transform(features)
print(input_features[0])
对于 input_features = preprocessing.StandardScaler().fit_transform(features) 这句话,需要包为 sklearn

基于Kras构建网络模型
构造网络模型
一些常用参数如下:
activation:激活函数选择,一般常用relu
kernel_initializer, bias_initializer:权重与偏置参数的初始化方法,有时候不收敛,换种初始化就好了
kernel_regularizer, bias_regularizer:要不要加入正则化
inputs:输入,自己指定 或 让网络模型自己选择
units:神经元个数
这里自己选择神经元个数,也可以根据输入特征来画图进行推导,hidden层自己选择适当添加

由于使用的是 Tensorflow2.x 所以只需要其中使用的每个Hidden有多少个神经元,输出有几个结果即可
# 按顺序构造神经元
model = tf.keras.Sequential()
model.add(layers.Dense(16))
model.add(layers.Dense(32))
model.add(layers.Dense(1))
其中,layers里有很多层的实现,如卷积层等等…,这里用的是全连接层
直达 2.3版本Tensorflow官方文档

配置网络参数
指定优化器和损失函数,并使用迭代的方式优化网络模型
model.compile(optimizer=tf.keras.optimizers.SGD(0.001),
loss='mean_squared_error')
model.fit(input_features, labels, validation_split=0.25, epochs=10, batch_size=128)
解释_fit函数参数:
1、x 2、y
3、自行切割出25%的数据作为验证集
4、迭代次数
5、每次迭代样本数
"""
源码
"""
@enable_multi_worker
def fit(self,
x=None,
y=None,
batch_size=None,
epochs=1,
verbose=1,
callbacks=None,
validation_split=0.,
validation_data=None,
shuffle=True,
class_weight=None,
sample_weight=None,
initial_epoch=0,
steps_per_epoch=None,
validation_steps=None,
validation_batch_size=None,
validation_freq=1,
max_queue_size=10,
workers=1,
use_multiprocessing=False):
若使用其他优化器可自行步入官方文档进行查阅(我觉得这很pytorch)

其中loss是训练损失结果,val_loss是验证损失结果
目前看来,训练损失还凑合,但是验证损失比较大,处于****过拟合状态
如何理解欠拟合和过拟合,请看此文章 理解过拟合 - 知乎
那么如何调参保证不让他过拟合,让他收敛呢???
通过下面的方法,将模型参数打印出来看一下
model.summary()

可以看到每一层计算后的结果,当然可以往前推计算出特征值个数
调参
更改一下初始化方法的参数试试
kernel_initializer
这里先使用随机高斯分布进行调参
学习入口:正态(高斯)分布
model = tf.keras.Sequential()
model.add(layers.Dense(16, kernel_initializer='random_normal'))
model.add(layers.Dense(32, kernel_initializer='random_normal'))
model.add(layers.Dense(1, kernel_initializer='random_normal'))
为了让他多学一会,我又将epoch上调到100
model.compile(optimizer=tf.keras.optimizers.SGD(0.001),
loss='mean_squared_error')
model.fit(input_features, labels, validation_split=0.25, epochs=100, batch_size=128)
可以看到,这次效果好了一点,当然了,epoch上调起了决定性作用hhhh
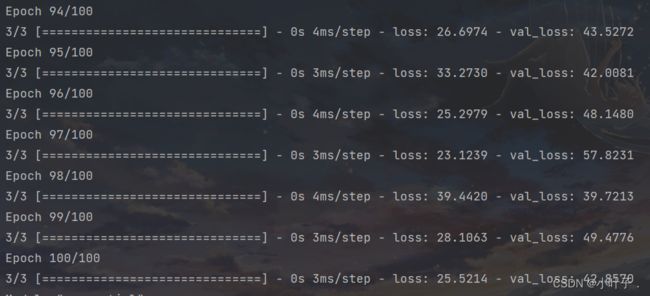
这回将高斯分布剔除,再跑一边看看,高斯分布的影响

当然,这个的优化还是有作用的,毕竟那几个三位数也不怎么样
kernel_regularizer
这回再加入正则化惩罚项试试
model = tf.keras.Sequential()
model.add(layers.Dense(16, kernel_initializer='random_normal', kernel_regularizer=tf.keras.regularizers.l2(0.03)))
model.add(layers.Dense(32, kernel_initializer='random_normal', kernel_regularizer=tf.keras.regularizers.l2(0.03)))
model.add(layers.Dense(1, kernel_initializer='random_normal', kernel_regularizer=tf.keras.regularizers.l2(0.03)))

可以看到,效果有一点提升,但是不那么明显
模型预测
predict = model.predict(input_features)
predict.shape
-------------------------------------------------------
"""
(348, 1)
"""
测试结果
为了让模型更可靠,我将epoch上调至10000次,并将结果可视化
plt.style.use('fivethirtyeight')
# 创建表保存日期和其对应的标签数值
dates = [str(int(year)) + '-' + str(int(month)) + '-' + str(int(day)) for year, month, day in
zip(years, months, days)]
dates = [datetime.datetime.strptime(date, '%Y-%m-%d') for date in dates]
true_data = pd.DataFrame(data={'date': dates, 'actual': labels})
# 创建表保存日期和其对应的模型预测值
months = features[:, features_list.index('month')]
days = features[:, features_list.index('day')]
years = features[:, features_list.index('year')]
test_dates = [str(int(year)) + '-' + str(int(month)) + '-' + str(int(day)) for year, month, day in
zip(years, months, days)]
test_dates = [datetime.datetime.strptime(date, '%Y-%m-%d') for date in test_dates]
predictions_data = pd.DataFrame(data={'date': test_dates, 'prediction': predict.reshape(-1)})
# 真实值
plt.plot(true_data['date'], true_data['actual'], 'b-', label='actual')
# 预测值
plt.plot(predictions_data['date'], predictions_data['prediction'], 'ro', label='prediction')
plt.xticks(rotation='60')
plt.legend()
# 图名
plt.xlabel('Date')
plt.ylabel('Maximum Temperature (F)')
plt.title('Actual and Predicted Values')
plt.tight_layout(pad=2)
plt.show()

可见结果还是可以接受的,啊。。。。右上角那个点是怎么回事儿??!!
To be continued…