linux gnome3安装_从零开始搭建基于linux(Ubuntu)深度学习服务器
从零开始搭建基于linux(Ubuntu)深度学习服务器
硬件设备介绍(服务器主机配置):CPU(inter i9 7900)、主板(华硕X299-A)、显卡(影驰1080ti 11G*2)、内存(金士顿16G)、硬盘(影驰240G固态+WD2T)、电源(长城1250W)。
第一步:制作Ubuntu server 16.04 U盘启动盘
首先去官网下载Ubuntu server 16.04的iOS文件(网址:https://ubuntu.com/download/alternative-downloads),如下选择Ubuntu16.04server(64bit),下下来是个ubuntu-16.04.6-server-amd64.iso.torrent文件,用迅雷下载。

然后制作Ubuntu server 16.04 U盘启动盘,首先去这里下在Rufus,链接地址:https://rufus.akeo.ie/,下载完之后,插入要制作启动盘的U盘,直接双击Rufus运行就行。运行界面如下:


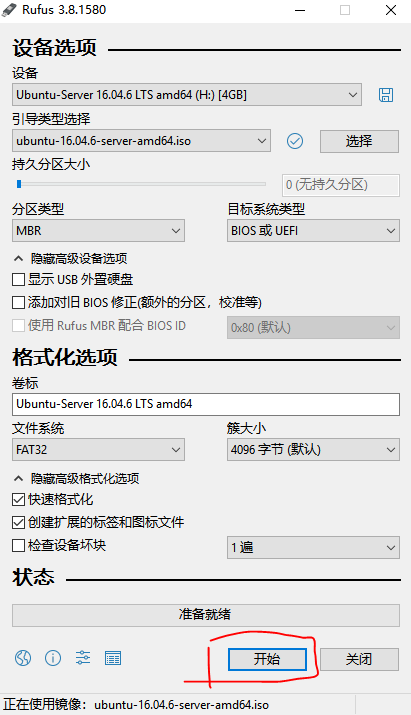
选择镜像文件,上一步下载好的,其余选项默认,点击开始。开始制作,完成后,为了保险本人把镜像文件再次放到U盘下。
第二步:给服务器安装Ubuntu server 16.04 系统
开机进入bios,F2或者del,看机子对应的主板是什么。
按F8选择启动菜单,选择刚刚制作好的U盘作为启动盘
进入之后选择 install Ubuntu
后面的操作可以参考这篇文章(https://blog.csdn.net/zhengchaooo/article/details/79500209)
选择硬盘写入的时候,选择固态硬盘,尽量把系统分区做大,2T的机械硬盘可以挂载来实现数据存放。
2T机械硬盘的挂载:
1.查看信息
输入sudo fdisk –l

由上图所示,需要挂载的硬盘是 /dev/sda1
2.格式化机械硬盘
sudo mkfs.ext4 /dev/sda1
3.创建/home/data目录(/home/data目录为硬盘将挂载的地方)
sudo mkdir /home/data
4.挂载分区
sudo mount /dev/sda1 /home/data
5. 查看磁盘分区的UUID
sudo blkid

6. 配置开机自动挂载
sudo vim /etc/fstab
按inset键 最后加入以下内容
# add mount disk
UUID=0e06d4ce-9b7d-4617-a7b6-b5b86cf4cbb9 /home/data ext4 defaults 0 0

7. 重启系统
sudo reboot 重启系统后输入 df –h检验如下所示即成功

第三步 安装显卡驱动以及可视化界面
- 首先要关闭 Ubuntu unity桌面环境默认的 lightdm 管理器,切换到tty (按快捷键 Ctrl + Alt + F2 就是切换到 tty2)
sudo service lightdm stop
2.卸载原有的N卡驱动(没有的请忽略)
卸载apt方式安装的n卡驱动
sudo apt remove --purge nvidia*
sudo apt autoremove
卸载用官网run方式安装的n卡驱动
sudo nvidia-uninstall
3.安装NVIDIA驱动
sudo add-apt-repository ppa:xorg-edgers/ppa
sudo add-apt-repository ppa:graphics-drivers/ppa
sudo apt update
sudo apt-get install prime-indicator #安装双显卡切换指示器(可忽略)
查看可安装驱动版本
ubuntu-drivers devices

找后面有recommend的版本,我的是nvidia-430
sudo apt install nvidia-430
重启
这种方法兼容性好,帮你禁用默认的 nouveau 开源驱动,避免和本闭源驱动冲突。
现在会存在循环登录的问题。我我采用客户端安装Git Bash,用openssh-server的方法解决。官网下载Windows版(https://git-scm.com/downloads),安装完打开Git Bash。

输入ssh uesrname@192.168.116 , username为你在安装系统是设置的用户名,@后面的ip地址是你服务器所在局域网内的IP地址(连上路由器了),如何查看呢。在你的电脑连上路由器所在局域网,通过登录路由器的管理界面,本人所在实验室的路由器登录地址为http://tplogin.cn/,进入点击设备管理,点击服务器名称对应管理查看IP地址。(通过管理员设置DHCP服务可以使服务器使用永久ip,不会因为每次重新开机而刷新)

4.验证
查询系统现在使用的驱动
sudo prime-select query
然后再把nvidia驱动设置为系统使用的显卡驱动
sudo prime-select nvidia
没有报错即表示显卡能够正常运行了,顺便查看显卡信息。
sudo nvidia-smi
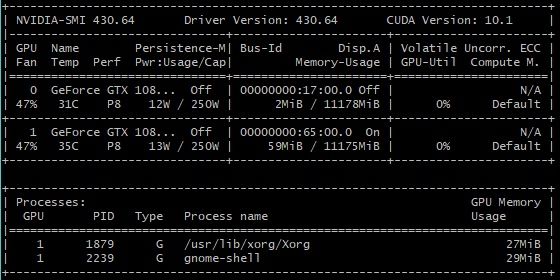
如上则成功。
如果出现: NVIDIA-SMI has failed because it couldn't communicate with the NVIDIA driver. Make sure that the latest NVIDIA driver is installed and running.(内核版本高造成的,开机启动换旧版本内核)
请查看https://blog.csdn.net/qq_41870658/article/details/93330041
5.解决循环登录问题
不用默认的unity桌面,改成 gnome3。
sudo add-apt-repository ppa:gnome3-team/gnome3
sudo apt-get update && sudo apt-get upgrade
sudo apt-get install gnome-shell ubuntu-gnome-desktop
此时选 gdm3
重启
进入图形界面
确认 gnome 桌面运行没有问题,就把 unity 桌面卸载掉
sudo apt-get remove unity lightdm ubuntu-desktop
第四步 服务器安装docker
- 客户端安装Gitbash 和filezilla
Gitbash下进入root:ssh username@192.168.116
2.安装docker以及nvidia-docker
关闭docker
sudo systemctl stop docker
首先卸载旧版本docker
sudo apt-get remove docker docker-engine http://docker.io containerd runc
或者
sudo apt-get purge docker-ce
更新apt包索引
sudo apt-get update
sudo apt-get -y install apt-transport-https ca-certificates curl software-properties-common
3.选择国内的云服务商,这里选择阿里云为例
curl -sSL http://acs-public-mirror.oss-cn-hangzhou.aliyuncs.com/docker-engine/internet | sh -
或者
curl -fsSL http://mirrors.aliyun.com/docker-ce/linux/ubuntu/gpg | sudo apt-key add -
其他来源查看(https://blog.csdn.net/BigData_Mining/article/details/87869147)
4.安装所需要的包
sudo apt-get install linux-image-extra-$(uname -r) linux-image-extra-virtual
5.添加使用 HTTPS 传输的软件包以及 CA 证书
sudo apt-get update
sudo apt-get install apt-transport-https ca-certificates
6.添加GPG密钥
sudo apt-key adv --keyserver hkp://http://p80.pool.sks-keyservers.net:80 --recv-keys 58118E89F3A912897C070ADBF76221572C52609D
7.添加软件源
echo "deb https://apt.dockerproject.org/repo ubuntu-xenial main" | sudo tee /etc/apt/sources.list.d/docker.list
或者
sudo add-apt-repository "deb [arch=amd64] http://mirrors.aliyun.com/docker-ce/linux/ubuntu $(lsb_release -cs) stable
8.添加成功后更新软件包缓存
sudo apt-get update
或者apt-cache madison docker-ce
9.安装docker
sudo apt install docker-ce=5:19.03.1~3-0~ubuntu-xenial(一定要安装19.03版本,这个版本docker能够共享宿主机的nvidia驱动,无需在docker容器内再安装)
10.启动docker
sudo systemctl start docker
11.加入开机启动
sudo systemctl enable docker
12.查看安装后信息
sudo docker info
13.安装nvidia-docker 看业务
sudo apt update
sudo apt install nvidia-docker2
如果失败查看(更新链接:https://github.com/NVIDIA/nvidia-docker/blob/master/README.md)或者直接如下操作
# Add the package repositories
$ distribution=$(. /etc/os-release;echo $ID$VERSION_ID)
$ curl -s -L https://nvidia.github.io/nvidia-docker/gpgkey | sudo apt-key add -
$ curl -s -L https://nvidia.github.io/nvidia-docker/$distribution/nvidia-docker.list | sudo tee /etc/apt/sources.list.d/nvidia-docker.list
$ sudo apt-get update && sudo apt-get install -y nvidia-container-toolkit
$ sudo systemctl restart docker
14.Docker免sudo
sudo groupadd docker
sudo gpasswd -a ${USER} docker
sudo service docker restart
newgrp – docker
15.列出GPU设备
docker run -it --rm --gpus all ubuntu nvidia-smi –L
安装docker和nvidia-docker成功。
第五步 docker安装镜像以及添加用户/
1、docker安装Ubuntu镜像
docker search ubuntu(如果获取报错response from daemon: Get https://index.docker.io/v1/search?q=centos&n=25: dial tcp: lookup http://index.docker.io on 222.88.88.88:53: read udp 192.168.1.101:56472->222.88.88.88:53: i/o timeout 原因是国外的源很慢访问有问题,建议更改国内的源)
docker pull ubuntu
docker images #列出镜像
2、添加/删除用户以及密码
sudo useradd –d /home/data/username –m –s /bin/bash username(username为你想添加的用户名,/home/data为我2T机械硬盘的挂载目录,在此目录下添加用方便数据的存储和计算)
sudo passwd username(设置或者更改密码)
删除用户:sudo userdel –r username
3、为用户创建docker容器器皿,并共享主机硬件
docker run -it --privileged=true --name username-v /home/data/username:/username ubuntu /bin/bas
4、将用户添加到docker组
sudo adduser username docker
docker start username
docker stop username
Docker安装完启动时提示Failed to start docker.service: Unit docker.service is masked(查看https://blog.csdn.net/u011403655/article/details/50524071)
docker的常规操作查看(https://blog.csdn.net/weixin_44286547/article/details/88980211)
第六步 为用户搭建深度学习环境
1、进入用户
ssh username@192.168.1.116
进入docker容器器皿:docker start username(第一次和重启服务器之后需要运行此命令)
docker exec –it username /bin/bash
退出ctl+D
2、anconda、tensorflow-gpu、keras安装
apt-get install -y wget
安装anaconda:wget https://mirrors.tuna.tsinghua.edu.cn/anaconda/archive/Anaconda3-2018.12-Linux-x86_64.sh (用的是清华镜像,一个字,快)
bash Anaconda3-2018.12-Linux-x86_64.sh
conda create –n tf python=3.6
source activate tf
conda install packagename(安装所需的包package,如tensorflow、tensorflow-gpu、keras等)
若测试tensorflow出错:不能创建session会话,则安装低版本cuda
Anaconda search –t conda cuda rlcc/cudatookkit
3、将容器器皿保存为一个新的镜像
docker ps –a #查看容器器皿地址

docker commit container_ID dockerimage #dockerimage为保存的镜像的名字, container_ID 为上述查询到的容器器皿地址
4、保存/加载镜像
docker save container_ID > filename.tar
docker load < filename.tar
5、下回创建新的用户可直接加载保存好的镜像
docker run -it --privileged=true --name username-v /home/data/username:/username dockerimage /bin/bash
PS:前端时间训练VQA数据集,安装了pytorch,不支持老版本的cuda故重新更新了宿主机的nvidia驱动,导致docker容器器皿下的用户无法使用N卡加速,这是老版本的docker不支持用户组跟宿主机同步的驱动导致的,索性重装系统重新配置服务器,现功能正常,又能愉快的深度学习了。第一次整理这么长的内容,内容有些表达不完善还请见谅。