java常用集合详解
文章目录
- 一、常用集合大纲
-
- 1.常用集合框架及介绍
- 2.集合和数组的区别
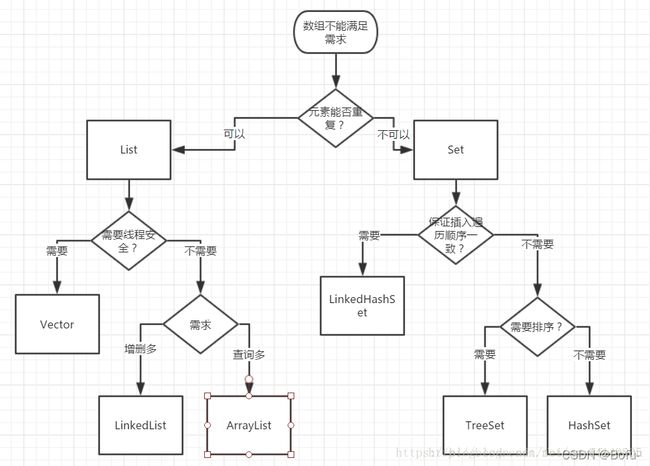
- 二、Collection 集合(接口)
- 三、List集合(接口)
-
- 1.存储遍历方式
- 2.ArrayList(实现类)
- 3.LinkedList(实现类)
- 4.小结
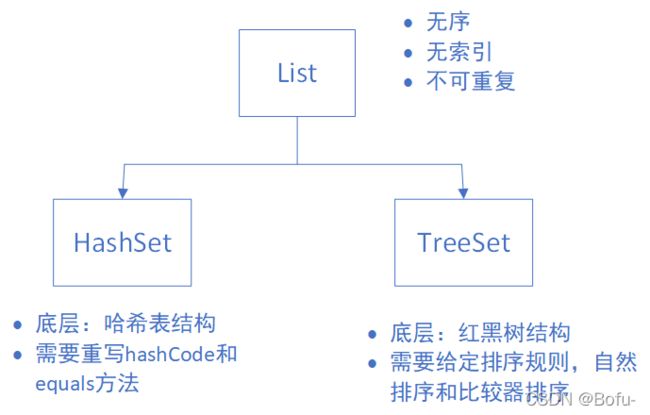
- 四、Set集合(接口)
-
- 1.存储遍历方式
- 2.TreeSet集合(实现类)
- 3.HashSet集合(实现类)
- 4.小结
- 五、List和Set总结:
- 六、Map集合(接口)
-
- 1.存储遍历方式
- 2.HashMap集合(实现类)
- 3.TreeMap集合(实现类)
- 参考文献
- 总结
一、常用集合大纲
1.常用集合框架及介绍
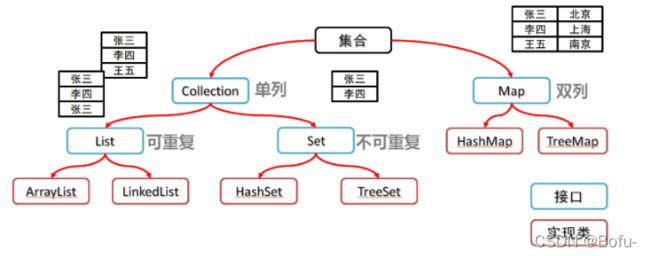
java集合类类库的用途主要是用于 “保存对象” ,其可以被划分为两个不同的概念:
(1)Collection:它是一个独立元素的序列,这些元素通常都服从一条或多条规则。它的下面包含List和Set,List必须按照插入的顺序保存元素,可以保存重复的元素,而Set则不能有重复的元素。
(2)Map:是一组成对的 “键值对" 对象,允许通过 “键” 来查找 “值”。Map用于保存具有映射关系的数据,Map里保存着两组数据:key和value,它们都可以使任何引用类型的数据,但key不能重复。所以通过指定的key就可以取出对应的value。
2.集合和数组的区别
(1)相同点:
两者都是容器,都用来存储多个数据。
(2)不同点:
1)长度区别:数组的长度是固定的,集合的长度可以通过扩容进行变化。
2)内容区别:数据可以存储基本数据类型(int, char, float等)和引用数据类型(类、 接口类型、 数组类型等),而集合只能存储引用数据类型。
3)元素区别:数组只能存储同一种类型,集合可以存储不同类型。
二、Collection 集合(接口)
(1)Collection集合概述
1)是单例集合的顶层接口,它表示一组对象,这些对象也称为Collection的元素。
2)JDK 不提供此接口的任何直接实现.它提供更具体的子接口(如Set和List)实现。
(2)创建Collection集合的对象
以多态的方式创建,具体的实现类为ArrayList。
(3)Collection集合常用方法
| 方法名 | 说明 |
|---|---|
| boolean add(E e) | 添加元素 |
| boolean remove(Object o) | 从集合中移除指定的元素 |
| boolean removeIf(Object o) | 根据条件进行移除 |
| void clear() | 清空集合中的元素 |
| boolean contains(Object o) | 判断集合中是否存在指定的元素 |
| boolean isEmpty() | 判断集合是否为空 |
| int size() | 集合的长度,也就是集合中元素的个数 |
(4)代码测试
public class CollectionTest {
public static void main(String[] args) {
//以多态的方式声明,具体的实现类为ArrayList
Collection<String> collection = new ArrayList<String>();
//add 添加数据
collection.add("aaa");
//remove 从集合中移除指定元素
collection.remove("aaa");
//removeIf 根据条件移除元素,当条件成立时该元素被移除
collection.removeIf(
(String s)->{
return s.length() == 3;
}
);
//clear 清空集合中的元素
collection.clear();
//contains 判断集合是否存在指定的元素,存在则返回true,否则返回false
collection.contains("aaa");
//isEmpty 判断集合是否为空,是则返回true,否则返回false
collection.isEmpty();
// size 表示该集合的长度
collection.size();
}
}
三、List集合(接口)
(1)List集合的概述和特点
1)List集合的概述
- 其是有序集合,这里的有序指的是存取顺序。
- 用户可以精确控制列表中每个元素的插入位置,用户可以通过整数索引访问元素,并搜索列表中的元素
- 与Set集合不同,列表通常允许存储重复的元素
2)List集合的特点
- 存取有序
- 可以重复
- 有索引
(2)List集合常用的方法
| 方法名 | 说明 |
|---|---|
| void add(int index,E element) | 在此集合中的指定位置插入指定的元素 |
| E remove(int index) | 删除指定索引处的元素,返回被删除的元素 |
| E set(int index,E element) | 修改指定索引处的元素,返回被修改的元素 |
| E get(int index) | 返回指定索引处的元素 |
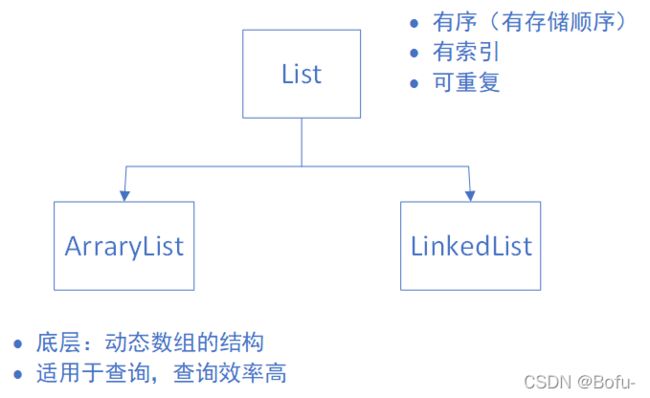
(3)List集合常用的子类及特点
(1)ArrayList:底层数据结构是数组,查询快,增删慢,线程不安全,效率高,可以存储重复元素
(2)LinkedList 底层数据结构是链表,查询慢,增删快,线程不安全,效率高,可以存储重复元素
1.存储遍历方式
List集合存储对象的遍历方式主要有以下三种(可根据自己实际需要选取遍历方式):
(1)使用迭代器遍历,集合特有的遍历方式
(2)使用普通for循环遍历,带有索引
(3)使用增强for循环,最方便的方式
public class ListTest {
public static void main(String[] args) {
List<String> list = new ArrayList<>();
list.add("d");
list.add("a");
list.add("b");
list.add("c");
list.add("d");
//迭代器进行遍历
Iterator<String> it = list.iterator();
while(it.hasNext()){
String s = it.next();
System.out.println(s);
}
//普通for循环方式
for (int i=0;i<list.size();i++){
String s=list.get(i);
System.out.println(s);
}
//加强for循环,foreach遍历方式
for (String s : list) {
System.out.println(s);
}
}
}
输出结果:
两种方式都一样,输出为:d a b c d
2.ArrayList(实现类)
(1)ArrayList常用的特有的方法
| 方法名 | 说明 |
|---|---|
| public ArrayList() | 创建一个空的集合对象 |
| public boolean add(E e) | 将指定的元素追加到此集合的末尾 |
| public void add(int index,E element) | 在此集合中的指定位置插入指定的元素 |
| public boolean remove(Object o) | 删除指定的元素,返回删除是否成功 |
| public E remove(int index) | 删除指定索引处的元素,返回被删除的元素 |
| public E set(int index,E element) | 修改指定索引处的元素,返回被修改的元素 |
| public E get(int index) | 返回指定索引处的元素 |
| public int size() | 返回集合中的元素的个数 |
(2)代码测试
1)当以List多态的方式声明,实现类为ArrayList时。ArrayList已经被向上转型为List,该对象只能调用List特有的方法而不能调用ArrayList中特有的方法。当你要用ArrayList中特有的方法时,则需要将其转型为对应的接口(ArrayList的接口),即参考(2)的代码测试,而不能将它们向上转型为通用的接口。
public class ListTest {
public static void main(String[] args) {
//当以List多态的方式声明,实现类为ArrayList时
List<String> list = new ArrayList<String>();
//add 添加数据。输出:索引为0的位置值为aaa
list.add("aaa");
//在此集合中的指定位置插入指定的元素。输出:索引为1的位置值为qqq
list.add(1,"qqq");
//remove 删除指定索引处的元素,返回被删除的元素。 输出:索引为0的值被删除
list.remove(0);
//set 修改指定索引处的元素,返回被修改的元素。输出:索引为0的值被修改为qqq
list.set(0, "qqq");
//get 返回指定索引处的元素。 输出:索引为0的值被获取
list.get(0);
}
}
2)当以ArrayList的方式声明,实现类为ArrayList时,因为ArrayList继承了List,故其不仅可以使用自身特有方法,也可以使用List的特有方法。
public class ListTest {
public static void main(String[] args) {
//以ArrayList为接口声明
ArrayList<String> array = new ArrayList<String>();
//add 添加数据。
array.add("aaa");
//remove 删除指定的元素,返回删除是否成功
array.remove("aaa");
//删除指定索引处的元素,返回被删除的元素
array.remove(1)
//set 修改指定索引处的元素,返回被修改的元素。输出:索引为0的值被修改为qqq
array.set(0, "qqq");
//get 返回指定索引处的元素。 输出:索引为0的值被获取
array.get(0);
//size 返回集合中的元素的个数
array.size();
}
}
3)ArrayList存储学生对象并遍历
-
案例需求
- 创建一个存储学生对象的集合,存储多个学生对象,使用程序实现在控制台遍历该集合
-
代码实现:
学生类
public class Student implements Comparable<Student>{
private String name;
private int age;
public Student() {
}
public Student(String name, int age) {
this.name = name;
this.age = age;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public int getAge() {
return age;
}
public void setAge(int age) {
this.age = age;
}
@Override
public String toString() {
return "Student{" +
"name='" + name + '\'' +
", age=" + age +
'}';
}
}
测试类
public class ArrayListTest {
public static void main(String[] args) {
//创建集合对象
ArrayList<Student> array = new ArrayList<Student>();
//创建学生对象
Student s1 = new Student("林青霞",30);
Student s2 = new Student("风清扬", 33);
Student s3 = new Student("张曼玉", 18);
//添加学生对象到集合之中
array.add(s1);
array.add(s2);
array.add(s3);
//遍历出数据,采用通用遍历方式
for(int i = 0; i< array.size(); i++){
Student s = array.get(i);
System.out.println(s.getName()+","+s.getAge());
}
//采用加强for循环foreach方式
for (Student value: array) {
System.out.println(value.getName()+","+value.getAge());
}
}
}
输出结果:
//两种输出方式一样
林青霞,30
风清扬,33
张曼玉,18
3.LinkedList(实现类)
(1)LinkedList常用的特有的方法
| 方法名 | 说明 |
|---|---|
| public void addFirst(E e) | 在该列表开头插入指定的元素 |
| public void addLast(E e) | 将指定的元素追加到此列表的末尾 |
| public E getFirst() | 返回此列表中的第一个元素 |
| public E getLast() | 返回此列表中的最后一个元素 |
| public E removeFirst() | 从此列表中删除并返回第一个元素 |
| public E removeLast() | 从此列表中删除并返回最后一个元素 |
(2)代码测试
1)当以List多态的方式声明,实现类为LinkedList时。和上述的ArrayList一样,LinkedList已经被向上转型为List,该对象只能调用List特有的方法而不能调用LinkedList中特有的方法。该代码测试和ArrayList一样,如下。
public class ListTest {
public static void main(String[] args) {
//当以List多态的方式声明,实现类为ArrayList时
List<String> list = new LinkedList<String>();
//add 添加数据。输出:索引为0的位置值为aaa
list.add("aaa");
//在此集合中的指定位置插入指定的元素。输出:索引为1的位置值为qqq
list.add(1,"qqq");
//remove 删除指定索引处的元素,返回被删除的元素。 输出:索引为0的值被删除
list.remove(0);
//set 修改指定索引处的元素,返回被修改的元素。输出:索引为0的值被修改为qqq
list.set(0, "qqq");
//get 返回指定索引处的元素。 输出:索引为0的值被获取
list.get(0);
}
}
2)当以LinkedList的方式声明,实现类为LinkedList时,因为LinkedList继承了List,故其不仅可以使用自身特有方法,也可以使用List的特有方法。
public class ListTest {
public static void main(String[] args) {
//当以List多态的方式声明,实现类为ArrayList时
LinkedList<String> list = new LinkedList<String>();
//addFirst 在该列表开头插入指定的元素
list.addFirst("qqq");
//addLast 将指定的元素追加到此列表的末尾
list.addLast("www");
//返回此列表中的第一个元素
list.getFirst();
//返回此列表中的最后一个元素
list.getLast();
//从此列表中删除并返回第一个元素
list.removeFirst();
//从此列表中删除并返回最后一个元素
list.removeLast();
}
}
4.小结
四、Set集合(接口)
(1)Set集合概述和特点
- 无序
- 不可以存储重复元素
- 没有索引,不能使用普通for循环遍历,需要使用迭代器或者加强for循环遍历
1.存储遍历方式
Set集合存储对象的遍历方式主要有以下两种(可根据自己实际需要选取遍历方式,其不能使用普通for循环遍历):
(1)使用迭代器遍历,集合特有的遍历方式
(2)使用增强for循环,最方便的方式
public class MySet1 {
public static void main(String[] args) {
//创建集合对象
Set<String> set = new TreeSet<>();
//添加元素
set.add("ccc");
set.add("aaa");
set.add("aaa");
set.add("bbb");
/**
*Set集合是没有索引的,所以不能使用通过索引获取元素的方法,该方法是错误的
for (int i = 0; i < set.size(); i++) {
}
*/
//遍历集合,迭代器方法遍历
Iterator<String> it = set.iterator();
while (it.hasNext()){
String s = it.next();
System.out.println(s);
}
System.out.println("-----------------------------------");
//加强for循环遍历
for (String s : set) {
System.out.println(s);
}
}
}
输出结果:
aaa
bbb
ccc
2.TreeSet集合(实现类)
(1)TreeSet集合概述和特点
- 不可以存储重复元素
- 没有索引
- 底层数据结构采用二叉树来实现,元素唯一且已经排好序,可以将元素按照规则进行排序
TreeSet():根据其元素的自然排序进行排序
TreeSet(Comparator comparator):根据指定的比较器进行排序
根据构造方法不同,其可以分为自然排序(无参构造)和比较器排序(有参构造),自然排序要求元素必须实现Compareable接口,并重写里面的compareTo()方法,元素通过比较返回的int值来判断排序序列,返回0说明两个对象相同,不需要存储;比较器排序需要在TreeSet初始化的时候传入一个实现Comparator接口的比较器对象,或者采用匿名内部类的方式new一个Comparator对象,重写里面的compare()方法;
(2)TreeSet集合基本使用
存储Integer类型的整数并遍历
public class TreeSetDemo01 {
public static void main(String[] args) {
//创建集合对象
TreeSet<Integer> ts = new TreeSet<Integer>();
//添加元素
ts.add(10);
ts.add(40);
ts.add(30);
ts.add(50);
ts.add(20);
ts.add(30);
//遍历集合
for(Integer i : ts) {
System.out.println(i);
}
}
}
输出结果:
为排序好的顺序结果
10 20 30 40 50
(3)自然排序Comparable的使用
自然排序(无参构造)要求元素必须实现Compareable接口,并重写里面的compareTo()方法,元素通过比较返回的int值来判断排序序列,返回0说明两个对象相同,不需要存储。
- 案例需求
- 存储学生对象并遍历,创建TreeSet集合使用无参构造方法
- 要求:按照年龄从小到大排序,年龄相同时,按照姓名的字母顺序排序
- 实现步骤:
- 使用空参构造创建TreeSet集合:
- 用TreeSet集合存储自定义对象,无参构造方法使用的是自然排序对元素进行排序的
- 自定义的Student类实现Comparable接口:
- 自然排序,就是让元素所属的类实现Comparable接口,重写compareTo(T o)方法
- 重写接口中的compareTo方法:
- 重写方法时,一定要注意排序规则必须按照要求的主要条件和次要条件来写
- 使用空参构造创建TreeSet集合:
- 代码实现:
学生类
注意:自定义的学生类需要实现Comparable接口才能重写compareTo(T o)方法
public class Student implements Comparable<Student>{
private String name;
private int age;
public Student() {
}
public Student(String name, int age) {
this.name = name;
this.age = age;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public int getAge() {
return age;
}
public void setAge(int age) {
this.age = age;
}
@Override
public String toString() {
return "Student{" +
"name='" + name + '\'' +
", age=" + age +
'}';
}
/**
*重写接口中的compareTo方法
*/
@Override
public int compareTo(Student o) {
//按照对象的年龄进行排序
/**
*主要判断条件: 按照年龄从小到大排序,当result小于0时,则排序在前面,
*当result大于零时则排序到后面。this指向的是正在存储的函数,o表示
*已经存储过的函数(可包含多个函数),用正在存储的函数一个个和已经存储过的
*函数进行年龄比较
*/
int result = this.age - o.age;
/**
*次要判断条件: 年龄相同时,按照姓名的字母顺序排序
*下面的句子是一个三元运算符,判断当result等于0时(即表示两者年龄相同),
*则调用comparaTo函数比较名字的字母,否则直接输出result结果
*/
result = result == 0 ? this.name.compareTo(o.getName()) : result;
return result;
}
}
测试类
public class MyTreeSet2 {
public static void main(String[] args) {
//创建集合对象
TreeSet<Student> ts = new TreeSet<>();
//创建学生对象
Student s1 = new Student("zhangsan",28);
Student s2 = new Student("lisi",27);
Student s3 = new Student("wangwu",29);
Student s4 = new Student("zhaoliu",28);
Student s5 = new Student("qianqi",30);
//把学生添加到集合
ts.add(s1);
ts.add(s2);
ts.add(s3);
ts.add(s4);
ts.add(s5);
//遍历集合
for (Student student : ts) {
System.out.println(student);
}
}
}
输出结果为已经按顺序排序好的:
Student{name='lisi', age=27}
Student{name='zhangsan', age=28}
Student{name='zhaoliu', age=28}
Student{name='wangwu', age=29}
Student{name='qianqi', age=30}
- 图解原理:
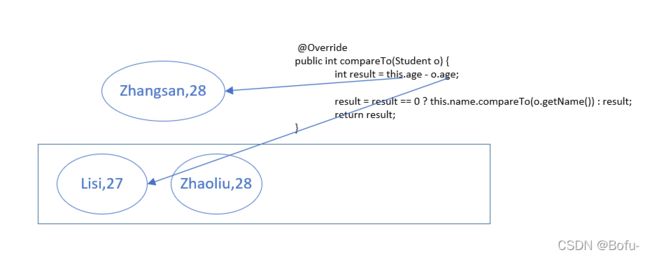
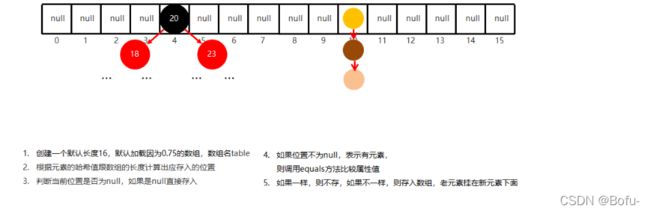
如图所示,当添加完数据到集合时,zhangsan的age值会拿来和已经存储到集合中的age值进行比较,即lisi的值。得出result结果为正数时,zhangsan的值将排在lisi后面,向后移动一位继续与后面的值进行比较。当与zhaoliu比较时,得出result的值为0(即年龄相同),则调用三元运算符里面的compareTo函数,比较他两的名字的字符串顺序(原理其实通过比对字符串的ASCII码值来排序),最后得出张三排在赵四的前面。

(4)比较器排序Comparator的使用
比较器排序(有参构造)需要在TreeSet初始化的时候传入一个实现Comparator接口的比较器对象,或者采用匿名内部类的方式new一个Comparator对象,重写里面的compare()方法;
- 案例需求:
- 存储老师对象并遍历,创建TreeSet集合使用带参构造方法
- 要求:按照年龄从小到大排序,年龄相同时,按照姓名的字母顺序排序
- 实现步骤:
- 用TreeSet集合存储自定义对象,带参构造方法使用的是比较器排序对元素进行排序的
- 比较器排序,就是让集合构造方法接收Comparator的实现类对象,重写compare(T o1,T o2)方法
- 重写方法时,一定要注意排序规则必须按照要求的主要条件和次要条件来写
代码实现:
老师类
public class Teacher {
private String name;
private int age;
public Teacher() {
}
public Teacher(String name, int age) {
this.name = name;
this.age = age;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public int getAge() {
return age;
}
public void setAge(int age) {
this.age = age;
}
@Override
public String toString() {
return "Teacher{" +
"name='" + name + '\'' +
", age=" + age +
'}';
}
}
测试类
public class MyTreeSet4 {
public static void main(String[] args) {
//创建集合对象,重写compare方法,采用匿名内部类的方式new一个Comparator对象
TreeSet<Teacher> ts = new TreeSet<>(new Comparator<Teacher>() {
@Override
public int compare(Teacher o1, Teacher o2) {
//o1表示现在要存入的那个元素
//o2表示已经存入到集合中的元素
//主要条件
/**
*主要判断条件: 按照年龄从小到大排序,当result小于0时,则排序在前面,
*当result大于零时则排序到后面。this指向的是正在存储的函数,o表示
*已经存储过的函数(可包含多个函数),用正在存储的函数一个个和已经存储过的
*函数进行年龄比较
*/
int result = o1.getAge() - o2.getAge();
//次要条件
/**
*次要判断条件: 年龄相同时,按照姓名的字母顺序排序
*下面的句子是一个三元运算符,判断当result等于0时(即表示两者年龄相同),
*则调用comparaTo函数比较名字的字母,否则直接输出result结果
*/
result = result == 0 ? o1.getName().compareTo(o2.getName()) : result;
return result;
}
});
//创建老师对象
Teacher t1 = new Teacher("zhangsan",23);
Teacher t2 = new Teacher("lisi",22);
Teacher t3 = new Teacher("wangwu",24);
Teacher t4 = new Teacher("zhaoliu",24);
//把老师添加到集合
ts.add(t1);
ts.add(t2);
ts.add(t3);
ts.add(t4);
//遍历集合
for (Teacher teacher : ts) {
System.out.println(teacher);
}
}
}
输出结果:
Teacher{name='lisi', age=22}
Teacher{name='zhangsan', age=23}
Teacher{name='wangwu', age=24}
Teacher{name='zhaoliu', age=24}
(5)两种比较方式总结
- 两种比较方式小结
- 自然排序: 自定义类实现Comparable接口,重写compareTo方法,根据返回值进行排序
- 比较器排序: 创建TreeSet对象的时候传递Comparator的实现类对象,重写compare方法,根据返回值进行排序
- 在使用的时候,默认使用自然排序,当自然排序不满足现在的需求时,必须使用比较器排序
- 两种方式中关于返回值的规则
- 如果返回值为负数,表示当前存入的元素是较小值,存左边
- 如果返回值为0,表示当前存入的元素跟集合中元素重复了,不存
- 如果返回值为正数,表示当前存入的元素是较大值,存右边
3.HashSet集合(实现类)
(1)HashSet集合概述和特点
- 底层数据结构是哈希表
- 存取无序
- 不可以存储重复元素
- 没有索引,不能使用普通for循环遍历,需要使用for
HashSet底层数据结构采用哈希表实现,元素无序且唯一,线程不安全,效率高,可以存储null元素,元素的唯一性是靠所存储元素类型是否重写hashCode()和equals()方法来保证的,如果没有重写这两个方法,则无法保证元素的唯一性。
Set的实现类的集合对象中不能够有重复元素,HashSet也一样使用了一种标识来确定元素的不重复,采用了哈希算法来保证HashSet中的元素是不重复的, 底层用 “数组+链表” 或者 “数组+红黑树” 存储数据,默认初始化容量16,加载因子0.75。
(2)哈希值
Object类中的hashCode()的方法是所有子类都会继承这个方法,这个方法会用Hash算法算出一个Hash(哈希)码值返回,HashSet会用Hash码值去和数组长度取模, 模(这个模就是对象要存放在数组中的位置)相同时才会判断数组中的元素和要加入的对象的内容是否相同,如果不同才会添加进去。
- 哈希值简介
- 是JDK根据对象的地址或者字符串或者数字算出来的int类型的数值
- 如何获取哈希值
- Object类中的public int hashCode():返回对象的哈希码值
- 哈希值的特点
- 同一个对象多次调用hashCode()方法返回的哈希值是相同的
- 默认情况下,不同对象的哈希值是不同的。而重写hashCode()方法,可以实现让不同对象的哈希值相同
(3)哈希表结构
在JDK1.8以前(不包含1.8jdk版本)
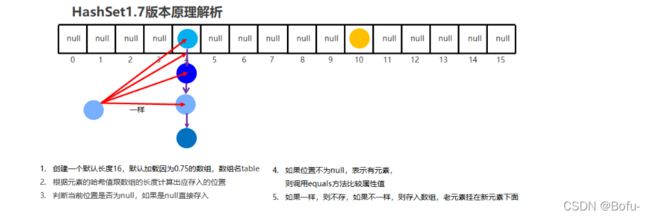
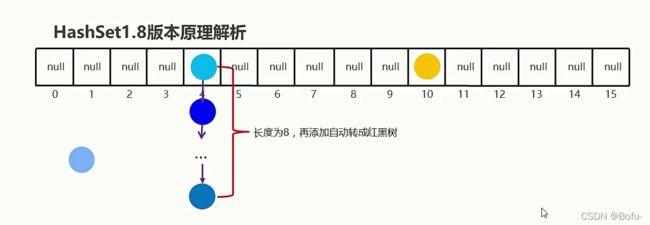
存储结构采用的是数组+链表的形式。存储元素首先会使用hash()算法函数生成一个int类型hashCode的散列值(如图用数组下标代替哈希值),然后和已经所存储的元素的hashCode值进行比较,如果hashCode不相等,则所存储的两个对象一定不相等,此时存储当前的新的hashCode值处的元素对象(如黄色圆圈所存储的位置)。如果hashCode相等,存储元素的对象还是不一定相等,此时会调用equals()方法判断两个对象的内容是否相等,如果内容相等,那么就是同一个对象,无需存储;如果比较的内容不相等,那么就是不同的对象,就该存储了,此时就要采用哈希的解决地址冲突算法,在当前hashCode值处生成类似一个新的链表, 在同一个hashCode值的后面存储存储不同的对象,并且老元素将会被挂在新元素下面,这样就保证了元素的唯一性(如下图蓝色存储位置及其列表)。
加载因子0.75:
当数组里面存储了16*0.75=12个元素时,数组就会被自动扩容为原先的两倍。
在JDK1.8以后
当存储的链表结构少于等于8个时,采用的是 “数组+链表” 的结构,当存储列表的长度多余8个时,采用的是 “数组+红黑树” 的结构。后面存储元素的原理和上述相同,只是存储结构发生了改变。
(4)HashSet集合案例应用
- 案例需求
- 创建一个存储学生对象的集合,存储多个学生对象,使用程序实现在控制台遍历该集合
- 要求:学生对象的成员变量值相同,我们就认为是同一个对象
代码实现
学生类
public class Student {
private String name;
private int age;
public Student() {
}
public Student(String name, int age) {
this.name = name;
this.age = age;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public int getAge() {
return age;
}
public void setAge(int age) {
this.age = age;
}
//equals函数,当hashCode值一样时,用来判断两个对象的内容是否相等。相同则不存储,不同则存储
@Override
public boolean equals(Object o) {
if (this == o) return true;
if (o == null || getClass() != o.getClass()) return false;
Student student = (Student) o;
if (age != student.age) return false;
return name != null ? name.equals(student.name) : student.name == null;
}
@Override
public int hashCode() {
int result = name != null ? name.hashCode() : 0;
result = 31 * result + age;
return result;
}
}
测试类
public class HashSetDemo02 {
public static void main(String[] args) {
//创建HashSet集合对象
HashSet<Student> hs = new HashSet<Student>();
//创建学生对象
Student s1 = new Student("林青霞", 30);
Student s2 = new Student("张曼玉", 35);
Student s3 = new Student("王祖贤", 33);
Student s4 = new Student("王祖贤", 33);
//把学生添加到集合
hs.add(s1);
hs.add(s2);
hs.add(s3);
hs.add(s4);
//遍历集合(增强for)
for (Student s : hs) {
System.out.println(s.getName() + "," + s.getAge());
}
}
}
输出结果:
王祖贤,33
张曼玉,35
林青霞,30
4.小结
五、List和Set总结:
(1)List,Set都是继承自Collection接口。
(2)List和Set的特点和区别:
- List:元素有放入顺序,元素可重复 ,支持for循环(即通过下标来遍历),也可以用迭代器遍历。
- Set:元素无放入顺序,元素不可重复,重复元素会覆盖掉,只能用迭代,因为他无序,无法用下标来取得想要的值。(注意:元素虽然无放入顺序,但是元素在set中的位置是有该元素的HashCode决定的,其位置其实是固定的,加入Set 的Object必须定义equals()方法 )
(3)ArrayList与LinkedList的区别和适用场景
当需要对数据进行对此访问的情况下选用ArrayList,当需要对数据进行多次增加删除修改时采用LinkedList。
- ArraryList:
- 优点:ArrayList是实现了基于动态数组的数据结构,因为地址连续,一旦数据存储好了,查询操作效率会比较高(在内存里是连着放的)。
- 缺点:因为地址连续, ArrayList要移动数据,所以插入和删除操作效率比较低。
- LinkedList:
- 优点:LinkedList基于链表的数据结构,地址是任意的,所以在开辟内存空间的时候不需要等一个连续的地址,对于新增和删除操作add和remove,LinedList比较占优势。LinkedList 适用于要头尾操作或插入指定位置的场景。
- 缺点:因为LinkedList要移动指针,所以查询操作性能比较低。
(4)HashSet与TreeSet的区别和适用场景
HashSet是基于Hash算法实现的,其性能通常都优于TreeSet。为快速查找而设计的Set,我们通常都应该使用HashSet,在我们需要排序的功能时,我们才使用TreeSet。
- HashSet:是哈希表实现的,HashSet中的数据是无序的,可以放入null,但只能放入一个null,两者中的值都不能重复,就如数据库中唯一约束。要求放入的对象必须实现HashCode()方法,放入的对象以hashcode码作为标识的,而具有相同内容的String对象,hashcode是一样,所以放入的内容不能重复。但是同一个类的对象可以放入不同的实例
- TreeSet:是二叉树(红黑树的树据结构)实现的,Treeset中的数据是自动排好序的,不允许放入null值。
六、Map集合(接口)
(1)Map集合概念
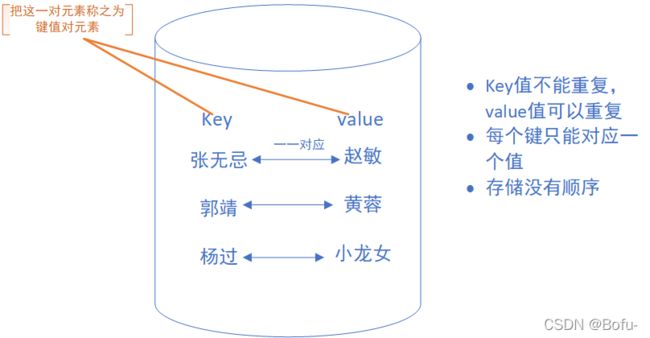
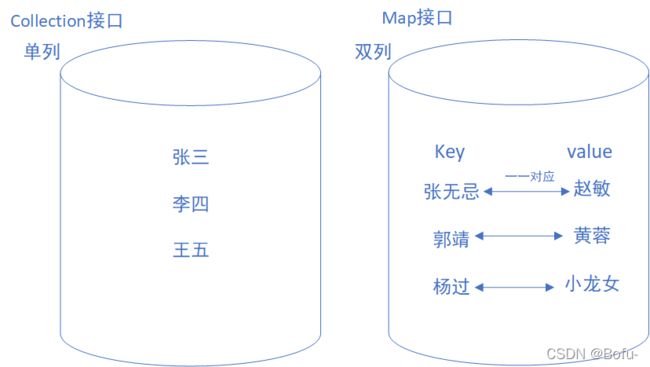
Map用于保存具有映射关系的数据,Map里保存着两组数据:key和value,它们都可以使任何引用类型的数据,但key不能重复。所以通过指定的key就可以取出对应的value。Map 没有继承 Collection 接口, Map 提供 key 到 value 的映射,可以通过 “键” 查找 “值”。一个 Map 中不能包含相同的 key ,每个 key 只能映射一个 value 。 Map 接口提供 3 种集合的视图, Map 的内容可以被当作一组 key 集合,一组 value 集合,或者一组 key-value 映射。
Map和Collection接口下的集合
-
Collection中的集合,元素是孤立存在的(理解为单身),向集合中存储元素采用一个个元素的方式存储。
-
Map中的集合,元素是成对存在的(理解为夫妻)。每个元素由键与值两部分组成,通过键可以找对所对应的值。
-
Collection中的集合称为单列集合,Map中的集合称为双列集合。
-
需要注意的是,Map中的集合不能包含重复的键,值可以重复;每个键只能对应一个值。
-
Map中常用的集合为HashMap集合、LinkedHashMap集合。
(2)Map集合常用方法
| 方法名 | 说明 |
|---|---|
| V put(K key,V value) | 添加元素 |
| V remove(Object key) | 根据键删除键值对元素 |
| void clear() | 移除所有的键值对元素 |
| boolean containsKey(Object key) | 判断集合是否包含指定的键 |
| boolean containsValue(Object value) | 判断集合是否包含指定的值 |
| boolean isEmpty() | 判断集合是否为空 |
| int size() | 集合的长度,也就是集合中键值对的个数 |
| V get(Object key) | 根据键获取值 |
| Set keySet() | 获取所有键的集合 |
| Collection values() | 获取所有值的集合 |
| Set |
获取所有键值对对象的集合 |
(3)代码测试
public class MapDemo02 {
public static void main(String[] args) {
//创建集合对象
Map<String,String> map = new HashMap<String,String>();
//V put(K key,V value):添加元素,"张无忌"是键名key,"赵敏"是值value,两者相互映射
map.put("张无忌","赵敏");
map.put("郭靖","黄蓉");
map.put("杨过","小龙女");
//V remove(Object key):根据键删除键值对元素
map.remove("郭靖")
//void clear():移除所有的键值对元素
map.clear();
//boolean containsKey(Object key):判断集合是否包含指定的键
map.containsKey("郭靖")
//boolean isEmpty():判断集合是否为空
map.isEmpty()
//int size():集合的长度,也就是集合中键值对的个数
map.size()
//输出集合对象
System.out.println(map);
//V get(Object key):根据键获取值
System.out.println(map.get("张无忌")); //输出结果为赵敏
System.out.println(map.get("张三丰")); //因没有这个键值,故输出结果为null
//Set keySet():获取所有键的集合
Set<String> keySet = map.keySet(); //输出结果为:张无忌,郭靖,杨过。
for(String key : keySet) {
System.out.println(key);
}
//Collection values():获取所有值的集合
Collection<String> values = map.values(); //输出结果为:赵敏,黄蓉,小龙女
for(String value : values) {
System.out.println(value);
}
}
}
1.存储遍历方式
(1)增强for循环遍历(使用较多)
(2)增强for结合Map.Entry(容量大时使用)
(3)迭代器遍历(根据keySet来遍历)
(4)迭代器遍历(根据entrySet来遍历)
public class MapDemo01 {
public static void main(String[] args) {
//创建集合对象
Map<String, String> map = new HashMap<String, String>();
//添加元素
map.put("张无忌", "赵敏");
map.put("郭靖", "黄蓉");
map.put("杨过", "小龙女");
/**
*(1)增强for循环遍历(使用较多)
*/
//获取所有键的集合。用keySet()方法实现
Set<String> keySet = map.keySet();
//遍历键的集合,获取到每一个键。用增强for实现
for (String key : keySet) {
//根据键去找值。用get(Object key)方法实现
String value = map.get(key);
System.out.println(key + ":" + value);
}
/**
*(2)增强for结合Map.Entry(容量大时使用)
*/
//获取所有键值对对象的集合
Set<Map.Entry<String, String>> entrySet = map.entrySet();
//遍历键值对对象的集合,得到每一个键值对对象
for (Map.Entry<String, String> me : entrySet) {
//根据键值对对象获取键和值
String key = me.getKey();
String value = me.getValue();
System.out.println(key + ":" + value);
}
/**
*(3)迭代器遍历(根据keySet来遍历)
*/
//获取所有键的集合。用keySet()方法实现
Set<String> keySet = map.keySet();
//遍历键的集合,获取到每一个键。用增强for实现
Iterator<String> keySets = keySet.iterator();
while(keySets.hasNext()) {
//遍历每一个键值,根据键去找值。用get(Object key)方法实现
String key = keySets.next();
String value = map.get(key);
System.out.println(key +":"+value);
}
/**
*(4)迭代器遍历(根据entrySet来遍历)
*/
//获取所有键值对对象的集合
Iterator<Map.Entry<String, String>> entries = map.entrySet().iterator();
while (entries.hasNext()){
//根据键值对对象获取键和值
Map.Entry<String,String> maps = entries.next();
String key = maps.getKey();
String value = maps.getValue();
System.out.println(key+":"+value);
}
}
}
输出结果:
杨过:小龙女
郭靖:黄蓉
张无忌:赵敏
2.HashMap集合(实现类)
(1)HashMap集合概述和特点
- HashMap底层是哈希表结构的(哈希表可参考上面HashSet中的介绍,只不过哈希值是通过 “键” 的值计算出来的)。
- 依赖hashCode方法和equals方法保证键的唯一。
- 如果键要存储的是自定义对象,需要重写hashCode和equals方法。
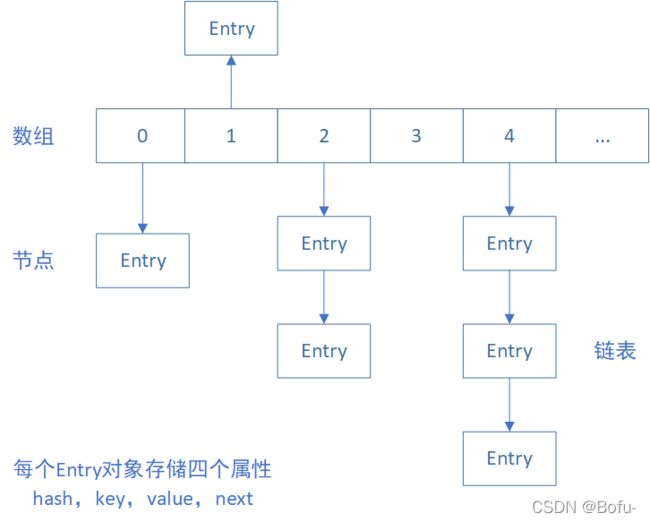
(2)HashMap工作原理
HashMap 数据结构为 “数组+链表”,其中:链表的节点存储的是一个 Entry 对象,每个Entry 对象存储四个属性(hash,key,value,next)。如下图可知,HashMap整体是一个数组,数组每一个位置都是一个链表,并且链表每个节点中的value值既是我们存储的Object。
(3)HashMap集合案例
- 案例需求
- 创建一个HashMap集合,键是学生对象(Student),值是居住地 (String)。存储多个元素,并遍历。
- 要求保证键的唯一性:如果学生对象的成员变量值相同,我们就认为是同一个对象
- 代码实现
学生类
public class Student {
private String name;
private int age;
public Student() {
}
public Student(String name, int age) {
this.name = name;
this.age = age;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public int getAge() {
return age;
}
public void setAge(int age) {
this.age = age;
}
/**
*重写equal方法
*/
@Override
public boolean equals(Object o) {
if (this == o) return true;
if (o == null || getClass() != o.getClass()) return false;
Student student = (Student) o;
if (age != student.age) return false;
return name != null ? name.equals(student.name) : student.name == null;
}
/**
*重写hashCode方法
*/
@Override
public int hashCode() {
int result = name != null ? name.hashCode() : 0;
result = 31 * result + age;
return result;
}
}
测试类
public class HashMapDemo {
public static void main(String[] args) {
//创建HashMap集合对象
HashMap<Student, String> hm = new HashMap<Student, String>();
//创建学生对象
Student s1 = new Student("林青霞", 30);
Student s2 = new Student("张曼玉", 35);
Student s3 = new Student("王祖贤", 33);
Student s4 = new Student("王祖贤", 33);
//把学生添加到集合
hm.put(s1, "西安");
hm.put(s2, "武汉");
hm.put(s3, "郑州");
hm.put(s4, "北京");
//遍历集合
Set<Student> keySet = hm.keySet();
for (Student key : keySet) {
String value = hm.get(key);
System.out.println(key.getName() + "," + key.getAge() + "," + value);
}
}
}
输出结果:
王祖贤,33,北京
张曼玉,35,武汉
林青霞,30,西安
3.TreeMap集合(实现类)
(1)TreeMap集合概述和特点
- TreeMap底层是红黑树结构
- 依赖自然排序或者比较器排序,对 “键” 进行排序
- 如果键存储的是自定义对象,需要实现Comparable接口或者在创建TreeMap对象时候给出比较器排序规则
(注:底层结构、自然排序和比较器排序等可以参考TreeSet,这里就不在详细介绍)
(2)TreeMap集合案例
- 案例需求
- 创建一个TreeMap集合,键是学生对象(Student),值是籍贯(String),学生属性姓名和年龄,按照年龄进行排序并遍历
- 要求按照学生的年龄进行排序,如果年龄相同则按照姓名进行排序
- 代码实现
学生类:
public class Student implements Comparable<Student>{
private String name;
private int age;
public Student() {
}
public Student(String name, int age) {
this.name = name;
this.age = age;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public int getAge() {
return age;
}
public void setAge(int age) {
this.age = age;
}
@Override
public String toString() {
return "Student{" +
"name='" + name + '\'' +
", age=" + age +
'}';
}
@Override
public int compareTo(Student o) {
//按照年龄进行排序
int result = o.getAge() - this.getAge();
//次要条件,按照姓名排序。
result = result == 0 ? o.getName().compareTo(this.getName()) : result;
return result;
}
}
测试类:
public class Test1 {
public static void main(String[] args) {
// 创建TreeMap集合对象
TreeMap<Student,String> tm = new TreeMap<>();
// 创建学生对象
Student s1 = new Student("xiaohei",23);
Student s2 = new Student("dapang",22);
Student s3 = new Student("xiaomei",22);
// 将学生对象添加到TreeMap集合中
tm.put(s1,"江苏");
tm.put(s2,"北京");
tm.put(s3,"天津");
// 遍历TreeMap集合,打印每个学生的信息
//获取所有键的集合。用keySet()方法实现
Set<Student> keySet = tm.keySet();
//遍历键的集合,获取到每一个键。用增强for实现
for (Student key : keySet) {
//根据键去找值。用get(Object key)方法实现
String value = tm.get(key);
System.out.println(key + ":" + value);
}
}
}
输出结果:
Student{name='xiaohei', age=23}:江苏
Student{name='xiaomei', age=22}:天津
Student{name='dapang', age=22}:北京
参考文献
(1)list、Map、Set遍历方式总结
(2)Java集合超详解
(3)黑马Java学习资料
(4)java笔记-Map的用法
(5)Java中的Map集合
(6)10分钟拿下HashMap
总结
这次写的关于Java集合的博客是因为在学习项目过程中用到了HashMap,以前学习过程中学得比较泛,对这List、Set和Map概念混淆在一起,现今整理了一下概念及其基础的用法,待以后深入学习之后再继续学习和记录集合中更底层的知识。