人工智能 | ShowMeAI资讯日报 #2022.06.01

ShowMeAI日报系列全新升级!覆盖AI人工智能 工具&框架 | 项目&代码 | 博文&分享 | 数据&资源 | 研究&论文 等方向。点击查看 历史文章列表,在公众号内订阅话题 #ShowMeAI资讯日报,可接收每日最新推送。点击 专题合辑&电子月刊 快速浏览各专题全集。点击 这里 回复关键字 日报 免费获取AI电子月刊与资料包。
1.工具&框架

工具库:compose - 面向预测工程自动化的机器学习工具
tags:[预测工程,自动化,机器学习]
‘compose - A machine learning tool for automated prediction engineering’ by alteryx
GitHub:http://github.com/alteryx/compose


工具:labelGo - 基于labelImg及YOLOV5的图形化半自动标注工具
tags:[数据标注,图像标注,半自动化]
‘labelGo - YOLOV5 semi-automatic annotation tool (Based on labelImg)’ by Cheng-Yu Fang
GitHub:http://github.com/cnyvfang/labelGo-Yolov5AutoLabelImg
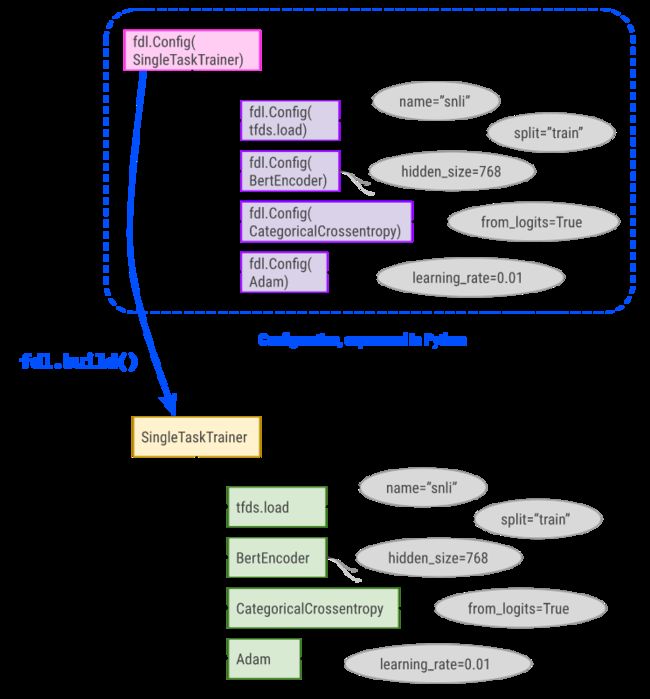
工具库:Fiddle - 适合机器学习应用的Python配置管理库,支持深度学习参数配置
tags:[机器学习,配置管理,参数配置]
‘Fiddle - a Python-first configuration library particularly well suited to ML applications’ by google
GitHub:http://github.com/google/fiddle
工具库:ERNIE - 文心大模型ERNIE
tags:[ERNIE,大模型]
‘Official implementations for various pre-training models of ERNIE-family, covering topics of Language Understanding & Generation, Multimodal Understanding & Generation, and beyond.’ by PaddlePaddle
GitHub:http://github.com/PaddlePaddle/ERNIE

工具库:UnionML - 构建和部署机器学习微服务
tags:[部署,服务,微服务,机器学习]
‘UnionML - the easiest way to build and deploy machine learning microservices’ by unionai-oss
GitHub:http://github.com/unionai-oss/unionml

工具库:BasicSR - 超分辨率开发工具集
tags:[超分辨率]
‘BasicSR - Basic Super-Resolution codes for development. Includes ESRGAN, SFT-GAN for training and testing.’ by Xintao
GitHub:http://github.com/XPixelGroup/BasicSR

工具:GRASS GIS - 免费开源的地理信息系统(GIS)
tags:[GIS,地理信息]
‘GRASS GIS - free and open source Geographic Information System (GIS)’ by Open Source Geospatial Foundation
GitHub:http://github.com/OSGeo/grass
2.项目&代码

项目:Python示例代码集
tags:[python]
‘My Python Examples’ by geekcomputers
GitHub:http://github.com/geekcomputers/Python
项目:InsightFace: 最先进的2D和3D人脸分析项目
tags:[人脸识别,人脸分析]
‘InsightFace: 2D and 3D Face Analysis Project - State-of-the-art 2D and 3D Face Analysis Project’ by Deep Insight
GitHub:http://github.com/deepinsight/insightface


书籍项目代码:《Rasa实战:构建开源对话机器人》官方随书代码
tags:[对话系统,问答]
GitHub:http://github.com/Chinese-NLP-book/rasa_chinese_book_code
3.博文&分享

博文:机器学习核心概念的可视化解释
tags:[机器学习,可视化]
‘MLU-Explain - Visual explanations of core machine learning concepts’
Link:https://mlu-explain.github.io/
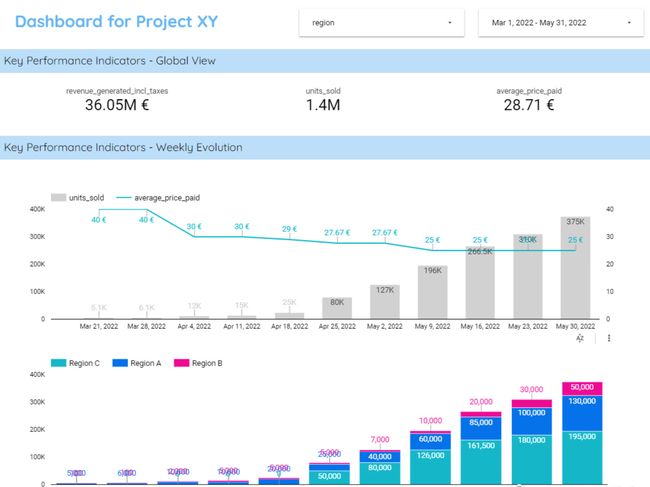
博文:如何构建高效(且有用)的面板
tags:[面板]
《How to Build Effective (and Useful) Dashboards》by Marie Lefevre
Link:http://towardsdatascience.com/how-to-build-effective-and-useful-dashboards-711759534639
 |
|
教程:从零开始的Kubernetes攻防
tags:[Kubernetes,攻防]
GitHub:http://github.com/neargle/my-re0-k8s-security
4.数据&资源

数据集:WTW-Dataset:现实场景表格检测识别数据集**
tags:[表格检测,数据集]
‘WTW-Dataset - an official implementation for the WTW Dataset in "Parsing Table Structures in the Wild " on table detection and table structure recognition.’ by wangwen-whu
GitHub:http://github.com/wangwen-whu/WTW-Dataset

数据集:DialogSum: 现实生活场景对话摘要数据集
tags:[对话,摘要,数据集]
‘DialogSum: A Real-life Scenario Dialogue Summarization Dataset - DialogSum: A Real-life Scenario Dialogue Summarization Dataset - Findings of ACL 2021’ by cylnlp
GitHub:http://github.com/cylnlp/DialogSum
数据集:SILVR: 合成沉浸式大容量全景数据集
tags:[图像,全景,数据集]
‘SILVR: A Synthetic Immersive Large-Volume Plenoptic Dataset - A Synthetic Immersive Large-Volume Plenoptic Dataset’ by IDLab Media
GitHub:http://github.com/IDLabMedia/large-lightfields-dataset
资源列表:机器学习数学基础学习资源集
tags:[AI数学基础]
‘Mathematics for Machine Learning - A collection of resources to learn mathematics for machine learning’ by DAIR.AI
GitHub:http://github.com/dair-ai/Mathematics-for-ML
资源列表:多标签图像识别相关资源大列表
tags:[多标签,图像]
‘Everything about Multi-label Image Recognition.’ by Tao Pu
GitHub:http://github.com/putao537/Awesome-Multi-label-Image-Recognition
资源列表:对话推荐系统论文列表
tags:[对话,推荐系统]
‘CRS Papers - Conversational Recommender System (CRS) paper list. 对话推荐系统论文列表’ by Chenzhan Shang
GitHub:http://github.com/Zilize/CRSPapers
5.研究&论文

可以点击 这里 回复关键字 日报,免费获取整理好的6月论文合辑。
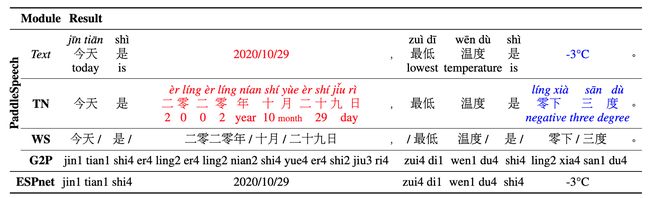
论文:PaddleSpeech: An Easy-to-Use All-in-One Speech Toolkit
论文标题:PaddleSpeech: An Easy-to-Use All-in-One Speech Toolkit
论文时间:20 May 2022
所属领域:Speech/语音
对应任务:Automatic Speech Recognition,Environmental Sound Classification,Keyword Spotting,Speaker Diarization,Speaker Identification,Speaker Recognition,Speaker Verification,Speech Recognition,Speech Synthesis,Speech-to-Text Translation,Text-To-Speech Synthesis,自动语音识别,环境声音分类,关键词识别,说话人区分,说话人识别,说话人识别,说话人验证,语音识别,语音合成,语音到文本翻译,文本到语音合成
论文地址:https://arxiv.org/abs/2205.12007
代码实现:https://github.com/PaddlePaddle/PaddleSpeech,https://github.com/PaddlePaddle/DeepSpeech
论文作者:HUI ZHANG, Tian Yuan, Junkun Chen, Xintong Li, Renjie Zheng, Yuxin Huang, Xiaojie Chen, Enlei Gong, Zeyu Chen, Xiaoguang Hu, dianhai yu, Yanjun Ma, Liang Huang
论文简介:PaddleSpeech is an open-source all-in-one speech toolkit./PaddleSpeech 是一个开源的一体化语音工具包。
论文摘要:PaddleSpeech is an open-source all-in-one speech toolkit. It aims at facilitating the development and research of speech processing technologies by providing an easy-to-use command-line interface and a simple code structure. This paper describes the design philosophy and core architecture of PaddleSpeech to support several essential speech-to-text and text-to-speech tasks. PaddleSpeech achieves competitive or state-of-the-art performance on various speech datasets and implements the most popular methods. It also provides recipes and pretrained models to quickly reproduce the experimental results in this paper. PaddleSpeech is publicly avaiable at https://github.com/PaddlePaddle/PaddleSpeech .
PadderSpeech是一个开源的多功能语音工具包。它旨在通过提供易于使用的命令行界面和简单的代码结构,促进语音处理技术的开发和研究。本文描述了PadleSpeech的设计理念和核心架构,以支持几个基本的语音到文本和文本到语音任务。PadleSpeech在各种语音数据集上实现了极具竞争力或最先进的性能,并实现了最流行的方法。它还提供了配方和预训练模型,以快速再现本文中的实验结果。
 |
|
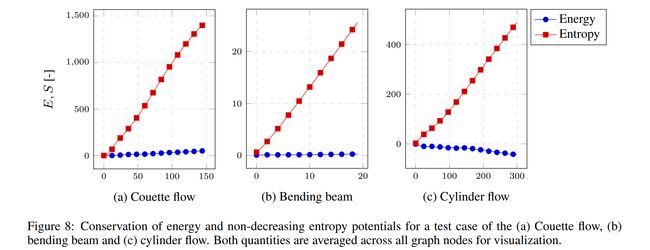
论文:Thermodynamics-informed graph neural networks
论文标题:Thermodynamics-informed graph neural networks
论文时间:3 Mar 2022
所属领域:图神经网络
论文地址:https://arxiv.org/abs/2203.01874
代码实现:https://github.com/quercushernandez/ThermodynamicsGNN
论文作者:Quercus Hernández, Alberto Badías, Francisco Chinesta, Elías Cueto
论文简介:In this paper we present a deep learning method to predict the temporal evolution of dissipative dynamic systems./本文提出了一种预测耗散动力系统时间演化的深度学习方法。
论文摘要:In this paper we present a deep learning method to predict the temporal evolution of dissipative dynamic systems. We propose using both geometric and thermodynamic inductive biases to improve accuracy and generalization of the resulting integration scheme. The first is achieved with Graph Neural Networks, which induces a non-Euclidean geometrical prior with permutation invariant node and edge update functions. The second bias is forced by learning the GENERIC structure of the problem, an extension of the Hamiltonian formalism, to model more general non-conservative dynamics. Several examples are provided in both Eulerian and Lagrangian description in the context of fluid and solid mechanics respectively, achieving relative mean errors of less than 3% in all the tested examples. Two ablation studies are provided based on recent works in both physics-informed and geometric deep learning.
在本文中,我们提出了一种深度学习方法来预测耗散动态系统的时间演化。我们建议使用几何和热力学感应偏差来提高所得积分方案的准确性和泛化性。第一个是通过图神经网络实现的,它引入了具有置换不变节点和边更新函数的非欧几里得几何先验。第二个偏差是通过学习问题的 GENERIC 结构(哈密顿形式主义的扩展)来强制建模更一般的非保守动力学。在流体力学和固体力学的背景下,欧拉和拉格朗日描述中分别提供了几个示例,在所有测试示例中实现了小于 3% 的相对平均误差。基于物理信息和几何深度学习的最新工作,提供了两项消融研究。

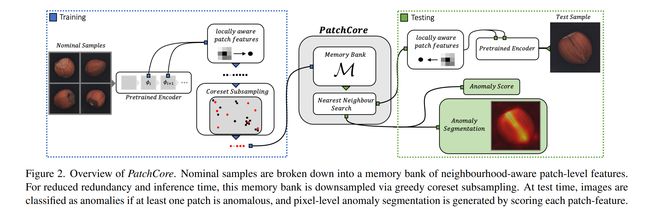
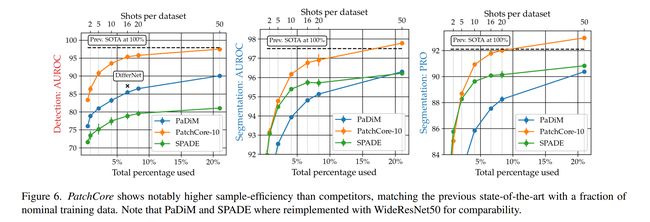
论文:Towards Total Recall in Industrial Anomaly Detection
论文标题:Towards Total Recall in Industrial Anomaly Detection
论文时间:15 Jun 2021
所属领域:Anomaly Detection/异常检测
对应任务:Anomaly Detection,Few Shot Anomaly Detection,Outlier Detection,异常检测,少样本异常检测,离群检测
论文地址:https://arxiv.org/abs/2106.08265
代码实现:https://github.com/amazon-research/patchcore-inspection , https://github.com/openvinotoolkit/anomalib ,
https://github.com/hcw-00/PatchCore_anomaly_detection ,
https://github.com/mindspore-ai/models/tree/master/official/cv/patchcore , https://github.com/rvorias/ind_knn_ad
论文作者:Karsten Roth, Latha Pemula, Joaquin Zepeda, Bernhard Schölkopf, Thomas Brox, Peter Gehler
论文简介:Being able to spot defective parts is a critical component in large-scale industrial manufacturing./能够发现有缺陷的零件是大规模工业制造中的一个关键组成部分。
论文摘要:Being able to spot defective parts is a critical component in large-scale industrial manufacturing. A particular challenge that we address in this work is the cold-start problem: fit a model using nominal (non-defective) example images only. While handcrafted solutions per class are possible, the goal is to build systems that work well simultaneously on many different tasks automatically. The best performing approaches combine embeddings from ImageNet models with an outlier detection model. In this paper, we extend on this line of work and propose \textbf{PatchCore}, which uses a maximally representative memory bank of nominal patch-features. PatchCore offers competitive inference times while achieving state-of-the-art performance for both detection and localization. On the challenging, widely used MVTec AD benchmark PatchCore achieves an image-level anomaly detection AUROC score of up to 99.6%, more than halving the error compared to the next best competitor. We further report competitive results on two additional datasets and also find competitive results in the few samples regime.\freefootnote{∗ Work done during a research internship at Amazon AWS.} Code:http://github.com/amazon-research/patchcore-inspection .
能够发现有缺陷的零件是大规模工业制造中的一个关键组成部分。我们在这项工作中解决的一个特殊挑战是冷启动问题:仅使用标称(无缺陷)示例图像拟合模型。虽然每个类都有手工制作的解决方案,但目标是构建能够自动同时在许多不同任务上工作的系统。性能最好的方法是将ImageNet模型的嵌入与异常检测模型相结合。在本文中,我们对这一工作进行了扩展,并提出了\textbf{PatchCore},它使用具有最大代表性的标称补丁特征的内存库。PatchCore提供了有竞争力的推理时间,同时在检测和定位方面实现了最先进的性能。在这一极具挑战性的、广泛使用的MVTec AD benchmark PatchCore上,图像级异常检测AUROC得分高达99.6%,与下一个最佳竞争对手相比,误差减少了一半以上。我们进一步报告了另外两个数据集的竞争结果,并在少数样本制度中发现了竞争结果。
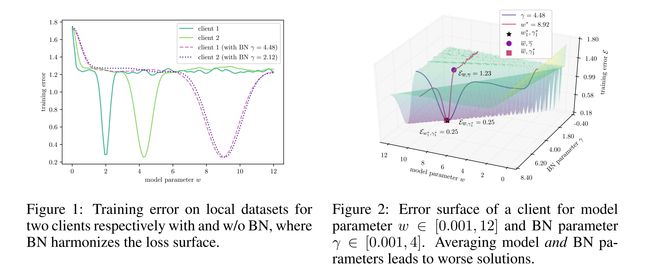
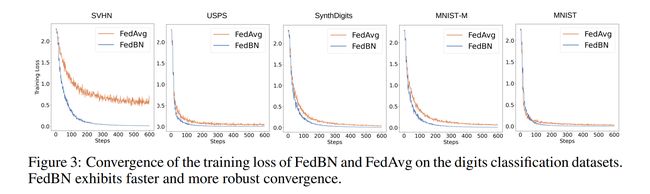
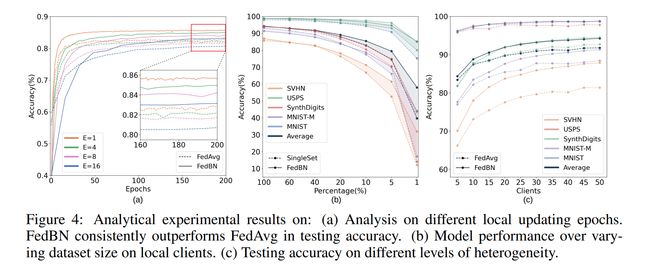
论文:FedBN: Federated Learning on Non-IID Features via Local Batch Normalization
论文标题:FedBN: Federated Learning on Non-IID Features via Local Batch Normalization
论文时间:ICLR 2021
所属领域:Computer Vision/计算机视觉
对应任务:Autonomous Driving,Federated Learning,自主驾驶、联邦学习
论文地址:https://arxiv.org/abs/2102.07623
代码实现:https://github.com/adap/flower,https://github.com/med-air/FedBN , https://github.com/TsingZ0/PFL-Non-IID
论文作者:Xiaoxiao Li, Meirui Jiang, Xiaofei Zhang, Michael Kamp, Qi Dou
论文简介:The emerging paradigm of federated learning (FL) strives to enable collaborative training of deep models on the network edge without centrally aggregating raw data and hence improving data privacy./新兴的联邦学习 (FL) 范式致力于在网络边缘进行深度模型的协作训练,而无需集中聚合原始数据,从而提高数据隐私。
论文摘要:The emerging paradigm of federated learning (FL) strives to enable collaborative training of deep models on the network edge without centrally aggregating raw data and hence improving data privacy. In most cases, the assumption of independent and identically distributed samples across local clients does not hold for federated learning setups. Under this setting, neural network training performance may vary significantly according to the data distribution and even hurt training convergence. Most of the previous work has focused on a difference in the distribution of labels or client shifts. Unlike those settings, we address an important problem of FL, e.g., different scanners/sensors in medical imaging, different scenery distribution in autonomous driving (highway vs. city), where local clients store examples with different distributions compared to other clients, which we denote as feature shift non-iid. In this work, we propose an effective method that uses local batch normalization to alleviate the feature shift before averaging models. The resulting scheme, called FedBN, outperforms both classical FedAvg, as well as the state-of-the-art for non-iid data (FedProx) on our extensive experiments. These empirical results are supported by a convergence analysis that shows in a simplified setting that FedBN has a faster convergence rate than FedAvg. Code is available at https://github.com/med-air/FedBN .
新兴的联邦学习 (FL) 范式致力于在网络边缘进行深度模型的协作训练,而无需集中聚合原始数据,从而提高数据隐私。在大多数情况下,跨本地客户端的独立且相同分布的样本的假设不适用于联邦学习设置。在这种设置下,神经网络的训练性能可能会根据数据分布而有很大差异,甚至会损害训练的收敛性。之前的大部分工作都集中在标签分布或客户转移的差异上。与这些设置不同,我们解决了 FL 的一个重要问题,例如,医学成像中的不同扫描仪/传感器,自动驾驶中不同的风景分布(高速公路与城市),本地客户端存储的示例与其他客户端相比具有不同的分布,我们表示为特征转移非独立同分布。在这项工作中,我们提出了一种有效的方法,该方法使用局部批量归一化来缓解平均模型之前的特征偏移。由此产生的方案,称为 FedBN,在我们广泛的实验中优于经典的 FedAvg,以及非独立同分布数据 (FedProx) 的最新技术。这些实证结果得到了收敛分析的支持,该分析在简化的设置中显示 FedBN 的收敛速度比 FedAvg 更快。
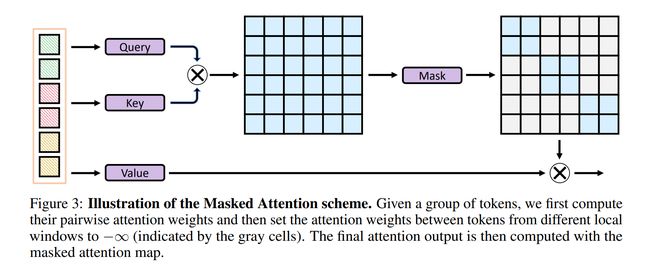
论文:Green Hierarchical Vision Transformer for Masked Image Modeling
论文标题:Green Hierarchical Vision Transformer for Masked Image Modeling
论文时间:26 May 2022
所属领域:Computer Vision/计算机视觉
对应任务:bject Detection,目标检测,物体检测
论文地址:https://arxiv.org/abs/2205.13515
代码实现:https://github.com/layneh/greenmim
论文作者:Lang Huang, Shan You, Mingkai Zheng, Fei Wang, Chen Qian, Toshihiko Yamasaki
论文简介:We present an efficient approach for Masked Image Modeling (MIM) with hierarchical Vision Transformers (ViTs), e. g., Swin Transformer, allowing the hierarchical ViTs to discard masked patches and operate only on the visible ones./我们提出了一种使用分层视觉Transformers (ViT) 进行掩蔽图像建模 (MIM) 的有效方法,例如Swin Transformer,允许分层 ViT 丢弃掩码补丁并仅对可见补丁进行操作。
论文摘要:We present an efficient approach for Masked Image Modeling (MIM) with hierarchical Vision Transformers (ViTs), e.g., Swin Transformer, allowing the hierarchical ViTs to discard masked patches and operate only on the visible ones. Our approach consists of two key components. First, for the window attention, we design a Group Window Attention scheme following the Divide-and-Conquer strategy. To mitigate the quadratic complexity of the self-attention w.r.t. the number of patches, group attention encourages a uniform partition that visible patches within each local window of arbitrary size can be grouped with equal size, where masked self-attention is then performed within each group. Second, we further improve the grouping strategy via the Dynamic Programming algorithm to minimize the overall computation cost of the attention on the grouped patches. As a result, MIM now can work on hierarchical ViTs in a green and efficient way. For example, we can train the hierarchical ViTs about 2.7× faster and reduce the GPU memory usage by 70%, while still enjoying competitive performance on ImageNet classification and the superiority on downstream COCO object detection benchmarks. Code and pre-trained models have been made publicly available at https://github.com/LayneH/GreenMIM .
我们提出了一种使用分层视觉Transformer (ViT) 进行掩蔽图像建模 (MIM) 的有效方法,例如 Swin Transformer,允许分层 ViT 丢弃掩蔽补丁并仅对可见补丁进行操作。我们的方法包括两个关键部分。首先,对于窗口注意力,我们按照分治策略设计了一个组窗口注意力方案。为了减轻 self-attention w.r.t. 的二次复杂度。补丁的数量,组注意鼓励统一分区,可以将任意大小的每个局部窗口内的可见补丁分组为相同大小,然后在每个组中执行掩码自注意。其次,我们通过动态规划算法进一步改进了分组策略,以最小化分组块上注意力的总体计算成本。因此,MIM 现在可以以绿色高效的方式处理分层 ViT。例如,我们可以将分层 ViT 的训练速度提高约 2.7 倍,并将 GPU 内存使用量减少 70%,同时在 ImageNet 分类上仍享有有竞争力的性能以及在下游 COCO 对象检测基准上的优势。
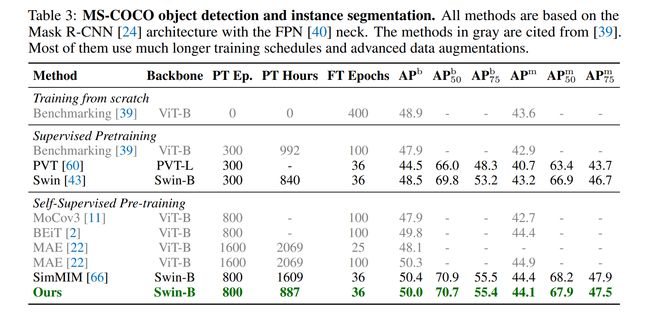
论文:Deep Video Harmonization with Color Mapping Consistency
论文标题:Deep Video Harmonization with Color Mapping Consistency
论文时间:2 May 2022
所属领域:Computer Vision/计算机视觉
对应任务:Video Harmonization/视频协调
论文地址:https://arxiv.org/abs/2205.00687
代码实现:https://github.com/bcmi/video-harmonization-dataset-hyoutube
论文作者:Xinyuan Lu, Shengyuan Huang, Li Niu, Wenyan Cong, Liqing Zhang
论文简介:Video harmonization aims to adjust the foreground of a composite video to make it compatible with the background./视频协调旨在调整合成视频的前景,使其与背景兼容。
论文摘要:Video harmonization aims to adjust the foreground of a composite video to make it compatible with the background. So far, video harmonization has only received limited attention and there is no public dataset for video harmonization. In this work, we construct a new video harmonization dataset HYouTube by adjusting the foreground of real videos to create synthetic composite videos. Moreover, we consider the temporal consistency in video harmonization task. Unlike previous works which establish the spatial correspondence, we design a novel framework based on the assumption of color mapping consistency, which leverages the color mapping of neighboring frames to refine the current frame. Extensive experiments on our HYouTube dataset prove the effectiveness of our proposed framework. Our dataset and code are available at https://github.com/bcmi/Video-Harmonization-Dataset-HYouTube .
视频协调旨在调整复合视频的前景,使其与背景兼容。到目前为止,视频协调只受到有限的关注,并且没有用于视频协调的公共数据集。在这项工作中,我们通过调整真实视频的前景来创建合成合成视频,构建了一个新的视频协调数据集 HYouTube。此外,我们考虑了视频协调任务中的时间一致性。与建立空间对应关系的先前工作不同,我们设计了一个基于颜色映射一致性假设的新颖框架,该框架利用相邻帧的颜色映射来细化当前帧。在我们的 HYouTube 数据集上进行的大量实验证明了我们提出的框架的有效性。

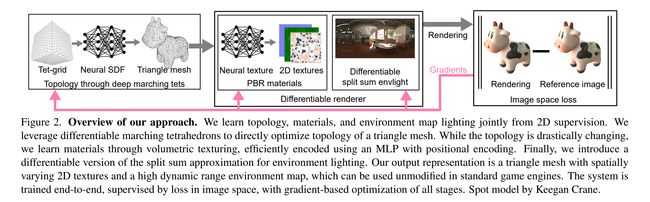
论文:Extracting Triangular 3D Models, Materials, and Lighting From Images
论文标题:Extracting Triangular 3D Models, Materials, and Lighting From Images
论文时间:24 Nov 2021
所属领域:Computer Vision/计算机视觉
论文地址:https://arxiv.org/abs/2111.12503
代码实现:https://github.com/NVlabs/nvdiffrec , https://github.com/nvlabs/tiny-cuda-nn
论文作者:Jacob Munkberg, Jon Hasselgren, Tianchang Shen, Jun Gao, Wenzheng Chen, Alex Evans, Thomas Müller, Sanja Fidler
论文简介:We present an efficient method for joint optimization of topology, materials and lighting from multi-view image observations.
论文摘要:We present an efficient method for joint optimization of topology, materials and lighting from multi-view image observations. Unlike recent multi-view reconstruction approaches, which typically produce entangled 3D representations encoded in neural networks, we output triangle meshes with spatially-varying materials and environment lighting that can be deployed in any traditional graphics engine unmodified. We leverage recent work in differentiable rendering, coordinate-based networks to compactly represent volumetric texturing, alongside differentiable marching tetrahedrons to enable gradient-based optimization directly on the surface mesh. Finally, we introduce a differentiable formulation of the split sum approximation of environment lighting to efficiently recover all-frequency lighting. Experiments show our extracted models used in advanced scene editing, material decomposition, and high quality view interpolation, all running at interactive rates in triangle-based renderers (rasterizers and path tracers). Project website: https://nvlabs.github.io/nvdiffrec/ .
我们提出了一种从多视图图像观察中联合优化拓扑、材料和照明的有效方法。与最近的多视图重建方法(通常产生在神经网络中编码的纠缠 3D 表示)不同,我们输出的三角形网格具有空间变化的材料和环境照明,可以在未经修改的任何传统图形引擎中部署。我们利用最近在可微渲染、基于坐标的网络中的工作来紧凑地表示体积纹理,以及可微行进四面体以直接在表面网格上实现基于梯度的优化。最后,我们引入了环境照明的分裂和近似的可微公式,以有效地恢复全频照明。实验表明我们提取的模型用于高级场景编辑、材质分解和高质量视图插值,所有这些模型都在基于三角形的渲染器(光栅化器和路径跟踪器)中以交互速率运行。

论文:6D Rotation Representation For Unconstrained Head Pose Estimation
论文标题:6D Rotation Representation For Unconstrained Head Pose Estimation
论文时间:25 Feb 2022
所属领域:Computer Vision/计算机视觉
对应任务:Head Pose Estimation,Pose Estimation,Pose Prediction,头部姿势估计,姿势估计,姿势预测
论文地址:https://arxiv.org/abs/2202.12555
代码实现:https://github.com/thohemp/6drepnet
论文作者:Thorsten Hempel, Ahmed A. Abdelrahman, Ayoub Al-Hamadi
论文简介:In this paper, we present a method for unconstrained end-to-end head pose estimation./本文提出了一种无约束端到端头位姿估计方法。
论文摘要:In this paper, we present a method for unconstrained end-to-end head pose estimation. We address the problem of ambiguous rotation labels by introducing the rotation matrix formalism for our ground truth data and propose a continuous 6D rotation matrix representation for efficient and robust direct regression. This way, our method can learn the full rotation appearance which is contrary to previous approaches that restrict the pose prediction to a narrow-angle for satisfactory results. In addition, we propose a geodesic distance-based loss to penalize our network with respect to the SO(3) manifold geometry. Experiments on the public AFLW2000 and BIWI datasets demonstrate that our proposed method significantly outperforms other state-of-the-art methods by up to 20%. We open-source our training and testing code along with our pre-trained models: https://github.com/thohemp/6DRepNet .
在本文中,我们提出了一种无约束的端到端头部姿态估计方法。我们通过为我们的地面实况数据引入旋转矩阵形式来解决模糊旋转标签的问题,并提出一个连续的 6D 旋转矩阵表示,以实现高效和稳健的直接回归。这样,我们的方法可以学习完整的旋转外观,这与以前将姿势预测限制在窄角以获得令人满意的结果的方法相反。此外,我们提出了一种基于测地距离的损失来惩罚我们的网络关于 SO(3) 流形几何。在公共 AFLW2000 和 BIWI 数据集上的实验表明,我们提出的方法显着优于其他最先进的方法高达 20%。

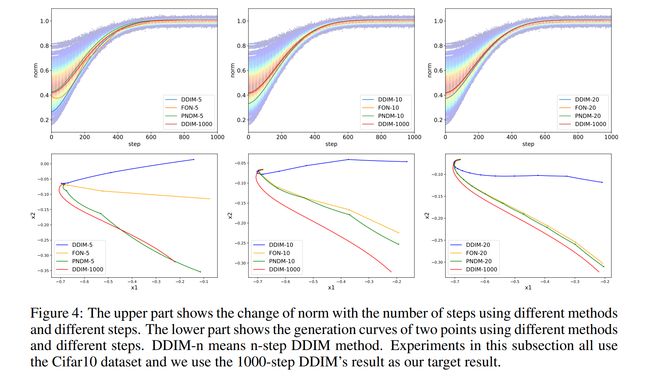
论文:Pseudo Numerical Methods for Diffusion Models on Manifolds
论文标题:Pseudo Numerical Methods for Diffusion Models on Manifolds
论文时间:ICLR 2022
所属领域:Computer Vision/计算机视觉
对应任务:Denoising,Image Generation,去噪,图像生成
论文地址:https://arxiv.org/abs/2202.09778
代码实现:https://github.com/luping-liu/PNDM , https://github.com/compvis/latent-diffusion , https://github.com/voletiv/mcvd-pytorch
论文作者:Luping Liu, Yi Ren, Zhijie Lin, Zhou Zhao
论文简介:Under such a perspective, we propose pseudo numerical methods for diffusion models (PNDMs)./去噪扩散概率模型(DDPM)可以生成高质量的样本,如图像和音频样本,我们提出了用于扩散模型(PNDM)的伪数值方法。
论文摘要:Denoising Diffusion Probabilistic Models (DDPMs) can generate high-quality samples such as image and audio samples. However, DDPMs require hundreds to thousands of iterations to produce final samples. Several prior works have successfully accelerated DDPMs through adjusting the variance schedule (e.g., Improved Denoising Diffusion Probabilistic Models) or the denoising equation (e.g., Denoising Diffusion Implicit Models (DDIMs)). However, these acceleration methods cannot maintain the quality of samples and even introduce new noise at a high speedup rate, which limit their practicability. To accelerate the inference process while keeping the sample quality, we provide a fresh perspective that DDPMs should be treated as solving differential equations on manifolds. Under such a perspective, we propose pseudo numerical methods for diffusion models (PNDMs). Specifically, we figure out how to solve differential equations on manifolds and show that DDIMs are simple cases of pseudo numerical methods. We change several classical numerical methods to corresponding pseudo numerical methods and find that the pseudo linear multi-step method is the best in most situations. According to our experiments, by directly using pre-trained models on Cifar10, CelebA and LSUN, PNDMs can generate higher quality synthetic images with only 50 steps compared with 1000-step DDIMs (20x speedup), significantly outperform DDIMs with 250 steps (by around 0.4 in FID) and have good generalization on different variance schedules. Our implementation is available at https://github.com/luping-liu/PNDM .
去噪扩散概率模型 (DDPM) 可以生成高质量的样本,例如图像和音频样本。但是,DDPM 需要数百到数千次迭代才能产生最终样本。一些先前的工作通过调整方差计划(例如,改进的去噪扩散概率模型)或去噪方程(例如,去噪扩散隐式模型(DDIM))成功地加速了 DDPM。然而,这些加速方法无法保持样本质量,甚至在高速加速时引入新的噪声,限制了它们的实用性。为了在保持样本质量的同时加速推理过程,我们提供了一个全新的观点,即 DDPM 应该被视为求解流形上的微分方程。在这种观点下,我们提出了扩散模型(PNDM)的伪数值方法。具体来说,我们弄清楚了如何求解流形上的微分方程,并表明 DDIM 是伪数值方法的简单案例。我们将几种经典数值方法改为相应的伪数值方法,发现伪线性多步法在大多数情况下是最好的。根据我们的实验,通过直接在 Cifar10、CelebA 和 LSUN 上使用预训练模型,与 1000 步 DDIM(20 倍加速)相比,PNDM 只需 50 步即可生成更高质量的合成图像,显着优于 250 步的 DDIM(约FID 中为 0.4),并且对不同的方差计划具有良好的泛化性。
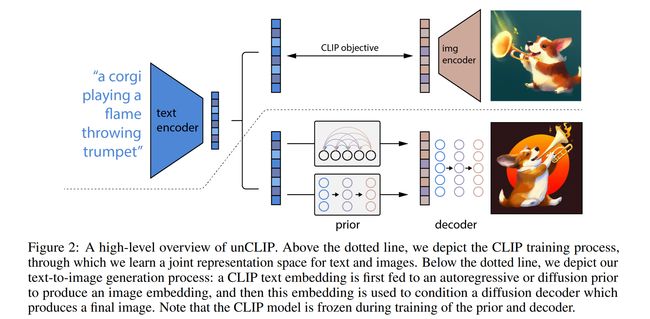
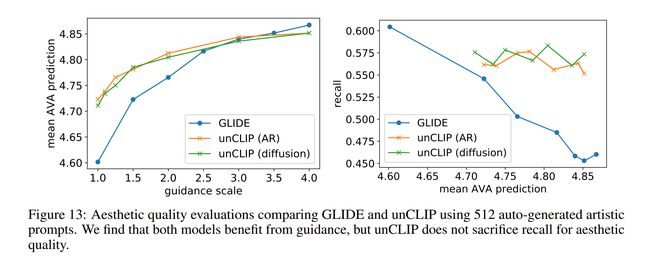
论文:Hierarchical Text-Conditional Image Generation with CLIP Latents
论文标题:Hierarchical Text-Conditional Image Generation with CLIP Latents
论文时间:13 Apr 2022
所属领域:Computer Vision/计算机视觉
对应任务:Conditional Image Generation,Image Generation,Text-to-Image Generation,Zero-Shot Text-to-Image Generation,条件图像生成,图像生成,文本到图像生成,零样本文本到图像生成
论文地址:https://arxiv.org/abs/2204.06125
代码实现:https://github.com/lucidrains/DALLE2-pytorch
论文作者:Aditya Ramesh, Prafulla Dhariwal, Alex Nichol, Casey Chu, Mark Chen
论文简介:Contrastive models like CLIP have been shown to learn robust representations of images that capture both semantics and style./像CLIP这样的对比模型已经被证明可以学习捕获语义和风格的图像的健壮表示。
论文摘要:Contrastive models like CLIP have been shown to learn robust representations of images that capture both semantics and style. To leverage these representations for image generation, we propose a two-stage model: a prior that generates a CLIP image embedding given a text caption, and a decoder that generates an image conditioned on the image embedding. We show that explicitly generating image representations improves image diversity with minimal loss in photorealism and caption similarity. Our decoders conditioned on image representations can also produce variations of an image that preserve both its semantics and style, while varying the non-essential details absent from the image representation. Moreover, the joint embedding space of CLIP enables language-guided image manipulations in a zero-shot fashion. We use diffusion models for the decoder and experiment with both autoregressive and diffusion models for the prior, finding that the latter are computationally more efficient and produce higher-quality samples.
像 CLIP 这样的对比模型已被证明可以学习捕捉语义和风格的图像的鲁棒表示。为了利用这些表示来生成图像,我们提出了一个两阶段模型:一个先验生成一个给定文本标题的 CLIP 图像嵌入,一个解码器生成以图像嵌入为条件的图像。我们表明,显式生成图像表示可以提高图像多样性,同时在照片真实感和标题相似性方面的损失最小。我们以图像表示为条件的解码器还可以生成图像的变体,同时保留其语义和风格,同时改变图像表示中缺少的非必要细节。此外,CLIP 的联合嵌入空间能够以零镜头方式进行语言引导的图像操作。我们对解码器使用扩散模型,并对先验模型使用自回归模型和扩散模型进行实验,发现后者在计算上更高效,并产生更高质量的样本。
我们是 ShowMeAI,致力于传播AI优质内容,分享行业解决方案,用知识加速每一次技术成长!点击查看 历史文章列表,在公众号内订阅话题 #ShowMeAI资讯日报,可接收每日最新推送。点击 专题合辑&电子月刊 快速浏览各专题全集。点击 这里 回复关键字 日报 免费获取AI电子月刊与资料包。

- 作者:韩信子@ShowMeAI
- 历史文章列表
- 专题合辑&电子月刊
- 声明:版权所有,转载请联系平台与作者并注明出处
- 欢迎回复,拜托点赞,留言推荐中有价值的文章、工具或建议,我们都会尽快回复哒~