图书管理系统
目录
一、需求分析
1、项目功能结构图
2、 分析
3、封装的方法:
二、使用对象序列化流需要注意的事项
1、序列化追加对象产生多个头
2、序列化集合在使用集合前需要先加载文件内容到集合
3、实体类需要实现Serializable接口以及指定serialVersionUID的值
三、项目实现
1、结构分析
2、代码实现
四、项目心得
1、remove与delete的区别
2、return与break的区别
3、传参的使用
4、运行过程
一、需求分析
1、项目功能结构图

2、 分析
图书管理系统分为五个模块每个模块下包含了增删改查的功能,主要使用IO流实现,可以把每个实体类看作一个对象,把这个对象存储到一个集合里进行操作,然后再把这个集合作为一个对象进行序列化,这样便实现了多个对象的数据存储。在需要使用这些数据时,再把文件里的内容(集合)反序列化出来,通过遍历集合得到文件中的数据,整个图书馆里系统均在使用对象序列化,所以我们可以把序列化以及反序列化封装成方法,直接调用,大大提高了代码的复用性和效率。
3、封装的方法:
序列化:
ObjectOutputStream oos = new ObjectOutputStream(new FileOutputStream(file));
oos.writeObject(array);
oos.close();
反序列化:
ObjectInputStream ois = new ObjectInputStream(new FileInputStream(file));
Object obj = ois.readObject();二、使用对象序列化流需要注意的事项
1、序列化追加对象产生多个头
使用对象序列化流时如果需要序列化多个对象,那么就要考虑到追加,然而Java默认的对象序列化是每次写入对象都会写入一个头aced 0005(占4个字节),如果追加序列化就会导致出现多个头结点,从而出现异常!所以如果要实现对象的追加,就只能出现一个头,解决方法就是先判断文件是否存在且为空。如果不存在,就先创建文件,当文件内容为空就正常写入第一个对象,也写入了头aced 0005。追加的时候就需要判断文件不为空时,要把那个4个字节的头aced 0005截取掉,然后在把对象写入到文件,这样就实现了对象序列化的追加。

但是这种方法每一次都需要进行复杂的去头操作,显然太繁琐了,在需求分析时提到用一个集合来存储对象,再把集合作为一个大的对象进行序列化,这样巧妙的避免了序列化追加对象所产生多个头的问题。并且在集合里进行操作更便于我们提取数据以及存储数据。鉴于图书管理系统是使用IO流知识点来实现的,那么对象序列化流就正好能满足我们的要求,整个图书管理系统贯穿了对象序列化和对象反序列化,所有数据的存储以及提取都离不开序列化,因此,我们把对象序列化与反序列化封装成为方法。
2、序列化集合在使用集合前需要先加载文件内容到集合
集合存储了对象的数据,在使用集合时,一开始集合里面是没有对象数据的,所以每次使用集合前都必须先把文件内容反序列化到集合,这个时候集合里面才有了数据,而这些数据正式通过集合添加的对象序列化到文件中的,其实理解起来就是,把集合序列化到文件中了,就相当于集合把数据借给了文件,那么集合就没有这些数据了,下次需要通过集合使用数据时,就需要文件把数据先还给集合,这时集合才有了数据。同时需要注意在反序列化文件前要确保文件存在并且不为空,如果反序列化一个空文件会出现异常。
//当文件存在且文件内容为空时先序列化
if (file.exists() && file.length() == 0) {
ReaderType rt = new ReaderType(typeid, typename, limit, maxborrownum);
array.add(rt);
ObjectOutputStream oos = new ObjectOutputStream(new FileOutputStream(file));
oos.writeObject(array);
oos.close();
System.out.println("添加成功!");
} else {
//反序列化文件内容加载到集合中
ObjectInputStream ois = new ObjectInputStream(new FileInputStream(file));
Object obj = ois.readObject();
ArrayList array = (ArrayList) obj;
boolean idflag = true;
for (ReaderType rt : array) {
if (typeid.equals(rt.getTypeid())) {
System.out.println("此读者类型编号已存在,请重新添加!");
idflag = false;
new SelectReaderType().addReaderType();
}
}
if (idflag) {
ReaderType rt = new ReaderType(typeid, typename, limit, maxborrownum);
array.add(rt);
ObjectOutputStream oos = new ObjectOutputStream(new FileOutputStream(file));
oos.writeObject(array);
oos.close();
System.out.println("添加成功!");
}
} 3、实体类需要实现Serializable接口以及指定serialVersionUID的值
在Java中只有实现了Serializable接口后, JVM才会在底层帮我们实现序列化和反序列化,如果不实现serializable接口则Java虚拟机则不会实现序列化。同时需要指定serialVersionUID的值。在用对象序列化流序列化了一个对象后,假如我们修改了对象所属的类文件,读取数据就会出问题,会抛出InvalidClassException异常。这是因为如果不显示指定serialVersionUID, JVM在序列化时会根据属性自动生成一个serialVersionUID, 然后与属性一起序列化, 再进行持久化或网络传输. 在反序列化时, JVM会再根据属性自动生成一个新版serialVersionUID, 然后将这个新版serialVersionUID与序列化时生成的旧版serialVersionUID进行比较, 如果相同则反序列化成功, 否则报错。而当我们给对象所属的类加一个serialVersionUID,即便更改了文件的内容,只要serialVersionUID相同,JVM进行比较时就不会报错。
public class Book implements Serializable {
private static final long serialVersionUID = 42L;
}三、项目实现
1、结构分析
在弄清楚用什么方法去完成整个项目后,应该着手整个项目的逻辑结构,明白具体要写什么,从哪开始写,每个模块之间的联系。
流程图:
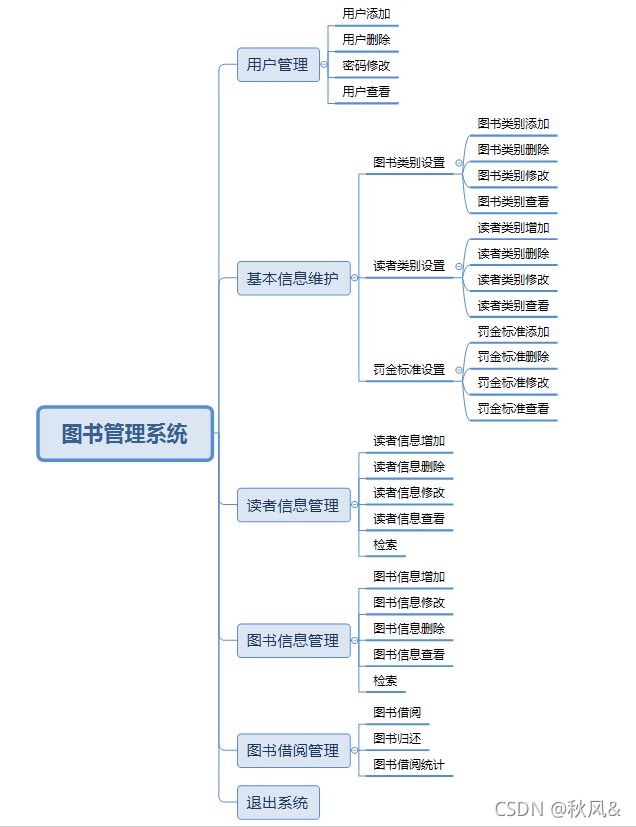
如图所示,整个图书管理项目都在进行增删改查,而增删改查的数据来源以及存储的地方,我们将使用对象序列化来实现。放在最前面的当然是登录注册功能,而其中,用户管理模块与其它四个模块是独立的,所以我们先从用户管理开始,而图书借阅管理涉及到了图书类型、读者类型、罚金标准、读者、图书这些实体,所以图书借阅应该放在最后写;读者,图书,又需要确定读者类型与图书类型,故而,基础信息维护模块应在用户管理后就要设置好。这样得到整个逻辑顺序为登录注册--用户管理--基础信息维护--读者信息管理--图书信息管理--图书借阅管理--退出系统。如此一来整个图书管理系统的流程就清晰明了了。
2、代码实现
整个项目的代码其实大同小异,但是都数据进行增删改查,我就不一一列举了,只演示一部分功能的代码了。
图书类型的设置代码演示:
//创建集合对象,指定文件路径
ArrayList array = new ArrayList<>();
File file = new File("ItemTwo\\src\\Data\\booktype"); 图书类型的添加:
//添加图书类型
public void addBookType() throws InterruptedException, IOException, ClassNotFoundException {
TSUtility.loadSpecialEffects();
System.out.println("开始添加图书类型!");
System.out.println("***************");
System.out.println("请输入图书类型编号!");
String typeid = TSUtility.readKeyBoard(12, false);
System.out.println("请输入图书类型名称!");
String typename = TSUtility.readKeyBoard(12, false);
//当文件存在且文件内容为空时先序列化
if (file.exists() && file.length() == 0) {
BookType bt = new BookType(typeid, typename);
array.add(bt);
ObjectOutputStream oos = new ObjectOutputStream(new FileOutputStream(file));
oos.writeObject(array);
oos.close();
System.out.println("添加成功!");
} else {
ObjectInputStream ois = new ObjectInputStream(new FileInputStream(file));
Object obj = ois.readObject();
ArrayList array = (ArrayList) obj;
boolean idflag = true;
for (BookType bt : array) {
if (typeid.equals(bt.getTypeid())) {
System.out.println("此图书类型编号已存在,请重新添加!");
idflag = false;
new SelectBookType().addBookType();
}
}
if (idflag) {
BookType bt = new BookType(typeid, typename);
array.add(bt);
ObjectOutputStream oos = new ObjectOutputStream(new FileOutputStream(file));
oos.writeObject(array);
oos.close();
System.out.println("添加成功!");
}
}
} 图书类型的删除:
//删除指定类型编号的图书类型
public void deleteBookType() throws IOException, ClassNotFoundException {
System.out.println("开始图书类型的删除!");
System.out.println("请输入需要删除的图书类别编号!");
String typeid = TSUtility.readKeyBoard(12, false);
ObjectInputStream ois = new ObjectInputStream(new FileInputStream(file));
Object obj = ois.readObject();
ArrayList array = (ArrayList) obj;
boolean delete = true;
for (BookType bt : array) {
if (typeid.equals(bt.getTypeid())) {
array.remove(bt);
ObjectOutputStream oos = new ObjectOutputStream(new FileOutputStream(file));
oos.writeObject(array);
oos.close();
System.out.println("删除成功!");
delete = false;
break;
}
}
if (delete) {
System.out.println("无此图书类别编号,请核对后操作!");
}
} 图书类型的修改:
//修改指定编号的图书类型信息
public void modifyBookType() throws IOException, ClassNotFoundException {
System.out.println("开始图书类型的修改!");
System.out.println("请输入你需要修改的图书类别的编号");
String typeid = TSUtility.readKeyBoard(12, false);
ObjectInputStream ois = new ObjectInputStream(new FileInputStream(file));
Object obj = ois.readObject();
ArrayList array = (ArrayList) obj;
boolean modify = true;
for (BookType bt : array) {
if (typeid.equals(bt.getTypeid())) {
System.out.println("请输入你将要修改的图书类别名称!");
String newtypeid = TSUtility.readKeyBoard(6, false);
bt.setTypename(newtypeid);
ObjectOutputStream oos = new ObjectOutputStream(new FileOutputStream(file));
oos.writeObject(array);
oos.close();
modify = false;
System.out.println("修改成功!");
break;
}
}
if (modify) {
System.out.println("无此图书类别编号,请核对后操作!");
}
} 图书类型的查看:
//查询所有图书类型信息
public void allBookType() throws IOException, ClassNotFoundException {
//反序列化文件内容
ObjectInputStream ois = new ObjectInputStream(new FileInputStream(file));
Object obj = ois.readObject();
ArrayList array = (ArrayList) obj;
for (BookType bt : array) {
System.out.println("图书类别编号:" + bt.getTypeid() + ",图书类别:" + bt.getTypename());
}
}
//查询指定类型名的图书类型信息
public void appointBookType() throws IOException, ClassNotFoundException {
System.out.println("请输入你要查询的图书类别");
String booktype = TSUtility.readKeyBoard(12, false);
ObjectInputStream ois = new ObjectInputStream(new FileInputStream(file));
Object obj = ois.readObject();
ArrayList array = (ArrayList) obj;
boolean appoint = true;
for (BookType bt : array) {
if (booktype.equals(bt.getTypename())) {
System.out.println("查询的图书类别信息如下:");
System.out.println("图书类别编号:" + bt.getTypeid() + ",图书类别:" + bt.getTypename());
appoint = false;
break;
}
}
if (appoint) {
System.out.println("无此图书类别,请核对后操作!");
}
} 从这段代码中可以看出其实都是在进行序列化与反序列化,增删改查的实现但是在集合中完成的,数据都是通过文件反序列化到集合,然后遍历集合得到的,遍历时要注意一个地方,应为集合里面存储的是一个对象,所以导致只会判断第一条数据是否满足,而后的数据就会直接进入else里面,那么就不能直接else;而应该把所有满足条件遍历得到在结束,那么要实现查找所有数据后还是没有满足条件的就可以使用一个Flag作为阀门,在遍历时只要有数据满足条件,Flag就变为false,若Flag一直为true就说明所有数据均不满足条件。
四、项目心得
1、remove与delete的区别
在进行集合的删除时发现集合的remove与文件的delete是不一样的,所以特意去查询了一下。
delete()方法主要用在文件操作上,用于删除文件或文件夹,语法如下File file=new File("文件名或目录名");file.delete(); remove()方法:主要用在集合上,对于集合中的元素进行移除。
2、return与break的区别
return;表示结束当前方法。
break;可以使流程跳出switch语句体,也可以用break语句在循环结构终止本层循环体,从而提前结束本层循环。
3、传参的使用
//读取罚金设置文件内容返回罚金标准
public String fine(String typename) throws IOException {
//把罚金设置文件的内容加载到集合中
BufferedReader br = new BufferedReader(new FileReader("ItemTwo\\src\\Data\\fine"));
Properties p = new Properties();
p.load(br);
String value;
try {
value = p.getProperty(typename);
} catch (Exception e) {
System.out.println("无此类型的罚金标准");
return null;
}
br.close();
return value;
}
//返回读者类型规定的最大可借天数
ReaderType readertype = readertype(readerid);
int limit = Integer.parseInt(readertype.getLimit());
int Intday = (int) day;
//返回读者类型
String typename = readertype.getTypename();4、运行过程

You work hard all the end ,worthy of the way of the displaced.