使用 Python爬虫+OpenCV 通过摄像头来 二维码识别 从而实时检测健康码状态(获取JS动态数据)
使用 Python爬虫+OpenCV 通过摄像头来 二维码识别 从而实时检测健康码状态(获取JS动态数据)
- 1. 环境准备
- 2. 二维码识别 部分
-
-
- 1> OpenCV 代码框架:
- 2> pyzbar 二维码解析:
-
- 3. 爬虫 部分
-
-
- 1> 试手1:
- 2> 试手2:
-
- 理论部分:
- 代码部分:
-
- 4. 源码
Notes:
看到 CSDN上 健康码识别 基本都是通过 OpenCV 色块检测 + OCR AI文字识别检测时间 的 方式 来进行 健康码状态的识别。嗯,我感觉…这个好像不是很靠谱… 毕竟健康码和图片文字是可以伪造的。或者说 如果你用 不久前的 截图 不就可以萌混过关了嘛 。。。
ο(=• ω <=)づ☆.。欸嘿~~~
所以 我想试试 能不能 通过获取二维码的实际数据来判断 健康码是否是真的健康
所以这里 使用 上海的 随申码 来做样例。
- 整体步骤:二维码识别 ----> 爬虫获取健康码状态数据 ----> Json 解析成 人看的
1. 环境准备
- 所需Python模块:
<1> pyzbar ----> 二维码解析
<2> requests ----> 爬虫
<3> OpenCV ----> 获取图像
<4> ast ----> 字符串 转 字典
from pyzbar import pyzbar
import requests
import cv2
import ast
2. 二维码识别 部分
这里我使用了 电脑摄像头来进行 识别。
1> OpenCV 代码框架:
cap = cv2.VideoCapture(0) # 参数 = 0 为开启电脑摄像头, 若填路径则为开启视频文件
isOpened = cap.isOpened() # 判断摄像头是否正常开启
while isOpened:
flag, frame = cap.read()
# 二维码解析 部分
# 爬虫 程序
if cv2.waitKey(1) == ord("q"):
break
这里简要解释一下 OpenCV 这里的代码含义:
- 通过 cap = cv2.VideoCapture(0) 开启摄像头 并套入循环 从而 通过 cap.read 不断获取摄像头每帧的图片,这里的 frame 即为图片数据,flag 为 是否成功读取到 图片。
-
这串代码 功能 为 按 q 键 停止运行摄像头if cv2.waitKey(1) == ord("q"): break
2> pyzbar 二维码解析:
bacodes = pyzbar.decode(frame, symbols=[pyzbar.ZBarSymbol.QRCODE])
for bacode in bacodes:
url = bacode.data.decode("UTF-8")
解释一下 这里的代码含义:
通过之前 OpenCV 摄像头 获取的图片数据 frame 传入给 pyzbar.decode()函数 来解析,在这里我们可以获取到 二维码 所指向的 目标地址 data 以及 二维码坐标 和 长宽大小,我们这里 直接取 data 指向的 网址 通过
for bacode in bacodes:
url = bacode.data.decode(“UTF-8”)
来获取到 目标网址 url (这里要 声明是 UTF-8 编码的)
url = ‘https://s.sh.gov.cn/XXXXXXXXXXXXXXXXXXXXXXX’
如果 你打开这里网址 你会发现 这里会直接给出 你的 健康码状态
嗯,非常好!那么 我们如果直接 获取其html数据 不就能准确判定 了嘛。。

3. 爬虫 部分
好!优势在我
这就动手,先在上面那个网页中 F12 凑一眼 定位一下这个 “绿色”

搜噶 搜噶 ,原来 在这个 id = “app” 的 div里头啊
好! 导入requests模块来获取url地址下的整体数据凑一眼试试
1> 试手1:
(这里还是 需要声明是 UTF-8 编码的)
tar_req = requests.get(tar_url, 'lxml') # 使用 lxml 来解析
tar_req.encoding = 'utf-8'
print(tar_req.text)
嗯嗯。。嗯?。。嗯????
内容呢???

wait。。wait,stay cool
先看看 html源码

emm… 好像这里官方用了 Ajax 异步加载,通过JavaScript 动态生成了网页内容
2> 试手2:
理论部分:
既然它 通过 js 动态渲染了,那么 这里我们需要去 找到 对应的 JS文件所实时返回的 数据接口。接下来就是 愉快的解密环节
老方法,游览器中 F12 一下
- 首先打开网页调试工具
- 进入network 选项卡
- 选择xhr类型
- 刷新一下网页页面
- 找到xhr类的文件
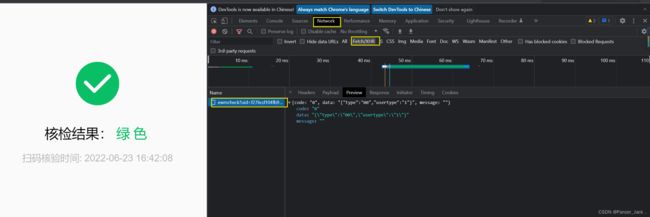
嗯 这里就存在唯一 一个文件,我们点击它打开 就能如图所示
这里我们 可以看到 三个数据类别:code , data , message
其中只有 code 和 data 存在 有用信息,那么这两个哪个是我们需要的信息呢?
啊。。。好像二维码过期了
(所以这里申明一下,健康码好像是每分钟都会重新刷新一次)

看来我们得 重新识别一下二维码了。。
等等!wait!这里 code :“1” 了
看来我们可以确定一点 code 是用来 判断 二维码是否有效的参数

那么 我们可以锁定 我们所需要的数据 应该是 在 data 里面
data里包含了 2个数据 “type”:“00” 和 “usertype”:"1
因为 我没有 红码的小伙伴帮忙做对比,那么只能通过查询JS 源码 来 确认数据了
之前 我们看 html源码 可以知道 我们数据 是 藏在 id = “app” 的 div 里头
所以 这里 我们 还是将 刚刚 的 xhr类 换成 all 可以看到 有个 app.xxx.js的文件在实时数据里面,我们点开它

ctrl + F 打开代码搜索,我们搜索一下 type的值 “00”
啊! 一步到位, 这里我们 获取到了 三个 高度相关数据
好 type = 高度嫌疑犯
![]()


另一个 “usertype”:“1” 我也试了下,发现查出来的数据 好像 并没有多少相关性
那么 我们先暂定 这个 type 的值 应该就是 判定黄码 绿码 红码 的 关键值
之后,先找找有没有相关的 官方API 说明

啊! 还真有个。。。 结合 上面我们自己解析的JS源码数据,我们可以定位 这个 type值 就是 判定信息的关键。
既然是Ajax 异步加载 , 那么我们需要通过 获取实时的 xhr 数据 来得到我们想要的type值。因此 这里我们需要得到动态数据接口,还是老位置xhr,我们打开 它的Headers数据

得到了 Request URL地址,那么我们只需要使用爬虫直接访问到这个URL 就能得到我们想要的 JSON数据了。但是 Wait!我们刚刚提到过 一个很关键的一点:健康码是动态变化的,每分钟 他都会重新刷新一遍,因此 又到解密环境了。
![]()
通过几次健康码刷新后的对比 可以得出 它的这个uid 的值 是变化的,那么我们只需要得到这个uid的值即可
得到这个uid 其实也很简单,我们可以通过访问健康码二维码的data指向网址就可以观察出了(这里可以回到上文二维码识别的 2> pyzbar 二维码解析部分去看看)
url = ‘https://s.sh.gov.cn/XXXXXXXXXXXXXXXXXXXXXXX’
通过观察 二维码所指向的网址 中 XXXXXXXXXXX 部分 和 uid = xxxxxxxxxxx 是相同的
那么我们秩序与写个 算法 来分割字符串 取出其中的 xxxx 就行了
代码部分:
通过字符串切割 取出 uid 的值,构建 实时数据地址
uid = url[str(url).find(".cn/") + 4:]
tar_url = f"https://suishenmafront1.sh.gov.cn/smzy/yqfkewm/ssm/ewmcheck?uid={uid}"
访问目标地址 并print出来
tar_req = requests.get(tar_url, 'lxml')
tar_req.encoding = 'utf-8'
print(tar_req.text)

ok 了! 不过。。这个反斜杠。。。可真丑!
那么 我们需要将这个 翻译成 人看的 (json转python)
tar_json = tar_req.json()
print(tar_json)

好,到这里 我们终于达成了 我们的目的。不过这里有个需要说明的 我们所需要的type 被 usertype 一起混进了一个字符串里头了, 所以如果这里我们光光通过 tar_json = tar_req.json()[“data”][“type”]来取出 我们需要的元素是不可能的 ----------> “TypeError” ,因此在这里我们就需要使用到 ast 模块 来将 字符串 转成 字典再取出type
tar_json = ast.literal_eval(tar_req.json()["data"])["type"]
到这里 我们终于得到了我们所想要得到的 健康码判定值了
4. 源码
源码开源到 我的 Github 上了 :
https://github.com/Panzer-Jack/Health-QRcode-Detect