推荐算法之DeepFM
前言
今天的模型是DeepFM,这算是一个非常经典的模型了。在介绍这个模型之前先针对之前模型的不足进行一个小总结,这也是DeepFM模型提出来的一个原因。
CTR预测任务中, 高阶特征和低阶特征的学习都非常的重要。 推荐模型我们也学习了很多,基本上是从最简单的线性模型(LR), 到考虑低阶特征交叉的FM, 到考虑高度交叉的神经网络,再到两者都考虑的W&D组合模型。 其实这些模型又存在着自己的问题,也是后面模型不断需要进行改进的原理,主要有下面几点:
- 简单的线性模型虽然简单,同样这样是它的不足,就是限制了模型的表达能力,随着数据的大且复杂,这种模型并不能充分挖掘数据中的隐含信息,且忽略了特征间的交互,如果想交互,需要复杂的特征工程。
- FM模型考虑了特征的二阶交叉,但是这种交叉仅停留在了二阶层次,虽然说能够进行高阶,但是计算量和复杂性一下子随着阶数的增加一下子就上来了。所以二阶是最常见的情况,会忽略高阶特征交叉的信息
- DNN,适合天然的高阶交叉信息的学习,但是低阶的交叉会忽略掉,并且不能够实时的进行更新参数,而且记忆能力较弱。
- W&D模型进行了一个伟大的尝试,把简单的LR模型和DNN模型进行了组合, 使得模型既能够学习高阶组合特征,又能够学习低阶的特征模式,但是W&D的wide部分是用了LR模型, 这一块依然是需要一些经验性的特征工程的,且Wide部分和Deep部分需要两种不同的输入模式, 这个在具体实际应用中需要很强的业务经验。
所以DeepFM也就应运而生了,老规矩先看一下知识脉络图:
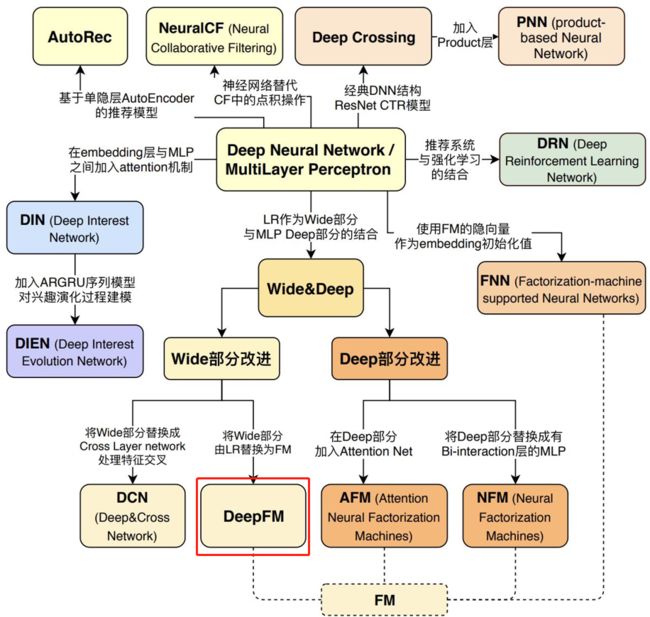
一、DeepFM模型原理
DeepFM是2017年哈工大和华为公司联合提出的一个模型,用一句话来进行概括那就是将W&D中的wide部分由LR换成了FM。其实就是这么简单,但是仅仅知道这个还是远远不够的,这篇论文中还存在着很多细节,以及对推荐系统的理解。
首先先来看一下DeepFM具体的模型图吧:
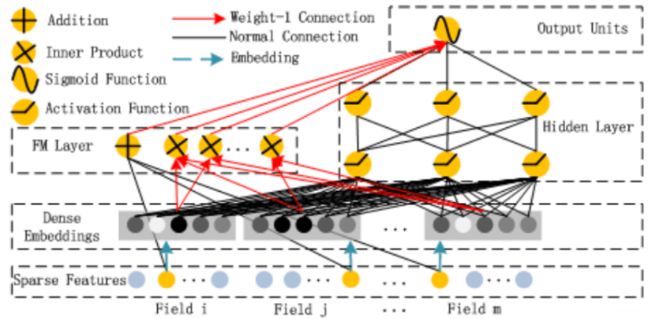
这个模型也是两部分组成, 左边的FM+右边的DNN, 结构也不是很复杂,和W&D和DCN 模型长得都很像, DNN部分都没改,主要是Wide部分, W&D采用了LR, Deep&Cross采用了一个Cross的交叉网络,而这里采用了FM, 后两者都是针对于W&D的wide不具备自动特征组合能力的缺陷进行改进的。DeepFM的运算过程也比较简单, 左边的FM和右边的DNN共享相同的Embedding层的输入(这个要和W&D进行区分, 不单单是FM替换Wide那么简单,模型的输入模式上也进行了改进), 左侧的FM对不同特征域的Embedding进行了两两交叉(这里的Embedding向量当成了原FM的特征隐向量,也就是输入,对于FM的参数还需要通过梯度下降求解), 右边的DNN对特征Embedding进行了深度交叉, 最后将FM的输出与Deep部分的输出一起送入最后的输出层,参与最后的目标拟合, 公式如下:
![]()
上面还有个小细节不知道注意到了没有,就是红线和黑线的区别, 上面的黑线表示的是embedding这里的这些参数是通过深度神经网络这边进行更新的, 而更新好了之后, FM这端直接拿过来用, 也就是红线这部分是直接拿过来用就行了,不同进行参数更新这样的操作了。
二、Embedding
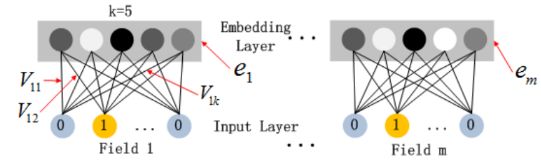
关于输入,包括离散的分类特征域(如性别、地区等)和连续的数值特征域(如年龄等)。分类特征域一般通过one-hot或者multi-hot(如用户的浏览历史)进行处理后作为输入特征;数值特征域可以直接作为输入特征,也可以进行离散化进行one-hot编码后作为输入特征。对于每一个特征域,需要单独的进行Embedding操作,因为每个特征域几乎没有任何的关联,如性别和地区。而数值特征无需进行Embedding。与Wide&Deep不同的是,DeepFM中的Wide部分与Deep部分共享了输入特征,即Embedding向量。
Embedding layer长这样:
三、FM
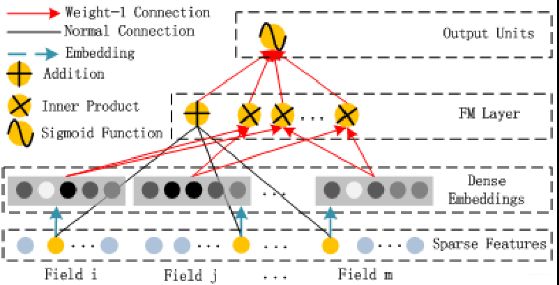
这个感觉不必多说了, 和FNN一样,这里依然是一个标准的FM模型,负责特征之间的低阶交互过程,FM的输出是Addition单元和Inner Product units的加和, Addition单元反映1阶特征各自的影响, 而Inner product代表2阶特征交互的影响。
与FNN不同, FM这里的隐向量参数是直接和神经网络的参数一样,都是当做学习参数一块学习的,这样就省去了FM的预训练过程,而是以端到端方式训练整个网络。 且这种训练方式还有个好处,就是作者发现通过高阶和低阶交互特征一块来进行反向传播更新参数反而会使得模型表现更佳,当然,这个也依赖于共享Embedding输入的策略。
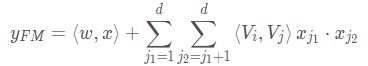
四、论文细节
问题一:什么是特征交互,为什么要进行特征交互?
- 二阶特征交互:通过对主流应用市场的研究,我们发现人们经常在用餐时间下载送餐的应用程序,这就表明应用类别和时间戳之间的(阶数-2)交互作用是CTR预测的一个信号。
- 三阶或者高阶特征交互:我们还发现男性青少年喜欢射击游戏和RPG游戏,这意味着应用类别、用户性别和年龄的(阶数-3)交互是CTR的另一个信号。
- 根据谷歌的W&D模型的应用, 作者发现同时考虑低阶和高阶的交互特征,比单独考虑其中之一有更多的改进
问题二:为啥人工特征工程有挑战性?
- 一些特征工程比较容易理解,就比如上面提到的那两个, 这时候往往我们都能很容易的设计或者组合那样的特征。 然而,其他大部分特征交互都隐藏在数据中,难以先验识别(比如经典的关联规则 "尿布和啤酒 "就是从数据中挖掘出来的,而不是由专家发现的),只能由机器学习自动捕捉,即使是对于容易理解的交互,专家们似乎也不可能详尽地对它们进行建模,特别是当特征的数量很大的时候.。
第三个就是作者在这里对之前的PNN, FNN和W&D与自己提出的DeepFM进行了对比:
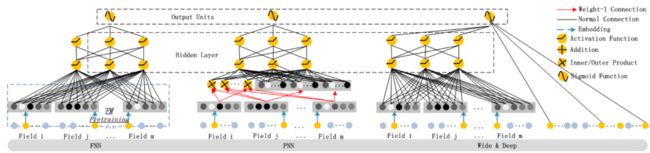
这里再简单的总结一下:
FNN模型: 预训练的方式增加了开销,模型能力受限于FM表征能力的上限,且只考虑了高阶交互
PNN模型:IPNN的内积计算非常复杂, OPNN的外积近似计算损失了很多信息,结果不稳定, 且同样忽视了低阶交互
W&D模型:虽然是考虑到了低阶和高阶交互,兼顾了模型的泛化和记忆,但是Wide部分输入需要专业的特征工程经验,作者这里还举了个例子,比如用户安装应用和应用推荐中曝光应用的交叉,这个需要一些强的业务经验。
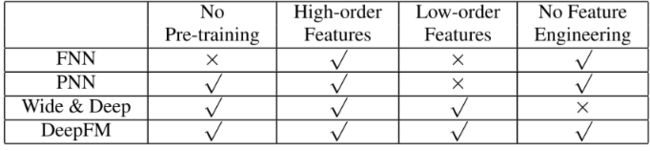
所以DeepFM同时考虑了上面的这些问题, 用FM换掉了W&D的LR,并Wide部分和Deep部分通过低阶和高阶特征交互来影响特征表示,从而更精确地对特征表示进行建模的策略共享了特征Embedding, 解决了上面的问题。 一个小图进行总结:
下面依然是工业上的一些使用经验, 这个模型也是工业上常用的模型:
- MLP这端神经网络的层数, 工业上的经验值不超过3层,一般用两层即可。
- MLP这端隐藏神经元的个数,工业上的经验值,一般128就差不多,最多不超过500
- embedding的维度一般不要超过50维, 经验值10-50
五、模型复现
import torch
import torch.nn as nn
import torch.nn.functional as F
import warnings
warnings.filterwarnings('ignore')
class FM(nn.Module):
"""FM part"""
def __init__(self, latent_dim, fea_num):
"""
latent_dim: 各个离散特征隐向量的维度
input_shape: 这个最后离散特征embedding之后的拼接和dense拼接的总特征个数
"""
super(FM, self).__init__()
self.latent_dim = latent_dim
# 定义三个矩阵, 一个是全局偏置,一个是一阶权重矩阵, 一个是二阶交叉矩阵,注意这里的参数由于是可学习参数,需要用nn.Parameter进行定义
self.w0 = nn.Parameter(torch.zeros([1, ]))
self.w1 = nn.Parameter(torch.rand([fea_num, 1]))
self.w2 = nn.Parameter(torch.rand([fea_num, latent_dim]))
def forward(self, inputs):
# 一阶交叉
first_order = self.w0 + torch.mm(inputs, self.w1) # (samples_num, 1)
# 二阶交叉 这个用FM的最终化简公式
second_order = 1 / 2 * torch.sum(
torch.pow(torch.mm(inputs, self.w2), 2) - torch.mm(torch.pow(inputs, 2), torch.pow(self.w2, 2)),
dim=1,
keepdim=True
) # (samples_num, 1)
return first_order + second_order
class Dnn(nn.Module):
"""Dnn part"""
def __init__(self, hidden_units, dropout=0.):
"""
hidden_units: 列表, 每个元素表示每一层的神经单元个数, 比如[256, 128, 64], 两层网络, 第一层神经单元128, 第二层64, 第一个维度是输入维度
dropout = 0.
"""
super(Dnn, self).__init__()
self.dnn_network = nn.ModuleList(
[nn.Linear(layer[0], layer[1]) for layer in list(zip(hidden_units[:-1], hidden_units[1:]))])
self.dropout = nn.Dropout(dropout)
def forward(self, x):
for linear in self.dnn_network:
x = linear(x)
x = F.relu(x)
x = self.dropout(x)
return x
class DeepFM(nn.Module):
def __init__(self, feature_columns, hidden_units, dnn_dropout=0.):
"""
DeepFM:
:param feature_columns: 特征信息, 这个传入的是fea_cols
:param hidden_units: 隐藏单元个数, 一个列表的形式, 列表的长度代表层数, 每个元素代表每一层神经元个数
"""
super(DeepFM, self).__init__()
self.dense_feature_cols, self.sparse_feature_cols = feature_columns
# embedding
self.embed_layers = nn.ModuleDict({
'embed_' + str(i): nn.Embedding(num_embeddings=feat['feat_num'], embedding_dim=feat['embed_dim'])
for i, feat in enumerate(self.sparse_feature_cols)
})
# 这里要注意Pytorch的linear和tf的dense的不同之处, 前者的linear需要输入特征和输出特征维度, 而传入的hidden_units的第一个是第一层隐藏的神经单元个数,这里需要加个输入维度
self.fea_num = len(self.dense_feature_cols) + len(self.sparse_feature_cols) * self.sparse_feature_cols[0][
'embed_dim']
hidden_units.insert(0, self.fea_num)
self.fm = FM(self.sparse_feature_cols[0]['embed_dim'], self.fea_num)
self.dnn_network = Dnn(hidden_units, dnn_dropout)
self.nn_final_linear = nn.Linear(hidden_units[-1], 1)
def forward(self, x):
dense_inputs, sparse_inputs = x[:, :len(self.dense_feature_cols)], x[:, len(self.dense_feature_cols):]
sparse_inputs = sparse_inputs.long() # 转成long类型才能作为nn.embedding的输入
sparse_embeds = [self.embed_layers['embed_' + str(i)](sparse_inputs[:, i]) for i in
range(sparse_inputs.shape[1])]
sparse_embeds = torch.cat(sparse_embeds, dim=-1)
# 把离散特征和连续特征进行拼接作为FM和DNN的输入
x = torch.cat([sparse_embeds, dense_inputs], dim=-1)
# Wide
wide_outputs = self.fm(x)
# deep
deep_outputs = self.nn_final_linear(self.dnn_network(x))
# 模型的最后输出
outputs = F.sigmoid(torch.add(wide_outputs, deep_outputs))
return outputs
hidden_units = [128, 64, 32]
dnn_dropout = 0.
model = DeepFM(fea_cols, hidden_units, dnn_dropout)参考:翻滚的小强