开源开放 | 一个用于文言文实体识别与关系抽取等任务的开源数据集C-CLUE(CCKS2021)...
OpenKG地址:http://openkg.cn/dataset/c-clue
GitHub地址:https://github.com/jizijing/C-CLUE
网站地址:http://152.136.45.252:60002/pages/login.html
开放许可协议:CC BY-SA 4.0 (署名相似共享)
贡献者:天津大学(王鑫,季紫荆,申雨鑫,孙毅宁,雨田)
1. 介绍
“二十四史”是中国古代各朝撰写的二十四部史书的总称,记录了丰富的历史人物和事件。由于古代汉语和现代汉语在语义和语法上存在较大差异,识别史书中的实体和关系耗时耗力,因此我们利用群体智慧,采用众包标注系统,并通过引入领域知识来实现高效准确的标注。根据系统的标注结果,可以得到一系列的实体和关系来构建文言文语言理解测评基准及数据集。
C-CLUE是一个基于众包标注系统构建的文言文语言理解测评基准及数据集,由天津大学数据库课题组贡献,包括建立在相应数据集上的细粒度命名实体识别(NER)任务和关系抽取(RE)任务,可用于微调当前自然语言处理(NLP)主流的预训练语言模型(PTM)并评估模型处理文言文的性能,同时能够为中国古代历史文献知识图谱构建提供数据支持。本次开源了从标注系统中获取的近2万个实体以及4千多个关系,并分割成训练集、校验集、测试集等文件,可供文言文NER和RE直接使用。
2. 众包系统设计
我们设计并构建了一个众包标注系统,该系统引入“二十四史”的全部文本(约4000万字),并允许用户标注实体和关系。与现有的众包系统不同,在理解和标注文言文语料时,我们在系统中注入领域知识,并通过引入专业度得到高精度标注。具体而言,该系统通过在线测试判断用户的专业度,并在结果整合和奖励分配阶段考虑用户的专业度。另外,不同于注重任务分配策略的众包系统,本系统向每个用户开放相同任务,即“二十四史”的内容,并允许用户选择感兴趣的章节,对同一文本进行不同的标注,以最大限度地发挥群体智慧。

图1 C-CLUE的构建框架图
1、专业度评测方法(Professional Evaluation Standard)
为了将领域知识注入众包标注系统,本系统引入大多数现有众包系统中没有考虑的用户专业度,并定义两种用户角色“专家标注用户(Expert Annotation User)”和“普通标注用户(Ordinary Annotation User)”,以及两种判断方法。
对于已知的专业度较高的用户,在将用户信息录入数据库时,直接将其角色定义为“专家标注用户”。
对于未知用户,系统准备了具有标准答案的测试题目,并要求用户在第一次登录时进行作答。专业度将根据用户答题的准确率和题目的难度综合计算:(1) 根据志愿者的答题情况定义每道题目的难度初始值,难度值随着答题用户数的增加而动态变化,表示为答错的用户数量与参与答题用户总数的比值(取值范围为[0,1]);(2) 题目分数与难度成正比,定义为难度乘10后进行向上取整(例如,难度值为0.24,题目分数为2.4向上取整,结果为3);(3) 将所有题目分数之和作为总分,如果用户的得分高于总分的60%,将其角色定义为专家标注用户,反之,则将定义为普通标注用户。
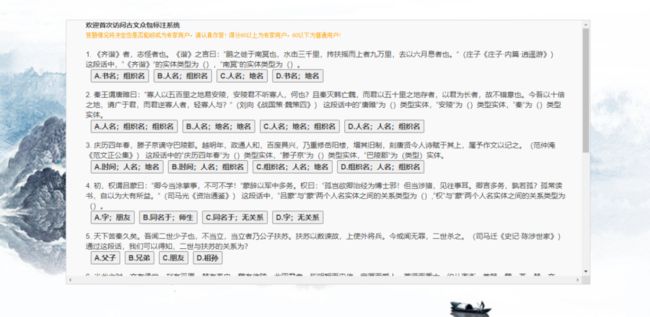
图2 众包标注系统中的用户专业度测试页面
2、答案整合机制(Answer Integration Mechanism)
对于需要领域知识的文言语料标注任务,专业度高的用户更有可能做出正确的标注。例如,历史系学生比其他系学生掌握更多专业知识,做出正确标注的概率更大。因此,不同于现有的多数投票策略或引入准确度的方法,为了确保结果的准确性,本系统充分考虑了用户的专业度。
该众包系统允许用户修改界面上的现有注释,并将用户id、标注时间以及标注内容等信息录入数据库。如果多个用户对同一个实体或实体对有不同的标注,将分别保存它们而不是覆盖之前的标注。在下载数据时,如果有多条记录对应同一文本,则进行考虑用户专业度的答案整合,具体来说,系统为专家标注用户赋予的权重是普通标注用户的两倍,并采用加权多数投票策略来获得最终结果。
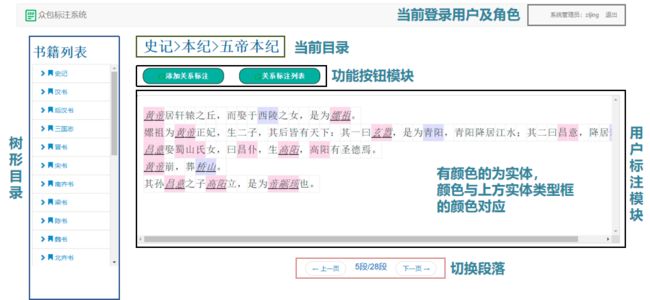
图3 众包标注系统中的用户标注页面
3、奖励分配策略(Crowdsourcing Reward Mechanism)
我们在现有众包系统的基础上,综合考虑专业度、标注准确率和标注数量,提出了一种新的奖励机制,并每隔固定时间结算一次奖励。
将答案整合后的最终结果视为正确结果,如果用户的标注与正确结果相同,则给予其奖励。对于专家标注用户,给予其双倍于普通标注用户的奖励。为了激励用户积极进行标注,该系统对标注的数量和正确率设置了阈值,并对超过该阈值的用户给予多倍奖励。
将一次标注的单价设为 ,标注数量阈值设为 ,标注准确率阈值设为 。如果一名普通标注用户在某一奖励分配周期内完成了n个标注,其中有效标注(与最终结果相同)为m个,且 , ,则该用户能够获得的奖励定义如下:
3. 基准及数据集
基于众包标注系统的实体和关系标注结果,我们构建了一个由NER和RE任务及其相应数据集组成的文言文语言理解基准。细粒度NER任务数据集由文本文件和标签文件组成,包括六类实体:人名、地名、组织名、职位名、书名和战争名。RE任务数据集包括七类关系:组织名-组织名、地名-组织名、人名-人名、人名-地名、人名-组织名、人名-职位名和地名-地名。
基于原始数据集,我们可以生成一个由句子和关系文件组成的关系分类数据集,以及一个类似于NER任务数据集的序列标记数据集。这时,生成的标签不再是实体类别标签,而是标志其为某关系的主体或客体的标签。
表1 用于命名实体任务数据集的统计数据
实体类型 |
训练集 |
校验集 |
测试集 |
总数 |
人名(PER) |
9,467 |
1,267 |
701 |
11,435 |
地名(LOC) |
2,962 |
391 |
167 |
3,520 |
职位名(POS) |
1,750 |
242 |
139 |
2,131 |
组织名(ORG) |
1,698 |
266 |
100 |
2,064 |
其他 |
110 |
18 |
9 |
137 |
表2 用于关系抽取任务数据集的统计数据
关系类型 |
训练集 |
校验集 |
测试集 |
总数 |
人名-人名(PER-PER) |
1,139 |
324 |
130 |
1,593 |
人名-组织名(PER-ORG) |
231 |
60 |
38 |
329 |
人名-地名(PER-LOC) |
462 |
129 |
53 |
644 |
人名-职位名(PER-POS) |
1,093 |
319 |
162 |
1,574 |
其他 |
157 |
40 |
28 |
225 |
4. 实验与结果
我们在基准测试中评估了以下预训练模型:BERT-base、BERT-wwm、Roberta-zh和Zhongkeyuan-BERT(在下文中缩写为ZKY-BERT)。基线模型的详细介绍请参考我们的github项目。
在微调阶段,除batch size、learning rate和training epoch外,其他超参数均与BERT预训练阶段所使用的相同。实验结果表明,能够在微调阶段获得较好效果的超参数取值如下,batch size:32;learning rate:5e-5,3e-5,2e-5;epoch:3-10。对于NER和RE任务,github项目中提供了详细的评估过程供读者参考。
表3 在六类实体数据集上的实验结果(%)
模型 |
准确率 |
召回率 |
F1 |
BERT-base |
29.82 |
35.59 |
32.12 |
BERT-wwm |
32.98 |
43.82 |
35.40 |
Roberta-zh |
28.28 |
34.93 |
31.09 |
ZKY-BERT |
33.32 |
42.71 |
36.16 |
表4 在四类实体数据集(去除了人名、地名、组织名、职位名外的其他实体)上的实验结果(%)
模型 |
准确率 |
召回率 |
F1 |
BERT-base |
44.33 |
53.60 |
48.11 |
BERT-wwm |
45.42 |
54.33 |
48.95 |
Roberta-zh |
45.40 |
53.00 |
48.61 |
ZKY-BERT |
44.35 |
53.69 |
48.09 |
从表3的结果可以看出,在处理细粒度NER时,在文言语料库上训练的ZKY-BERT模型表现最好,适应中文特点的BERT-wwm模型次之。从表4的结果可以看出,由于实体类型的减少,预训练模型都取得了相对较好的性能。
对于RE任务,我们将其拆分为两个子任务:关系分类和序列标记。实验表明,基线模型在关系分类任务上可以达到47.61%的准确率。
5. 结语及致谢
为了构建大规模、高质量的文言文知识图谱,我们设计并构建了一个引入领域知识的众包标注系统,实现了文言文语料中实体和关系的高精度抽取,并根据标注结果生成了一个文言文语言理解基准及NLP数据集,为构建中国历史文献知识图谱提供数据支持。最后,感谢中国高校产学研创新基金项目(2019ITA03006)和国家自然科学基金项目(61972275)对本项工作的资助。
OpenKG
OpenKG(中文开放知识图谱)旨在推动以中文为核心的知识图谱数据的开放、互联及众包,并促进知识图谱算法、工具及平台的开源开放。

点击阅读原文,进入 OpenKG 网站。