【阅读笔记】PPFL全面综述文章: A Comprehensive Survey of Privacy-preserving Federated Learning
PPFL全面综述
- 前言
- 一、个人拙见
-
- 1. 什么是联邦学习?
- 2. 联邦学习与分布式机器学习的区别
- 3. 联邦学习的应用与前景
- 二、综述解析
-
- 1. INTRODUCTION
-
- 1.1 Background
- 1.2 Motivation
- 1.3 Main Contributions
- 2. AN OVERVIEW OF FEDERATED LEARNING
-
- 2.1 Brief Introduction to FL
- 2.2 Categorization of Current FL Methods
-
- 2.2.1 Horizontal FL
- 2.2.2 Vertical FL
- 2.2.3 Federated Transfer Learning
- 2.3 Related Concepts
-
- 2.3.1 Distributed Machine Learning
- 2.3.2 Mobile Edge Computing
- 2.3.3 Split Learning
- 2.3.4 Privacy-preserving Machine Learning
- 3. OVERVIEW OF GENERIC PRIV ACY-PRESERVING MECHANISMS
-
- 3.1 Cryptographic Techniques
- 3.2 Perturbation Techniques
- 3.3 Anonymization Techniques
- 3.4 Privacy-preserving Metrics
- 4. PRIV ACY-PRESERVING FEDERATED LEARNING: A TAXONOMY AND REVIEW
-
- 4.1 Proposed 5W-Scenario-Based Taxonomy
- 4.2 Potential Privacy Leakage Risks in FL
-
- 4.2.1 Scenario 1: Who might be a malicious adversary?Insiders and outsiders
- 4.2.2 Scenario 2: What types of privacy attacks?Passive and active attacks
- 4.2.3 Scenario 3: When might a data privacy leakage occur?Training phase and inference phase
- 4.2.4 Scenario 4: Where might a data privacy leakage occur?Weight update, gradient update, and the final model
- 4.2.5 Scenario 5: Why might a malicious attacker launch an attack?Inference attacks, including inference of class representatives, memberships , properties of training data, and training samples and labels
- 4.3 PPFL Methods
-
- 4.3.1 Encryption-based PPFL
- 4.3.2 Perturbation-based PPFL methods
- 4.3.3 Anonymization-based PPFL
- 4.3.4 Hybrid Privacy-preserving Federated Learning
- 4.4 Summary of the Relationship between the Taxonomy and Latest Techniques
- 5. SUMMARY AND OPEN RESEARCH DIRECTIONS
- 三、总结
前言
其实文章的全称为 A Comprehensive Survey of Privacy-preserving Federated Learning: A Taxonomy, Review, and Future Direction,是一篇对面向隐私保护的联邦学习(PPFL)的一个全面的综述文章,也是我在开始毕业设计前阅读的第一篇联邦学习隐私保护问题的文献。其实在阅读这篇文献之前,我就已经把杨强教授的《联邦学习》拜读了两遍了,在我浅显地看来,杨教授的《联邦学习》也是对联邦学习的一个完整的综述,所有内容基本都在理论层面,并没有过多涉及到深入的算法和实现,这对密码学、数论知识匮乏的我也是一个不小的挑战,只能说有太多太多基础需要填充了,虽然前路漫漫,但是我并不迷茫,我一直坚信联邦学习将会是未来的发展趋势(或者说已经是了),前途无限,而我最需要做的,就是脚踏实地,紧跟大佬的步伐,在互联网领域闯出一片天地。
一、个人拙见
在分析这篇文章之前,我想就我理解的与联邦学习相关的知识分享给大家,一是回答一下我在前言中所提到的联邦学习的为何可以是发展的趋势,二是记录一下自己初识联邦学习的理解,以便日后自己批判,或者被广大读者批判,这样才能在批判中学习,在批判中成长。
1. 什么是联邦学习?
联邦学习,全名为联邦机器学习,也就是说,联邦学习的本质还是完成机器学习的任务,只不过在联邦的环境下。那么“联邦”怎么理解呢?我们以联邦制国家为例,联邦制是若干个单位联合组成的统一国家,它有如下特点:
- 国家整体与组成部分之间是一种联盟关系,联邦政府行使国家主权,是对外交往的主体。
- 联邦设有国家最高立法机关和行政机关,行使国家最高权力,领导其联邦成员。
- 实行联邦制的国家都认同于统一的联邦宪法,遵从代表国家利益的统一法律。
- 联邦各成员国有自己的立法和行政机关,有自己的宪法、法律和国籍,管理本国内的财政、税收、文化、教育等公共行政事务。
- 联邦和各成员国的权限划分,由联邦宪法规定。如果联邦宪法与成员国的宪法发生冲突,以联邦宪法和法律为准。
啰嗦了一大堆,其实联邦的本质就是利益,没有利益的交涉,就没必要组成联邦,分散不同地方的移动终端设备,就是联邦学习的参与方,他们共同组成联邦训练机器学习的模型,中间可以随时退出。联邦学习旨在建立一个基于分布数据集的联邦学习模型。
2. 联邦学习与分布式机器学习的区别
那么就会有人问了,那联邦学习不就是分布式机器学习吗,大不了再加上一些隐私保护的算法,为什么可以自成体系呢?这样的说法从形式上来看是对的,但是细究起来,从应用场景来看就是错的了。
分布式机器学习,应用的场景是对大规模数据的处理,通过分布式的方式解决内存限制的问题以及数据并行的问题,提高机器学习的效率与性能,这些分布式数据都存储在工作者部署的数据库中,就像是这些分布式数据库都是工作者的小弟一般,或者说分身更为精确,它们百分百听从工作者的指令,并且极少出现宕机、退出训练的情况(基本都是通信问题或者机器故障),它所面对的最大的威胁一般是分布式数据库与服务器通信时受到的外部攻击,比如中间参数、梯度的泄露,恶意第三方攻击等等,这个时候应用隐私保护算法可以在一定程度上保护通信数据,为分布式机器学习提供安全保障。
联邦学习不同,它所面对的都是未知的移动终端等设备,他们一般是半诚实的第三方,有些甚至是恶意的第三方,对于半诚实的设备(诚实且好奇的设备),他们随时可能会退出训练,或者发送一些无意义的数据,此外由于不同的移动终端数据集没有对齐,服务器对于这些数据或者模型的处理又是一个很麻烦的事情,这样复杂的应用场景,分布式机器学习是无法应付的,并且隐私保护在其中的地位也是万分重要。
在我看来,联邦学习的应用终端可以是亿万个移动终端,这样的广阔市场所带来的价值是不可估量的,这也是我对其特别看好的原因。
3. 联邦学习的应用与前景
联邦学习可以在金融,医疗,教育等场景大放异彩,因为随着法律法规的不断完善,这些特殊领域的用户数据会受到更加严格的保护,窃取数据所造成的后果是不可估量的,但是这样的数据孤岛所能够激发的价值又被弃之不用,略显可惜。联邦学习恰好解决了这样的痛点,在不泄露用户隐私的情况下,打破数据孤岛,进行模型训练,在医疗领域可以大力发展医疗AI,为患者提供更准确的病情判断以及更优质的疾病恢复,在金融领域可以可以帮助银行评估用户的信用等级,为用户定制个性化金融服务等等。此外,联邦学习的思想甚至符合人类社会的发展方向,比如共同致富的思想。在当前的市场中,存在许多垄断主义,造成了市场的极度不平衡,国家也很难对此实施有力的监管措施,但是如果在统一的联邦学习的体系下,那些大企业公司可以通过分享更加优秀的模型帮助那些微小企业发展,微小企业也会通过分享它所在特定小众领域的模型信息完善大企业的模型,达到“共同致富”的效果,这样的效果正符合社会主义发展的理念。总而言之,联邦学习就像是数据领域的“人类命运共同体”,打破数据领域的数据孤岛,让那些所谓的垄断主义都不复存在,帮助每个个体在隐私不被泄露的情况下,享受大数据时代所带来的便利。
二、综述解析
言归正传,回到综述本身,我将细致地解析整篇综述,并且在最后总结,提出自己的想法。文章摘要部分是对作者的介绍,三位来自新南威尔士大学的作者首先说明了联邦学习在过去几年发展迅速,也出现了新的隐私安全的问题,PPFL被认为是一种通用隐私保护机器学习的解决方案。但是在隐私保护和数据效用的平衡挑战仍然存在,他们利用提出的方法对PPFL进行了全面系统的研究,从五个方面分析了FL的隐私泄露风险,总结现有方法并明确未来的发展方向。
1. INTRODUCTION
1.1 Background
背景部分简单介绍了联邦学习的概念以及发展的三个原因:(1)机器学习的广泛应用;(2)大数据的爆发式增长;(3)世界范围数据隐私保护的法律法规。其中,机器学习的发展是主要的驱动力,大数据发展进一步推动机器学习的发展,隐私保护法律法规促进了隐私保护技术的发展。
1.2 Motivation
动机部分是表明写这篇综述的缘由,相当于Research Gap,补充过去研究的不足。因为当前讨论FL大部分关注点还是放在通信成本,系统异质性,效率与有效性等,相关调查并没有对FL的隐私保护方面提供一个全面的审查。所以有必要对PPFL进行全面的调查,回顾最新的调查结果,指出存在的差距,并指出未来PPFL的研究方向。
1.3 Main Contributions
在本文提出的5W-scenario-based分类法下对PPML进行了全面的调查。,并带来以下四点贡献:
- 5W-scenario-based分类法全面系统分析了FL中的隐私泄露风险;
- 总结了最先进的PPFL方法,包括:基于加密的,基于扰动的,基于匿名的和混合的PPFL;
- 提供了一个对FL和通用隐私保护机制的明确概述,从隐私保护技术和隐私保护指标两个方面介绍了通用的隐私保护机制;
- 讨论了PPFL的挑战,明确了现有的差距,确定了开放的研究问题,并指出了未来的研究方向。
最后就是对剩余部分的介绍,先是第二节对FL的概述,第三节通用隐私保护机制的介绍,接着是第四节使用提出的5W-scenario-based分类法对PPFL分类,并分析潜在对的隐私泄露风险,最后是总结展望。
2. AN OVERVIEW OF FEDERATED LEARNING
FL的关键思想是在分布于不同设备或组织的数据集上训练机器学习模型,同时试图保护数据隐私。FL的研究重点可以大致分类为三点:(1)提高FL的效率和有效性;(2)提高FL的安全性;(3)改善私有用户数据的隐私保护,避免泄露。本节从介绍FL开始,根据数据分区和通信架构提供对FL方法的分类,最后将FL与一些相关概念进行了简要的比较。
2.1 Brief Introduction to FL
简单介绍FL,是一种机器学习技术,目标是分布在独立节点上的多个数据集上协作训练一个全局机器学习模型,而无需各个节点之间显示交换数据样本。
至于有效性定义,就是联邦学习协作完成的模型所得到的精度要比各个客户端在本地训练的模型要高。
δ-Accuracy的定义:就是FL在分布式节点协作得到的模型与传统数据集合上训练的模型精度的差值在δ以内,则说明该FL具有δ-精度损失。
FL系统中有两个主要角色,客户端和服务器,在一些特殊的FL中,服务器是由某些客户端扮演,FL训练过程分为三步:
- 服务器初始化参数,激活客户端,广播全局模型,分配计算任务;
- 在客户端进行本地模型训练和更新。客户端接收全局模型信息并使用本地数据集更新本地模型参数,完成训练后将本地模型参数发送到服务器融合;
- 服务器全局模型融合和更新。服务器首先聚合所选客户端发送的信息,然后将更新的信息发送回客户端,最终目标是获得全局最优模型参数。
满足终止条件(到达迭代次数或者准确度大于阈值),服务器终止训练,聚合更新并将全局模型分发给所有客户端。下面是伪代码实现的具体例子:

最后总结四点如下:
- FL系统有两个主要角色:数据持有者的客户机,全局模型的服务器;
- FL通过在客户机和服务器之间共享模型参数来训练全局模型;
- FL具有数据不共享的特点,为隐私保护训练提供了潜在解决方案;
- 在独立数据集上协同训练的FL模型的准确性应该接近于在包含所有这些独立数据集的数据集上训练的传统模型的准确性。
2.2 Categorization of Current FL Methods
该小节根据基于数据分区和通信架构的分类,总结了当前的FL方法。公式说明的部分比较繁琐,我就直接概括了,一共被分为了三种联邦学习的方法:横向联邦学习、纵向联邦学习、迁移联邦学习。
横向联邦学习数据集样本中,数据ID很少有重合的,但是特征空间重合多,它类似于数据在表格视图中将数据水平划分的情况。举例来说,两个地区的城市商业银⾏可能在各⾃的地区拥有⾮常不同的客户群体,所以他们的客户交集⾮常⼩,他们的数据集有不同的样本ID。然⽽,他们的业务模型⾮常相似,因此他们的数据集的特征空间是相同的。这两家银⾏可以联合起来进⾏横向联邦学习以构建更好的风控模型。横向联邦学习的数据特征和标签关系可视化如下图所示:
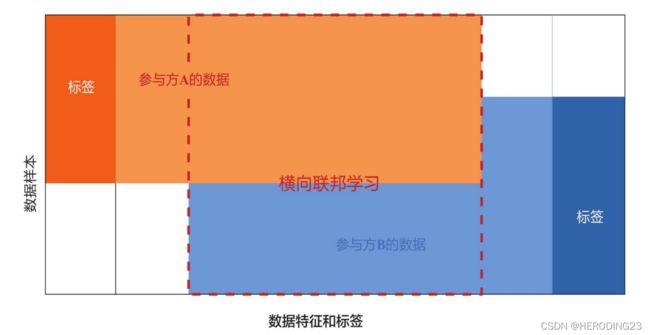
与横向联邦学习不同,纵向联邦学习适⽤于联邦学习参与⽅的训练数据有重叠的数据样本,即参与⽅之间的数据样本是对齐的,但是在数据特征上有所不同。它类似于数据在表格视图中将数据垂直划分的情况。纵向联邦学习的数据特征和标签关系可视化如下图所示:
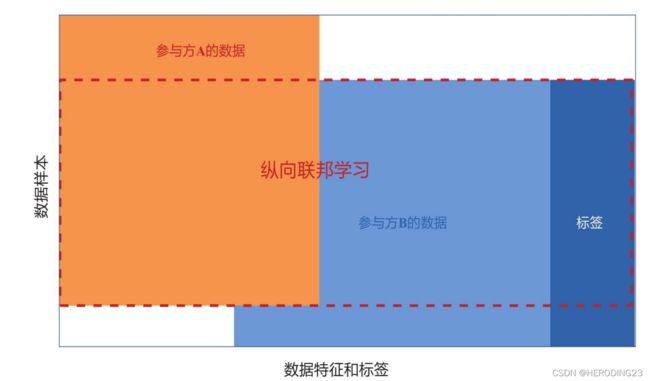
联邦迁移学习适⽤于参与⽅的数据样本和数据特征重叠都很少的情况,它可以处理超出现有横向联邦学习和纵向联邦学习能力范围的问题。

2.2.1 Horizontal FL
横向联邦学习的数据可以表述为如下形式:
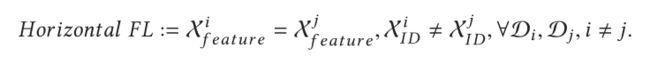
在横向联邦学习的应用中,McMahan等人提出了一种基于手机客户端对的横向FL框架;Li等人提出了一种横向FL框架,用于梯度增强决策树,以提高模型的效率和精度;Phong等人将加性同态加密应用于水平FL框架以保护梯度;Smith等人提出了一个多任务学习框架,允许多个客户培训不同的任务,其优点是考虑了培训阶段的高沟通成本和失散问题。
根据通信架构的分类,横向FL又可以划分为client-server和peer-to-peer架构。客户机-服务器体系结构使用集中计算,因为有一个中央服务器用于编排整个训练过程。点对点架构使用去中心化计算,因为没有中心服务器,每轮训练中都会随机选择一个客户端作为服务器。
Client-Server架构,也被称为集中式FL,它的潜在假设是客户是诚实的,但是服务器是诚实且好奇的,它的训练过程分为五个步骤:
- 服务器初始化模型参数和超参数,并将计算任务分配给选定的客户端;
- 选定的客户机训练它们的本地模型,并使用隐私保护技术处理训练好的模型参数,然后将这些参数发送给服务器;
- 服务器通过采用加权平均或者其它方式来执行安全聚合;
- 服务器将聚合的参数发送回客户机;
- 客户端解密接收到的参数并更新其本地模型。
在训练过程中,交换的模型参数有两种类型:模型权重和梯度。对于模型权重,客户端将本地计算的权重发送给服务器,服务器将接收到的权重聚合后返回给客户端。这样的好处是不需要频繁的同步,并且对更新丢失有一定的容忍度,缺点是不能保证收敛。对于模型的梯度,客户端将本地计算的梯度发送给服务器,服务器将接收到的梯度聚合后返回给客户端。这种方法的优点是梯度信息准确,收敛性好。缺点是通信成本和需要连接需要可靠的通信。
Peer-to-Peer架构,也被称为去中心化FL,它没有中央服务器。在该体系结构中,每个客户端使用其本地数据集本地训练机器学习模型,并使用从其他客户端接收的模型信息更新其模型;然后客户端将更新后的模型信息发送给其他客户端。因此在此系统中,防止信息泄露的重点在于客户机之间的通信。有循环传输和随机传输两个协议编排训练的过程。
- 循环传输。客户端组织成一个循环链,依照链的顺序发送更新模型,满足终止条件后停止训练。
- 随机传输。在这个协议中,客户随机挑选另一个客户并发送模型信息,后者收到信息后使用本地数据集更新收到的信息,然后同样随机发送给别的客户机。直到满足停止条件后停止。
2.2.2 Vertical FL
纵向联邦学习的数据可以表述为如下形式:
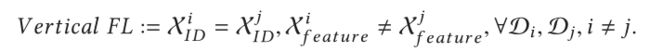
在纵向联邦学习的应用中,某篇文献提出了垂直FL方案来训练一个隐私保护逻辑回归模型。该方案用于研究实体分辨率对学习性能的影响,并对损失函数和梯度函数进行泰勒近似,从而可以采用同态加密进行隐私保护计算。Yang等提出了一种基于拟牛顿法的垂直FL框架用于逻辑回归,其优点是降低了通信成本。然而,这两种方法只关注在垂直FL设置中有两个客户机的二进制分类任务。Feng等人提出了一个多参与者多类垂直FL框架。Yang等提出了一种不需要第三方协调者的物流回归模型的垂直FL框架。Cheng等人提出了一种无损的垂直FL方法,它可以使客户以协作的方式训练梯度增强决策树。Liu等提出了一种基于块坐标梯度下降算法的垂直FL框架,每个客户端在本地进行一次以上的梯度更新,然后将本地模型信息发送给其他客户端。利用该方法,分析了局部轮数对局部更新的影响,并给出了适当选择局部轮数的全局收敛性。该方法的优点是减少了通信开销。此外,Wang等提出了基于组实例删除和组Shapley值的度量方法,计算每个客户端对垂直FL的贡献。
对于垂直FL,主要有两种通信架构:一种是带有第三方协调器的架构,另一种是没有第三方协调器的架构。
具有第三方协调的架构。在该架构中,客户端彼此是诚实且好奇的,为了保证数据隐私性,引入第三方进行协调,这样的纵向FL系统包括五个主要步骤(C1,C2是客户机,C3是协调方):
- ID对齐,使用基于加密的ID对齐技术,不暴露私有数据,然后使用这些数据实例进行训练;
- C3生成加密秘钥对,把公钥分发给C1和C2;
- C1和C2对它们的中间结果进行加密并且互相交换;
- C1和C2计算各自加密得到梯度信息并添加掩码,C1还计算加密损失,然后,C1和C2将加密后的结果发送给C3;
- C3将收到的加密结果解密并将解密后的梯度和损失返回给C1和C2,接着C1和C2去除掩码更新他们的模型参数。
其中,C1是拥有数据集合标签的一方,而C2只有数据集。
不具有第三方协调的架构。假设C1和C2协同训练一个机器学习模型,C1有训练全局模型的标签数据。C1和C2彼此诚实且好奇,为了防止隐私泄露,纵向FL系统需要包括一夏七个主要步骤:
- ID对齐,利用它们的常见数据实例来训练垂直FL模型;
- C1生成加密秘钥对并将公钥发送给C2;
- C1和C2初始化它们的模型权重;
- C1和C2分贝计算它们的部分线性预测器,C2再将其预测器的结果发送给C1;
- C1计算模型的残差,加密残差发送给C2;
- C2计算加密的梯度并附上掩码发送给C1;
- C1解密加了掩码的梯度的并将其发送回C2,接着C1和C2在本地更新其数据。
2.2.3 Federated Transfer Learning
联邦迁移学习的数据可以表述为如下形式:
![]()
对于联邦迁移学习的研究,Yang等人提出了一个安全的FTL框架:FedSteg,这是一种适用于一般网络结构的通用框架。Gao等人提出了一个异构的FTL框架,它提供了一个端到端学习协议,用于多个客户机之间的异构特征空间训练。实验表明,该框架优于局部训练方案和均匀FL方案。Liu等人提出了一个一般的隐私保护的FTL框架,将现有的安全FTL的范围扩展到更广泛的实际应用。与一些存在精度损失的安全深度学习方法相比,FTL可以达到与非隐私保护方法相同的精度且精度高于非联邦自学习方法。Sharma等人提出了一种基于多方计算的安全高效的超光速框架。这允许客户训练一个传输学习模型,同时保持他们的数据集对对手的隐私。此外,与同态加密方法相比,它减少了运行时间和通信成本。
联邦迁移学习可以分为三类:基于实例的FTL、基于特征的FTL和基于参数的FTL。
- 基于实例的FTL假设源域中数据集中的一些标记实例可以重新加权并应用于目标域中的训练。对于横向FL,不同的客户端的数据集可能有不同的分布,这会导致在这些数据集上训练的模型准确性下降。一种解决方案是通过重新加权一些选定的数据实例来减轻分布差异,然后重新使用它们训练模型;对于纵向FL,不同客户的目的可能不同,在纵向的内径对齐可能对FTL产生负面影响,称为负迁移,一种解决方案是使用重要性抽样来缓解负迁移。
- 基于特征的FTL为了最小化域差异学习良好的特征表示,从而可以有效地编码从源域到目标域的转换知识。在横向FL中,可以通过最小化客户端不同数据集之间的最大平均差异来获得特征表示;在纵向FL中,可以通过最小化不同数据集中对齐实例的特征之间的距离来获得特征表示。
- 基于参数的FTL目的是利用源域和目标域模型之间共享的参数或超参数的先验分布来有效地编码转换知识。对于横向FL,首先基于不同客户端的数据集训练共享全局模型。然后,每个客户端可以在其本地数据集上使用预训练的全局模型微调其本地模型。对于纵向FL,可以首先使用在对齐实例上训练的预测模型来推断客户端的未对齐数据实例的缺失特性或标签。然后对扩展后的数据集进行训练,得到更精确的模型。
2.3 Related Concepts
本节介绍了与联邦学习相关的概念,并与FL进行比较,比较结果如下表所示:
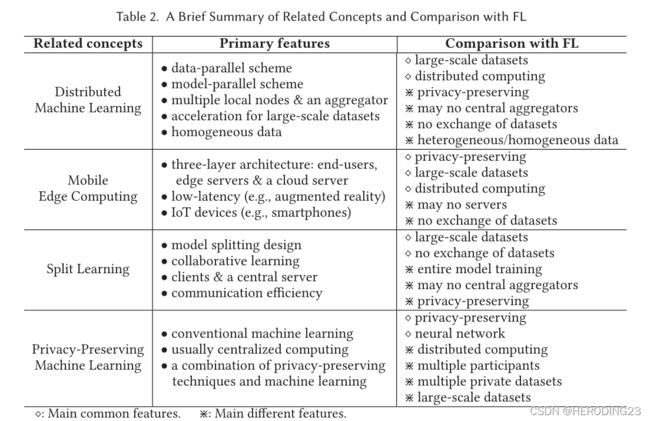 接着就是对相关概念得到详细介绍。
接着就是对相关概念得到详细介绍。
2.3.1 Distributed Machine Learning
分布式机器学习在前言部分有所提及,它是分布式计算和机器学习的结合,其目的是加速大规模数据集的训练过程。通常有数据并行和模型并行两种方式。
数据并行是将数据分区成本地节点,并在本地数据集上进行模型训练,然后将本地模型参数发送给参数聚合器,与FL相比,本地节点具有相同的机器学习模型。
在模型并行方案中,首先将一个机器模型划分为几个分区并分发到多个本地节点。然后,每个本地节点在整个数据集的副本上训练模型的一部分。通过部署聚合器来分配计算任务并聚合所有模型部件。
2.3.2 Mobile Edge Computing
移动边缘计算。旨在实现在蜂窝网络的边缘客户端提供云计算服务。它的关键思想是通过更靠近边缘用户的地方执行计算任务减少网络的拥塞。因此,它可以为客户快速部署新服务或应用程序。
2.3.3 Split Learning
分割学习是一种分布式学习概念,它使协作机器学习无需与中央服务器交换数据集。首先每个用户将一个模型训练到一个特定的层,即切割层。然后将中间参数传输到中央服务器,完成剩余层的训练。最后将聚合的梯度方向传播回切割层,再发送回客户端完成局部训练。相比之下,FL通常涉及整个模型的参数或梯度的通信。分割学习在模型较大或者用户较多的情况下,通信效率更高,因为分割学习的客户端并不会将所有的模型都传输到中央服务器中。但是FL比分割学习容易实现,因为FL的客户端和中心服务器运行相同的全局模型。
2.3.4 Privacy-preserving Machine Learning
隐私保护的机器学习(PPML)旨在在机器学习使用隐私保护技术来保护数据隐私。PPFL可以是PPML的特殊情况。主要区别在于PPFL强调协同训练,数据集分别存储在不同设备上。通常的PPML方法有三种,分别是:基于同态加密的PPML,基于安全多方计算的PPML,以及基于差分隐私的PPML。
3. OVERVIEW OF GENERIC PRIV ACY-PRESERVING MECHANISMS
在计算机安全领域,隐私被定义为:“确保个人操作或者影响与他们相关的信息可能被收集和存储,以及该信息可能被何人或向何人披露”。隐私保护机制旨在实现数据的实用性,同时确保原始信息不会泄露给其他个人或团体。本节主要概述了涉及隐私保护的三种类型的通用隐私保护机制:加密技术、扰动技术和匿名技术。
3.1 Cryptographic Techniques
在PPML广泛使用的加密技术主要包括同态加密、秘密共享和安全多方计算。
同态加密是加密的一种形式,正式来说,一个同态加密算法是符合以运算符*的标准En(m1) * En(m2) = En(m1 * m2),其中m1和m2都是明文的形式。根据支持的运算符,同态加密方法可以分为部分同态加密和完全同态加密。部分同态加密可以理解成一个群,只支持加性运算或者乘性运算。完全同态加密同时支持加性运算或者乘性运算。与部分同态加密相比,完全同态加密提供了更强的加密能力,但存在计算成本问题。此外根据笔者的了解,完全同态加密中还有一种些许同态加密,即数据只能进行有限次数的运算,因为在每次计算中都会加入许多噪声,达到一定程度数据就失去效用了。
秘密共享其实是安全多方计算的一个重要的基础原语,形式为(t,n),即对于n个参与方,至少有t个参与方共享才能够重新重构秘钥,少于t个都不能够实现。然而这样的方法容易受到不诚实的经销商或者恶意参与者的攻击。因此,提出可验证的秘密共享来防止这两种攻击。
安全多方计算(SMC)允许分布式参与者在不暴露其数据的情况下协同计算目标函数。n个参与方{P1,P2,…,Pn}共同去计算全局函数f(D1,D2,…,Dn),并且满足以下要求:(1)正确性,计算的结果是正确的;(2)隐私,协议没有透露任何参与方的私人信息。它有三个优点:
- 不需要可信的第三方;
- 消除了数据效用和数据隐私之间的权衡;
- 实现了较高的准确性。
缺点也存在,就是计算开销和通信成本高。
3.2 Perturbation Techniques
扰动技术的关键思想是在原始数据上添加噪声,使从扰动数据上计算出来的统计信息与从原始信息上计算出来的信息难以区分。有三种广泛使用的扰动技术:差分隐私、加性扰动和乘性扰动。
差分隐私技术基于概率统计模型来量化数据集中实例的隐私信息泄露程度。通常差分隐私技术可以分为两类:全局差分隐私技术和局部差分隐私技术。全局差分隐私技术旨在实现这样一个目标:如果在数据集中即使替换任意样本的效果足够小,查询结果也不能用于探索关于数据集中任何样本的更多信息。这样的差分隐私技术比局部差分隐私技术更加精确,因为它不需要加入大量的噪声。局部差分隐私不需要可信的第三方,但是噪声很大。
加性扰动旨在保持原始数据的隐私通过添加来自某个分布(如均匀分布和高斯分布)的随机噪声,来实现Y=X+δ,其中Y是扰动数据,X是原始数据,这种技术很简单,但是容易受到噪声的影响降低数据效用。
乘性扰动的目的是利用来自某个分布的噪声对原始数据进行乘法。它并不是添加随机噪声,而是将数据点变换到另一个空间。相比加性扰动,乘性扰动更加有效,因为由乘性扰动的数据重构原始数据更困难。
总之,扰动技术简单高效,但是容易受到概率性攻击,在不降低数据效用的情况下很难降低这种风险。
3.3 Anonymization Techniques
匿名化技术主要用于在保持已发布数据的实用性的同时,通过删除可识别信息来实现基于组的匿名化。有三种广泛可用的匿名技术:k-匿名,l-多样性,t-亲密度。这些技术主要是为了结构化数据开发的,包括主要的三个属性:ID,敏感属性,非敏感属性。
k-匿名旨在保护数据的隐私同时保持已发布数据的效用。如果数据集中的每个样本不能从已经发布的至少k-1个数据中重新识别,那么就称为k-匿名。它的优点是有效保护基于UID记录的隐私,但是可能会受到对敏感属性的攻击。
此外,l-多样性,是k-匿名的延伸,增强了对敏感属性的保护。与k-匿名相比,该技术在匿名机制中将组内的多样性添加到敏感属性中。但是仍然容易受到属性链接攻击,因为敏感属性可能通过值的分布推断出来。
因此,t-亲密度被提出,通过维持敏感属性的分布来增强多样性。它比前两个技术更为有效。然而强制增强不同分布之间的t-亲密度会降低数据的效用。
3.4 Privacy-preserving Metrics
有两类指标广泛用于评估隐私保护方法的性能:(1)度量数据集隐私损失的隐私指标和(2)度量受保护数据的效用指标,用于数据分析目的。
常见的隐私保护的指标有四个方面:对手模型,数据源,指标计算和输出模型。在大多数情况下,单一指标可能无法全面评估完整的隐私。
效用指标是为了量化被隐私保护的数据,用于数据分析的目的,即一般分析目的和特定分析目的。一般分析目的定义了信息丢失度量来度量原始数据和受保护数据之间的相似性。它们通常由受保护数据保留原始数据统计信息的程度来衡量。特定分析目的的数据效用是通过比较使用受保护数据和原始数据的任务的评估准确性来衡量的。
4. PRIV ACY-PRESERVING FEDERATED LEARNING: A TAXONOMY AND REVIEW
PPFL是FL和隐私保护机制的巧妙结合。**它的主要挑战是在将隐私保护机制应用到FL框架时,如何平衡数据隐私和数据实用性之间的权衡。**在本节中,首先概括了提出的 5W-scenario-based分类法,然后根据该方法从五个方面分析了FL中潜在的隐私泄露风险。最后根据四种隐私保护方法对PPFL方法进行研究和总结。
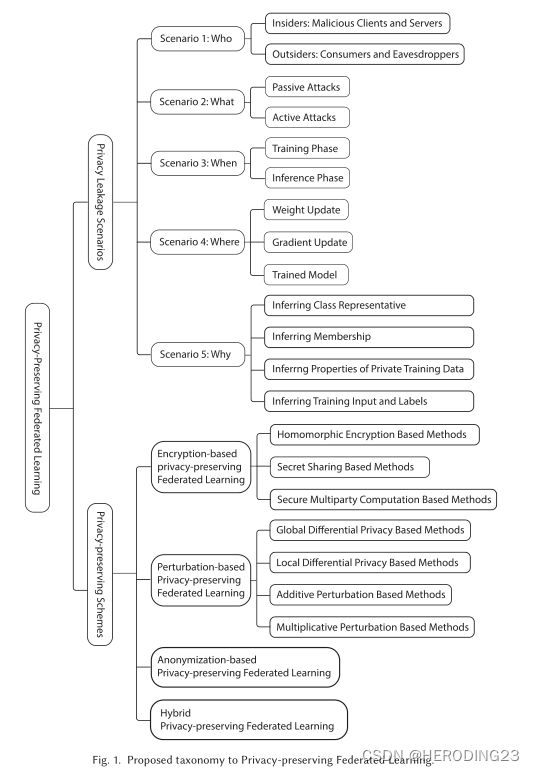
4.1 Proposed 5W-Scenario-Based Taxonomy
5W-Scenario-Based 分类法强调了PPFL的两个方面:(1)潜在的隐私泄露和(2)可能的隐私保护方案。关于潜在的隐私泄露,将从五个基本方面讨论:who(内部还是外部攻击者)、what(主动还是被动攻击)、when(训练还是推理阶段)、where(权重更新、梯度更新和最终模型)、why(四种类型推理攻击)。对于可能的隐私保护方案,将现有的PPFL方法分为4类:基于加密的、基于扰动的、基于匿名的和混合的PPFL。
4.2 Potential Privacy Leakage Risks in FL
FL不能充分保护数据的隐私,主要是因为模型参数(权重或梯度)可能会将一些敏感信息泄露给对手,造成深度隐私泄露,比如原始梯度的小部分可能会暴露局部训练数据集的隐私。因此本节从五个基本方面对FL中潜在的隐私泄露风险全面分析。
4.2.1 Scenario 1: Who might be a malicious adversary?Insiders and outsiders
FL中,有两种角色可以获得对模型信息的访问:内部参与者(参与的客户机或服务器)和外部参与者(模型使用者和窃听者)。
对于内部的参与的客户机或服务器可能是诚实且好奇的,他们的目标是对私有数据的访问,对于外部的恶意对手,首先是模型使用者,有两种方法探查私有数据:(1)获得整个模型的权重的访问;(2)获得平台API提供的访问查询结果。接着是窃听者,可以通过截获参与者与服务器之间的通信来窃取中间训练更新或最终模型,但是需要更多的精力。此外,窃听者可能窃取参与者和集合者之间传输的中间权重或梯度。
接着进行风险评估。如果客户是恶意的,那么有三种情况下导致隐私的泄露:(1)恶意客户端可以从聚合器中获得中间训练更新,以探取其他客户端数据集的私有信息;(2)恶意客户端可能发送故意设计的模型更新,以探测其他客户端数据集的私有信息;(3)恶意客户端发起信息推断攻击。虽然这些风险可以设计特定的协议解决,但是仍然面临着恶意用户的泄露隐私风险。
如果服务器是恶意的,那么会造成更高级别的隐私泄露风险。
- 由于恶意服务器维护中间更新和最终模型,服务器可以利用这些信息进行重构攻击;
- 恶意服务器能够通过区分特定客户机的模型更新来探索它们的私有数据;
- 恶意服务器有能力在每一轮训练中选择和规范参与的客户端,以探索训练数据集的隐私性。
考虑到服务器的作用是聚合模型更新,一个简单的隐私保护解决方案是限制和量化服务器重构客户端的本地训练数据集的能力。
模型的使用者可以很容易访问最终模型或者查询结果,如果它们是恶意的或者被攻击者控制,可以利用信息通过信息推断攻击来探测敏感信息。因此,恶意消费者可能会造成较高的隐私泄露风险。
窃听者试图通过窃取参与者和服务器之间传输的中间训练更新或最终模型来探测敏感信息,他们可以利用这些信息来探索训练数据集的私有信息,例如重建训练样本。与恶意用户相比,窃听可以通过加密机制(如同态加密、秘密共享或安全多方计算)进行防御。
4.2.2 Scenario 2: What types of privacy attacks?Passive and active attacks
首先要明确被动攻击和主动攻击的定义,根据RFC4949,被动攻击定义为使用系统的信息或从系统中学习但是不改变系统;主动攻击定义为改变系统资源或影响系统操作。被动攻击者只在FL训练和推理阶段观察,而主动攻击者可以通过操控模型参数来影响FL系统。
FL中的被动攻击可以分为被动黑盒攻击和被动白盒攻击两类,例如,在被动黑盒攻击中,在服务平台的设置中,假设对手只能访问查询结果,而不能访问模型参数或中间训练更新。在被动白盒攻击中,假设攻击者可以访问中间训练更新、模型参数和查询结果。
FL中的主动攻击旨在主动影响训练过程,提取训练数据集的敏感信息。比如攻击者向全局模型上传一个特殊的梯度来学习可分离表示,从恶意服务器的角度,通过隔离某些客户端,研究一种主动攻击。
风险评估:被动黑盒攻击风险通常是有限的,而被动白盒攻击通常可以揭示更多关于训练数据集的敏感信息。与被动攻击相比,主动攻击要强大得多,因为对手可以在客户端或服务器端修改模型更新。例如,为了提取更多关于训练数据集的私有信息,客户端恶意修改的梯度更新会误导全局模型学习特定的特征,而不会对模型的性能产生显著影响。
4.2.3 Scenario 3: When might a data privacy leakage occur?Training phase and inference phase
FL有两个主要的阶段:训练阶段和推理阶段。训练阶段客户端计算梯度信息,服务器聚合全局模型,二者之间传输更新。推理阶段主要涉及一种向消费者提供查询服务的方法。这两个阶段都容易受到隐私泄露的影响。
风险评估:在训练阶段,一个隐私泄露的风险主要与模型的更新有关,这是因为在训练阶段的所有更新信息都有可能暴露给恶意对手,这些信息包括局部梯度、局部模型权重、聚合梯度或模型权重,以及最终的模型。此外在训练阶段,对手可能会发送恶意的局部更新,误导全局模型学习特定的特征,此外训练阶段的模型可能会暴露给窃听者。为了限制更新或最终模型的隐私泄露,可以在FL训练过程中应用用户级差分隐私。
在推理阶段,隐私泄露的风险主要与最终模型有关,最终模型是发布给参与者或者作为服务平台提供的。有两种主要的隐私和泄露风险:(1)基于模型参数的攻击,(2)基于模型查询的攻击。在第一种情况下,攻击者可以访问模型参数,从而获得查询输出和所有中间计算,攻击者可以利用模型参数进行推理攻击,提取参与者训练数据集的敏感信息。在第二种情况下,假设对手只能获得模型查询输出,这时候的隐私泄露主要是由推理攻击引起的。
4.2.4 Scenario 4: Where might a data privacy leakage occur?Weight update, gradient update, and the final model
使用FL时,有三种重要的数据需要在参与者和聚合器之间进行传输:局部权重、聚合权值和最终的模型,所有这些重要信息都可以用来揭示训练数据集的敏感信息。
风险评估:在基于梯度更新的FL框架中,由于更新的梯度来源于参与者的私有数据,所有会造成严重的隐私泄露。对手可以通过在训练过程中观察、修改或者窃听梯度更新来进行隐私攻击。
在基于权重更新的FL框架中,服务器计算出的聚合权重在每一轮训练中可供多个参与者使用。因此,权重的更新会将参与者训练数据的隐私泄露给敌对参与者或窃听者。恶意攻击者可以保存当前FL模型的参数,利用当前FL模型与以前FL模型的差异进行属性推断。
因为最终的模型编码了参与者所有数据集的基本信息,因此基于最终模型的攻击将导致严重的隐私泄露。一般来说对于最终发布的模型有两种类型的隐私泄露:(1)基于模型参数的攻击,假设攻击对手能够访问模型参数,(2)基于查询的攻击,对手被认为能够获得模型的查询结果。实验结果表明,基于模型参数的攻击比基于查询的攻击泄露更多的敏感信息。
4.2.5 Scenario 5: Why might a malicious attacker launch an attack?Inference attacks, including inference of class representatives, memberships , properties of training data, and training samples and labels
隐私攻击的目的通常是推断训练数据集的敏感信息,推理攻击可以分为四类:
- 类代表的推理的目的是生成代表样本,这些代表样本不是训练数据集的真实数据实例,但可以用来研究训练数据集的敏感信息;
- 成员关系的推断旨在确定一个数据样本是否已被用于模型训练;
- 训练数据的属性推断目的是对训练数据集的属性信息进行推断;
- 推理训练样本和标签的目的是重建原始训练数据样本和相应的标签。
风险评估:第一种推理攻击试图去提取类代表,类代表是合成的泛型样本,而不是训练数据集中的真实数据。GANs可以提取与训练数据相似的类代表,比如GANs模型生成的手写的数字“9”和任何数字的图像和训练样本相像。
成员推理的目的是确定一个数据样本是否包含在训练数据集中。Melis等从嵌入层和梯度两个方面研究了成员隐私泄露问题。结果表明,深度学习模型的嵌入层的非零梯度可以揭示单词在训练批中的位置。这使得对手能够执行成员推断攻击。
训练数据的属性推断的目的是对训练数据集的属性信息进行推断,特别是这些任务可能与主要训练任务无关。
训练样本和标签的推理是为了生成原始的训练数据样本和相应的标签。最近的研究表明,训练样本和标签可以从公开共享的模型梯度中获得。
4.3 PPFL Methods
PPFL方法分为四类:(1)基于加密的,(2)基于扰动的,(3)基于匿名的,(4)混合的PPFL方法。
4.3.1 Encryption-based PPFL
基于加密的PPFL方法主要利用加密技术进行隐私保护,可分为三类:(1)基于同态加密的PPFL方法,(2)基于秘密共享的PPFL方法,(3)基于安全多方计算的PPFL方法。
同态加密是指直接对密文进行计算使生成的加密结果解密后与对应的明文运算相同。该方案是FL训练过程中交换中间参数时保护数据隐私的一种有效方式,已广泛应用于许多FL方法中。但是同态加密带来了很大的通信成本和计算开销。一种解决方案是批量加密的PPFL。
秘密共享的PPFL方法保证有足够的数量的共享组合时,多个共享组成的秘密才能被重构。基于秘密共享的FL安全框架的一个优点是允许服务器安全地聚合参与者的模型更新。容易受到不诚实的服务器或者恶意参与者攻击。
安全多方计算是一种加密方案,它允许分布式参与者在不暴露自己数据的情况下协作计算目标函数。优点是保留原始数据的准确性,实现高度的隐私保障。缺点是安全聚合协议会带来很大的通信成本。
4.3.2 Perturbation-based PPFL methods
基于扰动的PPFL方法可以分为四类:(1)基于全局差分隐私的PPFL方法,(2)基于局部差分隐私的PPFL方法,(3)基于加性扰动的PPFL方法,(4)基于乘性扰动的PPFL方法。
基于全局差分隐私的PPFL方法在许多FL方法中得到了广泛的应用。比如服务器通过添加随机高斯噪声来聚合全局模型。这样,恶意参与者就无法从共享的全局模型中推断出其他参与者的信息。但是这个框架容易受到恶意服务器的攻击,因为服务器可以从客户端获得原始的数据。与该方法相比,Hao等提出的在局部梯度中添加噪声。全局差分隐私的优势是在保证数据隐私的同时提供了良好的准确性。
局部差分隐私的FL与全局差分隐私的FL方法相比,提供了更强的隐私保障。
基于加性扰动的PPFL方法旨在权重或梯度更新中添加随机噪声来保护隐私。它的优点是简单,可以保留统计特性,并不需要了解原始的数据分布,但是数据扰动会降低数据的效用。
基于乘性扰动的PPFL方法。Gade等人提出了一种PPFL方法,通过使用乘法摄动来混淆随机梯度,以保护梯度不受好奇的服务器的影响。与基于加性摄动的FL方法相比,基于乘性摄动的FL方法往往更有效,因为重建原始数据值更困难。
4.3.3 Anonymization-based PPFL
尽管基于扰动的PPFL可以为隐私保护提供有力的保证,但是这会导致数据效用的退化。因此,基于匿名化的FL方法被提出用于隐私保护。比如Choudhury等人提出了一种用于PPFL的语法方法,提出该方法是为了提高数据的实用性和模型的性能,同时提供了一个遵循法律法规的数据隐私的保护水平。该方法有两个核心。第一个核心是在客户端的原始数据上应用k-匿名方案,并利用匿名数据协同训练全局模型。第二个核心组件是一个全局匿名映射过程,用于预测FL全局模型。结果表明,该方法比基于差分隐私的FL方法具有更好的隐私保护和模型性能。
4.3.4 Hybrid Privacy-preserving Federated Learning
由于基于加密的FL方法往往受到计算和通信开销,基于扰动的FL容易降低数据的效用,所以近年来提出了混合PPFL方法来平衡数据隐私和数据效用之间的权衡。比如SMC用来保证在差分隐私下的FL框架不会泄露私人信息。该方法的优点是可以减少注入的噪声量,同时保证隐私和保持预定义的信任率。
4.4 Summary of the Relationship between the Taxonomy and Latest Techniques
在图1中,提出的 5W-scenario-based分类法强调了两点:(1)在五个场景下可能的隐私泄露,(2)在现有的PPFL中使用的隐私保护方案。关于第一个方面,从五个角度讨论了谁可以通过操纵什么参数和为了什么样的目的执行什么类型的攻击。第二个方面,回顾了现有的PPFL方法并讨论了它们具体隐私保护技术,以及优缺点。
5. SUMMARY AND OPEN RESEARCH DIRECTIONS
一些潜在的开放研究问题和方向:
- 应该确定一种有效地将section3中描述的隐私保护机制应用到FL框架的隐私保护的方法。并且在向FL中引入隐私保护机制时,有必要平衡数据效用和数据隐私之间的权衡。
- 在FL中,参与者与聚合器之间通信的中间权重或梯度可能会揭示参与者训练数据集的敏感信息。有两种方法来保护这些数据的隐私。第一种是利用加密技术,但是基于加密的FL往往受到计算和通信开销的影响。因此,有必要开发一种有效的方法来平衡两者之间的权衡。另一种方法是通过扰动技术来保护权重或梯度的更新,然而该技术通常需要添加噪声,所以会同时降低模型的精度并引入计算开销。因此有必要找到一种方法,在这两种相互冲突的表现之间提供良好的平衡。
- 通过对推理攻击的研究发现如果没有正确地保护最终模型或查询结果,则可以从最终模型或推理API中提取敏感信息。解决思路有两个方向:(1)利用加密和扰动技术保护最终模型不受外部攻击;(2)使用分割技术,通过对全局模型的分割为每个参与者提供个性化模型。
- 在PPFL中应该有效处理数据记忆,以防隐私泄露。因为神经网络模型会无意中记住训练数据的隐私信息。解决方法有两种:(1)对训练数据集匿名化;(2)对训练过程匿名化。
- 在FL中应用隐私保护机制时,其有效性和计算成本可能有所不同。因此有必要研究如何优化防御机制或防御措施的部署。现有的研究大多数集中 在具有中央服务器上的PPFL框架上。有必要研究现有的针对这些框架的隐私攻击是否对没有中央服务器的FL有效。
- 基于混合隐私保护技术的PPFL框架被相信是有前途的。
三、总结
花费了一周多的时间,总算是认认真真、仔仔细细把这篇有关PPFL的全面综述整理完成了,本来想是通过概括的方式解析这篇文章,写着写着就变成翻译文献了,确实在本文中作者的概括已经很详尽了,有些晦涩难懂的地方也给了实例便于读者理解,并且全文没有复杂的语法和生僻的单词,对于英文不好的读者还是很友好的。
通过这篇综述的学习,我总算是明白了FL的危险主要存在于五种场景中,并且有四种基本的隐私保护技术可以运用在FL中。读完最让我受益颇多的应该是对于混合隐私保护方法的描述,显然混合的隐私保护机制是四种基本隐私保护方法的完美结合,属于是中庸之道,比如加密技术和扰动技术结合,噪声不用添加过多,也能降低计算、通信成本;匿名技术和加密技术结合,精度保证了实现起来也简单了,计算成本也降低了。也许,我的下一步研究方向就是基于混合隐私保护技术的PPFL框架呢,那么向下一篇文献进发吧!