yolov5训练结果————分类指标的学习
一:weights
包含best.pt(做detect时用这个)和last.pt(最后一次训练模型)
二:confusion
1:混淆矩阵:
①:混淆矩阵是对分类问题的预测结果的总结。使用计数值汇总正确和不正确预测的数量,并按每个类进行细分,这是混淆矩阵的关键所在。混淆矩阵显示了分类模型的在进行预测时会对哪一部分产生混淆。它不仅可以让我们了解分类模型所犯的错误,更重要的是可以了解哪些错误类型正在发生。正是这种对结果的分解克服了仅使用分类准确率所带来的局限性。
②:在机器学习领域和统计分类问题中,混淆矩阵(英语:confusion matrix)是可视化工具,特别用于监督学习,在无监督学习一般叫做匹配矩阵。矩阵的每一列代表一个类的实例预测,而每一行表示一个实际的类的实例。之所以如此命名,是因为通过这个矩阵可以方便地看出机器是否将两个不同的类混淆了(比如说把一个类错当成了另一个)。
2:图解
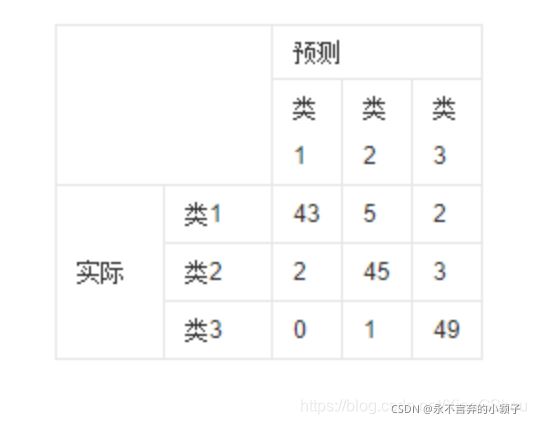
横轴是预测类别,纵轴是真实类别;
每一行之和为50,表示每个类各有50个样本,第一行说明类1的50个样本有43个分类正确,5个错分为类2,2个错分为类3。
每一行代表了真实的目标被预测为其他类的数量,比如第一行:43代表真实的类一中有43个被预测为类一,5个被错预测为类2,2个被错预测为类3;
表格里的数目总数为150,表示共有150个测试样本。
3:TP/TN/FP/FN

①. 真阳性(True Positive,TP):样本的真实类别是正例,并且模型预测的结果也是正例,预测正确
②. 真阴性(True Negative,TN):样本的真实类别是负例,并且模型将其预测成为负例,预测正确
③. 假阳性(False Positive,FP):样本的真实类别是负例,但是模型将其预测成为正例,预测错误
④. 假阴性(False Negative,FN):样本的真实类别是正例,但是模型将其预测成为负例,预测错误
几个指标:
1)正确率(accuracy)
正确率是我们最常见的评价指标,accuracy = (TP+TN)/(P+N),这个很容易理解,就是被分对的样本数除以所有的样本数,通常来说,正确率越高,分类器越好;
2)错误率(error rate)
错误率则与正确率相反,描述被分类器错分的比例,error rate = (FP+FN)/(P+N),对某一个实例来说,分对与分错是互斥事件,所以accuracy =1 - error rate;
3)灵敏度(sensitive)
sensitive = TP/P,表示的是所有正例中被分对的比例,衡量了分类器对正例的识别能力;
4)特效度(specificity)
specificity = TN/N,表示的是所有负例中被分对的比例,衡量了分类器对负例的识别能力;
5)精度(precision)
精度是精确性的度量,表示被分为正例的示例中实际为正例的比例,precision=TP/(TP+FP);
6)召回率(recall)
召回率是覆盖面的度量,度量有多个正例被分为正例,recall=TP/(TP+FN)=TP/P=sensitive,可以看到召回率与灵敏度是一样的。
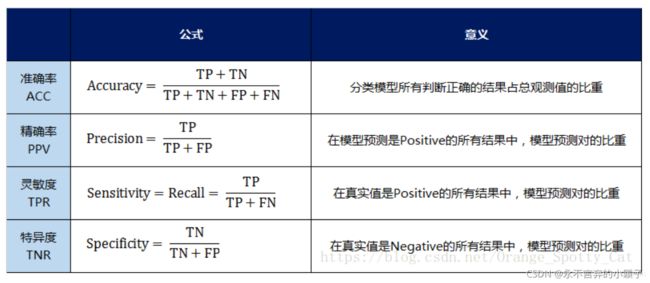
(1) accuracy(总体准确率):分类模型总体判断的准确率(包括了所有class的总体准确率)
注:准确率是我们最常见的评价指标,而且很容易理解,就是被分对的样本数除以所有的样本数,通常来说,正确率越高,分类器越好。
(2) precision(单一类准确率) : 预测为positive的准确率
Precision从预测结果角度出发,描述了二分类器预测出来的正例结果中有多少是真实正例,即该二分类器预测的正例有多少是准确的;
“分类器认为是正类并且确实是正类的部分占所有分类器认为是正类的比例”,衡量的是一个分类器分出来的正类的确是正类的概率
(3) 回归率recall : 真实为positive的准确率,即正样本有多少被找出来了(召回了多少)。
Recall从真实结果角度出发,描述了测试集中的真实正例有多少被二分类器挑选了出来,即真实的正例有多少被该二分类器召回。
“分类器认为是正类并且确实是正类的部分占所有确实是正类的比例”,衡量的是一个分类能把所有的正类都找出来的能力。两种极端情况,如果召回率是100%,就代表所有的正类都被分类器分为正类。如果召回率是0%,就代表没一个正类被分为正类。
综合recall和precision:
Precision和Recall通常是一对矛盾的性能度量指标。一般来说,Precision越高时,Recall往往越低。原因是,如果我们希望提高Precision,即二分类器预测的正例尽可能是真实正例,那么就要提高二分类器预测正例的门槛,例如,之前预测正例只要是概率大于等于0.5的样例我们就标注为正例,那么现在要提高到概率大于等于0.7我们才标注为正例,这样才能保证二分类器挑选出来的正例更有可能是真实正例;而这个目标恰恰与提高Recall相反,如果我们希望提高Recall,即二分类器尽可能地将真实正例挑选出来,那么势必要降低二分类器预测正例的门槛,例如之前预测正例只要概率大于等于0.5的样例我们就标注为真实正例,那么现在要降低到大于等于0.3我们就将其标注为正例,这样才能保证二分类器挑选出尽可能多的真实正例。
Precision和Recall往往是一对矛盾的性能度量指标;
- 提高Precision == 提高二分类器预测正例门槛 == 使得二分类器预测的正例尽可能是真实正例;
- 提高Recall == 降低二分类器预测正例门槛 == 使得二分类器尽可能将真实的正例挑选出来;
(4) F1-Score
F1分数(F1-score)是分类问题的一个衡量指标。一些多分类问题的机器学习竞赛,常常将F1-score作为最终测评的方法。它是精确率和召回率的调和平均数,最大为1,最小为0。
对于某个分类,综合了Precision和Recall的一个判断指标,F1-Score的值是从0到1的,1是最好,0是最差
简而言之就是想同时控制recall和precision来评价模型的好坏

Fβ分数: 另外一个综合Precision和Recall的标准,F1-Score的变形。
(5)错误接受率:FAR (False Acceptance Rate)是错误接受率,也叫误识率,表示错误判定为正例的次数与所有实际为负例的次数的比例。错误判定为正例的次数是FP,所有实际为负例的次数是(FP + TN),FAR=FP/(FP+TN)。
(6)错误拒绝率:FRR (False Rejection Rate)是错误拒绝率,也叫拒识率,表示错误判定为负例的次数与所有实际为正例的次数的比例。错误判定为负例的次数是FN,所有实际为正例的次数是(TP + FN),FRR=FN/(FN+TP)。
原文链接:https://blog.csdn.net/XiaoGShou/article/details/118274900