如何解决 Iterative 半监督训练 在 ASR 训练中难以落地的问题丨RTC Dev Meetup
前言
「语音处理」是实时互动领域中非常重要的一个场景,在声网发起的「RTC Dev Meetup丨语音处理在实时互动领域的技术实践和应用」活动中,来自微软亚洲研究院、声网、数美科技的技术专家,围绕该话题进行了相关分享。
本文基于数美科技 NLP 技术负责人李田在活动中分享内容整理。

01 半监督训练在 ASR 领域的必要性
通用 ASR 的字准确率虽然已经非常高,但是在面向具体的场景(游戏场景、私聊场景、群聊场景、主播场景)时,还是存在场景不匹配的问题,因为通用的 ASR 在这些领域中的应用相对比较困难,主要存在以下问题。
1、标注资源的稀缺性
对应场景的标注很难获取,通常情况下无法快速获得业务场景需要的大量标注样本。即使样本的获取很简单,但获取标注样本仍是非常困难的事情,因为标注成本非常高。在创建项目或者确定产品方向的时候,会发现涉及领域的 ASR 任务时要先解决数据问题。以前使用音素和文字拆分的时候,数据量要求比较小,而现在常使用端到端的技术,动辄 1000 个小时起步的数据量,不管是自行标注还是借助比较知名的数据公司,在产品还没开始的情况下,其费用都是很难接受的。
2、标注质量的不稳定
在唤醒、Siri 交互等场景中,用户知道后端会进行转录,但大部分业务场景中人对于 ASR 转录是无感知的。
比如在与 Siri 沟通的时候,如果 Siri 没听清楚说话人表达的意思,那么人会进行二次尝试,使表达更加清楚即可。但是真实的业务层面,大部分情况下客户并不知道后端在对其进行 ASR 转录,比如直播平台。其中可能会提供审核层面的需求,此时不可能通知主播声音在被转录,咬字需要更清楚一些。吐字不清晰以及句法成分破碎带来的标注质量是非常不稳定的。
那么在标注的时候怎么解决这些问题呢?对数美业务而言,由于覆盖整个互联网中大量的类似社交场景,面临着各式各样五花八门的数据和特定术语等,因此对这类标注的获取难度非常大,同时标注质量也很难保证,但同源数据又可以轻易获得场景的数据,我们认为半监督方案是一个当仁不让的理想选择。
如果曾经接触过 NLP 或者 CV,相信你对半监督会有比较明确的定义。在 ASR 这个领域,尤其基于端到端,目前一般来说分为两种:Self-training 和 Pre-training,其他不太常见,或者目前来看不能在 ASR 领域获得比较好的落地。
Self-training 体系主要围绕大家熟知的 Pseudo labeling。核心方案主要基于 consistency regularization 逻辑。理论上来说,Pseudo label 其实是 true label 的一种噪音,在模型训练的时候,将 Pseudo label 和 true label 放在一起进行训练,这本身是训练抗噪的过程,可以使模型逐步学习。Pre-training 非常简单。如果做 NLP 出身就会比较了解,原先是在对应领域中训练对应领域更合适的表征。这种任务一般围绕的是表征的意义或者内容的重构,不需要额外的标签,这些数据可以构建无标签/无人工转录文字的 Pre-training 的训练任务,再使用对应场景的有人工转录数据进行 ASR 任务训练。
01 半监督训练在 ASR 领域的发展
1、Self-training
一般来说,Self-training 起始于 CV。从 2013 年的 Pseudo label ICML 第一次提出 Pseudo label 以来,出现了各式各样的新体系,诸如 2014 年 Learning with pseudo-ensembles(第一个体系),将 Pseudo label 与模型 Ensemble 进行融合;2016 年 Regularization With Stochastic Transformations and Perturbations for Deep Semi-Supervised Learning 认为 Pseudo label 本身的生成逻辑也应该是同一个模型的不同扰动;2017 年 Mean teachers are better role models: Weight-averaged consistency targets 则着重关注如何生成更高质量的标签,其采用模型平均的方式获得更好的 teacher 模型,从而确保伪标签的质量。
早在 2014 年、2016 年的两篇论文中,就已经提及到在 CV 中较火的领域进行对比学习,论文中的公式论证从很多层面上几乎是一样的,可以说技术的发展是历史的轮回。
2、Pre-training
Pre-training 主要集中在 NLP 领域,当然在 CV 领域中也有诸如 ladder network 体系,包含 Pre-training 概念。但是 Pre-training 发展较好的领域还是 NLP。核心问题在于 NLP 的底层特征是字符,这本身是一个非常离散的体系,是很难与 CV 这种稠密的数据输入进行比较的。
从这个体系来说,NLP 经历了多年的发展,从 1994 年的 N-gram-based 特征,到基于 NN 体系,再到后来对 NN 体系内部框架进行设计所生成的 RNN 和 LSTM 等语言模型的兴起,2017 年 ELMO 横空出世,再到 2018 年 transformer 架构出现。现在,不管是 BERT 或者是 GPT 等都在 NLP 领域的各种下游业务上都得到了比较充分的验证。
3、ASR 领域的半监督发展
一般来说会根据 ASR 本身的时代将其拆成两节:
①基于音素/文本拆分的时代:现在很多情况下大家依然会用 kaidi 作为业务层面的 ASR 底层技术方案。该方案的半监督训练逻辑为,声学模型可以训练一个到 general 音素的模型,然后通过下游语言模型或 rescore 模型输出具体业务所需的文字,从而达到部分半监督的功能。从流程上,它更像是一种迁移学习。但是随着 Alex Graves 在 2013 年完成 CTC 的博士论文后,端到端体系就开始逐步崭露头角。两年过后, EESEN 团队重新又把 CTC 运到音素层面,使音素/文本拆分体系短暂地回归。
②端到端的时代:LAS(listen attendance style) 体系兴起,以及 CTC/LAS + LM hybrid 体系的兴起,使端到端的效果、数据、模型质量以及推理速度等,开始逐步超越 Kaldi 或者传统的音素/文本拆分模型架构,业界也开始逐步步入端到端的时代。其时间脉络为 CTC,Deep speech,Listen,attend and spell, 以及 Hybrid CTC/attention。
在 2017 年以后,随着 Watanabi 提出 CTC/attention hybrid 和 ESPNET 框架的放出,端到端体系已初步完善并可应用于工业上的各个业务。其提供了一套同Lattice 一样灵活的联合decode框架:基于hypotheses route的设计,赋予后续shallow fusion 更加灵活的融合方案。事实上如果大家使用过 ESPnet,就可以看到整个 hypotheses 路径设计非常灵活,可以引入各式各样的技术方案对route进行联合打分或者 rescore。
由于不再采用音素等基础,且 CTC 和 Seq2Seq 本身训练成本就非常高,再加上实际的标注数据的获取难度,端到端体系对数据依赖的短板逐步成为了其落地的核心瓶颈。如果在早期尤其是 2015 年-2016 年在大厂做 ASR,大家实际落地的经验是,在 1000 小时过后再考虑端到端。
由此,如何约束端到端的数据需求成为后期(从 2019 年-2020 年开始)优化端到端,进而解决端到端落地的难题,也是学术界和工业界核心考量的问题。自此,基于 ASR 的 Pre-training 和 Self-training 开始逐步登上历史舞台。此前,虽然进行过相关的研究,但是影响范围较小,直到 2019 年和 2020 年,Facebook AI 分别提出了这两个领域能够工业落地的,且具备巨大的发展前景的两篇论文发表,人们才开始关注。
wav2vec: Unsupervised pre-training for speech recognition 是 Facebook 提出的基于 Pre-training 的技术方案。其原理同 word2vec 非常接近,利用负采样技术训练一个未来时刻表征预测的任务。由于其训练结果可作为任意音频下游任务的特征,所以这一套体系是目前工业界很多大厂都在使用的非常重要的音频技术基础。
Self-training for end to end speech recognition 是 Facebook AI 的 Jacob 团队的研究,旨在全面的分析 Pseudo label 体系对于 ASR 的实际落地应用效果。他们当时给出了 Pseudo label 体系在英文 ASR 领域的几个核心数据集上的 strong baseline,并且第一次系统的阐述了 Pseudo label 体系在 ASR 领域落地需要解决的几个核心问题。
4、Pre-training VS Self-training in ASR
在 2020 年,由于客户逐步变多,场景覆盖也越来越广,我们也同样面临:要对某些特定的场景进行单独的 ASR 构建,以获取相比于竞品更好的模型效果。单纯的利用音素/文本架构,通过替换语言模型来应付各个领域的需求已不能获得我们所期望的效果。但与此同时,单独对每个场景要构建自己的端到端 ASR,从数据标注上又是难以接受的。因此我们就开始考量选择 Pre-training 还是 Self-training。
原本我们考虑选择其他大厂类似的体系,比如 Pre-training 的 wav2vec,但是我们当时多次尝试了 wav2vec 的实际操作,成本非常高,下游的 Post-pretraining 在对应领域中的训练加上 Pre-training 本身的训练时间耗时也非常漫长,导致模型迭代周期会被拉长。重要的是,在 Pre-training+Post-pretraining 阶段暂时是没有任何的 ASR 模型产出的,对于新业务要求快速迭代的场景,这是难以接受的。
基于上述矛盾,我们最终还是倾向于在业务中使用 Self-training 的技术方案。因为 Self-training 的技术方案可进行每训练一个模型就进行评估,先使用后优化,这对于业务来说是比较友好的体系。
5、近期 ASR 领域 Self-training 发展轨迹
锚定了 Self-training 目标后,从 2020 年开始我们就在对这个领域进行调研跟进。我们发现,在这个领域中主要还是 Facebook,Google,三菱 做得比较完善,其他诸如老牌 ASR 公司 Nuance 和一些高校也会针对一些具体问题发表一些改进方案或问题研究。在 2020 年,他们的研究方向主要如下:
(1) 2020 年
Facebook:
SELF-TRAINING FOR END-TO-END SPEECH RECOGNITION,
END-TO-END ASR: FROM SUPERVISED TO SEMI-SUPERVISED LEARNING WITH MODERN ARCHITECTURES,
ITERATIVE PSEUDO-LABELING FOR SPEECH RECOGNITION
其研究脉络为 朴素 Pseudo label 在 CTC 框架上的 strong baseline 及调研;朴素 Pseudo label 在 CTC/Attention hybrid 架构上的效果;多轮迭代式 Pseudo label 体系的研究。
Google:
由于 Google 的 Iterative pseudo-labeling 在 CV 领域已经有非常强的技术底蕴,所以一上来他们就给出了他们的多轮迭代式 Pseudo label+model ensemble 方案:Noisy Student Training,并拿下当年 Librispeech100 + 860 SOTA。当然,Iterative 训练中其实存在很多坑,尤其是多轮迭代所带来的数据实验数量的爆炸。这个在我们的方案中有明确的阐述。
三菱:
Iterative 模式,流程上是先对 teacher 进行多轮的 pseudo-labeling 训练,每训练一个 pseudo-labeling,内部就要打一遍标签,这样的多轮次会使训练变得很烦琐。所以从 2021 年开始,我们也逐步在各大领域中看到了 on-the-fly 的方式。比如三菱在 2012 年提出的 MPL(基于 mean teacher 演化而来)。但是 on-the-fly 意味着需要实时生成 label,而 ASR 的 label 生成质量同 decode 计算成本直接相关。简单的 CTC 的 greedy search 比较快,但其生成的转录文字质量较差;而较为常见的 shallow fusion 方案,仅由多个模型融合打分 decode 转录产生文字,基本上不可能在训练的时候实时产生。所以一般来说,on-the-fly 模式的最终效果其实不如 Iterative 模式。
其他:
Saleforce 来了一次“文艺复兴”, 重新将伪标签训练用在了 Essen 框架上。其标签生成采用了 CTC greedy search。Nuance 作为老牌 ASR 技术厂商,通过阐述 FixMatch 理论诠释了半监督的理论本质实际上就是 Consistency Training。
(2) 2021 年
三菱:
由于 on-the-fly 模式的缺陷,三菱在 2021 年发表了 advanced MPL,又回归了 Iterative 模式。他们将 teacher 模型和后续的 on the flying 训练流程拆开,同时切换成了对于音频效果更加稳健的 Conformer 框架。最后超越了 Google 的 NST 方案,成为目前的第二名。
Facebook:
Facebook AI 在 2021 年使用了 cache 机制,在模型训练过程当中同步另外一个进程 decode,如果 cache decode 满了,就把训练切成 cache 数据和 label 数据进行联合训练,N 步过后 catch 清空,然后重新进行 decode。可见,虽然 Facebook AI 说自己是 on-the-fly 模式,但本质来说还是轮次概念。其使用 36 层 transformer,拿到了截至目前 Librispeech100+860 的 SOTA,甚至可以持平 ESPnet 直接训练 Librispeech960 了。
03 我们半监督方案解决的问题
1、Iterative or on-the-fly
处于效果需求和目前学术界工业界的结论,我们的技术方向最终还是锚定了 Iterative 模式。
2、Iterative 的问题
但 Iterative 模式训练起来是非常烦琐的,由于伪标签数据的生成是每一轮训练过后均需要重新生成的,且若要达到很好的结果,根据 Google 和 Facebook 的经验,需要多轮迭代。
那么每轮迭代都有三个问题,第一,如何在伪标签上面产生高质量的数据?这其实本质上来说是最简单的问题,我们有各式各样的 decode 算法,哪个算法好就用哪个。第二,如何筛选出高质量的伪标签数据?因为我们不知道哪个标签是对的,不管质量再高,都会有一些问题存在,此时需要研究如何将出现问题的比例降低,有哪些方案可以降低。第三,整个 Iterative 模式中最大的难题就是,如何做标注数据和无标注数据的数据平衡。
Google 的 NST 的体系要做五轮迭代,就意味着每一轮的标注和无标注的配比都是不一样的。第二轮大概是 2:7,第三轮是 1:3,在 librispeech 100+860,这个有标签:无标签 维护在 1:3 上下被验证是比较合理的比值。但是在不同的任务线,其配比也不相同。Facebook 在 Librispeech+LibriVox 数据集上实验结果证明其比值需要在 1:10 以上。这导致最终在业务中进行落地的时候,实验成本非常巨大。比如有五轮实验, 每轮训练均需进行不同比值的多个数据实验,训练完成后挑选模型进行 decode 评估,然后在下一轮再次进行不同比值的多个数据实验,这样迭代五轮。由于 ASR 训练成本高昂,每一轮的训练节奏都令人非常痛苦。
另外,在有限的标注层面,如何进行模型的冷启动呢?一般来说,初始的训练数据是有标签的,训练数据都非常少。比如 Iterative 中初始的标签数据一般来说非常少,只占能获得的数据的 1/10 左右,那么怎么进行冷启动也就成为一个核心问题。
04 Improved NLPL 解决方案
基于这些问题,我们提出了自己的解决方案,发表于 Improved noisy Iterative Pseudo-Labeling for Semi-superivised Speech Recogntion 中。现在先给大家提前简单阐述一下我们的解决方案是什么样的。
1、模型框架
从 2020 年以后,我们就不再使用 Kaldi 体系了,而是切换到了一个类 ESPnet 的自研究框架。模型框架上,对于 CTC 的前端 sharedEncoder 和 LAS 的 decoder,我们均采用的是 transformer,图 1 左侧展示的是 Watanabi 在 CTC/Attention hybrid 那篇论文中的图,右边是对模型框架的介绍,模型参数方面,SharedEncoder 之前有一个 subLayer,采用的是 2 层 (33+512) 的 CNN,步进为 2,这可能与 ESPnet 中的框架略微不太一样,但基本上大同小异。ransformer 我们目前采用了 128 的 transformer,512 维度,FFN 是 2048,这跟大部分的 formerbase 模型也几乎是一样的。另外,AttentionDecoder 我们采用的是 6 层 transformer,它的参数配置跟 Encoder 也是一样的。语言模型方面,LT 人!插入的 4 我们额外添加了一个 6 层的 transformer 语言模型,其余参数配置与 BERT 是一样的,12 头,768dims,FFN 为 3072,这是整体的模型框架。
从 2020 年以后,我们就不再使用 Kaldi 体系了,而是切换到了一个类 ESPnet 的自研究框架。模型框架上,对于 CTC 的前端 sharedEncoder 和 LAS 的 decoder,我们均采用的是 transformer,图 1 左侧展示的是 Watanabi 那篇 CTC/Attention hybrid 论文中的图,右边是对我们模型框架的介绍。模型参数方面,SharedEncoder 的 sublayer 目前采用的是 2 层 (3*3+512) 的 CNN,步进为 2,Transformer 我们目前采用了 12 层 8 头,512 维度,FFN 是 2048,这跟大部分的 Transformer-based 声学模型也几乎是一样的。另外,AttentionDecoder 我们采用的是 6 层 transformer,它的参数配置跟 Encoder 也是一样的。
对于语言模型,我们额外添加了一个 6 层的 transformer 语言模型,其余参数配置与 BERT 是一样的,12 头,768dims,FFN 为 3072。

■图 1
2、其他通用设置
我们的实验数据采用 Librrispeech 100+860,100 作为有标注数据,860 作为无标注数据。LM 数据是 Librispeech 自己的训练数据,以及官方提供的 800W 的文本语料。我们的声乐特征采用的是 100 维 Fbank+3 维 pitch。为了缩减文本标签个数,我们使用了 BPE,把 word 数量压缩到 7002 个 pieces 以减少最终的输出,同时加速 CTC 的训练。
训练配置方面涉及学习率,学习率与 transformer 相似,但存在差异点,就是在 decay 到最后位置的时候,我们会提前 5000step decay 到最后稳定值,然后再缓慢保持一段时间。这跟后面维护模型稳定的技术是直接相关的,让它能够在那段时间之内稳定地训练一段时间,使模型平均能够跟得上。
3、如何在未标注的数据上产生伪标签
目前业内比较常见的产生 decode 算法且比较高质量的方法是 shadow fusion 和 deep fusion 体系。我们采用了 shadow fusion,并且将声学模型 CTC、LAS 以及 LM 相融合进行搜索,bean size 为 50。大致流程上同 ESPNET 差不多,但是我们有两点小小的改动:
第一个就是我们采用 CTC 贪心搜索的方式进行句子终结的判断,而 ESPNET 不是这么做的,它有自己的 end detact 算法。
第二个就是我们不会对路径进行过多的剪枝,而是尽可能多的把路径保留下来。
4、如何筛选高质量的伪标签数据进行下一轮半监督训练
在进行伪标签生成的时候,很多数据的质量其实是不敢恭维的,尤其是前期的训练,比如 NST 或者 Iterative Labeling 的第一轮或第二轮,此时模型在 librispeech dev 和 test 上的 WER 可能接近 9 或者 10 个点以上。
针对这种情况,Google 和 Facebook 采取粗暴排序取百分位的方法,类似于 ESPNET 中的 hypothesis 的分,然后在 decode 过程当中进行概率加和,把概率从小从大进行排序,然后取其中的 90%。这里可能存在置信率断崖式的情况,比如前面 85% 的数据的概率分布非常相近,然后在 85%~95% 的位置,概率突然出现非常大的差异,掉到可能几个点以上变化的概率。为了应对上述问题,我们采用分布检验的方式进行样本抽取:我们先假定它服从高斯分布,然后只保留高斯分布双边置信区间 90% 或者 95% 来做训练。这里的双边置信区间 90%/95%,并不代表数据保留 90% 和 95%,而是在高斯分布的情况下保留置信区间在这个里面的数据,所以它很有可能是少于直接保留 90%数据的。
5、标注/无标注数据配比如何平衡,才能让模型不会过拟合到无标注数据的为标签数据上
标注/无标注数据配比如何平衡是在进行多轮迭代的半监督训练时最大的问题,所有的前序研究均未给出如何进行比例筛选,而只给出了对应任务的大致比例,Facebook 他们是做的是 Librispeed 960+LibriVOX,它的比例是 1:10~1:54 之间。Google 是 Librispeech 100 +800,比例在 1:3 左右。
上述意见均无法指导实际生产中能确定落地使用的比例。比如直播场景的 ASR,以 100 个小时作为起步价,同时可能可以很轻松地获得很多同源无标注数据。但是该以怎样的比例把这些无标注数据和有标签数据放在一起,才不会让模型全部训练到无标签数据上;怎么训练模型才能保证其稳定且效果更好,这将需要进行无穷无尽的数据实验。当然,如果公司内部机器资源足够多的话,的确是可以去做这些实验的,但是很多时候大家并不都像 Google 和 Facebook 一样有那么多台机器,可以直接暴力穷举。
那么此时怎么才能得到每个业务线上的指导意见呢?我们在 Librispeech 100/860 上进行了详细的实验和定性定量分析,得到了一个指导意见,这个指导意见在目前我们来看是非常准的指导意见,可以教大家如何进行选择数据平衡选择。在这里我们先进行一个假设,这与我们为什么要做伪标签的半监督训练直接相关。我们认为在训练伪标签的时候,因为有标签数据和无标签数据是混合在一起的,所以对于一些伪标签数据,我们不知道是否标对了,应该在某些特质上让模型训练尽可能的“保守”,不要过拟合到那些错误的数据或者尾标数据上。但是又保证一定的样本多样性,因为如果完全保守,模型训练就会陷入它认为的数据层面带来的最优,然后原地踏步落入局部最优解。多轮迭代训练会加剧这个过程,导致模型越训练越过拟合。
为了确认应该在哪些地方保守,哪些地方保证多样性,我们把数据分成三个画像维度,第一个画像维度为音频长度,第二个画像维度为文本/pieces 长度,第三个维度为标签本身的分布。问题就可以转化为,我们在哪些维度要尽可能保证训练保守,哪些维度要尽可能保证样本的多样性。基于此,我们进行了大规模的实验,每一轮生成新的伪标签后,我们会根据不同的比例,构建多个训练样本的 candidate,也就是备选集,这个 candidate 中的每一批训练数据。在每一轮训练之前,我们都将每一份悬链 cadidate 同我们上一次训练的数据 在上述三个维度进行比较,并且对所有的 candidate 进行排名。比如 1:2 的 candidate 同上游在三个维度上进行排名,1:4 的 candidate 也会有一个排名,1:5 和 1:6 也会有一个排名,等等。
在评估排名方案上,因为 frame lenth 和 pieces length 是单一维的统计量,所以我们采用了 KS 检验。但 label 分布本身是多维的,所以我们先归一化 TF,然后利用欧式距离评估本轮数据和上轮数据的分布差异,再对每个 candidate 排名。
经过大量的实验,发现了一个非常明确的规律,就是 pieces 分布本身差异越小的前提下,更大的 frame lenth 分布差异和 pieces length 的分布差异一般会带来更好的新一轮的模型效果。上述逻辑可以被描述成一个通用范式,如图 2 所示。

■图 2
6、模型训练中如何确保模型不会过拟合到错误的伪标签上的 trick
这是在整个这个体系中我们发现的一个关键点。这里我们有两个维度。第一个维度是数据层面的维度,我们加入了 specAug 和 specAug++使整个数据具备更好的泛化性。同时在模型层面,类似于 MPL,我们会生成 online 和 offline 的生成,在前期选择 online 的结果,后期选择 offline 的结果,一般来说第五轮过后 offline 的结果会稳定高于 online 的结果。另外,我们还会进行 dropout 提升,对于 dropout 会从 0.1 逐步提升到 0.3,因为 伪标签训练 会有很大的过拟合风险,但是基本上提升到 0.4 以后就不会有任何新的收益了。
7、在有限的标注样本下,模型冷启动监督训练如何进行可以获得最优的效果
我们同样采用了两阶段式的训练。第一阶段式的训练从 dropout0.1 30epoch 搭配到第二阶 dropout0.13 100epoch 效果最优。具体的实验结果如图 3 所示。这也说明了一个问题,就是冷启动时应该先以一个比较少的 epoch,比较小的 dropout,快速拟合目标,然后上调 dropout,让它以一个相对比较泛化的训练配置,再训练更多的轮次,让模型达到最优。这种冷启动方式基本上可以和 Google 的 NST 体系的模型冷启动结果是持平的。
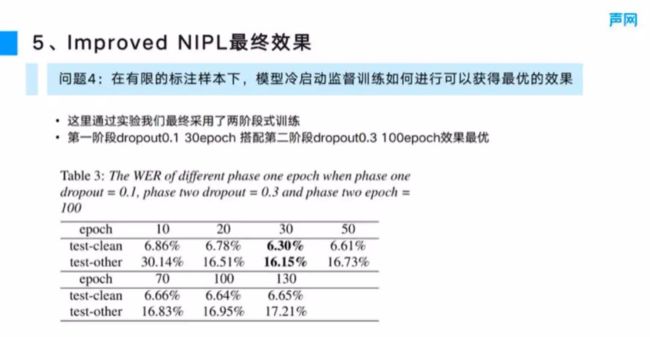
■图 3
最后介绍整个 improved NIPL 的最终效果。目前在截止我们投稿 interspeech 2022 来看,在 Librispeech 100+860 上比我们强的目前是两家,第一家就是三菱 MPL 的 conformer 是 3.8%/8.2%。但若控制变量为同样使用transformer,三菱只有 4.8%/10.1%,而我们是 3.93%/9.59%。另一家就是 Facebook 的 simIPL,它的 36 层 transformer 可以做到 3.8%/7.5%,而且不需要任何语言模型,如果加上语言模型和 rescore 可以做到 2.7%/5.2%。这个效果已经属于超出我们认知的效果了。因为我们训过 960 的数据,ESPnet librispeech 960 监督训练训练出来是 96.96 应该是 3.04%,这意味着 Facebook 不用 860 的数据,只 100 的 label 就可以做到 2.7%/5.2%。
最后介绍整个 improved NIPL 的最终效果。目前在截止我们投稿 interspeech 2022 来看,在 Librispeech 100+860 上比我们强的目前是两家,第一家就是三菱 MPL 的 conformer 是 3.8%/8.2%。但若控制变量为同样使用 transformer,三菱只有 4.8%/10.1%,而我们是 3.93%/9.59%。另一家就是 Facebook 的 simIPL,它的 36 层 transformer 可以做到 3.8%/7.5%,而且不需要任何语言模型,如果加上语言模型和 rescore 可以做到 2.7%/5.2%。这个效果已经属于超出我们认知的效果了。因为我们训过 960 的数据,ESPnet librispeech 960 监督训练训练出来是 96.96 应该是 3.04%,这意味着 Facebook 不用 860 的数据,只 100 的 label 就可以做到 2.7%/5.2%。
05 问答环节
1、对比 WER 效果如何?
我们的 test clean 是 3.93,test other 是 9.59,但是我们后来又继续进行了NIPL训练第七轮和第八轮,test other 还能再降低。虽然test clean 依旧维持在 3.93,但 test other 到今天为止已经降低到了约 9.3。三菱的 conformer 是 3.8%/ 8.2%,比我们的3.93 低,但它们的 transformer 是 4.8%/10.1%。Facebook 的 simIPL 是 3.8%/7.5%,对于 Facebook simIPL 我们表示有点不太相信,效果有点恐怖。这么来看我们应该是全球第三,比 Google 在 2020 年发表的那篇 NST 还要好一点。
2、介绍一下 CTC 的使用
CTC 在刚出现的时候,由于其训练优化的难度比较高,对于数据量的要求也比较苛刻,所以当时对 CTC 的使用都是些奇技淫巧。诸如上文所述 ESSEN,把 CTC 用于训练音素,然后依然跟大家一样去接 WFST。由于音素的个数相对于 word 来说小很多,大幅降低了 CTC 的训练难度,使之能在部分领域上同 MMI,LFMMI 等方案效果不分伯仲。直接裸上 CTC 端到端 ASR 数据成本会非常高昂。
如果你在 2020 年问这个问题,在新业务上会推荐你试一下 ESSEN 项目。但现在是 2022 年了,CTC 的工业界的使用中已经发生了很大的变化。Watanabi 那篇论文告诉大家,CTC 和 LAS hybrid 这套体系能够有非常好的效果,并且数据质量也不会像原先 CTC 那样要求那么高,因为 LAS 体系有非常多的优化技巧可以用于帮助训练。所以 CTC LAS 是目前相对来说比较标准的使用方案。如果你没有自己的 ASR 训练平台的话,我建议你尝试 ESPnet/Wenet,如果流式识别是核心业务诉求的话,Wenet 可以作为第一选择。