全链路业务追踪落地实践方案
2019年,“Kentik公司的一项调查表明,如今40%的组织认为自己是多云用户,他们的组织拥有两个或多个云服务提供商提供的云服务。三分之一的组织拥有混合云环境,其中至少有一个云计算服务提供商提供的云服务和内部部署数据中心或第三方的数据中心基础设施。 在此发展趋势下,IT运维管理工作进入了“运维最好的时代”,同时也是“运维最坏的时代”。企业在越来越重视IT运维对业务发展的价值的同时,发现IT架构发生了巨大变化。
- 业务部署模式极其灵活:公有云、私有云、混合云
- 业务节点分布极其广泛:很难到为业务提供支撑的XaaS实例的位置
- 调用承载关系极其复杂:微服务间的调用依赖数量相较从前呈指数级爆发
着眼于运维领域,面临如下困局亟待解决:
- 生产问题发现不及时:由于系统间服务调用关系不透明,以及传统“总量监控”的模式,造成交易链路中“问题服务”的影响无法快速进行预警与通知,运营监控存在一定滞后性。
- 排查问题工作量大:由于监控手段的限制,以及各系统运行数据标准不统一,生产问题的解决需调用大量“开发”与“运维”资源,且沟通成本较高。
- 解决问题效率低:由于各系统间运行数据没有统一的串联标识,以及记录标准不同,导致无法快速定位“问题服务”。
可观测性
由此,也引发了IT运维领域新的探索与实践,出现了不同以往的“SRE”、“可观测性”、“AIOps”等理念。为了解决新一代IT架构下上述难题,首先要解决系统运行状态数据化表征的问题,业界提出了“可观测性(Observability)”概念。
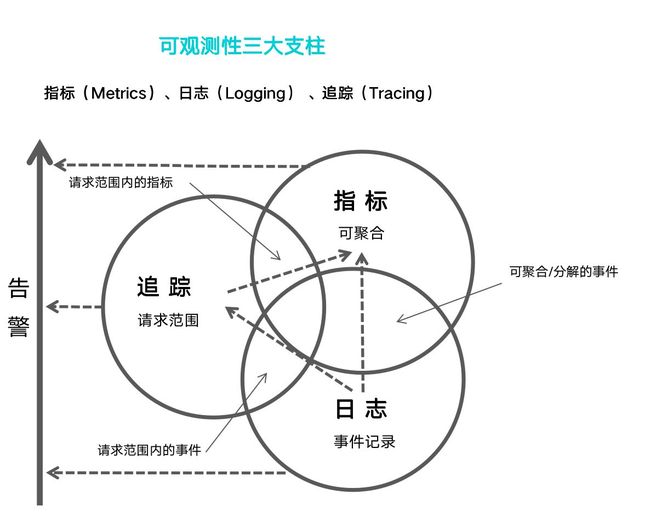
2017年,Peter Bourgon 提出的可观察性三大支柱——指标(Metrics)、调用链(Tracing)和 日志(Logging),这三个维度几乎涵盖了应用程序的各种表征行为,开发人员通过收集并查看这三个维度的数据(Telemetry Data)就可以做各种各样的事情,时刻掌握应用程序的运行情况。这已经成为当今可观测领域的标准,也是体系建设的地基。
- 指标(Metrics):一种聚合态的数据形式,日常中经常会接触到的 QPS、TP99、TP999 等等都属于Metrics 的范畴,一般是基于统计学原理来进行设计实现的;
- 日志(Logging):广义上的日志由业务请求或者事件触发,记录应用程序的状态信息快照。针对日志数据的统一收集、存储以及解析受诸多因素影响,比如结构化与非结构化的日志处理,往往需要一个高性能的解析器与缓存;
- 调用链(Tracing):起源于SOA技术时代,服务化带来的长调用链,仅仅依靠日志是很难去定位问题的,需要一些措施来进行复杂性补偿。因此它的表现形式比 Metrics 更复杂。
 落实可观测性的举措往小了说就是生产+收集+处理+消费观测数据。收集应用环境的观测数据并不是什么新鲜事。然而,从一个应用程序到另一个应用程序,收集机制和格式很少是一致的。
落实可观测性的举措往小了说就是生产+收集+处理+消费观测数据。收集应用环境的观测数据并不是什么新鲜事。然而,从一个应用程序到另一个应用程序,收集机制和格式很少是一致的。
对于开发人员和SRE来说,这种不一致性可能是一场噩梦。在全球范围提供可观测性解决方案中,不得不提及以下协议/工具,在支撑观测数据生产、收集、处理方面带来极大的便利,而全链路追踪则是运维领域实践可观测性消费的重要举措:
- 在云原生的场景下,虚拟化更加彻底、环境动态性更强。充分利用可观测性实现全链路追踪,以达到业务高可用、满足SLA等要求。
- 通过可视化的方式追踪交易全链路,实现快速发现问题、定位问题、辅助解决问题;以更直观、科学的方式产生并使用对观测数据进行实时监控分析。
- 引入AI的技术来进行自动化的异常发现、定位与修复。
问题与挑战
从链路层、数据层、应用层分别来看,要完成全链路追踪仍需要解决众多问题。链路层遇到的问题和挑战包括有云原生/虚拟化环境内外部流量数据的汇聚、复制、分流、过滤技术手段不完备,云原生/虚拟化环境与物理交换机环境流量数据建链困难;缺乏基于完整链路的性能监控分析。
数据层遇到的问题和挑战包括:不规范的日志(Logging)、调用链(Tracing)数据难以准确刻画出业务端到端拓扑,造成观测目标数据的不完整;不够精准的指标体系(Metrics)引起的信息干扰或分析失效。
应用层遇到的问题和挑战包括:传统的应用性能监控技术理念对于云原生/虚拟化环境下IT组件的观测能力要求不匹配。例如:多组件间异步交互的关联与排序、基于时间切片的调用链回溯等。 同时,从业务场景总体来看各层级内、层级间缺乏完整的端到端贯穿,无法完整描绘的被观测系统。
云智慧经过10多年持续实践、积累、探索、创新,构建并落地了完整的面向新一代IT架构的全链路追踪解决方案,下面我们将体系化的介绍一下该方案的技术理念及落地举措。
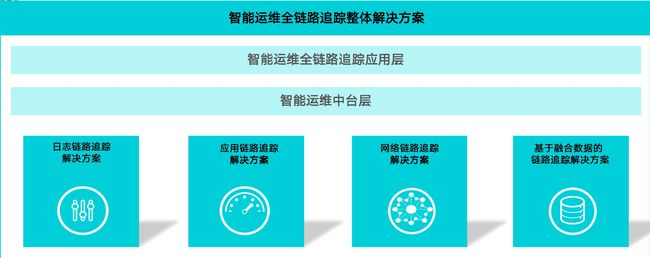
全链路追踪整体解决方案
适用场景
没有任何监控工具
目前处于手工运维。 随着业务发展,容器化应用,人工运维无法满足相对复杂业务的监控和业务链路追踪需求,快速响应业务,运维发展跟不上业务发展。
有少量监控工具
有少量的监控工具。如基础监控,网管监控工具,开源工具Zabbix等。但工具分散无法基于业务全链路追踪体系。
有比较全的工具
有比较全的监控工具,有一些可以形成链路的工具,如商业化应用性能监控,开源的ELK日志监控,同时也在探索Pinpoint、SkyWalking、OpenTracing标准等。但应用较传统,改造日志需要规划,无配置管理辅助形成全链路追踪。
运维数据统一管理和智能化
规划统一运维管理,目标是利用AIOps的能力提升调用链追踪,借助智能运维能力达到初步智能运维水平。工具层建设比较全,开源的、商业的,CMDB等。但对于调用链无法全面的展示和灵活使用全链路追踪数据。工具分散无法基于业务全链路追踪体系。链路不完整,链路和监控工具,监控数据无法形成合力,配置管理无法应用到全链路追踪场景。
解决方案
全链路业务追踪整体解决方案整体依托监控工具和智能运维平台,主要包含以下四个解决方案,日志链路追踪解决方案、应用链路解决方案、网络链路解决方案、基于融合数据的全链路追踪解决方案。 前三种解决方案依托监控工具,第四种基于融合数据的解决方案,融合各种运维数据,基于智能运维中台和算法能力。实现最终全链路最终目标。
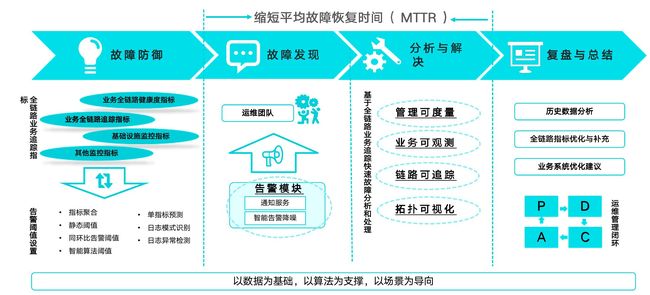
全链路业务追踪基本目标,显著缩短平均故障恢复时间。在运维过程的各个关键环节进行保障
- 故障防御阶段:全链路追踪指标规划和观测,指标同时转换为告警阈值,如果故障发生提前预测和告警,可以第一时间处理运维问题;
- 故障发现阶段:告警快速通知到运维团队,
- 分析与解决阶段:基于全链路业务追踪快速故障分析和处理,通过链路追踪和可视化快速分析定位运维问题,做到可度量可观测。
- 复盘和总结阶段:历史数据分析,全链路优化与补充,根因定位分析,业务系统优化建议。
通过以上过程,主要是故障发现阶段尤其是分析与解决阶段的效率提高,显著缩短平均故障恢复时间MTTR 整个过程中智能算法的作用
总结
回顾全链路追踪领域面临的问题和挑战,通过落地实践本方案内容,得到有效解决。
观测数据使用难的问题
- 通过AI算法能力与专家经验结合,实现复杂IT环境下故障快速检测、根因定位、性能优化;
- 识别业务场景关键调用链的全局性能,辅助业务优化;
- 提供可追溯的性能数据,量化运维部门业务价值
观测数据建链难的问题
- 基于运维数据中台的处理能力,将丰富的观测数据进行实时汇聚/处理/存储/分析,构建融合观测数据体系;
- 通过多维拓扑进行全程展示和上下游影响分析。
观测数据接入难的问题
- 多源头:前后端、跨云部署、三方工具等;
- 多数据类型:日志、指标、调用链、网络流量、三方拓扑等;
- 多语言:Java 、Go等;
- 多协议:OpenTracing、OpenTelemetry等;