【目标检测】评判指标:TP、TN、FP、FN、Precision、Recall、mAP。
混淆矩阵:True Positive、False Negative、False Positive、True Negative
一级指标:准确率(Accuracy)、精确率(Precision)、灵敏度(Sensitivity)(就是召回率Recall)、特异度(Specificity)
二级指标:mAP
目录
- 一、混淆矩阵
- 二、二级指标
- 三、三级指标mAP
一、混淆矩阵
先理解一下,TP、TN、FP、FN的含义:
| 字母 | 含义 | 备注 |
|---|---|---|
| T (True) | 样本被分类正确 | |
| F (False) | 样本被分类错误 | |
| P (Positive) | 样本被分为正样本 | |
| N (Negative | 样本被分为负样本 | |
| TP (True Positive) | 样本被分为正样本,且分类正确 | |
| TN (True Negative | 样本被分为负样本,且分类正确 | |
| FP (False Positive) | 样本被分为正样本,而分类错误 | 这就是统计学上的第一类错误(Type I Error) |
| FN (False Negative | 样本被分为负样本,而分类错误 | 这就是统计学上的第二类错误(Type II Error) |
将这四个指标一起呈现在表格中,就能得到如下这样一个矩阵,我们称它为混淆矩阵(Confusion Matrix):

按下图来解释,左半矩形是正样本(实心圆),右半矩形是负样本(空心圆)。一个2分类器,在图上画了个圆,分类器认为圆内是正样本,圆外是负样本。那么左半圆分类器认为是正样本,同时它确实是正样本,那么就是“被分为正样本,并且分对了”即TP,左半矩形扣除左半圆的部分就是分类器认为它是负样本,但是它本身却是正样本,就是“被分为负样本,但是分错了”即FN。右半圆分类器认为它是正样本,但是本身却是负样本,那么就是“被分为正样本,但是分错了”即FP。右半矩形扣除右半圆的部分就是分类器认为它是负样本,同时它本身确实是负样本,那么就是“被分为负样本,而且分对了”即TN

二、二级指标
在混淆矩阵的基础上,又延伸了如下4个指标,我称他们是二级指标(通过最底层指标加减乘除得到的)

有了上面TP TN FP FN的概念,Accuracy、Precision、Recall和Specificity的概念一张图就能说明。

P r e c i s i o n = T P T P + F P Precision =\frac{TP}{TP+FP} Precision=TP+FPTP
简单理解:准确率,越大越好。FP=0时,准确率为100%。
理解:分类正确的数量占总分类数量的比值,翻译成中文就是“分类器认为是正类并且确实是正类的部分占所有分类器认为是正类的比例”,衡量的是一个分类器分出来的正类的确是正类的概率。两种极端情况就是,如果精度是100%,就代表所有分类器分出来的正类确实都是正类。如果精度是0%,就代表分类器分出来的正类没一个是正类。光是精度还不能衡量分类器的好坏程度,比如50个正样本和50个负样本,我的分类器把49个正样本和50个负样本都分为负样本,剩下一个正样本分为正样本,这样我的精度也是100%,但是傻子也知道这个分类器很垃圾。
R e c a l l = T P T P + F N Recall =\frac{TP}{TP+FN} Recall=TP+FNTP
简单理解:查全率, ( 1 − r e c a l l ) (1-recall) (1−recall) 就是漏检率,所以 r e c a l l recall recall越大越好。FP=0,目标100%检测。(但FP不一定为0,准确率不一定为100%)
理解:分类正确的数量占总样本的数量翻译成中文就是“分类器认为是正类并且确实是正类的部分占所有确实是正类的比例”,衡量的是一个分类能把所有的正类都找出来的能力。两种极端情况,如果召回率是100%,就代表所有的正类都被分类器分为正类。如果召回率是0%,就代表没一个正类被分为正类。
三、三级指标mAP
首先需要了解交并比IoU,IoU 的全称为交并比(Intersection over Union),通过这个名称我们大概可以猜到 IoU 的计算方法。IoU 计算的是 “预测的边框” 和 “真实的边框” 的交集和并集的比值。
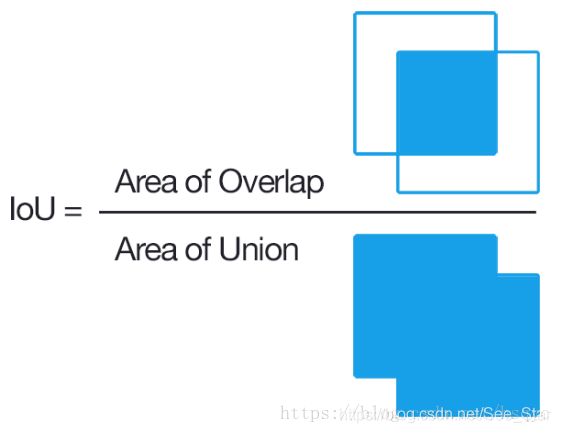
计算mAP
图片如下,要求算法找出face。蓝色框代表标签,绿色框代表算法给出的预测结果,红色字代表置信度。设定第一张图片的预测框为pre1,第一张图片的标签叫lab1,以此类推。
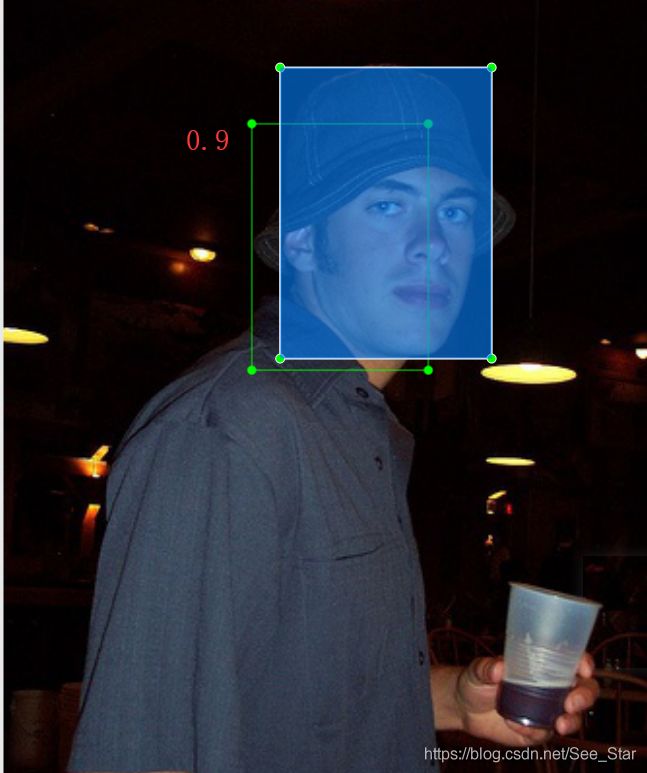

根据IoU计算TP、FP
根据IoU是否大于0.5这个阈值来判断pre属于TP还是FP。可以看出pre1、pre3为TP,pre2为FP。
排序
根据每个pre的置信度进行从高到低排序,这里pre1、pre2、pre3置信度刚好就是从高到低。
在不同置信度阈值下获得Precision和Recall
当阈值为0.9时,去除所有小于0.9的pre(pre2和pre3被去除,分类器内只有pre1)。此时TP=1,FP=0,TP+FP=1,由于pre1时TP,那么Precision=1/1。而此时总样本的数量为3,所以Recall=1/3。得到P、R值 ( 1 , 1 / 3 ) (1,1/3) (1,1/3)。
当阈值为0.8时,去除所有小于0.8的pre(pre3被去除,分类器内有pre1和pre2)。此时TP=1,FP=1,TP+FP=2。由于pre1是TP,pre2是FP,那么Precison=1/2。总样本数为3,所以Recall=1/3。得到P、R值 ( 1 / 2 , 1 / 3 ) (1/2,1/3) (1/2,1/3)。
当阈值为0.7时,去除所有小于0.7的pre(pre1、pre2和pre3都包含在内)。此时TP=2,FP=1,TP+FP=3。由于pre1和pre3都是TP,那么Precision=2/3。总样本数为3,所以Recall=2/3。得到P、R值 ( 2 / 3 , 2 / 3 ) (2/3,2/3) (2/3,2/3)。
绘制PR曲线并计算AP值
根据上面3组PR值绘制PR曲线如下。然后每个“峰值点”往左画一条线段直到与上一个峰值点的垂直线相交。这样画出来的红色线段与坐标轴围起来的面积就是AP值。
在这里 A P = 1 ∗ 0.33 + 0.67 ∗ 0.33 ≈ 0.55 AP=1*0.33+0.67*0.33\approx 0.55 AP=1∗0.33+0.67∗0.33≈0.55

计算mAP
AP衡量的是对一个类检测好坏,mAP就是对多个类的检测好坏。就是简单粗暴的把所有类的AP值取平均就好了。比如有两类,类A的AP值是0.5,类B的AP值是0.2,那么mAP=(0.5+0.2)/2=0.35
参考:理解目标检测当中的mAP