Simple-baseline for human pose estimation(官方代码)解析+制作自己的数据集
本人处于学习过程中,若该博客存在若干问题,望小伙伴们能够理解并指出,我会虚心接受并学习,也希望我们能够一起进步。
1、简述该开源项目的基本信息
1)是ECCV 2018年有关“Top-down多人姿态估计”的成果,来自微软亚洲研究院,更进一步的工作是“HR-Net”。
2)开源项目链接:https://github.com/Microsoft/human-pose-estimation.pytorch。
3)该开源项目基于的公开数据集:MSCOCO、MPII两种形式;有关数据集具体设置的方式,其中可采用“scale+center”或者“Bounding box”的方式。
4)可以基于多种深度学习框架(PyTorch、TensorFlow、PaddlePaddle、Gluon)官方采用PyTorch。
5) 官方基于“Ubuntu系统”。
2、自己制作数据集的一些细节
前提背景:基于MSCOCO数据集制作自己的数据集
(1)首先,确定MS COCO数据集中person_keypoints_train2017/2014.json或者person_keypoints_val2017/2014.json的具体细节,数据集中有些内容对于代码读取数据时并无作用,我们可以并不关注,仅是简单制作即可,主要集中于该任务的数据。
MSCOCO数据格式如下:
{ "info":{"xxx","xxx",...},
"license":[{"xxx","xxx",...}],
"annotations":[{"xxx""xxx",...}],
"categories":[{"xxx","xxx",...}]
}
我们主要关注于:"annotations"和"categories"。下面主要细说一下"annotations"
"segmentation:[[475.69,34.52,489.71,8.63,...]],
"num_keypoints": 13,
"area": 45726.9419,
"iscrowd": 0,
"keypoints":[x1,y1,z1,x2,y2,z2,...],
"image_id":10707,
"bbox":[xmin,ymin,w,h],
"category_id:"1,
"id":233159}
具体举例如下———————————————————————————————————————————————————
"segmentation:[[[475.69,34.52,489.71,8.63,511.28,2.16,540.4,5.39,550.11,32.36,536.09,76.58,560.9,94.92,594.34,111.1,600.81,146.7,585.71,213.57,574.92,283.69,569.53,298.79,570.61,335.46,544.72,388.31,528.54,435.78,536.09,472.45,470.29,473.53,474.61,439.01,476.76,396.94,476.76,364.58,476.76,313.89,474.61,265.35,475.69,229.75,480,207.1,474.61,180.13,458.43,200.63,440.09,210.34,434.7,211.42,422.83,142.38,423.91,91.69,426.07,75.51,437.93,53.93,445.48,105.71,439.01,122.97,451.96,176.9,464.9,143.46,471.37,114.34,474.61,99.24,467.06,72.27,473.53,45.3,475.69,35.6]],
"num_keypoints": 13,
"area": 45726.9419,
"iscrowd": 0,
"keypoints": [491,71,2,499,60,2,0,0,0,537,51,2,0,0,0,552,122,2,491,121,2,505,192,2,448,189,2,487,105,2,429,119,2,526,283,2,485,275,2,491,432,2,498,426,2,0,0,0,0,0,0],
"image_id": 10707,
"bbox": [422.83,2.16,177.98,471.37],
"category_id": 1,
"id": 233159}
——————————————————————————————————————————————————————————————
1)以上无需关注的是:“segmentation”,“iscrowd”,我认为是用于“分割”任务。
2)次要的信息:“area”,这个我不太确定,但我感觉在代码中用到该参数了。
3)"keypoints":z1代表可见性,具体包含三种值(0,1,2);
"image_id":就是图像名的后几位,当然要保证每张图像的名字不同(注:在该项目中我做了预处理,已将所有图像名按照0000000image_id.jpg(0个数不一定就是这么多,仅为举例)重新命名));
"id":这个是我遇到的一个小点,需注意要保证每张图像对应每个单独对象的id不同(即,每张图像存在多个人,而每张图像中每个人的id和在其他图像中的id要存在差异),否则图和关键点数据对应不上。
4)"bbox",可以通过"标注的关键点"获取,即[xmin,ymin,边界框w,边界框h],也可以通过"开源标注软件"进行边界框的标注。
边界框标注可参考如下:
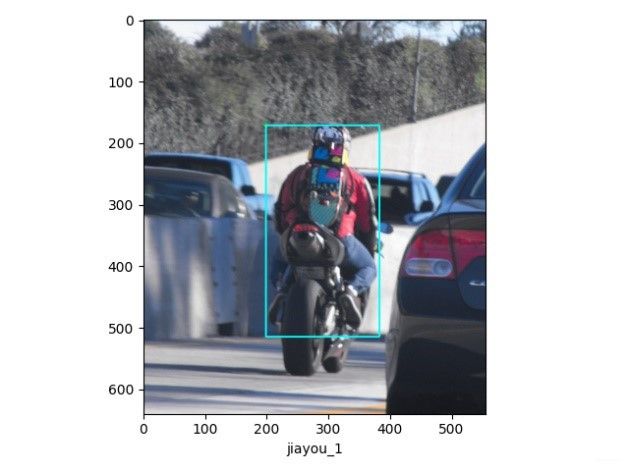

3、基于自己数据集实践开源代码
由于开源代码写的非常好,这里就不在赘述了,大家有什么问题可以讨论。
代码可实现内容:
1)保存训练和验证过程中的热点图和关键点可视化图的预测、真值图
2)保存每个训练epoch的模型,用于Tensorboard可视化训练验证过程中的acc和loss数据
3)保存从收到指令到结束的所有log信息
4)可基于训练好的模型进行测试并进行可视化(这里可视化我貌似采用的是HR-Net中的plot_coco.py)
我记得需要注意的地方是:
1)由于我们设置的关键点个数可能并不是“MPII的16个”或者是“MSCOCO的17个”,所有这里代码里注意一下;
2)并且,在评估时有利用的sigma,在算这个时也和“关键点个数”有关。
3)在保存以上信息时,存储位置需特别注意(output还是存储在pose_estimation下面)