优雅的代码—编程风格
各种程序语言的源代码,相当于是程序员与计算机的接口。因此看待代码,就有两个视角:
一个是编译器的视角,也就是所谓机器的视角。编译器将代码转化成机器可以执行的二进制格式,因此代码必须让机器易于理解。这一点其实比较容易做到,各种语言都有其相应的语言规则,只要符合这些规则,编译器就能准确地翻译为执行代码。
另一个是程序员的视角,就是所写的代码让别的程序员(也包括自己)容易理解。这种理解不仅仅是语言规则方面的理解,更主要的是对程序所要实现的功能、采用的算法以及运行结构的理解。既便于调试、审查和问题解决,也便于维护、功能扩充、版本升级和提高开发效率。在本章我们主要从程序员的视角来探讨易于理解代码的编写。
所谓代码的风格,就是体现在整个项目的目录结构、文件命名、变量命名、文件命名、注释等代码编写的各个方面的一套统一规则。在理解这套规则的基础上,可以容易地找到各功能实现的代码、理解其中的实现算法,以便于查找问题,扩充或增加功能等。
良好的代码风格,在以代码为中心的设计中,起着核心的作用。从开发流程的角度,源代码也是设计文档的一部分,具有很强可读性的源代码再加上一个对整体设计的简要描述文件就可以构成完整的设计文档。这相比于传统的概要设计、详细设计以及源代码所构成的设计资料,更加清晰,易于保持设计与代码的一致性,而且以后的更新维护都可以以代码为中心进行,也更加容易。
本章主要介绍代码风格方面的一些实践经验。这些经验在我们以代码为中心的项目开发中起到了关键的作用。当然,这些规则并不是唯一的,只要保证整个项目中风格统一,并在项目成员中达成共识,采用其它的代码风格也完全没有问题。
1. 文件结构
文件结构包含目录构成和文件命名。一个项目的源代码不可能只有一个文件,而且也不可能将所有源文件放在一个目录下,因此需要设计相应的目录结构和文件的命名方式, 而这同样是为了增加代码的可读性。一个设计良好的文件结构,甚至可以从文件名和目录结构大致了解系统的架构。这不但有助于迅速找到相关的文件,而且也有助于理解作者的设计思路。虽然各种集成开发环境提供了丰富的文件搜索功能,但设计良好的文件结构绝对是一件赏心悦目的事。
在一个项目中,目录结构的设计往往在基本的设计要素确定以后进行。这些要素包括:明确功能需求、决定是否使用操作系统、确定任务构成等等。在设计目录结构时,需要考虑以下一些原则:
- 如果使用操作系统,操作系统相关的内容组织在同一个一级目录下。而操作系统内部的文件组织和目录结构保持原样不变。比如图 1‑1就是一个以FreeRTOS为操作系统的目录结构例子。XXX Project作为整个项目的根目录,在其下有一个OS目录,其中包含操作系统的目录,此处是FreeRTOS。还有一个虚框标出的OSAL目录,OSAL(OS Adaption Layer)是操作系统适配层,用于提高应用程序的不同操作系统之间的可移植性。如果所开发的项目没有在不同的操作系统之间移植的需要,也可以没有OSAL。FreeRTOS以下的目录就完全照搬了操作系统的目录构成。

图 1‑1 操作系统的目录结构
- 依赖于硬件的部分可以单独组织一个一级目录。与硬件相关的代码分为两个部分:一部分是与CPU相关、支持操作系统工作的。这部分一般与操作系统放在一起,如FreeRTOS中,这一部分就放在了FreeRTOS下的Port目录下;另一部分是与应用程序直接相关的,主要是各种外设的驱动程序,可以直接放在一级目录,命名可以根据具体系统的特点,如drivers、hardware等等,或者其他易于理解的目录名,如图 1‑2所示。

图 1‑2 硬件的目录结构
根据应用系统的特点,如果需要支持多个硬件平台,为了移植方便,可以增加一个HAL(Hardware Adaption Layer)层。HAL层根据应用系统的要求,定义了应用程序与设备驱动的接口,从而保证应用程序与硬件平台之间的无关性,可以不做任何修改运行在不同的硬件平台上。
- 共通的部分放在公共目录下。比如在一级目录中,设置一个common目录,存放所有的共通的函数。这样的函数包括有些数学计算函数(比如checksum计算等)、LOG机制(LOG等级、LOG输出API等)等。基本的原则是,如果一个函数被多个任务调用,就可以考虑放到common目录下。
- 根据系统的任务构成设定其他一级目录,原则就是一个任务一个目录,如果一个任务当中处理的事物较多,可以在其中设定子目录。
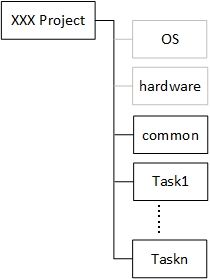
图 1‑3 应用程序的目录结构
很多程序员习惯于将c文件与h文件(头文件)放在不同的目录里,比如C文件在src目录下,h文件在inc目录下。根据系统的规模和开发人员的习惯,在每一个目录下,也可以增加src、inc子目录。
2. 命名规则
程序中变量或函数,特别是跨越多个文件使用的全局变量或函数,其命名应尽量包含更多的自我说明的信息。这些信息可以知道包括类型、用途、单位(表示时间等的变量)等的信息。当然也可以通过注释详细说明该变量或函数的含义,但是不可能在所有应用的地方都加上注释,在审查代码、调试、扩展功能时,需要频繁参照注释,十分不方便。因此最好不通过注释,而只是从命名上就能得到其各种信息。在程序开发的实践中,经过大量程序员的总结,有几大经典的命名规则:
- 匈牙利命名法【Hungarian】,据说是由微软的程序员查尔斯· 西蒙尼(Charles Simonyi)所 提出,广泛应用于Windows中。 Windows 编程中用到的变量和宏的命名规则即采用匈牙利命名法。匈牙利命名法通过在变量名前面加上相应的小写字母的符号标识作为前缀, 标识出该变量的作用域, 类型等。这些符号可以多个同时使用,顺序是先 m_(成员变量),再指针,再简单数据类型, 再其他。例如:m_lpszStr, 表示指向一个以 0 字符结尾的字符串的长指针成员变量。前缀之后的是 首字母大写的一个单词或多个单词组合,该单词组合要指明变量的用途。 微软的匈牙利命名法中常用的小写字母有:
a(数组Array)
b(布尔值Boolean)
by(字节Byte)
c(有符号字符 Char)
cb(无符号字符Char Byte)
cr(颜色参考值 ColorRef)
cx(x轴坐标差)
cy(y轴坐标差)
dw(双字Double Word)
fn(函数)
h(句柄Handler)
i(整型)
l(长整型Long Int)
lp(长指针Long Pointer)
m_(类的成员)
n(短整型 Short Int)
np(近指针Near Pointer)
p(指针Pointer)
s(字符串型)
sz(以 null 做结尾的字符串型 String with Zero End)
w(字Word)
可见主要是为C++、C#等服务,前缀字符较多,要记住和熟练运用不太容易。
- 骆驼命名法【camelCase】是指混合使用大小写字母来构成变量和函数 的名字,在名字中的每一个单词首字母大写,其他小写,像骆驼一样,有峰有谷。例如,printEmployeePaychecks()就是一个用骆驼式命名法命名的函数。使用骆驼命名法的目的就是便于阅读,配以准确描述功能的变量或函数命名,就有助于理解其功能,因此选一个合适的名字很重要。与骆驼命名法类似,还有下划线法命名法。比如上面的函数的同一个函数用下划线命名法即为print_employee_paychecks(),使用下划线法_来分割函数名中的每一个单词。 骆驼式命名法近年来越来越流行了,在许多新的函数库和 Microsoft Windows 这样的环境中,它使用得当相多。另一方面,下划线法是 c 出现后开始流行起来的,在UNIX 环境中,使用非常普遍。
- 帕斯卡命名法【PascalCase】 与骆驼命名法类似。只不过骆驼命名法是首字母小写,而帕斯卡命名法是首字母大写 。如: 如上述函数,用帕斯卡命名法即为PrintEmployeePaychecks()。
良好的命名规则可以让人一目了然地知道它的具体含义。比如sUserName是一个存储用户名的字符串;lUserID是一个存储用户ID的长整型数;printEmployeePaychecks()是输出员工薪水表的函数。采用这样的命名方式可以减少注释,提高程序可读性。
严格遵循以上的命名规则有时候也会带来一定的副作用,特别是匈牙利命名法,不但要定义很多稀奇古怪的小写字母的组合,而且会使得变量或函数名变得很长。有时候反而阻碍程序整体的可读性。
因此在具体的编程实践中,需要做一些折中。关于变量命名,可以采用一些以下的原则:
- 参照范围跨越多个文件的全局变量采用匈牙利命名法+骆驼命名法,只在一个函数中使用的局部变量采用骆驼命名法。如果函数比较简单,在不影响理解的前提下,甚至可以不遵循任何命名规则,但这个不推荐。
- 在嵌入式系统中,经常用到一些带单位的变量。最常见的是时间相关的变量,而且时间单位也根据使用场景,可能各不相同:有的是微秒(us)、有的是毫秒(ms),有的是10毫秒(ms),有的是秒(s)。为了便于理解,在变量名上带上单位也是一个非常好的做法。如:ulCurrentTime_ms表示用无符号长整形表示的当前时间,单位为毫秒。
- 将变量的类型带在变量名中,以类型的缩写作为变量名的开始。这是匈牙利命名法的一个子集。比如以下就是一个字母组合开头与类型的关系:
ul:无符号32bit整形数, 如ulCurrentTime, ulLength等
us:无符号16bit整形数, 如usPacketlength, usPassedTime等
uc:无符号8bit整形数,如ucStringLength,
l:有符号32bit整形数, 如ulCurrentTime, ulLength等
s:有符号16bit整形数, 如usPacketlength, usPassedTime等
c:有符号8bit整形数,如ucStringLength,
除了类型,也可以带上区分是否是指针变量的标识,如用p表示是一个指针变量,没有p表示一个普通变量。如
pul:指向一个无符号32bit整形数的指针,如pulPointer
其他依次类推。
函数命名在遵循上述命名规则的基础上,可以考虑以下原则:
- 以动词开头,以一句可以描述函数功能的语句来命名。比如:
fillMACHead():填充MAC头
calSalarySum():计算工资总额
printEmployeePaychecks():打印员工工资表
此处采用了骆驼命名法,同样也可以采用帕斯卡命名法,如fill_MAC_Head()。
- 也可以根据上述将类型带在变量名中同样的方式,将返回值的类型带在函数名中。上述例子可以分别命名为:
bFillMACHead():填充MAC头,返回一个逻辑值,表示填充成功或失败
usCalSalarySum():计算工资总额,返回一个无符号16位整形数,表示工资总额。
vPrintEmployeePaychecks():打印员工工资表,无返回类型
- 如果一个函数的命名不能用一句话来描述,往往说明该函数的内聚性不够高,也就是说企图把两个或多个功能实现在了一个函数里。此时往往可以考虑将其分割为两个或多个函数。考虑一个从串口接收数据帧,判断其是否合法,如果合法回复确认帧,如果不合法,则回复否认帧。如果企图把这些功能实现在一个函数里,就会发现很难用一句话来给这个实现函数命名。但如果分成以下几个函数:
pucReceiveFrame(),从串口接收数据帧,返回指向收到数据帧的指针
bIsLegalFrame(),判断一个数据帧是否是一个合法的帧
bSendAck(),发送确认帧
bSendNack(),发送否认帧
则各个函数的功能基本可以从其名字中直接得到,而且每个函数实现一个功能,内聚性很高。
3. 注释
注释是提高程序可读性的一个非常关键的因素。各种风格良好的开源代码中无不包含大量的注释。但代码中的注释的撰写也跟一本书的撰写一样,需要考虑读者的因素,也就是说这是写给什么样的人来看的。因为这直接关系到注释书写的详略、风格、用词,甚至于使用语言(用英文还是中文)。关于注释语言,随着unicode的普及,使用各种语言渐渐地都不成为问题,但考虑到编辑器的普适性,可能的话,还是推荐用英文书写。
因为注释总是跟代码关联在一起的,其读者首先是程序员、或者是熟悉程序语言的管理人员(为了代码审查等)。另外,还应该是对产品的功能需求有整体的了解,阅读过系统的概要设计文档,了解系统的整体架构。因此在书写注释时,基于产品的功能需求和概要设计,在其中有描述的内容,可以直接参照,也可以使用各种专业术语。
在写代码时,除了必要的版本、时间、作者等信息。可以在每个源文件的开头写一段该文件的实现功能的说明。这有几个好处:一是有助于明确什么样的函数适合放在这个文件中,在代码重构、功能追加的时候,这非常有帮助;还有在通盘了解程序的功能与整体结构时,也是非常好的参考。下图是一个源文件头的说明部分的例子,这是一个实现串口通信的文件,其中还包含了所利用的硬件功能、主要的实现策略等。

除了整个文件的注释,每个函数也都得有注释。以下是一个函数注释的例子。函数注释一般由以下几个部分组成:
- 函数功能、实现算法的简要说明。实现算法的说明可以让其他程序员在看代码之前就大致了解函数本身,可以大大方便程序的修改、重构和审查。
- 注意事项。这并不是必须的,主要用来提示函数的调用者需要注意的事项。可以让调用者像利用系统API一样,不需要了解实现的情况下,正确调用该函数。这中间也可以包括对函数实现者的提醒,如上例中关于线程安全的说明。这种说明主要是把程序实现中隐含的前提条件显在化,这在以后的功能追加、程序修改或重构的时候可以有效避免违反这些前提条件,而导致bug。
- 形参说明。在上例中,形参分成了三类:输入参数、输入/输出参数、输出参数。这样分类在实现的时候可以随时提醒自己形参的使用是否正确,也可以让程序的阅读者在看代码之前就准确把握形参的使用。如果形参是指针,还得说明是调用者还是函数内部分配内存、释放内存等。
- 返回值说明。主要解释返回值的含义、取值范围等。

在实现一个功能的时候,一种良好的实践做法是先定义全局数据结构、函数声明、文件/函数的注释。撰写这些内容的过程实际上是功能实现的设计过程。在设计过程中当然会后修改,修改注释远比修改代码简单,而且更容易保持逻辑清晰和实现的一致性。因此,先写注释,再写代码。下表是一个关于串口通信的函数声明和注释(局部,也不包括全局数据结构的定义)的例子。
|
/************************************************************************ * example.c V1.0.0 * Copyright (C) 2019 xxx Co. Ltd. All Rights Reserved. * Created by Rongcai Hu, Apr. 1, 2019 * * Implement UART communications, excluding operations of Rx data and * packing of Tx data. These features will be implemented in * corresponding tasks. * - Duplex communication. * - There is Rx/Tx FIFO in UART. * - DMA is used in Tx. * - A UART reception task to read data and dispatch to the other tasks. * - A buffer waiting list is used to hold Tx data when Tx is busy, * and interrupt handler will drive Tx when it becomes free. * ***********************************************************************/ /*********************************************************************** * * Send data to UART. The data will be linked to the waiting list. * If the UART is free, the data will be copied to DMA, and start * Tx immediately by calling vStartUartTx(). * * Attention: * - It may be called by different tasks. Therefore implementation * should be thread-safe. * - The caller should NOT free the data buffer if succeed, otherwise * the caller should free the data buffer. * * IN: * pucData: Pointer to the data buffer to be sent. * ucDataLen: Length of sent data. * * IN/OUT: * none * * OUT: * none * * Return: * TRUE: Succeed, may start Tx immediately, or be linked to the waiting list. * FALSE:Failed to send or link to the waiting list. * **********************************************************************/ uint8_t ucSendUartData(uint8_t *pucData, uint8_t ucDataLen) { } /******************************************************************************** * * Start UART transmission. If UART is free, choose the first buffer from waiting list * and copy the data to DMA, and start Tx immediately. When the data is copied, the * buffer will be freed. if the UART is busy, do nothing and exit. * * Attention: * - It MUST be called in CPU-locked context. * * IN: * none * * IN/OUT: * none * * OUT: * none * * Return: * none * ********************************************************************************/ static void vStartUartTx(void) { } |
除了文件和函数的开头,在代码当中,也得加上必要的注释。这些注释的目的是辅助程序员理解代码,因此如果是可以从系统的API说明书、变量名、程序本身获得信息的,就没有必要在注释中再加以说明。比如以下的注释就显得多余:
|
//Allocate buffer buf = AllocateBuffer(MAX_BUFFER_SIZE); |
因为从函数名中可以得到注释所说明的信息,注释并没有提供比代码更多的信息。以下的注释就好得多:
|
//Allocate buffer for UART reception. buf = AllocateBuffer(MAX_BUFFER_SIZE); |
因为该注释解释了分配buffer的原因,回答了为什么需要申请缓存的问题。而这样的信息是代码当中不包含的,有利于程序员理解代码。因此注释的最重要的目的是解释代码的意图,回答为什么要这么写,而不是代码做什么的问题。以下的注释就较好地解释了这段代码的意图。
|
//Find out the maximum value in the array. iValue = piArray[0]; for(uint8_t ucStep = 1; ucStep < ARRAY_SIZE; ucStep++) { If(iValue< piArray[ucStep]) iValue= piArray[ucStep]; } |
其实如果按照前面的变量命名原则,就会更有助于对代码的理解,甚至可以不需要注释。
|
//Find out the maximum value in the array. iMaxArrayValue = piArray[0]; for(uint8_t ucStep = 1; ucStep < ARRAY_SIZE; ucStep++) { If(iMaxArrayValue < piArray[ucStep]) iMaxArrayValue = piArray[ucStep]; } |
另一个必须要注释的是代码当中有疑问的地方。这包括几类:
- 所使用的API当中有bug,必须作特殊处理来规避。比方说,有一个创建信号量的系统调用osCreateSemaphore(int initValue),如果initValue等于10时不能正常工作,就需要作类似以下的规避处理:
|
/* *In osCreateSemaphore(int initValue), there is a bug, which it doesn’t work if initValue is 10. *we use 11 to get round this bug. */ #define SEMAPHORE_BROKEN_INIT_VALUE (10) #define SEMAPHORE_ROUND_INIT_VALUE (11) If(SEMAPHORE_BROKEN_INIT_VALUE == iInitValue) { iInitValue = SEMAPHORE_ROUND_INIT_VALUE; } osCreateSemaphore(iInitValue ); |
- 为了适应外部系统的要求,而作的特殊处理。这与规避API Bug类似,开发中的系统在与外部系统交互时,可能需要规避外部系统的bug而作特殊处理。比如在下面的例子中,假设于外部系统之间用数据帧通信,为了确认数据帧的正确送达,采用序列号来标识每个数据帧,序列号一个字节,有效范围为0-255。但外部系统因为实现的问题,处理不了序列号为255的数据帧。为了规避该问题,可以采用以下的实现:
|
/* *Because the receiving system has a bug, which it cannot deal with the case that the sequence *number is 255, we have to get round it with plus 1. */ #define BROKEN_SEQUENCE_NUMBER (255) If(BROKEN_SEQUENCE_NUMBER == ucSeqNo) { ucSeqNo++; } |
其中的注释清楚地说明了这样做的原因。
- 因为代码重构等原因,处理流程作了变动,在删除处作相应的注释,以便更好地理解流程。在下例中,当事件(比如超时)发生时,需要立即终止发送,因此将原先在任务中的代码移到中断处理程序中。但为了以后更容易理解执行流程和其中的原因,不是将该行直接删除,而是加注释后将该行保留。
|
/* *In order to stop Tx immediately, the following code is moved to interrupt handler. */ //vStopOngoingTx(); |
另外,在定义全局数据或者数据结构时,需要加相应的注释。包括定义的意图、各个变量的准确含义。如果有特殊的取值范围、单位等的要求,也需要明确说明。
最后,如果要想让注释真正有用,切记注释必须与代码一致。与代码偏离的注释是最坏的注释,远比没有注释坏。因此,前面我们倡导先写注释整理思路,然后写代码;同样在修改代码的时候,也应该先修改注释,再修改代码。如果是在调试代码,那也应该在调试结束以后,及时整理代码,包括修改注释。
注释也不是越多越好,最理想的情况是恰到好处的说明。比如变量名、宏定义或者函数名可以无歧义地说明其含义时,则不需要加注释。如果是对相同事项所作的相同内容的说明,在一处注释即可。比如对于一个函数,如果在函数定义时,已经有关于其功能的完整说明,在调用处就不需要再加关于其功能的注释。还有,如果是对系统API的调用,就不需要加以说明。
4. 宏定义
另一个良好的习惯,是在代码当中用宏定义取代数字常数。任何数字常数都要避免直接使用,而是定义成宏,然后调用宏。直接写在代码中的数字也被叫做魔幻数字,如果还没有注释,别说别人不理解,就是作者自己隔一段时间看着也发蒙。比如以下的代码,带上两个魔幻数字2和5,再加上变量命名没有自说明性,很难理解这段代码的意图。
|
If((state == 2) && (count < 5)) { sendFrame(aFrame); Count++; } |
采用宏定义取代直接使用数字,有以下几个好处:
- 通过适当的宏名,可以描述该变量的含义,使程序已于理解。比如修改上面的程序如下:
|
If((ucState == STATE_TIMEOUT) && (ucSendCount < MAX_SEND_COUNT)) { sendFrame(aFrame); ucSendCount ++; } |
即使没有任何注释,也能基本理解程序的意图。即便一个常量在程序中只使用一次,也强烈建议定义成宏。因为用宏名可以说明常量的含义,便于理解;而且随着功能的扩展,完全有可能将来在程序的别的地方也可能引用到该宏。
- 由于引入宏名,必须考虑该宏的含义,从而促使程序员在写代码时找出常量之间的关系。假设一个网络最大可以容纳1001个节点,同时需要用位图来表示各个节点的状态,最大位图需要126字节。很显然,这两个数之间是有联系的,如果直接用数字编程,但网络最大可容纳节点数改变时,最大位图所需字节数的修改容易遗漏而导致问题。而且这种问题往往反映为内存溢出等,很难定位。而如果用宏定义,可以一目了然地反映它们之间的关系:
|
#define MAX_NODE_NUM (1001) /* * If MAX_NODE_NUM is an integral multiple of 8, divide it with 8; otherwise plus 1. */ #if (((MAX_NODE_NUM>>3)<<3) == MAX_NODE_NUM) #define MAX_BITMAP_NUM (MAX_NODE_NUM>>3) #else #define MAX_BITMAP_NUM ((MAX_NODE_NUM>>3) + 1) #endif |
- 便于常量的修改。上面的例子中也可以看得很清楚,只要修改宏定义就可以完成常量的修改,不需要从一个个文件中找到那些数字一一修改。
5. 代码布局
在编码过程中,考虑代码布局主要是为了体现代码的逻辑结构,提高程序可读性。在布局时,主要考虑以下一些因素:
- 使用缩进
几乎所有程序的代码,都使用的缩进。而且在有的语言中,比如python,缩进体现了程序的作用范围,起到了C语言中大括号的作用,不合适的缩进直接导致程序出错。但在一般的语言中,缩进更多的是反映出处理的层次结构,让代码更易于理解。而且适当的缩进也让程序更富美感。
- 用空格代替tab
空格和tab主要用于程序的缩进。用tab缩进时,编辑器往往能够提供自动对齐的功能,从而提供编程效率。但在不同的编辑器中,tab对应的空格数并不统一,往往在一个编辑器里,层次清晰整洁的程序,用另一个编辑器打开时,就显得前后错开,十分凌乱。因此推荐用空格缩进,这样无论在什么编辑器上,都会显得层次清晰整洁。一般的程序编辑器都提供了用空格取代tab的设定,只要利用该设定,就可以在不影响编程效率的前提下,统一用空格缩进。以下是Keil设定的例子。
- 适当使用冗余的括号
根据C语言的运算符优先级规则,有些可以不使用括号的地方,为了增加可读性,也使用括号。比如以下的两个例子,就是使用的冗余括号。
- 适当插入空行
在源代码中,除了缩进,适当的空行也有利于提高程序可读性,特别是在对一件事务的处理转向另一件事务的地方。
- 保持编码风格的一致性
在上述介绍的各种编程风格中,各有优缺点。在具体使用中,也不是全部都需要严格遵守。但在一个项目的实现中,最好保持编程风格的一致性。这样即利于程序的理解,也利于整体系统的一致性。