python高频面试问题(二)
1. 解释什么是栈溢出,在什么情况下可能出现。
栈溢出是由于C语言系列没有内置检查机制来确保复制到缓冲区的数据不得大于缓冲区的大小,因此当这个数据足够大的时候,将会溢出缓冲区的范围。
在Python中,函数调用是通过栈(stack)这种数据结构实现的,每当进入一个函数调用,栈就会加一层栈帧,每当函数返回,栈就会减一层栈帧。由于栈的大小不是无限的,所以,递归调用的次数过多,会导致栈溢出。
以上内容来自百度百科。https://baike.baidu.com/item/%E6%A0%88%E6%BA%A2%E5%87%BA/8538051?fr=aladdin
栈溢出的几种情况:
局部数组过大,当函数内部的数组过大时,有可能导致堆栈溢出。
递归调用层次太多。递归函数在运行时会执行压栈操作,当压栈次数太多时,也会导致堆栈溢出。
指针或数组越界。这种情况最常见,例如进行字符串拷贝,或处理用户输入等等。
以上内容来自,https://blog.csdn.net/u010590166/article/details/22294291/
2.简述Cpython的内存管理机制
Python和其他高级编程语言,如Java、Ruby或JavaScript等一样,有自动内存管理机制。所以许多程序开发人员没有过多地关注内存管理,但是这可能会导致更多的内存开销和内存泄漏。
引用计数
每一个Python对象都有一个引用计数器----用于记录有多少其他对象指向(引用)这个对象。它存储在变量 refcnt 中,并通过调用C宏Py_INCREF实现引用计数增加和Py_DECREF实现引用计数减少的操作。 Py_DECREF更复杂点,当引用计数器到零时,它会运行该对象的释放函数,回收该类型的对象。
通常以下两种情况你需要考虑这个宏定义:实现自己创建数据结构,或者修改已经存在的Python C API。如果你使用Python内置的数据结构,那么不需要任何操作。
如果想不增加引用计数,可以使用弱引用或 weakrefs 引用对象。 Weakrefs对于实现缓存和代理非常有用。
垃圾回收(GC)
引用计数是在Python 2.0之前管理对象生命周期的唯一方法。它有一个弱点,它不能删除循环引用的对象。 循环引用的最简单的例子是对象引用自身。
通常情况下,可以避免使用循环引用对象,但是有时是不可避免的(例如:长时间运行的程序)。
为了解决这个问题,Python 2.0引入了新的垃圾回收机制。 新GC与其他语言运行时(如JVM和CLR)的GC的主要区别在于,它仅用于寻找存在引用计数的循环引用。
循环引用只能由容器对象创建,因此Python GC不会跟踪整数,字符串等类型。
GC将对象分为3代,每一代对象都有一个计数器和一个阈值。当对象被创建时,阈值会被自动地指派为0,也就是第0代对象。当计数器大于某个阀值,GC就会运行在当前对象代上,回收该对象。没被回收的对象会被移至下一代,并且将相应的计数器复位。下一代的对象保留在下一代。
在Python 3.4之前,GC有一个致命缺点----每个对象重载了del__()方法,因为每个对象都可以相互引用,所以GC不知道该调用那个对象的__del()方法,这会导致GC直接跳过这些对象。具体详细信息可以参考 gc.garbage并且循环引用需要编程人员手动打破。
Python3.4介绍了一种最终的解决方法finalization approach ,现在的GC可以打破对象的循环引用,而不在使用gc.garbage介绍的方法去回收对象。
此外,值得一提的是,如果你确定你的代码没有创建循环引用(或者你不关心内存管理),那么你可以只依赖引用计数器自动管理内存,而不使用GC去管理内存。
以上内容来自:,https://python.freelycode.com/contribution/detail/511
英文原文:https://medium.com/@nvdv/cpython-memory-management-479e6cd86c9#.sbvb0py87
3.请列举你知道的Python的魔法方法及用途。
__init__
构造器,当一个实例被创建的时候调用的初始化方法
__new__
__new__ 是在一个对象实例化的时候所调用的第一个方法
它的第一个参数是这个类,其他的参数是用来直接传递给 ####__init__ 方法
__new__ 决定是否要使用该 ####__init__ 方法,因为 ####__new__ 可以调用其他类的构造方法或者直接返回别的实例对象来作为本类的实例,如果 ####__new__ 没有返回实例对象,则 ####__init__ 不会被调用
__new__ 主要是用于继承一个不可变的类型比如一个 tuple 或者 string
__call__
允许一个类的实例像函数一样被调用
__del__
析构器,当一个实例被销毁的时候调用的方法
__len__(self): 定义当被 len() 调用时的行为
__repr__(self): 定义当被 repr() 调用时的行为
__str__(self): 定义当被 str() 调用时的行为
__bytes__(self):定义当被 bytes() 调用时的行为
__hash__(self): 定义当被 hash() 调用时的行为
__bool__(self): 定义当被 bool() 调用时的行为,应该返回 True 或 False
4. 已知以下list:
list1 = [
{
"mm": 2,
},{
"mm": 1,
},{
"mm": 4,
},{
"mm": 3,
},{
"mm": 3,
}
]
4.1 把list1中的元素按mm的值排序。
首先说函数sorted的具体用法:
(1).Python2.x:sorted(iterable, cmp=None, key=None, reverse=False)
,Python3.x:sorted(iterable, /, *, key=None, reverse=False),Python3.x和Python2.x的sorted函数有点不太一样,少了cmp参数。
key接受一个函数,这个函数只接受一个元素,默认为None
reverse是一个布尔值。如果设置为True,列表元素将被倒序排列,默认为False
着重介绍key的作用原理:
key指定一个接收一个参数的函数,这个函数用于从每个元素中提取一个用于比较的关键字。默认值为None 。
(2).sorted() 函数对所有可迭代的对象进行排序操作。
(3).对于 元组类型的列表比如
list2=[('b',4),('a',0),('c',2),('d',3)]
排序的方法是使用lambda然后获取需要排的元素的下标即可。
print(sorted(list2,key=lambda x:x[0]))
而本题有点麻烦 里面是字典类型所以我们需要通过以下方式获取
答案 :
sorted(list1,key=lambda x:x['mm']))
或者用 operator 函数来加快速度, 上面排序等价于
from operator import itemgetter
print(sorted(list1,key=itemgetter('mm')))
4.2 获取list1中第一个mm值等于x的元素。
x=1
for index,item in enumerate(list1):
if x in item.values():
print(list1[index])
break
4.3 删除list1中所有mm等于x的元素,且不对list重新赋值。
x=3
for item in list1[:]:
if x in item.values():
list1.remove(item)
print(list1)
4.4 取出list1中mm最大的元素,不能排序。
max_num=0
for item in list1[:]:
if item['mm']>max_num:
max_num=item['mm']
print(max_num)
5. 以下操作的时间复杂度是多少?
5.1 list.index 时间复杂度:
5.2 dict.get 时间复杂度:
5.3 x in set(…..) 时间复杂度:
首先了解什么是时间复杂度:
时间复杂度是指执行算法所需要的计算工作量
如果一个算法的执行次数是 T(n),那么只保留最高次项,同时忽略最高项的系数后得到函数 f(n),此时算法的时间复杂度就是 O(f(n))。
大概是这个意思,取n的最大次幂,去除低级次幂和常数以及系数项
简单的理解的话比如for循环,对于一个循环,假设循环体的时间复杂度为 O(n)
for i in range(1,1000):
print(i)
2个循环就是 O(n^2)
for i in range(1,1000):
for j in rang(1,1000):
print(i*j)
依次类推
再举一个例子
n = 64
while n > 1:
print(n)
n = n // 2
这个 n = n // 2,每次循环之后都会减半,时间复杂度为O(log2n),而常数项往往可以省略所以这个时间复杂度是O(logn)。
常见python内置方法的时间复杂度参考:https://www.cnblogs.com/harvey888/p/6659061.html
5.1 list.index 时间复杂度:
列表是以数组(Array)实现的。最大的开销发生在超过当前分配大小的增长,这种情况下所有元素都需要移动;或者是在起始位置附近插入或者删除元素,这种情况下所有在该位置后面的元素都需要移动。
点击这里查看列表的内部实现原理http://python.jobbole.com/82549/
答案:
O(1)
5.2 dict.get 时间复杂度:
首先先看dict的内部实现原理:
http://python.jobbole.com/85040/
答案:
平均复杂度:O(1) 最坏复杂度:O(n)
5.3 x in set(…..) 时间复杂度:
答案:
平均复杂度:O(1) 最坏复杂度:O(n)
6. 解释以下输出的原因:
In [1]: '{:0.2f}'.format(0.135)
Out[1]: '0.14'
In [2]: '{:0.2f}'.format(0.145)
Out[2]: '0.14'
答案:
官方文档:6.1. string - Common string operations - Python 3.4.8 documentation
https://docs.python.org/3.4/library/string.html
涉及知识点:Fixed Point 定点数表示法然后看看这两个数的定点数表示法
3.145:3.1450000000000000177635683940
3.135:3.1349999999999997868371792719699442386627197265625
所以就是一个简单的四舍五入:
3.1349显然舍了4
3.1450显然入了5
参考链接:https://www.zhihu.com/question/270543447/answer/355068323
7 简述代码跑出以下异常的原因是什么:
IndexError 序列中没有此索引(index)
AttributeError 对象没有这个属性
AssertionError 断言语句失败
NotImplementedError 尚未实现的方法
StopIteration 迭代器没有更多的值
TypeError 对类型无效的操作
IndentationError 缩进错误
8. 简述你对GIL的理解
GIL的全称是Global Interpreter Lock(全局解释器锁),来源是python设计之初的考虑,为了数据安全所做的决定。
每个CPU在同一时间只能执行一个线程
在单核CPU下的多线程其实都只是并发,不是并行,并发和并行从宏观上来讲都是同时处理多路请求的概念。
但并发和并行又有区别,并行是指两个或者多个事件在同一时刻发生;而并发是指两个或多个事件在同一时间间隔内发生。
在Python多线程下,每个线程的执行方式:
1、获取GIL
2、执行代码直到sleep或者是python虚拟机将其挂起。
3、释放GIL
可见,某个线程想要执行,必须先拿到GIL,我们可以把GIL看作是“通行证”,并且在一个python进程中,GIL只有一个。
拿不到通行证的线程,就不允许进入CPU执行。
在Python2.x里,GIL的释放逻辑是当前线程遇见IO操作或者ticks计数达到100(ticks可以看作是Python自身的一个计数器,
专门做用于GIL,每次释放后归零,这个计数可以通过 sys.setcheckinterval 来调整),进行释放。
而每次释放GIL锁,线程进行锁竞争、切换线程,会消耗资源。并且由于GIL锁存在,
python里一个进程永远只能同时执行一个线程(拿到GIL的线程才能执行)。
IO密集型代码(文件处理、网络爬虫等),多线程能够有效提升效率(单线程下有IO操作会进行IO等待,
造成不必要的时间浪费,而开启多线程能在线程A等待时,自动切换到线程B,
可以不浪费CPU的资源,从而能提升程序执行效率),所以多线程对IO密集型代码比较友好。
更多参考资料:
http://cenalulu.github.io/python/gil-in-python/
9.简述以下内置函数的用法
reduce
map
all
any
答案:
reduce:
在Python 3里,reduce()函数已经被从全局名字空间里移除了,它现在被放置在fucntools模块里
用的话要 先引入
from functools import reduce
reduce的用法
reduce(function, sequence[, initial]) -> value
from functools import reduce
reduce(lambda x,y: x+y, [1, 2, 3])
输出 6
reduce(lambda x, y: x+y, [1,2,3], 9)
输出 15
reduce(lambda x,y: x+y, [1, 2, 3], 7)
输出 13
map:
map()是 Python 内置的高阶函数,它接收一个函数 f 和一个 list,并通过把函数 f 依次作用在 list 的每个元素上,得到一个新的 list 并返回。
例如,对于list [1, 2, 3, 4, 5, 6, 7, 8, 9]
如果希望把list的每个元素都作平方,就可以用map()函数:
因此,我们只需要传入函数f(x)=x*x,就可以利用map()函数完成这个计算:
def f(x):
return x*x
print map(f, [1, 2, 3, 4, 5, 6, 7, 8, 9])
输出结果:
[1, 4, 9, 10, 25, 36, 49, 64, 81]
注意:map()函数不改变原有的 list,而是返回一个新的 list。
all:
all(x)如果all(x)参数x对象的所有元素不为0、''、False或者x为空对象,则返回True,否则返回False
all([0, 1,2, 3]) #列表list,存在一个为0的元素 输出Flase
all(('a', 'b', '', 'd')) #元组tuple,存在一个为空的元素 输出Flase
all(('', '', '', '')) #元组tuple,全部为空的元素 输出Flase
all([]) # 空列表 输出True
all(()) # 空元组 输出True
all('') # 空字串 输出True
注意:空元组、空列表,空字串返回值为True,这里要特别注意
any:
any(x)判断x对象是否为空对象,如果都为空、0、false,则返回false,如果不都为空、0、false,则返回true
any('123')
输出True
any([0,1])
输出True
any([0,'0',''])
输出True
any([0,''])
输出False
any([0,'','false'])
输出True
any([0,'',bool('false')])
输出True
any([0,'',False])
输出False
any(('a','b','c'))
输出True
any(('a','b',''))
输出True
any((0,False,''))
输出False
any([])
输出False
any(())
输出False
10.copy和deepcopy的区别是什么?
—–我们寻常意义的复制就是深复制,即将被复制对象完全再复制一遍作为独立的新个体单独存在。所以改变原有被复制对象不会对已经复制出来的新对象产生影响。
—–而浅复制并不会产生一个独立的对象单独存在,他只是将原有的数据块打上一个新标签,所以当其中一个标签被改变的时候,数据块就会发生变化,另一个标签也会随之改变。这就和我们寻常意义上的复制有所不同了。
对于简单的 object,用 shallow copy 和 deep copy 没区别
复杂的 object, 如 list 中套着 list 的情况,shallow copy 中的 子list,并未从原 object 真的「独立」出来。也就是说,如果你改变原 object 的子 list 中的一个元素,你的 copy 就会跟着一起变。这跟我们直觉上对「复制」的理解不同。
代码解释
>>> import copy
>>> origin = [1, 2, [3, 4]]
#origin 里边有三个元素:1, 2,[3, 4]
>>> cop1 = copy.copy(origin)
>>> cop2 = copy.deepcopy(origin)
>>> cop1 == cop2
True
>>> cop1 is cop2
False
#cop1 和 cop2 看上去相同,但已不再是同一个object
>>> origin[2][0] = "hey!"
>>> origin
[1, 2, ['hey!', 4]]
>>> cop1
[1, 2, ['hey!', 4]]
>>> cop2
[1, 2, [3, 4]]
#把origin内的子list [3, 4] 改掉了一个元素,观察 cop1 和 cop2
该部分内容来自:https://blog.csdn.net/qq_32907349/article/details/52190796
11. 简述多线程、多进程、协程之间的区别与联系。
概念:
进程:
进程是具有一定独立功能的程序关于某个数据集合上的一次运行活动,
进程是系统进行资源分配和调度的一个独立单位。每个进程都有自己的独立内存空间,
不同进程通过进程间通信来通信。由于进程比较重量,占据独立的内存,
所以上下文进程间的切换开销(栈、寄存器、虚拟内存、文件句柄等)比较大,但相对比较稳定安全。
线程:
线程是进程的一个实体,是CPU调度和分派的基本单位,
它是比进程更小的能独立运行的基本单位.
线程自己基本上不拥有系统资源,只拥有一点在运行中必不可少的资源(如程序计数器,一组寄存器和栈),
但是它可与同属一个进程的其他的线程共享进程所拥有的全部资源。
线程间通信主要通过共享内存,上下文切换很快,资源开销较少,但相比进程不够稳定容易丢失数据。
协程:
协程是一种用户态的轻量级线程,协程的调度完全由用户控制。
协程拥有自己的寄存器上下文和栈。
协程调度切换时,将寄存器上下文和栈保存到其他地方,在切回来的时候,恢复先前保存的寄存器上下文和栈,
直接操作栈则基本没有内核切换的开销,可以不加锁的访问全局变量,所以上下文的切换非常快。
区别:
进程与线程比较:
线程是指进程内的一个执行单元,也是进程内的可调度实体。线程与进程的区别:
1) 地址空间:线程是进程内的一个执行单元,进程内至少有一个线程,它们共享进程的地址空间,
而进程有自己独立的地址空间
2) 资源拥有:进程是资源分配和拥有的单位,同一个进程内的线程共享进程的资源
3) 线程是处理器调度的基本单位,但进程不是
4) 二者均可并发执行
5) 每个独立的线程有一个程序运行的入口、顺序执行序列和程序的出口,
但是线程不能够独立执行,必须依存在应用程序中,由应用程序提供多个线程执行控制
协程与线程进行比较:
1) 一个线程可以多个协程,一个进程也可以单独拥有多个协程,这样python中则能使用多核CPU。
2) 线程进程都是同步机制,而协程则是异步
3) 协程能保留上一次调用时的状态,每次过程重入时,就相当于进入上一次调用的状态
12. 代码中经常遇到的*args, **kwargs含义及用法。
在函数定义中使用args和*kwargs传递可变长参数
*args用来将参数打包成tuple给函数体调用
**kwargs 打包关键字参数成dict给函数体调用
13. 列举一些你知道的HTTP Header 及其功能。
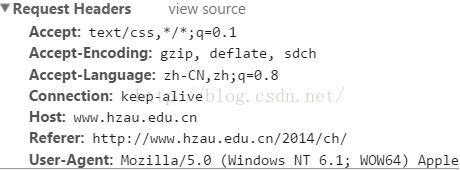
Accept
作用: 浏览器端可以接受的媒体类型,
例如: Accept: text/html 代表浏览器可以接受服务器回发的类型为 text/html 也就是我们常说的html文档,
如果服务器无法返回text/html类型的数据,服务器应该返回一个406错误(non acceptable)
通配符 * 代表任意类型
例如 Accept: / 代表浏览器可以处理所有类型,(一般浏览器发给服务器都是发这个)
Accept-Encoding:
作用: 浏览器申明自己接收的编码方法,通常指定压缩方法,是否支持压缩,支持什么压缩方法(gzip,deflate),(注意:这不是只字符编码);
例如: Accept-Encoding: zh-CN,zh;q=0.8
Accept-Language
作用: 浏览器申明自己接收的语言。
语言跟字符集的区别:中文是语言,中文有多种字符集,比如big5,gb2312,gbk等等;
例如: Accept-Language: en-us
Connection
例如: Connection: keep-alive 当一个网页打开完成后,客户端和服务器之间用于传输HTTP数据的TCP连接不会关闭,如果客户端再次访问这个服务器上的网页,会继续使用这一条已经建立的连接
例如: Connection: close 代表一个Request完成后,客户端和服务器之间用于传输HTTP数据的TCP连接会关闭, 当客户端再次发送Request,需要重新建立TCP连接。
Host(发送请求时,该报头域是必需的)
作用: 请求报头域主要用于指定被请求资源的Internet主机和端口号,它通常从HTTP URL中提取出来的
例如: 我们在浏览器中输入:http://www.hzau.edu.cn
浏览器发送的请求消息中,就会包含Host请求报头域,如下:
Host:www.hzau.edu.cn
此处使用缺省端口号80,若指定了端口号,则变成:Host:指定端口号
Referer
当浏览器向web服务器发送请求的时候,一般会带上Referer,告诉服务器我是从哪个页面链接过来的,服务器籍此可以获得一些信息用于处理。比如从我主页上链接到一个朋友那里,他的服务器就能够从HTTP Referer中统计出每天有多少用户点击我主页上的链接访问他的网站。可用于防盗链
User-Agent
作用:告诉HTTP服务器, 客户端使用的操作系统和浏览器的名称和版本.
我们上网登陆论坛的时候,往往会看到一些欢迎信息,其中列出了你的操作系统的名称和版本,你所使用的浏览器的名称和版本,这往往让很多人感到很神奇,实际上,服务器应用程序就是从User-Agent这个请求报头域中获取到这些信息User-Agent请求报头域允许客户端将它的操作系统、浏览器和其它属性告诉服务器。
例如: User-Agent: Mozilla/4.0 (compatible; MSIE 8.0; Windows NT 5.1; Trident/4.0; CIBA; .NET CLR 2.0.50727; .NET CLR 3.0.4506.2152; .NET CLR 3.5.30729; .NET4.0C; InfoPath.2; .NET4.0E)
更多参考资料:https://blog.csdn.net/u014175572/article/details/54861813
14 简述Cookie和Session的区别与联系。
cookie数据存放在客户的浏览器上,session数据放在服务器上
cookie不是很安全,别人可以分析存放在本地的COOKIE并进行COOKIE欺骗考虑到安全应当使用session。
session会在一定时间内保存在服务器上。当访问增多,会比较占用服务器的性能考虑到减轻服务器性能方面,应当使用COOKIE。
单个cookie保存的数据不能超过4K,很多浏览器都限制一个站点最多保存20个cookie。
建议:
将登陆信息等重要信息存放为SESSION
其他信息如果需要保留,可以放在COOKIE中
15. 简述什么是浏览器的同源策略。
同源策略是浏览器上为安全性考虑实施的非常重要的安全策略。
何谓同源:
URL由协议、域名、端口和路径组成,如果两个URL的协议、域名和端口相同,则表示他们同源。
同源策略:
浏览器的同源策略,限制了来自不同源的"document"或脚本,对当前"document"读取或设置某些属性。
从一个域上加载的脚本不允许访问另外一个域的文档属性。
举个例子:
比如一个恶意网站的页面通过iframe嵌入了银行的登录页面(二者不同源),如果没有同源限制,恶意网页上的javascript脚本就可以在用户登录银行的时候获取用户名和密码。
在浏览器中