前端渲染PDF文件成图带来的思考:什么是缓冲区Buffer、类型化数组TypedArray以及大型二进制对象Blob
起因
事情是这样的:从产品那里接到需求,要把pdf文件在移动端展示并保存在手机相册里。保存到手机相册中,那就要把pdf文件变成图片。网上搜索一下,Mozilla的pdf.js库刚好可以。于是开始看官方文档,但文档是都是由源代码的注释生成的,也就看到一部分源代码。pdf.js源码里有一个重要的方法getDocument,在这个方法上的注释写到:
@param{string|TypedArray|DocumentInitParameters|PDFDataRangeTransport} src Can be a url to where a PDF is located, a typed array (Uint8Array)
already populated with data or parameter object.
可以是URL也可以是Uint8Array?Uint8Array是什么?正是这里的Uint8Array才有接下来关于Uint8Array(TypedArray)的一系列知识点的学习。
历史
JavaScript在设计时只是简单运行于网页的脚本语言,远没有预想到会发展到今时今日的地步。起初JavaScript在业务场景中不会处理到复杂的数据和交互逻辑,但随着互联网的发展,网页已经不仅仅局限简单的文字图片展示等基础功能,逐步需要囊括视频播放、音频播放、在线绘画等功能。在此业务场景下,JavaScript亟需更多能力以处理音视频等二进制数据。但JavaScript的基本类型Boolean、Function、String…等都无法处理音视频等二进制数据(早期由Flash插件代为处理),也不存在某个对象拥有处理二进制流数据的能力。随着时间推移,Node的出现让JavaScript第一次能够处理文件(二进制流数据)的能力——Buffer。但Node依旧只能让运行在server端的JavaScript具有处理二进制数据的能力,client端依旧无法处理二进制数据。直到2015年的新规范ES2015(ES6)中,才定义了具有处理二进制数据能力的对象TypedArray。先来看看早于TypedArray出现的Buffer是什么:
Buffer
在Node文档中描写Buffer道:
在引入TypedArray之前,JavaScript并没有读取或者操作流或二进制数据数据的机制。而Buffer正是因此被引入Node.js API中,使得JavaScript能够介入TCP字节流、文件操作系统和其他场景并能处理其中的内容。随着TypedArray的普及,Buffer的地位变成更优化和更适合的Node端Uint8Array类型的TypedArray实现。
显然Buffer是为在HTTP和文件系统的场景下给予JavaScript处理数据的能力而诞生的,并且概念上Buffer属于TypedArray。那么Buffer是如何读取和操作数据内容的呢?
Buffer提供以下几个API:
- 创建缓存区:Buffer.from、Buffer.alloc;(废弃
new Buffer()确保新建的 Buffer 实例的内容不会包含敏感数据) - Buffer.concat像数组似的链接两个Buffer;
- Buffer.compare对比两个缓存区。
下面是关于Node中转文件的简单例子:
?Node文件中转-Buffer
async function nodeBuffer(){
let query = ctx.request.query;
let downloadPath = query.path;
let instance = axios.create({
headers: {
'content-type': 'application/octet-stream'
},
})
delete query.path;
await instance.get(downloadPath, query)
.then(res => {
ctx.attachment(query.name)
ctx.set('Encoding','binary'); \
ctx.set('Content-Type', 'application/octet-stream');
ctx.set("content-disposition", `attachment;filename=${query.name}`);
ctx.body = Buffer.from(res.data, 'binary');
ctx.status = 200;
})
.catch(res => {
console.log("catch:", res)
})
}
TypedArray
ES6规范尚未出世前,Buffer仅仅是server端的一种实现。而TypedArray才是JavaScript语言真正的‘Buffer’。在MDN文档中描述TypedArray道:
TypedArray是描述底层二进制数据缓存的一种类似数组的视图。在全局环境下并没有叫做TypedArray的对象,也没有叫做TypedArray的构造函数。相反,全局环境下有许多不同的对象,他们的value正是由针对特定类型的类型化数组构造函数所创建的。在接下来的描述中,你会发现有一些属性、方法在任何类型上都能使用。
从上述文字不难发现以下两点:
- TypedArray对象无法在全局环境中获取,应理解为全局环境下存在几种不同的TypedArray实例;
- TypedArray是在表现上一种类似数组的存在,并是用于描述二进制数据缓存区的内容的视图。
TypedArray有多种实现,但不存在基类?听上去总有点不可能,继续翻阅MDN文档关于TypedArray的内容在一段描述中道:
当创建一个TypedArray实例(例如:Int8Array)时,一个数组缓冲区将被创建在内存中,如果ArrayBuffer对象被当作参数传给构造函数将使用传入的ArrayBuffer代替。缓冲区的地址被存储在实例的内部属性中,所有的%TypedArray%.prototype上的方法例如set value和get value等都会操作在数组缓冲区上。
从描述中能知道全局环境中并不是不存在TypedArray,而是TypedArray被设置为无法通过JavaScript直接访问。如果TypedArray只是视图,那真正存储数据的究竟是什么?在MDN文档上关于ArrayBuffer的定义描述道:
ArrayBuffer对象被用以表示通用的固定长度的原始二进制数据缓存区。你不能直接操作一个ArrayBuffer的内容。你应该创建一个类型化数组或是DataView对象,类型化数组和DataView会将缓冲区中的数据格式化为特定格式,来读取和写入Buffer的内容。
答案已经不言而喻,TypedArray只是用以操作ArrayBuffer的对象或者说视图,而拥有二进制数据的则是ArrayBuffer。到这里相信关于TypedArray、ArrayBuffer、Buffer的概念和关系已经有基本雏形,他们的关系总结如下图所示:
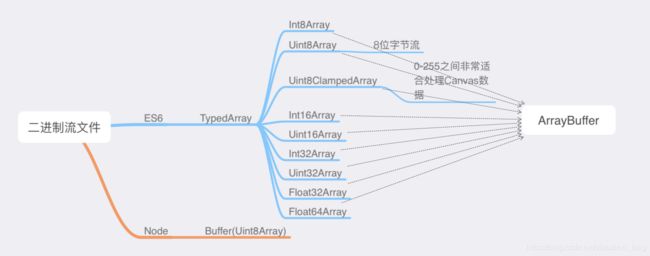
上图九种TypedArray中最常见和常用的是Uint8Array类型,正好由无符号的八位二进制数表示一个字节。下例是关于Uinit8Array与base64字符串的相互转换:
StringToTypedArray?
function StringToTypedArray(str){
let len = str.length;
let ab = new Uint8Array(len);
for(let i =0 ;i < len ;i++){
ab[i] = str.charCodeAt(i);
}
//返回buffer的引用,buffer为只读属性
return ab.buffer
}
TypedArrayToString?
function TypedArrayToString(buffer){
let ab = Uint8Array.from(buffer);
let res = '';
for(let i = 0; i<ab.length; i++){
//fromCharCode通过一串Unicode创建字符串
res += String.fromCharCode(ab[i])
}
return res
}
上述两例的成功转换基于String都是相同的编码类型(UTF-8、UTF-16等)。
More:JavaScript能从canvas.toDataURL()、FileReader.readAsDataURL()、window.btoa()等方法获取到base64字符串;通过FileReader.readAsArrayBuffer()和XHR请求设置XHR属性ResponseType为ArrayBuffer等方法获取到ArrayBuffer类型数据。
实际运用于pdf.js?
pdf.js的getDocument方法明确指出接受两种类型的参数:一是URL并且返回文件流,二是TypedArray(Uint8Array)类型数据。这时假如后端的有个接口(URL:’/somepath/to/file’),接口在成功时返回二进制文件流在失败时返回json字符串,如下:
//成功
...Binary Data
//失败
{
errno:10004,
error:'错误信息'
}
那对于渲染pdf文件可以这样做:
ajax.get({
url: '/somepath/to/file',
data:{
//...some data
},
responseType: 'arraybuffer',
success:(res)=>{
pdf.getDocument(res)
.then()
.catch()
},
error:(err)=>{
toast(err.error)
}
})
在后端兼容’arraybuffer’类型的返回值时(通常是兼容的),我们将直接得到二进制数据的ArrayBuffer类型作为返回,不再需要从字符串转为ArrayBuffer。值得注意的是失败时也会返回ArrayBuffer类型,此处笔者与后端约定此接口失败时将置HTTPCODE为403,这样不需要再将ArrayBuffer转换为对象来判断接口请求成功与否。
Blob
在HTML5中,关于web应用对于文件的操作引入相应的API,包括使用type=file的元素和FileReader API。MDN中描述FileReader道:
FileReader对象允许Web程序异步读取用户计算机上的文件或缓冲区内容,FileReader操作的对象是Blob以及继承于Blob的File对象。
其中Blob全称是Binary Large Object:二进制类型的大对象。显然Blob也是关于操作二进制数据的对象,MDN中描述道:
Blob 对象表示一个不可变、原始数据的类文件对象。Blob 表示的不一定是JavaScript原生格式的数据。File 接口基于Blob,继承Blob的功能并将其扩展使其支持用户系统上的文件。
从上述内容中我们能知道以下四点:
- 不可变(immutable);
- 原始数据(raw data);
- 数据不需要是JavaScript原生格式;
- File继承于Blob。
Blob只能通过构造函数生成,语法为new Blob(array , options)。其中array是由ArrayBuffer、ArrayBufferView(TypedArray和DataView)、Blob、DOMString等对象构成的数组。options包括type和endings,type表示文件的MIME类型,endings代表结束符\n如何被写入。显然Blob与TypedArray等关系如下图所示:
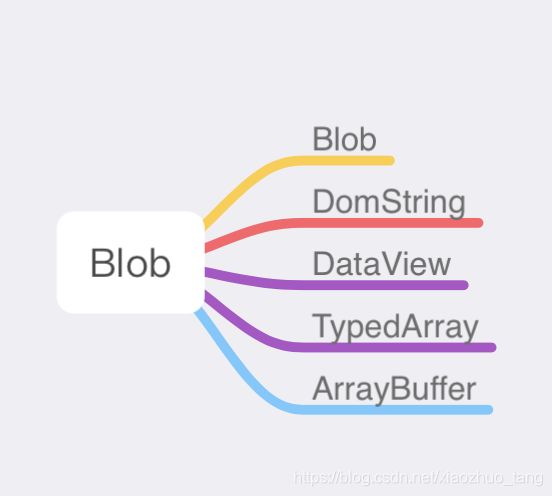
Blob对象包含两个只读属性(size和type)以及一个方法slice([start,[end,[contentType]]])。十分符合Blob的定义,不可变的原始数据的类文件对象。其中由Blob所延伸出的的Blob URL在实际场景中常会用到。
Blob URL: Blob URLs是W3C的官方名称,在实际使用时常称为Object-URLs。Blob URLs只能通过URL.createObjectURL方法暂时生成在浏览器中,此方法将生成一个指向于Blob和File的对象的URL,并能通过URL.revokeObjectURL方法释放,在页面关闭时被销毁掉并只存在于当前session中。
对比Data URLs: Blob URLs只是暂时的协议允许Blob和File对象能够利用URL以资源的形式被使用在图片(img标签)、二进制数据下载链接等,而不需通过上传文件到server端后返回URL资源。而Data URLs定义为data:[,在JavaScript中为二进制数据需要编码为Base64字符串,而一个字符需要占用两字节,使得原始纯二进制数据的Blob URLs相比于Data URLs更小更快。
解决的问题: 在面对需要保存canvas为图片的需求中,可以通过canvas.toDataURL方法转数据为base64编码并用以下载和展示。但在面对长图时,过长的base64编码将消耗过多的内存,并且由于客户端能力不尽相同使得在客户端有内存溢出风险甚至引起浏览器崩溃。但canvas同时可以使用canvas.toBlob方法获得原始二进制数据的Blob对象,并通过URL.createObjectURL方法获取暂时的URL资源,相比于base64消耗更低的内存风险也更小。
下面是关于生成Blob URLs并下载的简单示例?:
canvas.toBlob((blob)=>{
let url = URL.createObjectURL(blob);
let a = documen.createElement('a');
a.href = url;
a.download = 'test.test';
document.body.appendChild();
a.click();
},'image/png',1);
下面是通过FileReader读取Blob的简单示例?:
canvas.toBlob((blob)=>{
let fr = new FileReader();
fr.addEventListener('load' , (event) => {
//dosomething to event.target.result
})
// readAsArrayBuffer、readAsBinaryString、readAsText
fr.readAsDataURL(blob);
},'image/png',1);
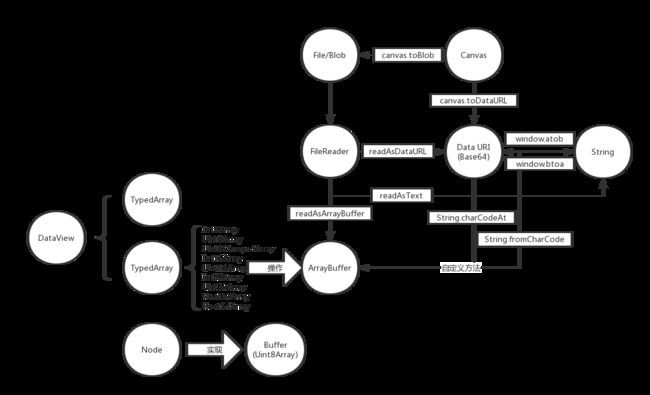
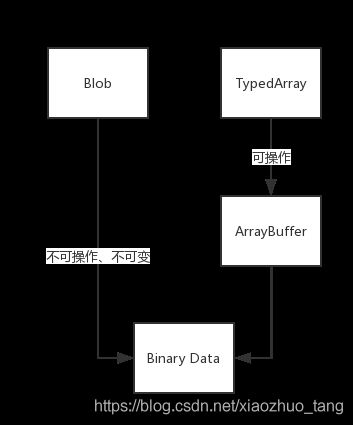
总结图
参考
- 关于ArrayBuffer-MDN以及ArrayBuffer-ECMAScript6入门
- 关于XMLHttpRequest.ResponseType
- 关于Blob
- 关于TypedArray
- 关于DateView