Editing Conditional Radiance Fields
Editing Conditional Radiance Fields
Abstract
神经辐射场(NeRF)是一种支持高质量视图合成的场景模型,对每个场景进行优化。在本文中,我们探索了允许用户编辑一个类别级的NeRF category-level NeRF-也被称为条件辐射场-训练在一个形状类别上。具体地说,我们介绍了一种将粗糙的二维用户涂鸦传播到三维空间的方法,以修改局部区域的颜色或形状。首先,我们提出了一个条件辐射场,它包含了新的模块化网络组件,包括一个跨对象实例共享的形状分支。观察同一类别的多个实例,我们的模型在没有任何监督的情况下学习底层的部分语义,从而允许将粗糙的2D用户涂鸦传播到整个3D区域(例如,椅子座椅)。接下来,我们提出了一种针对特定网络组件的混合网络更新策略,以平衡效率和准确性。在用户交互过程中,我们提出了一个既满足用户约束条件,又保留原始对象结构的优化问题。我们在三个形状数据集上的各种编辑任务上演示了我们的方法,并表明了它优于之前的神经编辑方法。最后,我们编辑一个真实照片的外观和形状,并表明编辑传播到外推的新视图。
3. Editing a Conditional Radiance Field
我们的目标是允许用户编辑一个3D场景的连续体积表示。在本节中,我们首先描述一种新的神经网络架构,它可以更准确地捕获对象类的形状和外观。然后,我们描述了我们如何更新网络权值,以实现颜色和形状编辑效果。
虽然NeRF表示可以渲染一个特定场景的新视图,但我们寻求启用对整个形状类的编辑,例如,“椅子”。为此,我们学习了一个条件辐射场模型,它扩展了在形状和外观上的潜在向量的NeRF表示。该表示法是在属于一个类的一组形状上进行训练的,每个形状实例都由潜在的形状和外观向量表示。形状和外观的分离使我们可以在编辑过程中修改网络的某些部分。


3.1. Network with Shared Branch
我们发现结构设计选择很重要,目标是模块化模型,为形状和颜色分离提供归纳偏差。这些设计选择允许在用户编辑过程中对选定的子模块进行细化(下一节将进一步讨论),从而实现更高效的下游编辑。我们在图2中说明我们的网络架构F。

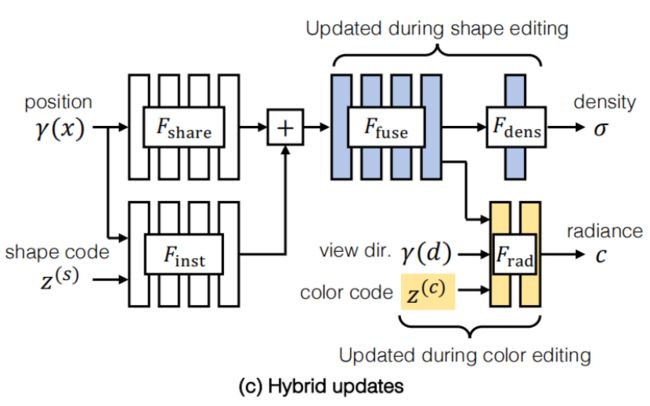
3.2.通过模块化的网络更新进行编辑

我们感兴趣的是编辑一个由条件辐射场编码的实例。给定具有形状z(s)(c)和颜色z(c)(c)编码的网络F的渲染,我们希望修改给定用户编辑的一组射线的实例。我们希望在网络参数和学习到的代码上优化一个损失的Ledit(F,z(s)k,z(c)k)。
我们的第一个目标是准确地进行编辑——编辑后的辐射字段应该呈现反映用户所需更改的实例视图。我们的第二个目标是有效地进行编辑。编辑一个辐射字段是很耗时的,因为修改权重需要几十个前向和向后调用。相反,用户应该收到关于他们的编辑的交互式反馈。为了实现这两个目标,我们考虑了以下策略来选择在编辑过程中要更新的参数。
更新形状和颜色代码。解决这个问题的一种方法是只更新实例的潜在代码,如图2(a).所示虽然优化这样少的参数可以导致相对有效的编辑,但正如我们将展示的,这种方法会导致低质量的编辑。
更新整个网络。另一种方法是更新网络的所有权值,如图2(b).所示正如我们将展示的,这种方法很慢,可能导致实例的未编辑区域发生不必要的更改。
混合更新。我们提出的解决方案,如图2(c)所示,通过更新网络的特定层,实现了准确性和效率。为了减少计算量,我们只微调了网络的后几层。这些选择通过只计算后期层的梯度而不是整个网络来加快优化。在编辑颜色时,我们只更新网络中的Frad和z(c),这比优化整个网络的优化时间减少了3.7⇥(从972秒减少到260秒)。在编辑形状时,我们只更新Ffuse和Fdens,这将优化时间减少了3.2⇥(从1081秒减少到342秒)。为了进一步减少计算,我们在编辑过程中采取了两个步骤。
Subsampling user constraints子采样用户约束。在训练过程中,我们采样了用户指定的光线的一个小子集。我们发现,随着问题的规模变小,这种选择允许优化收敛得更快。为了编辑颜色,我们随机抽取64条射线,为了编辑形状,我们随机抽取8,192条射线的子集。通过这种方法,我们获得了24⇥的颜色编辑加速和2.9⇥的形状编辑加速。此外,我们发现子采样用户约束保持了编辑质量。
特征缓存。NeRF渲染可能会很慢,特别是当渲染的视图是高分辨率时。为了在颜色编辑期间优化视图渲染,我们缓存在编辑期间不变的网络输出。因为我们只在颜色编辑期间优化Frad,所以在编辑期间对Frad的输入没有变化。因此,我们缓存显示给用户的每个视图的输入特性,以避免不必要的计算。这种优化将256⇥256图像的渲染时间减少了7.8⇥(从6.2秒减少到0.8秒以下)
3.3. Color Editing Loss
在本节中,我们将描述如何使用条件辐射场表示来执行颜色编辑。要编辑形状实例部件的颜色,用户将选择所需的颜色,并在渲染视图上草绘制前景掩模,以指示应该应用该颜色的位置。用户也可以选择一个颜色应该保持不变的背景掩模。这些面具不需要详细;相反,每个面具有一些粗糙的涂鸦。用户通过用户界面提供这些输入。给定所需的目标颜色和前景/背景掩模,我们试图更新对象实例的神经网络F和潜在的颜色向量z(c),以尊重用户的约束。



3.4. Shape Editing Loss
对于编辑形状,我们描述了两种操作-形状零件去除和形状零件添加
Shape part removal.为了删除形状部分,用户通过用户界面在渲染视图中涂鸦所需的删除区域。我们将视图的潦草区域作为前景掩模,并将视图的非潦草区域作为背景掩模。为了构建编辑示例,我们将与前景掩模相对应的区域变白
给定编辑示例,我们优化了一个基于密度的损失,以鼓励推断的密度是稀疏的。设σr是沿着像素位置的射线r采样点的推断密度值的向量,设yf是整个用户涂鸦的前景光线集。

其中,我们将所有的密度向量标准化为单位长度。惩罚沿每条射线的熵会鼓励推断的密度稀疏,导致模型预测移除区域的零密度

Shape part addition.为了将局部部分添加到形状实例中,我们将网络匹配到一个复合图像中,该图像包含粘贴到原始对象中的新对象的区域。为了实现这一点,用户首先选择一个原始的渲染视图来进行编辑。我们的界面在相同的视点下显示不同的实例,用户可以选择一个新的复制实例。然后,用户通过在选定的视图上涂鸦来复制新实例中的一个本地区域。最后,用户在原始视图中涂鸦,以选择所需的粘贴位置。对于修改视图中粘贴位置的射线,我们使用新实例的形状代码和原始实例的颜色代码来渲染其颜色。我们将复合视图的修改区域表示为前景区域,将未修改区域表示为背景区域。

5. Discussion
我们介绍了一种从三维对象集合中学习条件辐射场的方法。此外,我们还展示了如何使用我们学习到的解纠缠表示来执行直观的编辑操作。我们的方法的一个限制是形状编辑的交互性。目前,用户需要一分钟多的时间才能获得关于其形状编辑的反馈。编辑操作的大部分计算都用在渲染视图上,而不是编辑本身。我们乐观地认为,NeRF渲染时间的改进将有助于[46,75]。另一个限制是,我们的方法不能重建与其他类实例非常不同的新对象实例。尽管有这些限制,但我们的方法为探索其他高级编辑操作开辟了新的途径,例如重新设置和更改动画对象的物理属性。