【云开发】在 React Native 中使用 AWS Textract 实现文本提取
⭐️ 本文首发自 前端修罗场(点击加入),一个专注 Web 技术、答疑解惑、面试辅导、职业发展的社区。
现在加入,即可参与打卡挑战,和一群人一起努力。挑战成功即可获取一次免费的模拟面试机会,进而评估知识点的掌握程度,获得更全面的学习指导意见,不走弯路,不吃亏!
Amazon Textract 是 Amazon 推出的一项机器学习服务,可将扫描文档、PDF 和图像中的文本、手写文字提取到文本文档中,然后可以将其存储在任何类型的存储服务中,例如 DynamoDB、s3 等。
今天我将介绍从 React Native 移动应用程序中捕获或选择图像并将这些图像上传到 S3 的过程,然后一旦我们使用 API Gateway 触发 lambda 函数,就会从这些图像中提取数据,然后在处理完数据后我们 会将这些数据作为 DynamoDB 记录插入。大致的过程如下图所示:
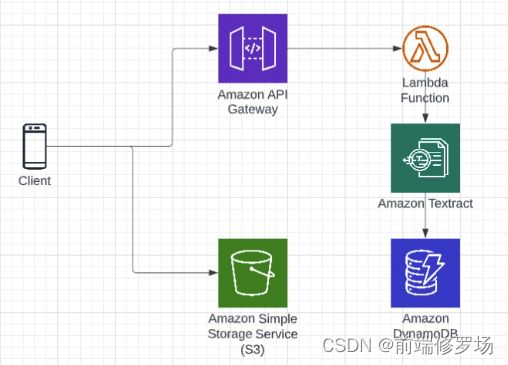
在开始实战前,我假设你对AWS 的 lambda 函数 和 API Gateway 已经了解了。同时,请准备好如下实战环境:
- npm or yarn
- react-native > 0.59
- aws-amplify
- nodejs
- aws-sdk
我会将内容分为 2 部分来讲解:
- 前端
- 后端
前端
在本节中,我们将处理我们在移动应用程序中捕获的图像,并将图像上传到 S3 中,以便我们的后端从这些图像中提取数据。首先,我们将从安装开始:
-
安装
aws-amplify,它会用在 React Native 中。 在命令行中执行如下命令:
npm install aws-amplify
或使用npm install @aws-amplify/api @aws-amplify/core @aws-amplify/storage因为我们不需要所有的 aws-amplify 库。 -
安装
react-native-image-picker: 它能从设备库或相机中选择照片。 执行如下命令:
npm install react-native-image-picker
接下来,我们将从实现两个函数开始,一个是用户从库中选择图像,一个是从相机中选择图像:
import {launchCamera, launchImageLibrary} from 'react-native-image-picker';
const options = {
mediaType: 'photo',
quality: 0.5,
includeBase64: true,
};
// 从库中选择图像
const libraryPickerHandler = () => {
launchImageLibrary(options, async (response) => {
if (response.didCancel) {
console.log('用户取消了图像选择');
} else if (response.errorMessage) {
console.log('ImagePicker Error: ', response.errorMessage);
} else {
await onImageSelect(response?.assets[0].uri);
}
});
};
// 从相机中提取图像
const cameraPickerHandler = async () => {
launchCamera(options, async (response) => {
if (response.didCancel) {
console.log('用户取消了图像选择');
} else if (response.errorMessage) {
console.log('ImagePicker Error: ', response.errorMessage);
} else {
await onImageSelect(response?.assets[0].uri);
}
});
};
onImageSelect 函数将处理图像上传到 S3,并将 S3 密钥发送到我们将在后端部分开发的 API 端点 /textract-scan:
import Storage from '@aws-amplify/storage';
import API from '@aws-amplify/api';
// or
import { Storage, API } from 'aws-amplify';
const onImageSelect = async (uri: string) => {
let imageResponse = await fetch(uri);
const blob = await imageResponse.blob();
// timestamp for random image names
let naming = `{new Date().getTime()}.jpeg`;
const s3Response = await Storage.put(naming, blob, {
contentType: 'image/jpeg',
level: 'protected',
});
await API.post('your-endpoint-name', '/main/textract-scan', {
body: {
imageKey: s3Response.key,
},
});
};
目前,前端部分就完成了。接下来,看后端部分。
后端
在本节中,我们将处理从将用 nodejs 编写的图像中提取数据。首先安装如下依赖:
aws-sdk,它使你能够轻松地使用Amazon Web Services。执行如下命令:
npm install aws-sdkoryarn add aws-sdk
我们将创建一个名为 textract.ts 的文件,其中将包含名为 textractScan 的 lambda 函数。textractScan 将是我们的主要函数,它将被前端通过指定的 api 调用。该函数将是一个 post 方法,它将在 body 中获取一个 imageKey 属性。 此 imageKey 表示指定 Bucket 中的 S3 对象键。
你需要将其添加到功能块内的 serverless.yml 文件中:
TextractScanLambda:
handler: path-to-your-file/textract.textractScan
events:
- http:
method: post
path: main/textract-scan
authorizer: aws_iam
现在在 textract.ts 文件中,我们开始实现 lambda 函数。让我们首先编写 Textract 函数来分析我们将在 lambda 函数中使用的 Text:
import { Textract } from 'aws-sdk';
const analyzeText = async(key: string) => {
const payload = {
Document: {
S3Object: {
//the bucket where you uploaded your images
Bucket: 'BUCKET_NAME',
Name: key,
},
},
};
return new Textract().detectDocumentText(payload);
}
现在我们开始编写我们的 lambda 函数 textractScan:
const textractScan = async (event: AWSLambda.APIGatewayProxyEvent) => {
try {
console.log(event);
const body = JSON.parse(event.body);
const { imageKey } = body;
const analyzeTextResult = await analyzeText(imageKey);
} catch (e) {
console.log(e);
return {
statusCode: 500,
body: JSON.stringify({ message: 'ERROR_ANALYZING_DOCUMENT' }),
};
}
};
现在我们完成了该功能,我们可以使用它从图像中提取文本。 analyzeTextResult 中的结果将包含一个对象数组,其中包含在文档中检测到的文本,但是从该对象中提取我们需要的实际数据将非常耗时。
这就是创建 aws-textract-json-parser 的原因,该库将来自 AWS Textract 的 json 响应解析为更可用的格式,然后你可以将其插入 DynamoDB:
import { DynamoDB } from 'aws-sdk';
const textractScan = async (event: AWSLambda.APIGatewayProxyEvent) => {
try {
console.log(event);
const body = JSON.parse(event.body);
const { imageKey } = body;
const analyzeTextResult = await analyzeText(imageKey);
const parsedData = await AWSJsonParser(analyzeTextResult);
console.info(parsedData);
const rawData = parsedData.getRawData();
console.info(data);
if (data.length === 0) {
console.error('no text detected');
return {
statusCode: 400,
body: JSON.stringify({ message: 'INVALID_DOCUMENT' }),
};
}
const payload = {
...someData,
textractData: rawData
}
new DynamoDB.DocumentClient(payload).put;
....
} catch (e) {
console.log(e);
return {
statusCode: 500,
body: JSON.stringify({ message: 'ERROR_ANALYZING_DOCUMENT' }),
};
}
};
现在,你可以实现许多需要用户拍照的场景,并通过简单的步骤提取数据并将其与他的个人资料相关联。