第十二周.直播.DGL-KG, LifeSci讲解
文章目录
- 知识图谱背景
- DGL-KE
- LifeSci
- 双线性系列
-
- RESCAL
-
- 摘要
- 2. Modelling and Notation
- 模型
- DistMult
-
- 摘要
- 模型
- ConvE
-
- 为什么是2D不是1D卷积
- 模型
本文内容整理自深度之眼《GNN核心能力培养计划》
公式输入请参考: 在线Latex公式
DGL有三个比较知名的开源库,DGL-KG, DGL-LifeSci, DGL-Recsys,最后一个还在开发状态,没有发布,今天先来讲前面两个,重点是第一个。
知识图谱背景
之前Trans系列有讲过,这里再啰嗦一下:
知识图谱常用三元组(triples)来表示,例如:(Beijing,Capital City,China)
上例中前后两个元素论文中都称为实体,中间元素称为关系,Beijing是Header,Capital City是Relation,China是Tail。从图的角度来看实体就是结点,关系就是边。
知识图谱常见应用有:
Question answering
Search
Recommender Systems
Natural language understanding
具体看这里
不展开了
DGL-KE
官网:https://dglke.dgl.ai/doc/
KE的意思knowledge graph embeddings.
构架图上可以看到,它支持不同硬件,后端,模型支持: TransE, TransR, RESCAL, DistMult, ComplEx, and RotatE。
LifeSci
https://lifesci.dgl.ai/
这个不是我专业稍微copy一下相关应用:
Molecular property prediction:分子结构预测
Attention visualization:可视化
Generative models:生成模型
Protein-ligand binding affinity prediction:蛋白质序列预测
Reaction prediction:(药效?)反应预测
双线性系列
RESCAL
A Three-Way Model for Collective Learning on Multi-Relational Data
ICML早期的一篇文献,因此部分专有名词的叫法以及思路和现在有所区别。
摘要
想研究啥,啥就很重要
Relational learning is becoming increasingly important in many areas of application.
直接本文做了啥(总)
Here, we present a novel approach to relational learning based on the factorization of a three-way tensor.
本文做了啥(分)
We show that unlike other tensor approaches, our method is able to perform collective learning via the latent components of the model and provide an efficient algorithm to compute the factorization.
实验怎么弄
We substantiate our theoretical considerations regarding the collective learning capabilities of our model by the means of experiments on both a new dataset and a dataset commonly used in entity resolution.
效果怎么样
Furthermore, we show on common benchmark datasets that our approach achieves better or on-par results, if compared to current state-of-the-art relational learning solutions, while it is significantly faster to compute.
2. Modelling and Notation
这里主要是用了一个three-way tensor来表示实体及实体关系:

上图就表示有n个实体,m种关系的three-way tensor(维度为 n × n × m n\times n\times m n×n×m,和普通的三元组表示顺序不一样,要注意)。从关系的维度拆开来看就是m个关系的图的邻接矩阵。
数学表示为:
X i j k = 1 \mathcal{X}_{ijk}=1 Xijk=1
表示第 i i i个实体和第 j j j个实体存在第 k k k种关系。不存在关系则为0。
作者还定义了几种three-way tensor的运算,例如: X k \mathcal{X}_{k} Xk代表第
k k k种关系的切片。具体看原文。
模型
模型的核心就是:
X k ≈ A R k A T , f o r k = 1 , ⋯ , m (1) \mathcal{X}_{k}\approx AR_kA^T,for\space k =1,\cdots,m\tag1 Xk≈ARkAT,for k=1,⋯,m(1)
从线性代数来看就是把每个关系对应的邻接矩阵进行了矩阵的分解,因为每个矩阵估计比较稀疏,可以把n维矩阵分解为k维的;
从我们神经网络的角度来看,那么这里就做线性变换,而且是两次线性变换,第一次: A R k AR_k ARk,第二次: R k A T R_kA^T RkAT
基于上面的公式,可转化为正则最小化问题,得最后的loss函数。
DistMult
EMBEDDING ENTITIES AND RELATIONS FOR LEARNING
AND INFERENCE IN KNOWLEDGE BASES
摘要
先开门见山说要搞啥
We consider learning representations of entities and relations in KBs using the neural-embedding approach.
现有的方法有哪些,目的是什么
We show that most existing models, including NTN (Socher et al., 2013) and TransE (Bordes et al., 2013b), can be generalized under a unified learning framework, where entities are low-dimensional vectors learned from a neural network and relations are bilinear and/or linear mapping functions.
我们咋做,主要核心是:双线性变换
Under this framework, we compare a variety of embedding models on the link prediction task. We show that a simple bilinear formulation achieves new state-of-the-art results for the task (achieving a top-10 accuracy of 73.2% vs. 54.7% by TransE on Freebase).
还做了类似逻辑规则挖掘的工作
Furthermore, we introduce a novel approach that utilizes the learned relation embeddings to mine logical rules such as B o r n I n C i t y p ( a , b ) ∧ C i t y I n C o u n t r y ( b , c ) ⇒ N a t i o n a l i t y p ( a , c ) BornInCityp(a, b)\wedge CityInCountry(b, c)\Rightarrow Nationalityp(a, c) BornInCityp(a,b)∧CityInCountry(b,c)⇒Nationalityp(a,c).
原理稍微解释一下
We find that embeddings learned from the bilinear objective are particularly good at capturing relational semantics, and that the composition of relations is characterized by matrix multiplication.
效果如果
More interestingly, we demonstrate that our embedding-based rule extraction approach successfully outperforms a state-ofthe-art confidence-based rule mining approach in mining Horn rules that involve compositional reasoning.
模型
这个模型是改进了前面的RESCAL,也是双线性变换:
g r b ( Y e 1 , Y e 2 ) = Y e 1 T M r Y e 2 g_r^b(Y_{e1},Y_{e2})=Y_{e1}^TM_rY_{e2} grb(Ye1,Ye2)=Ye1TMrYe2
这里的形式和RESCAL一样,但是中间的 M r M_r Mr不一样,它在RESCA中没有限制,而这里则有限制:必须是对角阵。这样做最直接的变化就是参数量变少。
ConvE
这篇和前面的方法思路不一样,之前的随机游走、Trans系列,双线性变换系列的研究都是属于浅层模型的研究,表达能力有限,这篇文章就用了深层模型来解决知识图谱中的链接预测任务。
Convolutional 2D Knowledge Graph Embeddings
代码:https://github.com/TimDettmers/ConvE
摘要就不贴了。
为什么是2D不是1D卷积
2D能引入更多的交互信息,例如:
( [ a a a ] ; [ b b b ] ) = [ a a a b b b ] ([ a\quad a\quad a ];[ b\quad b\quad b ])=[ a\quad a\quad a\quad b\quad b\quad b ] ([aaa];[bbb])=[aaabbb]
这里a和b可以看做head和tail实体对应的向量,这里用1D卷积核( k = 3 k=3 k=3)得到的head和tail的交互信息和卷积核大小成正比
如果按原文的方式将head和tail向量进行拷贝堆叠(堆叠方式也有影响),再用2D进行卷积得到的交互信息更多。
这里的交互次数可以这样理解,在推荐系统里面通常是要考虑用户与商品的共现次数的,例如张三买火锅,如果能使得这个关系在数据中多次重复出现,那么就会使得张三与火锅的关系凸显非常紧密。
模型
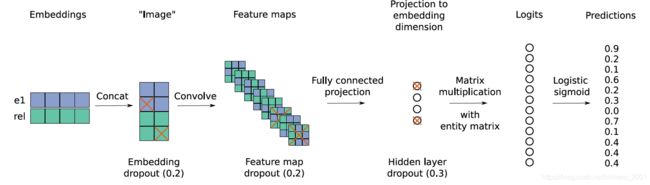
ψ r ( e s , e o ) = f ( v e c ( f ( [ e s ‾ ; r r ‾ ] ∗ ω ) ) W ) e o \psi _r(e_s,e_o)=f(vec(f([\overline{e_s};\overline{r_r}]*\omega))W)e_o ψr(es,eo)=f(vec(f([es;rr]∗ω))W)eo
上式中, [ e s ‾ ; r r ‾ ] [\overline{e_s};\overline{r_r}] [es;rr]表示源实体对象和关系两个向量的二维拼接,就是上图中的concat,得到单通道的图像
∗ ω *\omega ∗ω表示卷积操作,得到上图中的Feature map
v e c vec vec表示把Feature map整形为一个向量
然后使用矩阵 W W W做线性变换,得到和预测目标实体对象相同维度的结果,
然后和预测目标实体对象矩阵做内积得到预测结果。
具体的维度原文有,这里就不写了。