负载均衡Ribbon入门
一、负载均衡的引入
在微服务中,服务的调用很常见,比如有2个集群,A和B,如果A集群需要调用B集群的某个接口,但是B集群中有很多服务b,这时A集群就不知道调用哪个
为了解决这个问题,大佬们引入了负载均衡器。
负载均衡有2种类型
一种是以Nginx为代表的服务端的负载均衡
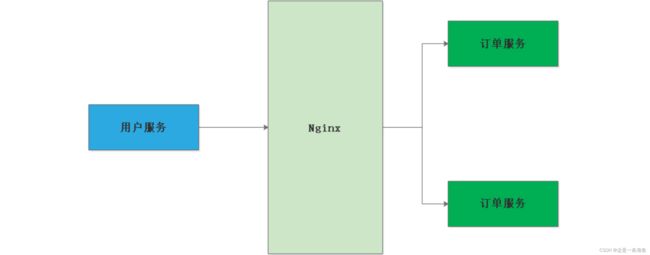
我们用户服务发送请求首先打到Ng上,然后Ng根据负载均衡算法进行选择一个服务调 用,而我们的Ng部署在服务器上的,所以Ng又称为服务端的负载均衡(具体调用哪个服务, 由Ng所了算)
生活案例: 程序员张三 去盲人按摩, 前台的小姐姐接待了张三,然后为张三分派技师按摩.
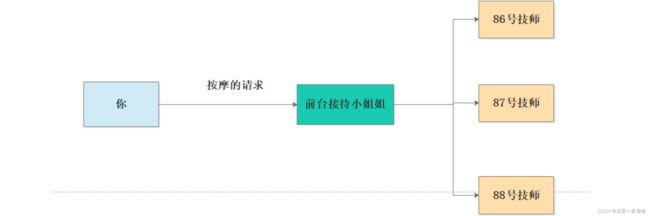
另一种是以ribbon为代表的客户端负载均衡

生活案例: 程序员张三去盲人按摩,张三自己选技师按摩.
spring cloud ribbon是 基于NetFilix ribbon 实现的一套客户端的负载 均衡工具,Ribbon客户端组件提供一系列的完善的配置,如超时,重试 等。通过Load Balancer(LB)获取到服务提供的所有机器实例,Ribbon 会自动基于某种规则(轮询,随机)去调用这些服务。Ribbon也可以实 现我们自己的负载均衡算法。
二、自定义的负载均衡算法
我们可以通过DiscoveryClient组件来去我们的Nacos服务端拉取给名称的微服务列表。我们可以通过这个特性来改写我们的RestTemplate 组件,经过阅读源码RestTemplate组件得知,不管是post,get请求最终是会调 用我们的doExecute()方法,所以我们写一个TulingRestTemplate类继承 RestTemplate,从写doExucute()方法。
Slf4j
public class TulingRestTemplate extends RestTemplate {
private DiscoveryClient discoveryClient;
public TulingRestTemplate (DiscoveryClient discoveryClient) {
this.discoveryClient = discoveryClient;
}
protected <T> T doExecute(URI url, @Nullable HttpMethod method, @Nullable RequestCallback requestCallback,
@Nullable ResponseExtractor<T> responseExtractor) throws RestClientException {
Assert.notNull(url, "URI is required");
Assert.notNull(method, "HttpMethod is required");
ClientHttpResponse response = null;
try {
log.info("请求的url路径为:{}",url);
//把服务名 替换成我们的IP
url = replaceUrl(url);
log.info("替换后的路径:{}",url);
ClientHttpRequest request = createRequest(url, method);
if (requestCallback != null) {
requestCallback.doWithRequest(request);
}
response = request.execute();
handleResponse(url, method, response);
return (responseExtractor != null ? responseExtractor.extractData(response) : null);
}
catch (IOException ex) {
String resource = url.toString();
String query = url.getRawQuery();
resource = (query != null ? resource.substring(0, resource.indexOf('?')) : resource);
throw new ResourceAccessException("I/O error on " + method.name() +
" request for \"" + resource + "\": " + ex.getMessage(), ex);
} finally {
if (response != null) {
response.close();
}
}
}
/**
* 方法实现说明:把微服务名称 去注册中心拉取对应IP进行调用
* http://product-center/selectProductInfoById/1
* @author:smlz
* @param url:请求的url
* @return:
* @exception:
* @date:2020/2/6 13:11
*/
private URI replaceUrl(URI url){
//1:从URI中解析调用的调用的serviceName=product-center
String serviceName = url.getHost();
log.info("调用微服务的名称:{}",serviceName);
//2:解析我们的请求路径 reqPath= /selectProductInfoById/1
String reqPath = url.getPath();
log.info("请求path:{}",reqPath);
//通过微服务的名称去nacos服务端获取 对应的实例列表
List<ServiceInstance> serviceInstanceList = discoveryClient.getInstances(serviceName);
if(serviceInstanceList.isEmpty()) {
throw new RuntimeException("没有可用的微服务实例列表:"+serviceName);
}
String serviceIp = chooseTargetIp(serviceInstanceList);
String source = serviceIp+reqPath;
try {
return new URI(source);
} catch (URISyntaxException e) {
log.error("根据source:{}构建URI异常",source);
}
return url;
}
/**
* 方法实现说明:从服务列表中 随机选举一个ip
* @author:smlz
* @param serviceInstanceList 服务列表
* @return: 调用的ip
* @exception:
* @date:2020/2/6 13:15
*/
private String chooseTargetIp(List<ServiceInstance> serviceInstanceList) {
//采取随机的获取一个
Random random = new Random();
Integer randomIndex = random.nextInt(serviceInstanceList.size());
String serviceIp = serviceInstanceList.get(randomIndex).getUri().toString();
log.info("随机选举的服务IP:{}",serviceIp);
return serviceIp;
}
}
三、通过Ribbon组件来实习负载均衡
第一步:加入依赖(加入nocas-client和ribbon的依赖)
<dependency>
<groupId>com.alibaba.cloudgroupId>
<artifactId>spring-cloud-alibaba-nacos-discoveryartifactId>
dependency>
<dependency>
<groupId>org.springframework.cloudgroupId>
<artifactId>spring-cloud-starter-netflix-ribbonartifactId>
dependency>
第二步:写注解: 在RestTemplate上加入@LoadBalanced注解
@Configuration
public class WebConfig implements WebMvcConfigurer {
@LoadBalanced
@Bean
public RestTemplate restTemplate( ) {
return new RestTemplate();
}
}
例如:下面的restTemplate还没有被@LoadBalanced进行处理,所以他不能把服务吗order进行处理。
@PostConstruct
public JsonResult getOrderById1(){
ResponseEntity<JsonResult> responseEntity= restTemplate.getForEntity("http://order/order/getOrder", JsonResult.class);
return responseEntity.getBody();
}
第三步:写配置文件(这里是写Nacos 的配置文件,暂时没有配置Ribbon的配置)
spring:
application:
name: order #服务名是必须设置的,否则nacos发现不了这个服务
cloud:
nacos:
discovery:
server-addr: 192.168.93.224:8848
第四步:测试,存储服务调取订单服务order
@GetMapping("getOrderById1/{orderNo}")
public JsonResult getOrderById1(@PathVariable String orderNo){
ResponseEntity<JsonResult> responseEntity= restTemplate.getForEntity("http://order/order/getOrder", JsonResult.class);
return responseEntity.getBody();
}
四、Ribbon负载均衡规则
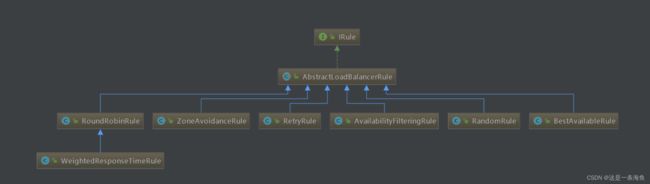
①RandomRule:(随机选择一个Server)
②RetryRule: 对选定的负载均衡策略机上重试机制,在一个配置时间段内当选择Server不成功, 则一直尝试使用subRule的方式选择一个可用的server.
③RoundRobinRule :轮询选择, 轮询index,选择index对应位置的Server
④AvailabilityFilteringRule: 过滤掉一直连接失败的被标记为circuit tripped的后端Server,并过滤掉那些高并发的后端 Server或者使用一个AvailabilityPredicate来包含过滤server的逻辑,其实就就是检查 status里记录的各个Server的运行状态
⑤BestAvailableRule:选择一个最小的并发请求的Server,逐个考察Server,如果Server被tripped了,则跳过。
⑥WeightedResponseTimeRule: 根据响应时间加权,响应时间越长,权重越小,被选中的可能性越低;
⑦ZoneAvoidanceRule:(默认是这个) 复合判断Server所在Zone的性能和Server的可用性选择Server,在没有Zone的情况下作用就是是轮询。
如果我们不想使用默认策略,我们可以这样配置
@Configuration
public class WebConfig {
@LoadBalanced
@Bean
public RestTemplate restTemplate() {
return new RestTemplate();
}
/**
* 修改默认策略
*/
@Bean
public RandomRule randomRule(){
return new RandomRule();
}
}
五、Ribbon自定义负载均衡规则
5.1 基于权重的负载均衡
我们发现,nacos server上的页面发现 注册的微服务有一个权重的概 念。取值为0-1之间

权重选择的概念: 假设我们一个微服务部署了三台服务器A,B,C 其中A,B,C三台服务的性能不一,A的性能最牛逼,B次之,C最差. 那么我们设置权重比例 为5 : 3:2 那就说明 10次请求到A上理论是5次,B 服务上理论是3次,B服务理论是2次.
但是Ribbon 所提供的负载均衡算法中没有基于权重的负载均衡算法。那我们自己实现一个.
public class TulingWeightedRule extends AbstractLoadBalancerRule {
@Autowired
private NacosDiscoveryProperties discoveryProperties;
@Override
public void initWithNiwsConfig(IClientConfig clientConfig) {
//读取配置文件并且初始化,ribbon内部的 几乎用不上
}
@Override
public Server choose(Object key) {
try {
log.info("key:{}",key);
BaseLoadBalancer baseLoadBalancer = (BaseLoadBalancer) this.getLoadBalancer();
log.info("baseLoadBalancer--->:{}",baseLoadBalancer);
//获取微服务的名称
String serviceName = baseLoadBalancer.getName();
//获取Nocas服务发现的相关组件API
NamingService namingService = discoveryProperties.namingServiceInstance();
//获取 一个基于nacos client 实现权重的负载均衡算法
Instance instance = namingService.selectOneHealthyInstance(serviceName);
//返回一个server
return new NacosServer(instance);
} catch (NacosException e) {
log.error("自定义负载均衡算法错误");
}
return null;
}
}
5.2 同集群优先权重负载均衡算法
业务场景:现在我们有二个微服务order-center, product-center二个微服 务。我们在南京机房部署一套order-center,product-center。为了容灾处理,我们在北京同样部署一套order-center,product-center

@Slf4j
public class TheSameClusterPriorityRule extends AbstractLoadBalancerRule {
@Autowired
private NacosDiscoveryProperties discoveryProperties;
@Override
public void initWithNiwsConfig(IClientConfig clientConfig) {
}
@Override
public Server choose(Object key) {
try {
//第一步:获取当前服务所在的集群
String currentClusterName = discoveryProperties.getClusterName();
//第二步:获取一个负载均衡对象
BaseLoadBalancer baseLoadBalancer = (BaseLoadBalancer) getLoadBalancer();
//第三步:获取当前调用的微服务的名称
String invokedSerivceName = baseLoadBalancer.getName();
//第四步:获取nacos clinet的服务注册发现组件的api
NamingService namingService = discoveryProperties.namingServiceInstance();
//第五步:获取所有的服务实例
List<Instance> allInstance = namingService.getAllInstances(invokedSerivceName);
List<Instance> theSameClusterNameInstList = new ArrayList<>();
//第六步:过滤筛选同集群下的所有实例
for(Instance instance : allInstance) {
if(StringUtils.endsWithIgnoreCase(instance.getClusterName(),currentClusterName)) {
theSameClusterNameInstList.add(instance);
}
}
Instance toBeChooseInstance ;
//第七步:选择合适的一个实例调用
if(theSameClusterNameInstList.isEmpty()) {
toBeChooseInstance = TulingWeightedBalancer.chooseInstanceByRandomWeight(allInstance);
log.info("发生跨集群调用--->当前微服务所在集群:{},被调用微服务所在集群:{},Host:{},Port:{}",
currentClusterName,toBeChooseInstance.getClusterName(),toBeChooseInstance.getIp(),toBeChooseInstance.getPort());
}else {
toBeChooseInstance = TulingWeightedBalancer.chooseInstanceByRandomWeight(theSameClusterNameInstList);
log.info("同集群调用--->当前微服务所在集群:{},被调用微服务所在集群:{},Host:{},Port:{}",
currentClusterName,toBeChooseInstance.getClusterName(),toBeChooseInstance.getIp(),toBeChooseInstance.getPort());
}
return new NacosServer(toBeChooseInstance);
} catch (NacosException e) {
log.error("同集群优先权重负载均衡算法选择异常:{}",e);
}
return null;
}
}
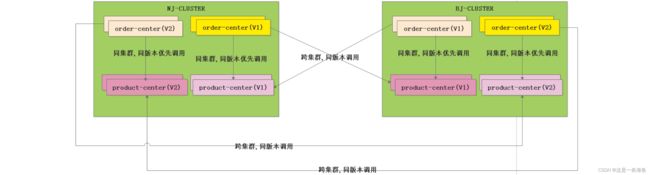
5.2 解决生产环境金丝雀发布(灰度发布)问题
比如 order-center 存在二个版本 V1(老版本) V2(新版本),product-center也存在二个版本V1(老版本) V2新版本 现在需要做到的是 order-center(V1)---->product-center(v1),order-center(V2)— ->product-center(v2)。记住v2版本是小面积部署的,用来测试用户对新版本功能的。若用户完全接受了v2。我们就可以把V1版本卸载完全部署V2版本。
@Slf4j
public class TheSameClusterPriorityWithVersionRule extends AbstractLoadBalancerRule {
@Autowired
private NacosDiscoveryProperties discoveryProperties;
@Override
public void initWithNiwsConfig(IClientConfig clientConfig) {
}
@Override
public Server choose(Object key) {
try {
String currentClusterName = discoveryProperties.getClusterName();
List<Instance> theSameClusterNameAndTheSameVersionInstList = getTheSameClusterAndTheSameVersionInstances(discoveryProperties);
//声明被调用的实例
Instance toBeChooseInstance;
//判断同集群同版本号的微服务实例是否为空
if(theSameClusterNameAndTheSameVersionInstList.isEmpty()) {
//跨集群调用相同的版本
toBeChooseInstance = crossClusterAndTheSameVersionInovke(discoveryProperties);
}else {
toBeChooseInstance = TulingWeightedBalancer.chooseInstanceByRandomWeight(theSameClusterNameAndTheSameVersionInstList);
log.info("同集群同版本调用--->当前微服务所在集群:{},被调用微服务所在集群:{},当前微服务的版本:{},被调用微服务版本:{},Host:{},Port:{}",
currentClusterName,toBeChooseInstance.getClusterName(),discoveryProperties.getMetadata().get("current-version"),
toBeChooseInstance.getMetadata().get("current-version"),toBeChooseInstance.getIp(),toBeChooseInstance.getPort());
}
return new NacosServer(toBeChooseInstance);
} catch (NacosException e) {
log.error("同集群优先权重负载均衡算法选择异常:{}",e);
return null;
}
}
/**
* 方法实现说明:获取相同集群下,相同版本的 所有实例
* @author:smlz
* @param discoveryProperties nacos的配置
* @return: List
* @exception: NacosException
* @date:2019/11/21 16:41
*/
private List<Instance> getTheSameClusterAndTheSameVersionInstances(NacosDiscoveryProperties discoveryProperties) throws NacosException {
//当前的集群的名称
String currentClusterName = discoveryProperties.getClusterName();
String currentVersion = discoveryProperties.getMetadata().get("current-version");
//获取所有实例的信息(包括不同集群的)
List<Instance> allInstance = getAllInstances(discoveryProperties);
List<Instance> theSameClusterNameAndTheSameVersionInstList = new ArrayList<>();
//过滤相同集群的
for(Instance instance : allInstance) {
if(StringUtils.endsWithIgnoreCase(instance.getClusterName(),currentClusterName)&&
StringUtils.endsWithIgnoreCase(instance.getMetadata().get("current-version"),currentVersion)) {
theSameClusterNameAndTheSameVersionInstList.add(instance);
}
}
return theSameClusterNameAndTheSameVersionInstList;
}
/**
* 方法实现说明:获取被调用服务的所有实例
* @author:smlz
* @param discoveryProperties nacos的配置
* @return: List
* @exception: NacosException
* @date:2019/11/21 16:42
*/
private List<Instance> getAllInstances(NacosDiscoveryProperties discoveryProperties) throws NacosException {
//第1步:获取一个负载均衡对象
BaseLoadBalancer baseLoadBalancer = (BaseLoadBalancer) getLoadBalancer();
//第2步:获取当前调用的微服务的名称
String invokedSerivceName = baseLoadBalancer.getName();
//第3步:获取nacos clinet的服务注册发现组件的api
NamingService namingService = discoveryProperties.namingServiceInstance();
//第4步:获取所有的服务实例
List<Instance> allInstance = namingService.getAllInstances(invokedSerivceName);
return allInstance;
}
/**
* 方法实现说明:跨集群环境下 相同版本的
* @author:smlz
* @param discoveryProperties
* @return: List
* @exception: NacosException
* @date:2019/11/21 17:11
*/
private List<Instance> getCrossClusterAndTheSameVersionInstList(NacosDiscoveryProperties discoveryProperties) throws NacosException {
//版本号
String currentVersion = discoveryProperties.getMetadata().get("current-version");
//被调用的所有实例
List<Instance> allInstance = getAllInstances(discoveryProperties);
List<Instance> crossClusterAndTheSameVersionInstList = new ArrayList<>();
//过滤相同版本
for(Instance instance : allInstance) {
if(StringUtils.endsWithIgnoreCase(instance.getMetadata().get("current-version"),currentVersion)) {
crossClusterAndTheSameVersionInstList.add(instance);
}
}
return crossClusterAndTheSameVersionInstList;
}
private Instance crossClusterAndTheSameVersionInovke(NacosDiscoveryProperties discoveryProperties) throws NacosException {
//获取所有集群下相同版本的实例信息
List<Instance> crossClusterAndTheSameVersionInstList = getCrossClusterAndTheSameVersionInstList(discoveryProperties);
//当前微服务的版本号
String currentVersion = discoveryProperties.getMetadata().get("current-version");
//当前微服务的集群名称
String currentClusterName = discoveryProperties.getClusterName();
//声明被调用的实例
Instance toBeChooseInstance = null ;
//没有对应相同版本的实例
if(crossClusterAndTheSameVersionInstList.isEmpty()) {
log.info("跨集群调用找不到对应合适的版本当前版本为:currentVersion:{}",currentVersion);
throw new RuntimeException("找不到相同版本的微服务实例");
}else {
toBeChooseInstance = TulingWeightedBalancer.chooseInstanceByRandomWeight(crossClusterAndTheSameVersionInstList);
log.info("跨集群同版本调用--->当前微服务所在集群:{},被调用微服务所在集群:{},当前微服务的版本:{},被调用微服务版本:{},Host:{},Port:{}",
currentClusterName,toBeChooseInstance.getClusterName(),discoveryProperties.getMetadata().get("current-version"),
toBeChooseInstance.getMetadata().get("current-version"),toBeChooseInstance.getIp(),toBeChooseInstance.getPort());
}
return toBeChooseInstance;
}
}
六、Ribbon的细粒度负载均衡自定义配置
场景:我订单中心需要采用随机算法调用库存中心,而采用轮询算法调用其他中心微服务。
我们针对调用具体微服务的具体配置类 ProductCenterRibbonConfig,OtherCenterRibbonConfig不能被放在我们主启动类所 在包以及子包下,不然就起不到细粒度配置.
@Configuration
public class PayCenterRibbonConfig {
@Bean
public IRule roundRobinRule() {
return new RoundRobinRule();
}
}
@Configuration
public class ProductCenterRibbonConfig {
@Bean
public IRule randomRule() {
return new RandomRule();
}
}
ribbon的全局配置
@Configuration
@RibbonClients(value = {
@RibbonClient(name = "product-center",configuration = ProductCenterRibbonConfig.class),
@RibbonClient(name = "pay-center",configuration = PayCenterRibbonConfig.class)
})
@RibbonClients(defaultConfiguration = GlobalRibbonConfig.class)
public class CustomRibbonConfig {
}
或者我们使用配置文件实现上面的功能,如下
yml配置:(我们可以在order-center的yml中进行配置) 配置格式的语法如下
#自定义Ribbon的细粒度配置
product‐center:
ribbon:
NFLoadBalancerRuleClassName: com.netflix.loadbalancer.RandomRule
pay‐center:
ribbon:
NFLoadBalancerRuleClassName: com.netflix.loadbalancer.RoundRobinRule
七、Ribbon常用参数讲解
7.1 配置负载均衡策略
Ribbon 默认的策略是轮询,从我们前面讲解的例子输出的结果就可以看出来,Ribbon 中提供了很多的策略。我们通过配置可以指定服务使用哪种策略来进行负载操作。
<服务提供者名称>:
ribbon:
listOfServers: localhost:7901,localhost:7902
NFLoadBalancerRuleClassName: com.netflix.loadbalancer.RandomRule
7.2 超时时间
Ribbon 中有两种和时间相关的设置,分别是请求连接的超时时间和请求处理的超时时间,设置规则如下:
全局设置
# 请求连接的超时时间
ribbon.ConnectTimeout=2000
# 请求处理的超时时间
ribbon.ReadTimeout=5000
局部设置
# 也可以为每个Ribbon客户端设置不同的超时时间, 通过服务名称进行指定:
<服务提供者名称>.ribbon.ConnectTimeout=2000
<服务提供者名称>.ribbon.ReadTimeout=5000
7.3 并发参数
# 最大连接数
ribbon.MaxTotalConnections=500
# 每个host最大连接数
ribbon.MaxConnectionsPerHost=500
7.4 重试机制
在集群环境中,用多个节点来提供服务,难免会有某个节点出现故障。用 Nginx 做负载均衡的时候,如果你的应用是无状态的、可以滚动发布的,也就是需要一台台去重启应用,这样对用户的影响其实是比较小的,因为 Nginx 在转发请求失败后会重新将该请求转发到别的实例上去。
由于 Eureka 是基于 AP 原则构建的,牺牲了数据的一致性,每个 Eureka 服务都会保存注册的服务信息,当注册的客户端与 Eureka 的心跳无法保持时,有可能是网络原因,也有可能是服务挂掉了。
在这种情况下,Eureka 中还会在一段时间内保存注册信息。这个时候客户端就有可能拿到已经挂掉了的服务信息,故 Ribbon 就有可能拿到已经失效了的服务信息,这样就会导致发生失败的请求。
这种问题我们可以利用重试机制来避免。重试机制就是当 Ribbon 发现请求的服务不可到达时,重新请求另外的服务。
有2种方法解决上述问题
第一种,RetryRule 重试,它是利用 Ribbon 自带的重试策略进行重试,此时只需要指定某个服务的负载策略为重试策略即可:
ribbon-config-demo.ribbon.NFLoadBalancerRuleClassName=com.netflix.loadbalancer.RetryRule
第一种,Spring Retry 重试,通过集成 Spring Retry 来进行重试操作。
在 pom.xml 中添加 Spring Retry 的依赖,代码如下所示。
<dependency>
<groupId>org.springframework.retrygroupId>
<artifactId>spring-retryartifactId>
dependency>
配置重试次数等信息:
# 对当前实例的重试次数
ribbon.maxAutoRetries=1
# 切换实例的重试次数
ribbon.maxAutoRetriesNextServer=3
# 对所有操作请求都进行重试
ribbon.okToRetryOnAllOperations=true
# 对Http响应码进行重试
ribbon.retryableStatusCodes=500,404,502
7.4 解决Ribbon 第一次调用耗时高
#开启饥饿加载
ribbon:
eager‐load:
enabled: true
clients: product‐center #可以指定多个微服务用逗号分隔
7.5 是否对所以的操作进行重试
#True 的话 会对post put操作进行重试,存在服务幂等问题,所以最好设置成false
ribbon.OkToRetryOnAllOperations=false