大数据辅助工具--Flume 数据采集组件
大数据辅助工具--Flume 数据采集组件
- 1、数据收集工具系统产生背景
- 2、专业的数据收集工具
-
- 2.1、Chukwa
- 2.2、Scribe
- 2.3、Fluentd
- 2.4、Logstash
- 2.5、Apache Flume
- 3、Flume 概述
-
- 3.1、Flume 概念
- 3.2、Flume 版本介绍
- 4、Flume 体系结构/核心组件
-
- 4.1、概述
- 4.2、Flume 核心组件
-
- 4.2.1、Event
- 4.2.2、Client
- 4.2.3、Agent
- 4.2.4、Source
- 4.2.5、Agent 之 Channel
- 4.2.6、Agent 之 Sink
- 4.2.7、Iterator
- 4.2.8、Channel Selector
- 4.2.9、Sink Processor
- 4.3、Flume 经典部署方案
-
- 4.3.1、单 Agent 采集数据
- 4.3.2、多 Agent 串联
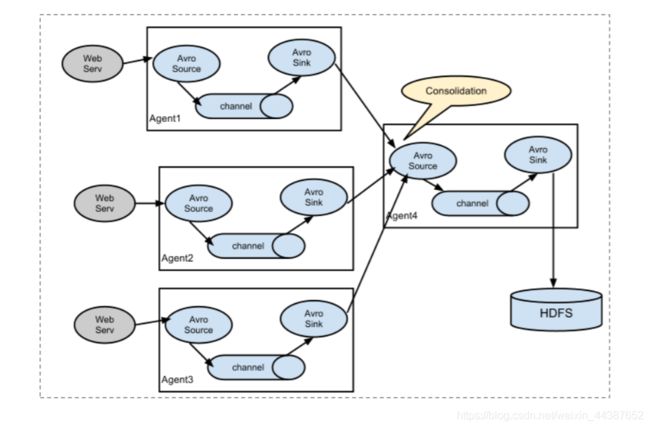
- 4.3.3、多 Agent 合并串联
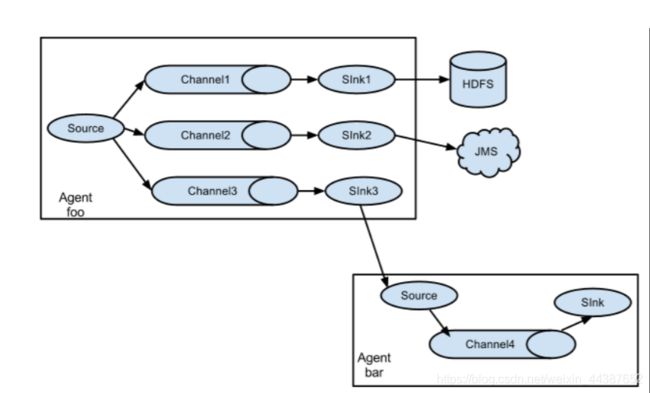
- 4.3.4、多路复用
- 5、Flume 实战案例
-
- 5.1、安装部署 Flume
- 5.2、Flume 实战案例
-
- 5.2.1、采集目录下文件到 HDFS
- 5.2.2、采集文件中信息到 HDFS
- 5.2.3、多 agent 串联采集
- 5.2.4、高可用部署采集
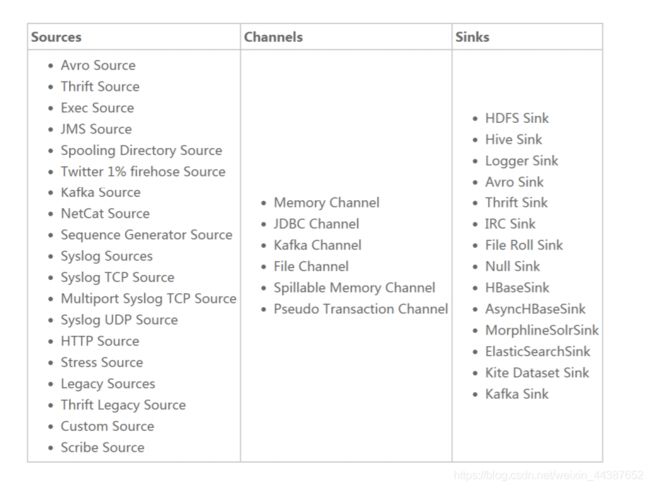
- 5.2.5、更多 Source 和 Sink 组件
- 6、综合案例
-
- 6.1、案例场景/需求
- 6.2、场景分析
- 6.3、数据处理流程分析
- 6.4、需求实现
1、数据收集工具系统产生背景
(1)Hadoop 业务的整体开发流程:

(2)任何完整的大数据平台,一般都会包括以下的基本处理过程:
① 数据采集;
② 数据 ETL;
③ 数据存储;
④ 数据计算/分析;
⑤ 数据展现。
⑥⑦⑧
其中,数据采集是所有数据系统必不可少的,随着大数据越来越被重视,数据采集的挑战也变的尤为突出。这其中包括:
① 数据源多种多样;
② 数据量大,变化快;
③ 如何保证数据采集的可靠性的性能;
④ 如何避免重复数据;
⑤ 如何保证数据的质量。
我们今天就来看看当前可用的一些数据采集的产品,重点关注一些它们是如何做到高可靠,高性能和高扩展。
2、专业的数据收集工具
2.1、Chukwa
Apache Chukwa 是 Apache 旗下另一个开源的数据收集平台,它远没有其他几个有名。Chukwa 基于 Hadoop 的 HDFS 和 MapReduce 来构建(显而易见,它用 Java 来实现),提供扩展性和可靠性。Chukwa 同时提供对数据的展示,分析和监视。很奇怪的是它的上一次 Github 的更新是差不多 10 年前左右了。可见该项目应该已经不活跃了。
官网:http://chukwa.apache.org/
2.2、Scribe
Scribe 是 Facebook 开源的日志收集系统,在 Facebook 内部已经得到的应用。它能够从各种日志源上收集日志,存储到一个中央存储系统(可以是 NFS,HDFS,或者其他分布式文件系统等)上,以便于进行集中统计分析处理。
官网:https://www.scribesoft.com/
2.3、Fluentd
Fluentd 是另一个开源的数据收集框架。Fluentd 使用 C/Ruby 开发,使用 JSON 文件来统一日志数据。它的可插拔架构,支持各种不同种类和格式的数据源和数据输出。最后它也同时提供了高可靠和很好的扩展性。
官网:https://www.fluentd.org/
2.4、Logstash
Logstash 是著名的开源数据栈 ELK(ElasticSearch,Logstash,Kibana)中的那个 L。几乎在大部分的情况下 ELK 作为一个栈是被同时使用的。所有当你的数据系统使用 ElasticSearch 的情况下,Logstash 是首选。Logstash 用 JRuby 开发,所以运行时依赖 JVM。
官网:https://www.elastic.co/cn/products/logstash
2.5、Apache Flume
Flume 是 Apache 旗下,开源,高可靠,高扩展,容易管理,支持客户扩展的数据采集系统。Flume 使用 JRuby 来构建,所以依赖 Java 运行环境。Flume 最初是由 Cloudera 的工程师设计用于合并日志数据的系统,后来逐渐发展用于处理流数据事件。
官网:http://flume.apache.org/
3、Flume 概述
3.1、Flume 概念
Flume is a distributed, reliable, and available service for efficiently collecting, aggregating, and moving large amounts of log data. It has a simple and flexible architecture based on streaming data flows. It is robust and fault tolerant with tunable reliability mechanisms and many failover and recovery mechanisms. It uses a simple extensible data model that allows for online analytic application.
Flume 是一个分布式、可靠、高可用的海量日志聚合系统,支持在系统中定制各类数据发送方,用于收集数据,同时,Flume 提供对数据的简单处理,并写到各种数据接收方的能力。
(1)Apache Flume 是一个分布式、可靠、和高可用的海量日志采集、聚合和传输的系统,和 Sqoop 同属于数据采集系统组件,但是 Sqoop 用来采集关系型数据库数据,而 Flume 用来采集流动型数据。
(2)Flume 名字来源于原始的近乎实时的日志数据采集工具,现在被广泛用于任何流事件数据的采集,它支持从很多数据源聚合数据到 HDFS。
(3)一般的采集需求,通过对 flume 的简单配置即可实现。Flume 针对特殊场景也具备良好的自定义扩展能力,因此,flume 可以适用于大部分的日常数据采集场景。
(4)Flume 最初由 Cloudera 开发,在 2011 年贡献给了 Apache 基金会,2012 年变成了 Apache的顶级项目。Flume OG(Original Generation)是 Flume 最初版本,后升级换代成 Flume NG(Next/New Generation)。
(5)Flume 的优势:可横向扩展、延展性、可靠性。
3.2、Flume 版本介绍
Flume 在 0.9.x and 1.x 之间有较大的架构调整,1.x 版本之后的改称 Flume NG,0.9.x 的称为 Flume OG。

官网文档:http://flume.apache.org/FlumeUserGuide.html
4、Flume 体系结构/核心组件
4.1、概述
Flume 的数据流由事件(Event)贯穿始终。Event 是 Flume 的基本数据单位,它携带日志数据(字节数组形式)并且携带有头信息,这些 Event 由 Agent 外部的 Source 生成,当 Source 捕获 Event 后会进行特定的格式化,然后 Source 会把 Event 推入(单个或多个) Channel 中。你可以把 Channel 看作是一个缓冲区,它将保存事件直到 Sink 处理完该事件。Sink 负责持久化日志或者把事件推向另一个 Source。
Flume 以 agent 为最小的独立运行单位。一个 agent 就是一个 JVM。单个 agent 由 Source、Sink 和 Channel 三大组件构成,如下图:

| 组件 | 功能 |
|---|---|
| Agent | 使用 JVM 运行 Flume。每台机器运行一个 agent,但是可以在一个 agent 中包含多个 sources 和 sinks。 |
| Client | 生产数据,运行在一个独立的线程。 |
| Source | 从 Client 收集数据,传递给 Channel。 |
| Sink | 从 Channel 收集数据,运行在一个独立线程。 |
| Channel | 连接 sources 和 sinks,这个有点像一个队列。 |
| Events | 可以是日志记录、avro 对象等。 |
4.2、Flume 核心组件
4.2.1、Event
Event(事件)是 Flume 数据传输的基本单元。Flume 以事件的形式将数据从源头传送到最终的目的。
Event 由可选的 header 和载有数据的一个 byte array 构成。
(1)载有的数据度 flume 是不透明的。
(2)Header 是容纳了 key-value 字符串对的无序集合,key 在集合内是唯一的。
(3)Header 可以在上下文路由中使用扩展。
4.2.2、Client
Client 是一个将原始 log 包装成 events 并且发送他们到一个或多个 agent 的实体。目的是从数据源系统中解耦 Flume,在 flume 的拓扑结构中不是必须的。
Client 实例:
(1)flume log4j Appender。
(2)可以使用 Client SDK(org.apache.flume.api)定制特定的 Client。
4.2.3、Agent
agent 是 flume 流的基础部分。一个 Agent 包含 source,channel,sink 和其他组件。它利用这些组件将 events 从一个节点传输到另一个节点或最终目的地。 flume 为这些组件提供了配置,声明周期管理,监控支持。
4.2.4、Source
Source 负责接收 event 或通过特殊机制产生 event,并将 events 批量的放到一个或多个 Channel,包含 event 驱动和轮询两种类型。
不同类型的 Source:
(1)与系统集成的 Source:Syslog、Netcat、监测目录池。
(2)自动生成事件的 Source:Exec。
(3)用于 Agent 和 Agent 之间通信的 IPC source:avro、thrift。
(4)source 必须至少和一个 channel 关联。
4.2.5、Agent 之 Channel
Channel 位于 Source 和 Sink 之间,用于缓存进来的 event。当 sink 成功的将 event 发送到下一个的 channel 或最终目的后, event 从 channel 删除。
不同的 channel 提供的持久化水平也是不一样的。
(1)Memory channel:volatile (不稳定的)。
(2)File Channel:基于 WAL(预写式日志 Write-Ahead logging)实现。
(3)JDBC channel:基于嵌入式 database 实现。
channel 支持事务,提供较弱的顺序保证,可以和任何数量的 source 和 sink 工作。
4.2.6、Agent 之 Sink
Silk 负责将 event 传输到下一跳或最终目的地,成功后将 event 从 channel 移除。
不同类型的 silk:
(1)存储 event 到最终目的地终端 sink,比如 HDFS、HBase。
(2)自动消耗的 sink 比如 null sink。
(3)用于 agent 间通信的 IPC:sink:Avro。
(4)必须作用于一个确切的 channel。
4.2.7、Iterator
Iterator 作用于 Source,按照预设的顺序在必要地方装饰和过滤 events。
4.2.8、Channel Selector
Channel Selector 允许 Source 基于预设的标准,从所有 channel 中,选择一个或者多个 channel。
4.2.9、Sink Processor
多个 sink 可以构成一个 sink group,sink processor 可以通过组中所有 sink 实现负载均衡,也可以在一个 sink 失败时转移到另一个。
4.3、Flume 经典部署方案
4.3.1、单 Agent 采集数据

4.3.2、多 Agent 串联

4.3.3、多 Agent 合并串联
4.3.4、多路复用
5、Flume 实战案例
5.1、安装部署 Flume
(1)安装包下载 apache-flume-1.8.0-bin.tar.gz:
链接:https://pan.baidu.com/s/1wxfczarvqJt4D03n512X8w
提取码:ass7
官网下载:http://flume.apache.org/download.html
(2)Flume 的安装非常简单,只需要解压即可,当然,前提是已有 Hadoop 环境。
上传安装包到数据源所在节点上,然后解压:
tar -zxvf apache-flume-1.8.0-bin.tar.gz -C ~/apps
然后进入 flume 的目录,修改 conf 下的 flume-env.sh,在里面配置 JAVA_HOME,再配置 fume 环境变量 FLUME_HOME,更新环境变量。
(3)根据数据采集的需求配置采集方案,描述在配置文件中(文件名可任意自定义)。
(4)指定采集方案配置文件,在相应的节点上启动 flume agent。
(5)先用一个最简单的例子来测试一下程序环境是否正常:
① 在 $FLUME_HOME/agentconf 目录下创建一个数据采集方案,该方案就是从一个网络端口收集数据,也就是创一个任意命名的配置文件如下:netcat-logger.properties
文件内容如下:
# 定义这个 agent 中各个组件的名字(此 agent 别名为 a1)
a1.sources = r1
a1.sinks = k1
a1.channels = c1
# 描述和配置 source 组件:r1
a1.sources.r1.type = netcat
a1.sources.r1.bind = localhost
a1.sources.r1.port = 44444
# 描述和配置 sink 组件:k1
a1.sinks.k1.type = logger
# 描述和配置 channel 组件,此处使用是内存缓存的方式
a1.channels.c1.type = memory
a1.channels.c1.capacity = 1000
a1.channels.c1.transactionCapacity = 100
# 描述和配置 source channel sink 之间的连接关系
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1
② 启动 agent 去采集数据:
在 $FLUME_HOME 下执行如下命令:
bin/flume-ng agent -c conf -f agentconf/netcat-logger.properties -n a1 -Dflume.root.logger=INFO,console

A、-c conf:指定 flume 自身的配置文件所在目录;
B、-f agentconf/netcat-logger.properties:指定我们所描述的采集方案文件;
C、-n a1:指定我们这个 agent 的名字。
③ 测试:
先要往 agent 的 source 所监听的端口上发送数据,让 agent 有数据可采。
例如在本机节点,使用 telnet localhost 44444 命令就可以输入两行数据:
zhang san
1 2 3 4

④ Flume-Agent 接收的结果:

5.2、Flume 实战案例
5.2.1、采集目录下文件到 HDFS
(1)采集需求:某服务器的某特定目录下,会不断产生新的文件,每当有新文件出现,就需要把文件采集到 HDFS 中去。

(2)根据需求,首先定义以下 3 大要素:
A、数据源组件,即 source ——> 监控文件目录 : spooldir。
spooldir 特性:
① 监视一个目录,只要目录中出现新文件,就会采集文件中的内容。
② 采集完成的文件,会被 agent 自动添加一个后缀:.COMPLETED。
③ 所监视的目录中不允许重复出现相同文件名的文件。
B、下沉组件,即 sink ——> HDFS 文件系:hdfs sink。
C、通道组件,即 channel ——> 可用 file channel 也可以用内存 channel。
(3)配置文件编写:spooldir-hdfs.properties.
#定义三大组件的名称
agent1.sources = source1
agent1.sinks = sink1
agent1.channels = channel1
# 配置 source 组件
agent1.sources.source1.type = spooldir
agent1.sources.source1.spoolDir = /home/hadoop/logs/flume/spooldir
agent1.sources.source1.fileHeader = false
#配置拦截器
agent1.sources.source1.interceptors = i1
agent1.sources.source1.interceptors.i1.type = host
agent1.sources.source1.interceptors.i1.hostHeader = hostname
# 配置 sink 组件
agent1.sinks.sink1.type = hdfs
agent1.sinks.sink1.hdfs.path=hdfs://myha01/logs/flume/%y-%m-%d/%H-%M
agent1.sinks.sink1.hdfs.filePrefix = events
agent1.sinks.sink1.hdfs.maxOpenFiles = 5000
agent1.sinks.sink1.hdfs.batchSize= 100
agent1.sinks.sink1.hdfs.fileType = DataStream
agent1.sinks.sink1.hdfs.writeFormat =Text
agent1.sinks.sink1.hdfs.rollSize = 102400
agent1.sinks.sink1.hdfs.rollCount = 1000000
agent1.sinks.sink1.hdfs.rollInterval = 60
#agent1.sinks.sink1.hdfs.round = true
#agent1.sinks.sink1.hdfs.roundValue = 10
#agent1.sinks.sink1.hdfs.roundUnit = minute
agent1.sinks.sink1.hdfs.useLocalTimeStamp = true
# Use a channel which buffers events in memory
agent1.channels.channel1.type = memory
agent1.channels.channel1.keep-alive = 120
agent1.channels.channel1.capacity = 500000
agent1.channels.channel1.transactionCapacity = 600
# Bind the source and sink to the channel
agent1.sources.source1.channels = channel1
agent1.sinks.sink1.channel = channel1
其中 /home/hadoop/logs/flume/spooldir 目录要存在。
Channel 参数解释:
① capacity:默认该通道中最大的可以存储的 event 数量。
② trasactionCapacity:每次最大可以从 source 中拿到或者送到 sink 中的 event 数量。
③ keep-alive:event 添加到通道中或者移出的允许时间。
(4)启动:
bin/flume-ng agent -c conf -f agentconf/spooldir-hdfs.properties -n agent1 -Dflume.root.logger=INFO,console
(5)测试:
① 如果 HDFS 集群是高可用集群,那么必须要放入 core-site.xml 和 hdfs-site.xml 文件到 $FLUME_HOME/conf 目录中。
② 查看监控的 /home/hadoop/logs/flume/spooldir 文件夹中的文件是否被正确上传到 HDFS 上。
③ 在该目录中创建文件,或者从其他目录往该目录加入文件,验证是否新增的文件能被自动的上传到 HDFS 上。



5.2.2、采集文件中信息到 HDFS
(1)采集需求:比如业务系统使用 log4j 生成的日志,日志内容不断增加,需要把追加到日志文件中的数据实时采集到 HDFS 上。
根据需求,首先定义以下 3 大要素:
A、采集源,即 source ——> 监控文件内容更新:exec ‘tail -F file’。
B、下沉目标,即 sink ——> HDFS 文件系:hdfs sink。
C、Source 和 sink 之间的传递通道 ——> channel,可用 file channel 也可以用内存 channel。
(2)配置文件编写:tail-hdfs.properties.
# 定义三大组件的名称
agent1.sources = source1
agent1.sinks = sink1
agent1.channels = channel1
# Describe/configure tail -F source1
agent1.sources.source1.type = exec
agent1.sources.source1.command = tail -F /home/hadoop/logs/flume/catalina.out
agent1.sources.source1.channels = channel1
#configure host for source
agent1.sources.source1.interceptors = i1
agent1.sources.source1.interceptors.i1.type = host
agent1.sources.source1.interceptors.i1.hostHeader = hostname
# Describe sink1
agent1.sinks.sink1.type = hdfs
#a1.sinks.k1.channel = c1
agent1.sinks.sink1.hdfs.path =hdfs://myha01/logs/flume-event/%y-%m-%d/%H-%M
agent1.sinks.sink1.hdfs.filePrefix = tomcat_
agent1.sinks.sink1.hdfs.maxOpenFiles = 5000
agent1.sinks.sink1.hdfs.batchSize= 100
agent1.sinks.sink1.hdfs.fileType = DataStream
agent1.sinks.sink1.hdfs.writeFormat =Text
agent1.sinks.sink1.hdfs.rollSize = 102400
agent1.sinks.sink1.hdfs.rollCount = 1000000
agent1.sinks.sink1.hdfs.rollInterval = 60
agent1.sinks.sink1.hdfs.round = true
agent1.sinks.sink1.hdfs.roundValue = 10
agent1.sinks.sink1.hdfs.roundUnit = minute
agent1.sinks.sink1.hdfs.useLocalTimeStamp = true
# Use a channel which buffers events in memory
agent1.channels.channel1.type = memory
agent1.channels.channel1.keep-alive = 120
agent1.channels.channel1.capacity = 500000
agent1.channels.channel1.transactionCapacity = 600
# Bind the source and sink to the channel
agent1.sources.source1.channels = channel1
agent1.sinks.sink1.channel = channel1
(3)启动:
bin/flume-ng agent -c conf -f agentconf/tail-hdfs.properties -n agent1 -Dflume.root.logger=INFO,console
(4)测试:
① 模拟像指定的日志文件 /home/hadoop/logs/flume/catalina.out 中追加内容。
② 验证 HDFS 上的对应文件是否有新增内容。
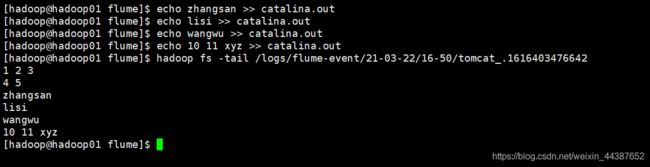
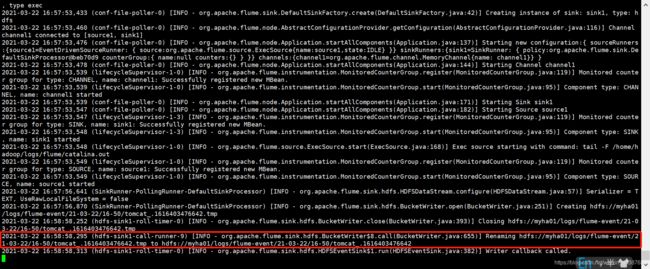
5.2.3、多 agent 串联采集
(1)分发 flume 到其它机器节点:
scp -r flume-1.8.0/ hadoop@hadoop02:~/apps
scp -r flume-1.8.0/ hadoop@hadoop03:~/apps
scp -r flume-1.8.0/ hadoop@hadoop04:~/apps
scp -r flume-1.8.0/ hadoop@hadoop05:~/apps
(2)架构设计:
从 hadoop05 的 flume agent 传送数据到 hadoop04 的 flume agent:

如现在我在两台机器上的测试,hadoop04 和 hadoop05 上面做 agent 的传递,分别是:
hadoop04:tail-avro.properties。
① 使用 exec “tail -F /home/hadoop/logs/flume/date.log” 获取采集数据。
② 使用 avro sink 数据到下一个 agent。
hadoop05:avro-hdfs.properties。
① 使用 avro 接收采集数据。
② 使用 hdfs sink 数据到目的地。
(3)准备 hadoop04:tail-avro.properties。
a1.sources = r1
a1.sinks = k1
a1.channels = c1
# Describe/configure the source
a1.sources.r1.type = exec
a1.sources.r1.command = tail -F /home/hadoop/logs/flume/date.log
a1.sources.r1.channels = c1
# Describe the sink
a1.sinks.k1.type = avro
a1.sinks.k1.channel = c1
a1.sinks.k1.hostname = hadoop05
a1.sinks.k1.port = 4141
a1.sinks.k1.batch-size = 2
# Use a channel which buffers events in memory
a1.channels.c1.type = memory
a1.channels.c1.capacity = 1000
a1.channels.c1.transactionCapacity = 100
# Bind the source and sink to the channel
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1
(4)准备 hadoop05:avro-hdfs.properties。
a1.sources = r1
a1.sinks = k1
a1.channels = c1
# Describe/configure the source
a1.sources.r1.type = avro
a1.sources.r1.channels = c1
a1.sources.r1.bind = 0.0.0.0
a1.sources.r1.port = 4141
# Describe k1
a1.sinks.k1.type = hdfs
a1.sinks.k1.hdfs.path =hdfs://myha01/logs/flume-event/%y-%m-%d/%H-%M
a1.sinks.k1.hdfs.filePrefix = date_
a1.sinks.k1.hdfs.maxOpenFiles = 5000
a1.sinks.k1.hdfs.batchSize= 100
a1.sinks.k1.hdfs.fileType = DataStream
a1.sinks.k1.hdfs.writeFormat =Text
a1.sinks.k1.hdfs.rollSize = 102400
a1.sinks.k1.hdfs.rollCount = 1000000
a1.sinks.k1.hdfs.rollInterval = 60
a1.sinks.k1.hdfs.round = true
a1.sinks.k1.hdfs.roundValue = 10
a1.sinks.k1.hdfs.roundUnit = minute
a1.sinks.k1.hdfs.useLocalTimeStamp = true
# Use a channel which buffers events in memory
a1.channels.c1.type = memory
a1.channels.c1.capacity = 1000
a1.channels.c1.transactionCapacity = 100
# Bind the source and sink to the channel
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1
(5)最终测试:
第 1 步测试:首先启动 hadoop05 机器上的 agent。
bin/flume-ng agent -c conf -n a1 -f agentconf/avro-hdfs.properties -Dflume.root.logger=INFO,console
第 2 步测试:再启动 hadoop04 上的 agent。
bin/flume-ng agent -c conf -n a1 -f agentconf/tail-avro.properties -Dflume.root.logger=INFO,console
第 3 步测试:执行一个普通的脚本 date.sh 往 hadoop04 的 /home/hadoop/logs/flume/date.log 中追加数据:
#!/bin/bash
for((x=0; x<=60; x++));
do
echo `date` >> /home/hadoop/logs/flume/date.log
sleep 1
done
第 4 步测试:至此会发现在 hadoop04 agent 发送的数据会转到 hadoop05 agent,然后被 sink 到了 HDFS 的对应目录 hdfs://myha01/logs/flume-event/ 下。


5.2.4、高可用部署采集
(1)Flume-NG 的高可用架构图:

图中,我们可以看出,Flume 的存储可以支持多种,这里只列举了 HDFS 和 Kafka(如:存储最新的一周日志,并给 Storm 系统提供实时日志流)。
(2)节点分配,Flume 的 Agent 和 Collector 分布如下表所示:
| 名称 | Host | 角色 |
|---|---|---|
| Agent1 | hadoop02 | 日志服务器 |
| Agent2 | hadoop03 | 日志服务器 |
| Agent3 | hadoop04 | 日志服务器 |
| Collector1 | hadoop04 | AgentMaster1 |
| Collector1 | hadoop05 | AgentMaster2 |
表中所示,Agent1,Agent2,Agent3 数据分别流入到 Collector1 和 Collector2,Flume NG 本身提供了 Failover 机制,可以自动切换和恢复。在上表中,有 3 个产生日志服务器分布在不同的机房,要把所有的日志都收集到一个集群中存储。下面我们开发配置 Flume NG 集群。
(3)配置信息,在下面单点 Flume 中,基本配置都完成了,我们只需要新添加两个配置文件,它们是 ha_agent.properties 和 ha_collector.properties,其配置内容如下所示:
ha_agent.properties 配置:
#agent name: agent1
agent1.channels = c1
agent1.sources = r1
agent1.sinks = k1 k2
#set gruop
agent1.sinkgroups = g1
#set channel
agent1.channels.c1.type = memory
agent1.channels.c1.capacity = 1000
agent1.channels.c1.transactionCapacity = 100
agent1.sources.r1.channels = c1
agent1.sources.r1.type = exec
agent1.sources.r1.command = tail -F /home/hadoop/logs/flume/testha.log
agent1.sources.r1.interceptors = i1 i2
agent1.sources.r1.interceptors.i1.type = static
agent1.sources.r1.interceptors.i1.key = Type
agent1.sources.r1.interceptors.i1.value = LOGIN
agent1.sources.r1.interceptors.i2.type = timestamp
# set sink1
agent1.sinks.k1.channel = c1
agent1.sinks.k1.type = avro
agent1.sinks.k1.hostname = hadoop04
agent1.sinks.k1.port = 52020
# set sink2
agent1.sinks.k2.channel = c1
agent1.sinks.k2.type = avro
agent1.sinks.k2.hostname = hadoop05
agent1.sinks.k2.port = 52020
#set sink group
agent1.sinkgroups.g1.sinks = k1 k2
#set failover
agent1.sinkgroups.g1.processor.type = failover
agent1.sinkgroups.g1.processor.priority.k1 = 10
agent1.sinkgroups.g1.processor.priority.k2 = 1
agent1.sinkgroups.g1.processor.maxpenalty = 10000
ha_collector.properties 配置:
#set agent name
a1.sources = r1
a1.channels = c1
a1.sinks = k1
#set channel
a1.channels.c1.type = memory
a1.channels.c1.capacity = 1000
a1.channels.c1.transactionCapacity = 100
# other node,nna to nns
a1.sources.r1.type = avro
# 当前主机为什么,就修改成什么主机名(复制一份到 hadoop05,注意修改)
a1.sources.r1.bind = hadoop04
a1.sources.r1.port = 52020
a1.sources.r1.interceptors = i1
a1.sources.r1.interceptors.i1.type = static
a1.sources.r1.interceptors.i1.key = Collector
# 当前主机为什么,就修改成什么主机名,(复制一份到 hadoop05,注意修改)
a1.sources.r1.interceptors.i1.value = hadoop04
a1.sources.r1.channels = c1
#set sink to hdfs
a1.sinks.k1.type=hdfs
a1.sinks.k1.hdfs.path= hdfs://myha01/logs/flume_ha/loghdfs
a1.sinks.k1.hdfs.fileType=DataStream
a1.sinks.k1.hdfs.writeFormat=TEXT
a1.sinks.k1.hdfs.rollInterval=10
a1.sinks.k1.channel=c1
a1.sinks.k1.hdfs.filePrefix=%Y-%m-%d
注意:在把 ha_collector.properties 文件拷贝到另外一台 collector 的时候,记得更改该配置文件中的主机名。在该配置文件中有注释。
(4)启动:先启动 hadoop04 和 hadoop05 上的 collector 角色:
bin/flume-ng agent -c conf -f agentconf/ha_collector.properties -n a1 -Dflume.root.logger=INFO,console
然后启动 hadoop02,hadoop03,hadoop04 上的 agent 角色:
bin/flume-ng agent -c conf -f agentconf/ha_agent.properties -n agent1 -Dflume.root.logger=INFO,console
5.2.5、更多 Source 和 Sink 组件
(1)更多 Sources:http://flume.apache.org/FlumeUserGuide.html#flume-sources
(2)更多 Channels:http://flume.apache.org/FlumeUserGuide.html#flume-channels
(3)更多 Sinks:http://flume.apache.org/FlumeUserGuide.html#flume-sinks
6、综合案例
6.1、案例场景/需求
A、B 两台日志服务机器实时生产日志主要类型为 access.log、nginx.log、web.log。
现在要求:
把 A、B 机器中的 access.log、nginx.log、web.log 采集汇总到 C 机器上然后统一收集到 hdfs 中。
但是在 hdfs 中要求的目录为:
/source/logs/access/20210323/**
/source/logs/nginx/20210323/**
/source/logs/web/20210323/**
6.2、场景分析

6.3、数据处理流程分析
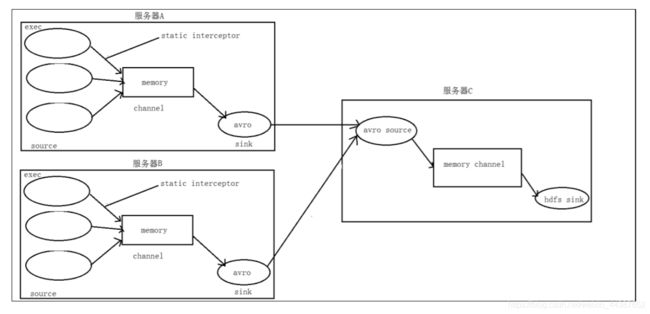
6.4、需求实现
(1)准备 3 台服务器:
服务器 A 对应的 IP 为 192.168.123.103,主机名为 hadoop03;
服务器 B 对应的 IP 为 192.168.123.104,主机名为 hadoop04;
服务器 C 对应的 IP 为 192.168.123.105,主机名为 hadoop05。
(2)设计采集方案 exec_source_avro_sink.properties:
在服务器 hadoop03 和服务器 hadoop04 上的 $FLUME_HOME/agentconf 创建采集方案的配置文件 exec_source_avro_sink.properties,文件内容为:
# 指定各个核心组件
a1.sources = r1 r2 r3
a1.sinks = k1
a1.channels = c1
# 准备数据源
## static 拦截器的功能就是往采集到的数据的 header 中插入自己定义的 key-value 对
a1.sources.r1.type = exec
a1.sources.r1.command = tail -F /home/hadoop/flume_data/access.log
a1.sources.r1.interceptors = i1
a1.sources.r1.interceptors.i1.type = static
a1.sources.r1.interceptors.i1.key = type
a1.sources.r1.interceptors.i1.value = access
a1.sources.r2.type = exec
a1.sources.r2.command = tail -F /home/hadoop/flume_data/nginx.log
a1.sources.r2.interceptors = i2
a1.sources.r2.interceptors.i2.type = static
a1.sources.r2.interceptors.i2.key = type
a1.sources.r2.interceptors.i2.value = nginx
a1.sources.r3.type = exec
a1.sources.r3.command = tail -F /home/hadoop/flume_data/web.log
a1.sources.r3.interceptors = i3
a1.sources.r3.interceptors.i3.type = static
a1.sources.r3.interceptors.i3.key = type
a1.sources.r3.interceptors.i3.value = web
# Describe the sink
a1.sinks.k1.type = avro
a1.sinks.k1.hostname = hadoop05
a1.sinks.k1.port = 41414
# Use a channel which buffers events in memory
a1.channels.c1.type = memory
a1.channels.c1.capacity = 20000
a1.channels.c1.transactionCapacity = 10000
# Bind the source and sink to the channel
a1.sources.r1.channels = c1
a1.sources.r2.channels = c1
a1.sources.r3.channels = c1
a1.sinks.k1.channel = c1
(3)准备 avro_source_hdfs_sink.properties 配置文件:
在服务器 C 上的 $FLUME_HOME/agentconf 中创建配置文件 avro_source_hdfs_sink.properties,文件内容为:
#定义 agent 名, source、channel、sink 的名称
a1.sources = r1
a1.sinks = k1
a1.channels = c1
#定义 source
a1.sources.r1.type = avro
a1.sources.r1.bind = 0.0.0.0
a1.sources.r1.port =41414
#添加时间拦截器
a1.sources.r1.interceptors = i1
a1.sources.r1.interceptors.i1.type=org.apache.flume.interceptor.TimestampInterceptor$Builder
#定义 channels
a1.channels.c1.type = memory
a1.channels.c1.capacity = 20000
a1.channels.c1.transactionCapacity = 10000
#定义 sink
a1.sinks.k1.type = hdfs
a1.sinks.k1.hdfs.path=hdfs://myha01/source/logs/%{type}/%Y%m%d
a1.sinks.k1.hdfs.filePrefix =events
a1.sinks.k1.hdfs.fileType = DataStream
a1.sinks.k1.hdfs.writeFormat = Text
#时间类型
a1.sinks.k1.hdfs.useLocalTimeStamp = true
#生成的文件不按条数生成
a1.sinks.k1.hdfs.rollCount = 0
#生成的文件按时间生成
a1.sinks.k1.hdfs.rollInterval = 30
#生成的文件按大小生成
a1.sinks.k1.hdfs.rollSize = 10485760
#批量写入 hdfs 的个数
a1.sinks.k1.hdfs.batchSize = 20
#flume 操作 hdfs 的线程数(包括新建,写入等)
a1.sinks.k1.hdfs.threadsPoolSize=10
#操作 hdfs 超时时间
a1.sinks.k1.hdfs.callTimeout=30000
#组装 source、channel、sink
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1
(4)启动:
配置完成之后,在服务器 A 和 B 上的 /home/hadoop/data 有数据文件 access.log、nginx.log、web.log。
先启动服务器 C(hadoop05)上的 flume,启动命令:在 flume 安装目录下执行:
bin/flume-ng agent -c conf -f agentconf/avro_source_hdfs_sink.properties -name a1 -Dflume.root.logger=DEBUG,console
然后在启动服务器上的 A(hadoop03)和 B(hadoop04),启动命令:在 flume 安装目录下执行:
bin/flume-ng agent -c conf -f agentconf/exec_source_avro_sink.properties -name a1 -Dflume.root.logger=DEBUG,console
(5)测试:
自行测试。