剖析linux高性能服务器框架核心—reactor设计模式
linux服务器开发相关视频解析:
linux多线程之epoll原理剖析与reactor原理及应用
详解线程池的组成与用途,手把手带你实现线程池
c/c++ linux服务器开发免费学习地址:c/c++ linux后台服务器高级架构师
Reactor
Reactor设计模式,又名反应堆模型,顾名思义就是服务器阻塞等待事件发生,只有当事件发生了,才能反应过来,该处理哪些事件。那么在这个模型中谁来扮演阻塞等待的角色呢?
epoll_wait
在Linux中一般是基于 epoll_wait 函数进行封装,然后将 epoll_wait 放在一个 while 循环中(这个循环一般叫事件循环),由 epoll_wait 阻塞等待事件的发生。因此,一个简陋版本的事件循环结构如下:
void loop() {
quit_ = true;
while(quit_) {
int numevents = epoll_wait(efd, &events, maxEvents, timeout); // 阻塞等待事件发生
handle_event(events, numevents); // 处理事件
}
quit_ = false;
}
在每轮循环中,都会先阻塞在epoll_wait 处:
- 如果之前通过 epoll_ctl 函数在 efd 上注册的事件,都没有触发,则 epoll_wait 函数最多阻塞 timeout 毫秒;
- 否则,在 timeout毫秒内,有事件触发,则epoll_wait函数立即唤醒,程序进入handle_events函数中,对触发的事件进行逐一处理。
现在,我们先观察上面这个最初始的简陋版本,它存在哪些问题?
主要以下两点:
1、timeout:怎么确定epoll_wait函数要阻塞的时间值timeout?设置一个合理的timeout值是很有必要的:
- 阻塞时间过长,使得服务器闲置,是对资源的极大浪费;
- 直接将timeout的值设置为0(不是NULL),即完全不阻塞,此时如果没有事件到来,则epoll_wait函数立即返回。如果恰好在某个时间段内又没有事件触发,那么服务器就一直忙于空循环(busy
loop),做无用功。
2、handle_event:怎么合理的处理事件,而不阻塞 loop 的运行?如果触发的事件events中,存在耗时、慢速IO等任务,那么就极其容易导致整个服务器阻塞在此:
- events中后续的事件无法得到及时处理;
- 对于新的事件,服务器又无法及时响应。
因此,如果无法有效处理epoll_wait监听到的事件,那么整个服务器的性能就谈不上高性能,效率就会变得低下。
解决了这两个问题,整个服务器框架才能建立起来,才具有高性能的基础。
下面,从这两个方面进行讲解。
timeout
在一个完整的服务器框架中,一般都会有定时器任务,即按照某一个固定的周期频率执行的任务,比如PING任务,具体怎么设计定时器留到下一期进行讲解。
因此,设置 timeout 值有如下两步:
- 先获取距离当前时间curr 最近的定时任务要触发的绝对时间shortest;
- 然后将这个时间差shortest - curr作为timeout。
那么就能保证:
- 即使 epoll_wait 没有监听到任何事件,epoll_wait 至多阻塞 timeout
毫秒,timeout毫秒后,就能立即去执行最近的定时任务,此时最近的那个定时任务刚好触发了; - 如果在timeout毫秒内,epoll_wait监听到了事件,那么就可以在handle_events函数中处理,然后再去执行定时器任务。
此时,你可能在想,服务器在handle_events函数中处理完事件后,当前时间很有可能已经超过定时器任务设定的触发时间,那定时器任务不就不准了吗?
其实啊,在服务器里,这个定时器任务没有严格准时要求,不是说设定1s执行一次PING就必须1s执行PING,延迟一点也没有关系的。
但是如果延迟太多,就要考虑重新设计handle_events机制了,这个后文再说。
此时,loop函数可以变更如下:
void loop() {
quit_ = true;
while(quit_) {
int timeout = next_timer_timeout(); // 获取最近的定时任务距离当前的时间差
int numevents = epoll_wait(efd, &events, maxEvents, timeout);
handle_event(events, numevents); // 处理监听到的任务
handle_timer_events(); // 处理定时器任务
}
quit_ = false;
}
可能你还有疑问,要是服务器中恰好就没有定时器任务呢?那 timeout 值该设置为多少?
先不回答这个问题,我们来看看redis是怎么设置timeout值的。
【文章福利】需要C/C++ Linux服务器架构师学习资料加群812855908(资料包括C/C++,Linux,golang技术,Nginx,ZeroMQ,MySQL,Redis,fastdfs,MongoDB,ZK,流媒体,CDN,P2P,K8S,Docker,TCP/IP,协程,DPDK,ffmpeg等)

redis的timeout计算方式分析
下面以redis为例,来看下redis是怎么计算timeout的。
这部分是在aeProcessEvents函数中,本文仅查看aeProcessEvents函数中关于计算timeout值的部分,其余的留到redis源码分析部分再写。其中,timeout 即程序中的tvp变量。
整个计算步骤整理如下:
1、 如果redis中存在定时任务,则 shortest 值是定时任务最早触发的绝对时间,然后基于shortest计算出
timeout值,即代码中的tvp。
2、如果shortest值是NULL,那么就是没有定时器任务。
此时,又回到上面提出那个疑问:没有定时任务时,timeout的值该怎么计算?
在redis中,如果没有设置定时任务:
- 如果flags中没有设置AE_DONT_WAIT标志,那么redis将会一直阻塞在epoll_wait处,等待事件发生,此时tvp=NULL。
- 否则,flags中存在AE_DONT_WAIT标志位,说明调用者希望在没有任务时也不阻塞,那么tvp的值就设置为0(不是NULL),即不阻塞。
3、执行epoll_wait
4、执行触发事件
5、执行定时事件
总结来说,redis中设置了一个AE_DONT_WAIT标志位,由aeProcessEvents调用者来决定调用aeProcessEvents函数时,如果没有事件时是否阻塞。
而且 AE_DONT_WAIT标志位的优先级最高:如果设置了AE_DONT_WAIT标志,即使有定时器任务,timeout的值也是0,而不是上述的时间差。
aeProcessEvents函数整理后如下:
int aeProcessEvents(aeEventLoop *eventLoop, int flags) {
int processed = 0, numevents;
//...
if (eventLoop->maxfd != -1 || ((flags & AE_TIME_EVENTS) && !(flags & AE_DONT_WAIT))) {
/***** 下面开始计算timeout *****/
int j;
aeTimeEvent* shortest = NULL; // 最早触发的定时器任务的绝对时间
struct timeval tv, *tvp;
// 存在定时器任务,并且没有设置 AE_DONT_WAIT 标志位
// 则获取 shortest 值
if (flags & AE_TIME_EVENTS && !(flags & AE_DONT_WAIT))
shortest = aeSearchNearestTimer(eventLoop);
if (shortest) {
/***** 1. 存在定时任务,则下面计算timeout的值 *****/
long now_sec, now_ms;
aeGetTime(&now_sec, &now_ms);
tvp = &tv;
// 最近超时的时间转为毫秒单位
long long ms = (shortest->when_sec - now_sec)*1000 + shortest->when_ms - now_ms;
if (ms > 0) {
tvp->tv_sec = ms/1000;
tvp->tv_usec = (ms % 1000)*1000;
} else {
tvp->tv_sec = 0;
tvp->tv_usec = 0;
}
}
else {
/***** 2. 没有定时任务,取取决于 AE_DONT_WAIT 标志位 *****/
if (flags & AE_DONT_WAIT) {
// 不要阻塞,则设置超时时间为0
tv.tv_sec = tv.tv_usec = 0;
tvp = &tv;
}
else {
// 没有可触发事件,则一直阻塞等待
tvp = NULL;
}
}
// 再次确认下:
// 即使有定时任务,但是设置了 AE_DONT_WAIT 标志位
// 阻塞时间也都设置为0
if (eventLoop->flags & AE_DONT_WAIT) {
tv.tv_sec = tv.tv_usec = 0;
tvp = &tv;
}
// 执行epoll_wait之前,执行一些任务
if (eventLoop->beforesleep != NULL && flags & AE_CALL_BEFORE_SLEEP)
eventLoop->beforesleep(eventLoop);
/***** 3. aeApiPoll 是 epoll_wait 封装 *****/
numevents = aeApiPoll(eventLoop, tvp);
if (eventLoop->aftersleep != NULL && flags & AE_CALL_AFTER_SLEEP)
eventLoop->aftersleep(eventLoop);
/***** 4. 逐个处理触发的事件 *****/
for (j = 0; j < numevents; j++) {
//...
}
}
/***** 5. 可以去处理时间事件了 *****/
if (flags & AE_TIME_EVENTS)
processed += processTimeEvents(eventLoop);
return processed;
}
到此,相信你对上面的疑问已经有了答案,并且也知道应该怎么设置timeout的值了。
如果你去看看muduo的设计,会发现muduo设计的是一个固定值:
const int kPollTimeMs = 10000;
这个和muduo设计有关,这个在下一期讲解定时器的设计时会再提及。
反观libuv的loop设计,大体思路和redis保持一致:
//in src/unix/core.c
int uv_run(uv_loop_t* loop, uv_run_mode mode) {
int timeout;
//...
while (r != 0 && loop->stop_flag == 0) {
//...
timeout = 0;
if ((mode == UV_RUN_ONCE && !ran_pending) || mode == UV_RUN_DEFAULT)
timeout = uv_backend_timeout(loop); // 计算 timeout
uv__io_poll(loop, timeout); // 基于epoll_wait封装
//...
}
//...
}
好了,到此,大致讲解清楚timeout 的设计思路,下面讲解另一个问题。
handle_event
当epoll_wait监听到事件发生时, 在handle_event 函数中的处理方式,大致如下:
for (j = 0; j < numevents; j++) {
handle_every_thing(events[j]);// 依次对每个事件进行处理
}
很自然,如果某个事件events[j]是个耗时、慢速IO等类型的任务,会导致后续任务无法及时处理,甚至无法及时响应即将到来的任务。
毫无疑问,应对这种问题,最直接就想到了线程池。
One Loop + ThreadPool
这里就自然想到了引入一个线程池,使用多线程来处理这些触发的事件events,此时是 One Loop + ThreadPool 模型。
什么意思呢?
主线程,即epoll_wait存在的线程,属于IO线程,只负责监听读写事件的到来,当epoll_wait结束后,就把触发的读写事件,分发到ThreadPool中,让子线程去执行。
REDIS-6.0中引入的多线程其实就是引入了这么一个线程池。当然,REDIS-6.0的线程池在设计上也有诸多细节考量,这个以后在分析REDIS源码时再细讲。
在 One Loop + ThreadPool 模型下,主线程负责两件事:
- 监听新的客户端连接请求(可读事件);
- 与已连接客户之间进行读写事件。
主线程,通过轮询的方式,将到来的任务尽可能均匀的分配给每个线程。当然,不同的实现在细节上考虑可能不同。
这里又有两个问题:
- 如果主线程负责以上两个任务,高并发下,可能会导致主线程应接不暇,那怎么办?
- 如果ThreadPool中充斥着大量的耗时、慢速等类型任务,使得新任务还是无法及时处理,怎么办?
下面,针对这两个问题再探讨下。
One Loop One Thread + ThreadPool
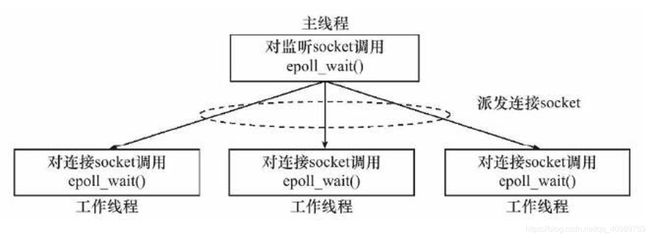
针对问题【1】,也很简单,设置多个eventloop线程,即每个eventloop线程中都设置一个epoll_wait函数。此时服务器的模型就变更为:One Loop One Thread + ThreadPoold。其设计如下:
- 主线程main-eventloop,只负责监听客户端的连接请求(可读事件)。监听到了,就把这个可读事件的处理分发给子线程
sub-eventloop; - 子线程sub-eventloop,负责建立与客户端的建立连接、读写通讯以及结束与客户端的连接等任务。
这样,就把任务划分好了,即原来一个主线程完成的任务被划分为多个线程分工协调完成,使得整个服务器就都变得高效:
- main-eventloop线程,只负责监听客户端的连接请求,而不处理其他任务,因此就能继续接受新客户端的连接请求,并把与客户端建立连接及其后续任务都分发到sub-eventloop中完成;
- sub-eventloop 线程,负责与本线程中的客户端进行通讯(即读写事件)、管理它们的生命周期,而对于那些耗时、慢速等任务,可以交给ThreadPool完成。
因此,这样就各司其职,有默契的完成任务,能更好地应对高并发,同时这也是muduo的设计架构,如下图所示:
ThreadPool
针对问题【2】,在讨论之前啊,先考虑下线程池的应用场景。
面对高并发、任务执行时间短的场景,使用线程池可以降低频繁创建、销毁线程带来的开销,一个任务执行完毕就可以迅速去执行其他任务。
但是,如果当前线程池中充斥着大量的耗时、慢速等任务类型时,线程池也不管用了。因为,线程全都用于去执行这类任务,对于新的任务就无法执行了,即使新任务耗时很短。
既然如此,那么我可不可以限制线程池中用于执行耗时任务的线程数? 超过某个阈值,就不再为慢速任务分配线程,反正是慢速任务,少几个线程,慢一点就慢一点,影响也不大。
libuv就是这么实现的,下面介绍下我从libuv中学习来的处理技巧。
libuv,将线程池中运行的任务分成三种:
enum uv__work_kind {
UV__WORK_CPU, // CPU 密集型,耗时长
UV__WORK_FAST_IO, // IO 快速型
UV__WORK_SLOW_IO // 慢速 IO 型,耗时长
};
使用者,肯定清楚自己要提交到线程池中的任务属于什么类型,那么使用者就可以根据不同的任务类型,使用不同的函数将任务提交到线程池中。
/* 提交非 cpu 密集型任务
* 即:UV__WORK_FAST_IO 和 UV__WORK_SLOW_IO 任务类型
*/
void uv__work_submit(uv_loop_t* loop,
struct uv__work* w,
enum uv__work_kind kind,
void (*work)(struct uv__work* w),
void (*done)(struct uv__work* w, int status)) {
uv_once(&once, init_once);
w->loop = loop; // w->lopp 提交到指定的 loop 中
w->work = work; // 线程池要执行的函数
w->done = done; // 通知主线程要执行的函数
post(&w->wq, kind); // 将任务提交到任务队列中
}
/*
* 提交的是 CPU 密集型任务
*/
int uv_queue_work(uv_loop_t* loop,
uv_work_t* req,
uv_work_cb work_cb,
uv_after_work_cb after_work_cb) {
if (work_cb == NULL)
return UV_EINVAL;
///设置请求的类型是 UV_WORK, loop 的活跃请求+1
uv__req_init(loop, req, UV_WORK);
req->loop = loop;
req->work_cb = work_cb;
req->after_work_cb = after_work_cb;
// 提交任务到线程池,让其执行
// 类型是CPU密集型
uv__work_submit(loop,
&req->work_req,
UV__WORK_CPU, // CPU密集型任务
uv__queue_work,
uv__queue_done);
return 0;
}
在线程池中执行任务时,一个线程会被阻塞,有以下两种可能:
- 当前任务队列是空的:此时没有任务可执行,线程就没有运行的必要,就进入阻塞休眠状态;
- 如果发现当前任务队列中,慢速任务占比超过阈值(默认50%),则阻塞当前线程,即不再为慢速任务分配线程。
因此,通过这种方式,来阻止慢速IO任务充满了线程池,使线程池仍有裕量,能继续积极响应高并发事件。
当然,libuv里面还有一些设计细节,比如,如果新到来的任务仍然是慢速任务怎么办?
libuv是仍然将其放到任务队列中,继续进入阻塞。更多设计细节,可自行学习libuv源码。
下面是判断一个线程是否需要阻塞的部分:
// libuv/src/threadpool.c
while (QUEUE_EMPTY(&wq) ||
(QUEUE_HEAD(&wq) == &run_slow_work_message &&
QUEUE_NEXT(&run_slow_work_message) == &wq &&
slow_io_work_running >= slow_work_thread_threshold())) {
idle_threads += 1;
// 整个线程池只有这里是等待
// 来一个新任务,空闲线程减少1
uv_cond_wait(&cond, &mutex);
idle_threads -= 1;
}
到此,服务器框架的基本架构部分讲解完毕。