寒假学习Day 2:Python数据分析
寒假学习Day 2:Python数据分析
今天主要是进行了python数据分析的相关学习,以2020年美赛C题的数据为着手点进行了实际操作
2020年美赛C题题目+翻译https://blog.csdn.net/qq_41618424/article/details/104690600?ops_request_misc=%257B%2522request%255Fid%2522%253A%2522161120225416780265452554%2522%252C%2522scm%2522%253A%252220140713.130102334…%2522%257D&request_id=161120225416780265452554&biz_id=0&utm_medium=distribute.pc_search_result.none-task-blog-2allsobaiduend~default-2-104690600.first_rank_v2_pc_rank_v29&utm_term=2020%E5%B9%B4%E7%BE%8E%E8%B5%9BC%E9%A2%98&spm=1018.2226.3001.4187
用到的库
import pandas as pd
from pandas import DataFrame
import matplotlib.pyplot as plt
import numpy as np
import sys
import time
import hmac
import jieba
import json
import uuid
import base64
import urllib
import random
import hashlib
import requests
import datetime
import http.client
import urllib.parse
import urllib.request
from imp import reload
import csv
import re
import seaborn as sns
import matplotlib.pyplot as plt
from wordcloud import WordCloud
from imageio import imread
from IPython.display import Image
from IPython import display
import imageio
导入数据
这个题的数据一共有三个,分别是吹风机,微波炉和奶嘴,这里我选择试试微波炉的数据
data=pd.read_csv('microwave.tsv',sep='\t')
data
一共得到了1615行,15列数据
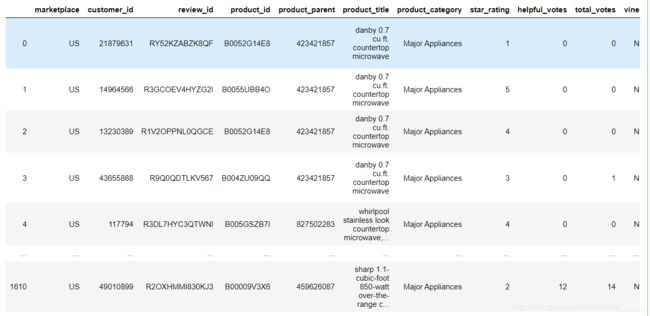
分析数据的列标签分别都是什么
| 列标签 | 含义 |
|---|---|
| marketplace | 超市地址,应该都是US |
| customer_id | 消费者id |
| review_id | 评价id |
| product_id | 产品id |
| product_parent | 产品专利权 |
| product_title | 产品标题 |
| product_category | 产品类别 |
| star_rating | 星级 |
| helpful_votes | 帮助评分 |
| total_votes | 总共的选票 |
| vine | 藤(?) |
| verified_purchase | 确认购买 |
| review_headline | 评论标题 |
| review_body | 评论主体 |
| review_date | 评论时间 |
问题一
Analyze the three product data sets provided to identify, describe, and support with mathematical evidence, meaningful quantitative and/or qualitative patterns, relationships, measures, and parameters within and between star ratings, reviews, and helpfulness ratings that will help Sunshine Company succeed in their three new online marketplace product offerings.
这段文字,直接用机翻翻译出来的句子非常拗口且难懂,我自己看了很多遍还是感觉很莫名其妙,后来求助了英语比较好的同学之后大概明白了一些,应该是需要对题中所给的数据中的star ratings,reviews,helpfulness ratings 进行相关分析,最后得到产品上线后取得成功的概率。
产品的reviews都是文字,这需要情感分析,所以我决定最后再分析这一块的影响,先分析start rating
先把整个数据里的start_rating画出来瞧瞧
plt.rcParams['font.sans-serif'] = ['KaiTi']#设置字体防止乱码
plt.rcParams['font.serif'] = ['KaiTi']
need= ['marketplace','star_rating','product_id']
data2= data[need]#获取需要的数据
regions = set(data2['marketplace'])#获取所有区域名称
for item in regions:#分别获取一个区域内的所有产品信息
plt.figure()#画图
d= data2[data2['marketplace'] == item]
sns.barplot(d['product_id'],d['star_rating'])
plt.xticks(rotation='vertical')#设置横坐标数据方向
plt.ylabel("star_rating")
plt.xlabel("product_id")
plt.title('{} is star_rating '.format(item))
plt.savefig(f"{item}is star_rating.png")#保存图片
plt.show()#图片展示
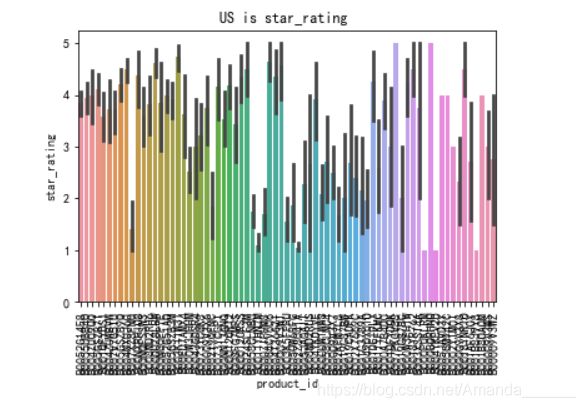
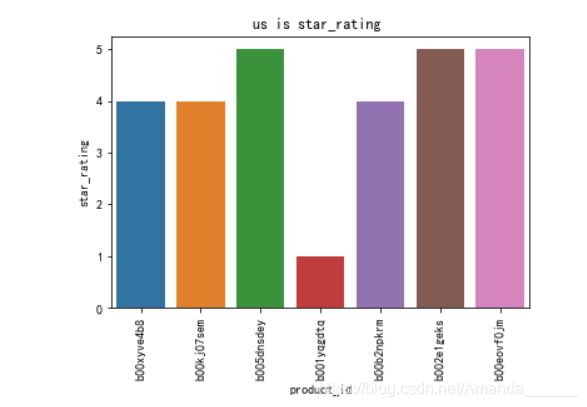
可以看出 数据非常多
接下来打算统计star rating 分别为1,2,3 ,4 ,5的占比如何
count = data.loc[:, 'star_rating'].value_counts()
print(count)

将数据化成饼状图
labels=['1','2','3','4','5']
sizes=[402,112,134,300,667]
plt.figure()#画饼图
explode =[0.05,0,0,0,0,0,0,0,0,0]
patches,l_text,p_text = plt.pie(x=sizes,labels=labels,autopct='%1.f%%')
plt.axis('equal')
for t in l_text:#设置字符尺寸
t.set_size = 130
for t in p_text:
t.set_size = 120
plt.legend(loc='upper left',bbox_to_anchor=(-0.1, 1))#设置图标位置
plt.savefig("star_rating.png")#保存图片
plt.grid()
plt.show()
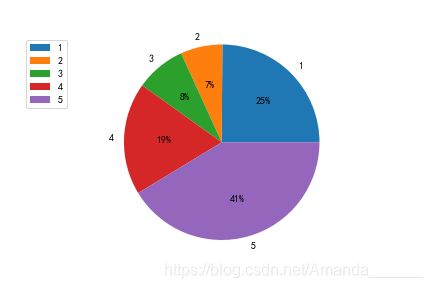
然而画出来之后还是感觉很茫然
突然想到分析两个及两个以上变量之间的关系可以用回归分析,就想到了决策树的回归树,决定先把reviews,helpfulness ratings不太好分析的数据转化成好分析的数据
由于今天太晚了,这段数据分析明天再分析吧
先画个词云看看 review_headline
yuni=''
data1=data['review_headline']
for i in range(1615):
data1=str(data1)
s_list=list(jieba.cut(data1))
for i in s_list:
yuni+=i+' '
cloud=WordCloud(background_color='white',max_words=200,font_path='C:\Windows\Fonts\simfang.ttf',max_font_size=100).generate(yuni)
plt.imshow(cloud,interpolation="bilinear")
plt.axis('off')
plt.show()
cloud.to_file('review.png')#保存图片

再看看review_body
yuni=''
data1=data['review_body']
for i in range(1615):
data1=str(data1)
s_list=list(jieba.cut(data1))
for i in s_list:
yuni+=i+' '
cloud=WordCloud(background_color='white',max_words=200,font_path='C:\Windows\Fonts\simfang.ttf',max_font_size=100).generate(yuni)
plt.imshow(cloud,interpolation="bilinear")
plt.axis('off')
plt.show()
cloud.to_file('review.png')#保存图片
