Selenium获取动态图片验证码
关于图片验证码的文章,我想大家都有一定的了解了。
在我们做UI自动化的时候,经常会遇到图片验证码的问题。

当开发不给咱们提供万能验证码,或者测试第三方网站比如知乎的时候,我们就需要自己去识别验证码。
OCR
OCR是一种图像文字识别的技术,例如图中的验证码,我们用肉眼识别就是c5s3,但机器可不比咱们肉眼。所以我们要利用ocr技术,让我们的Python脚本自动通过图片识别出对应的文字。
常见的识别类库
在Python中其实有许多识别类库,这里只介绍博主自己实践过的成功率还不错的: 百度ocr。
简单的说,就是百度提供了一个SDK,让我们传入图片数据,从而拿到识别的结果。ocr的细节我们不需要关心。
申请开通OCR
首先我们得有一个百度账号,这个相信大家都有,没有的可以申请一个。
·登录百度控制台
进入https://login.bce.baidu.com/并登录。
· 选择文字识别
左上角展开->产品服务->文字识别
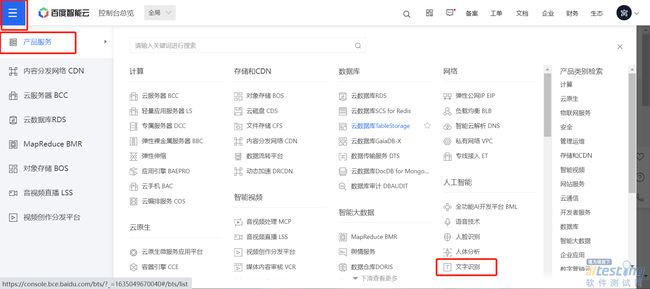
· 创建应用
点击创建应用按钮
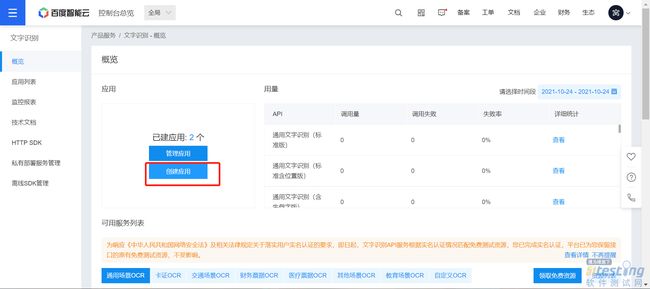
·填写相关应用信息
简单描述下应用是干嘛的就行,因为我们只需要识别文字,所以其他也不用勾上。

创建好了之后可以看到具体的应用信息,记住这3个关键信息。待会会用到。
·appid
· apikey
· secret key
熟悉OCR文档
官方文档地址: https://cloud.baidu.com/doc/OCR/s/wkibizyjk
文档会写的比较清楚,简单的说就是通过你的appid,api key和secret key获取一个client,接着你就可以调用client的api去获取图片中的文字了。官方的SDK还是比较贴心的。
· 安装SDK
pip install baidu-aip
讲完了文字怎么识别,接着就来说说标题中的动态图片验证码。
动态图片验证码
这个概念是我自己命名的,一般来说,我们的一张图片都是对应唯一一个url的,比如:
https://yuque.com?image=dshqadiau
(这个地址是我编的)
一般来说image字段的值不同,图片也就不同,都是一串随机的或者规律的不重复数据,确保图片不会重复。
但是博主最近遇到了这样一种情况:
输入一个url,每次输入,拿到的图片都不一样。
这样就会带来一个很严重的问题,页面上你虽然读取了图片的信息。我们把图片的url传递给百度sdk的时候,url由于再次调用,导致图片发生了变化。
比如网站上显示的是: c5s3,调用百度sdk的时候,百度会通过url读取图片,但再次读取,图片可能变成了lfew。
不信大家可以看看这个图片地址:
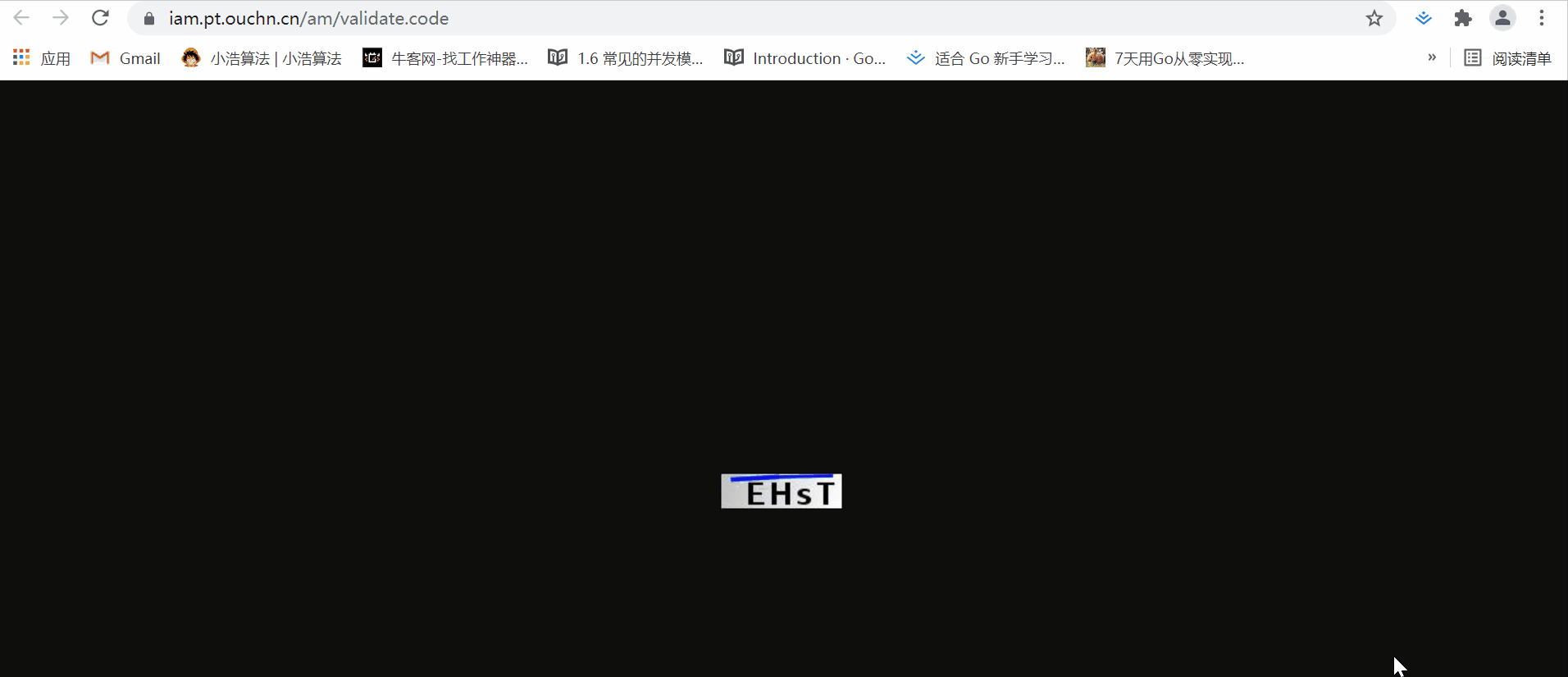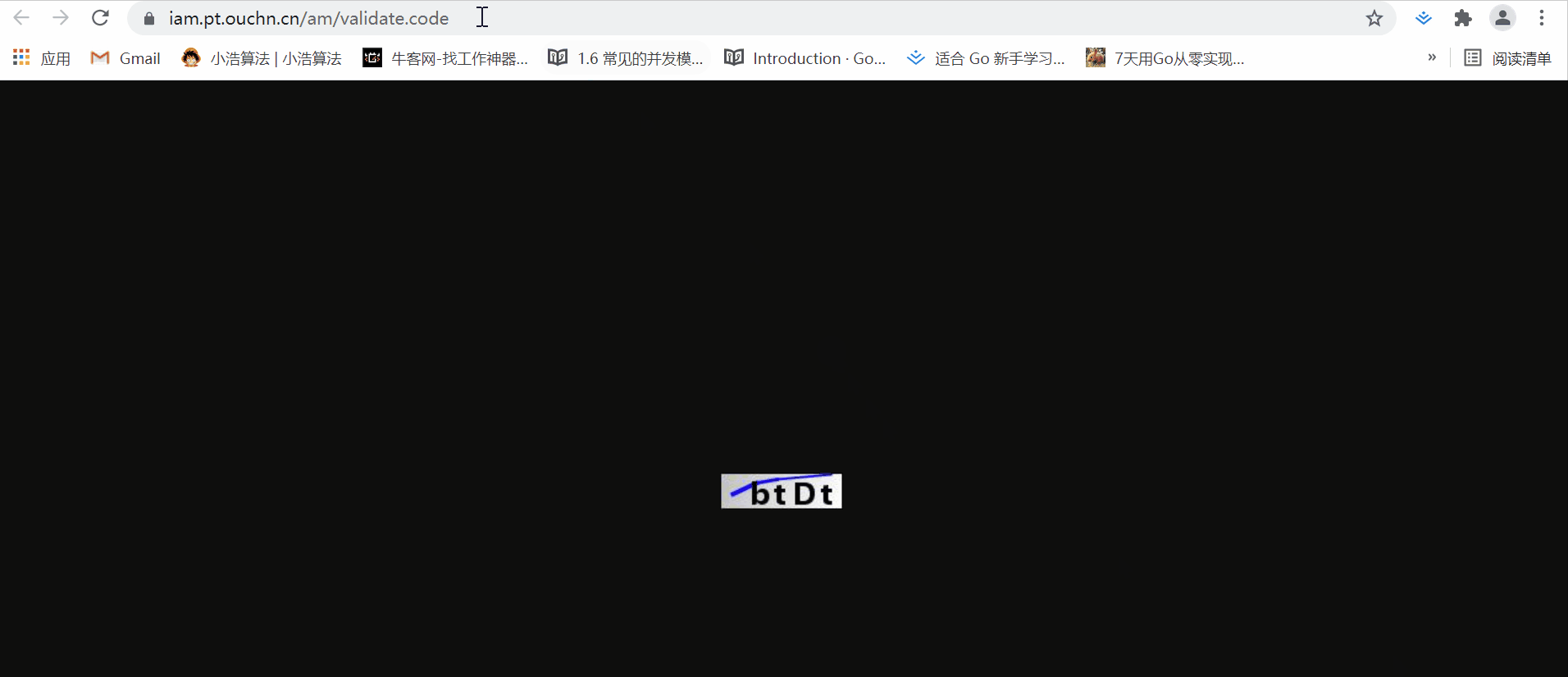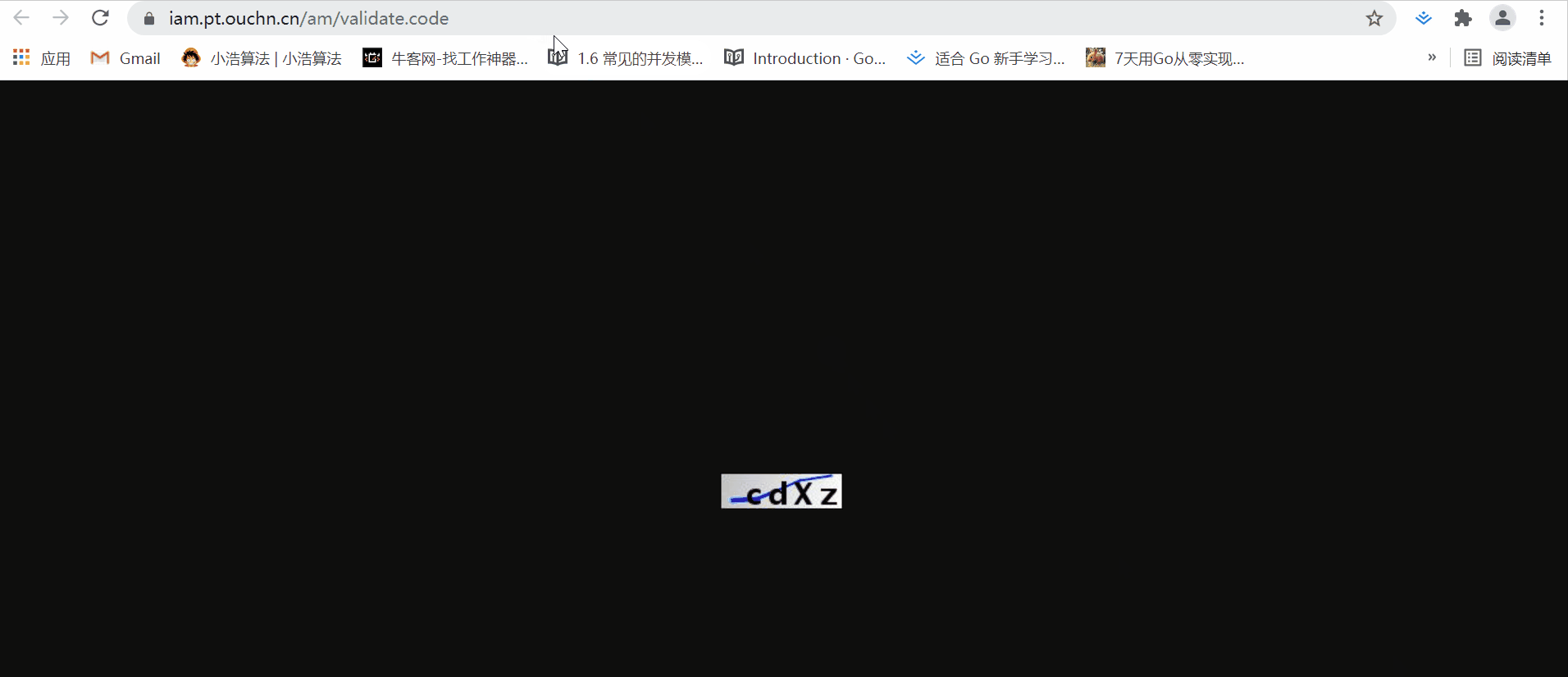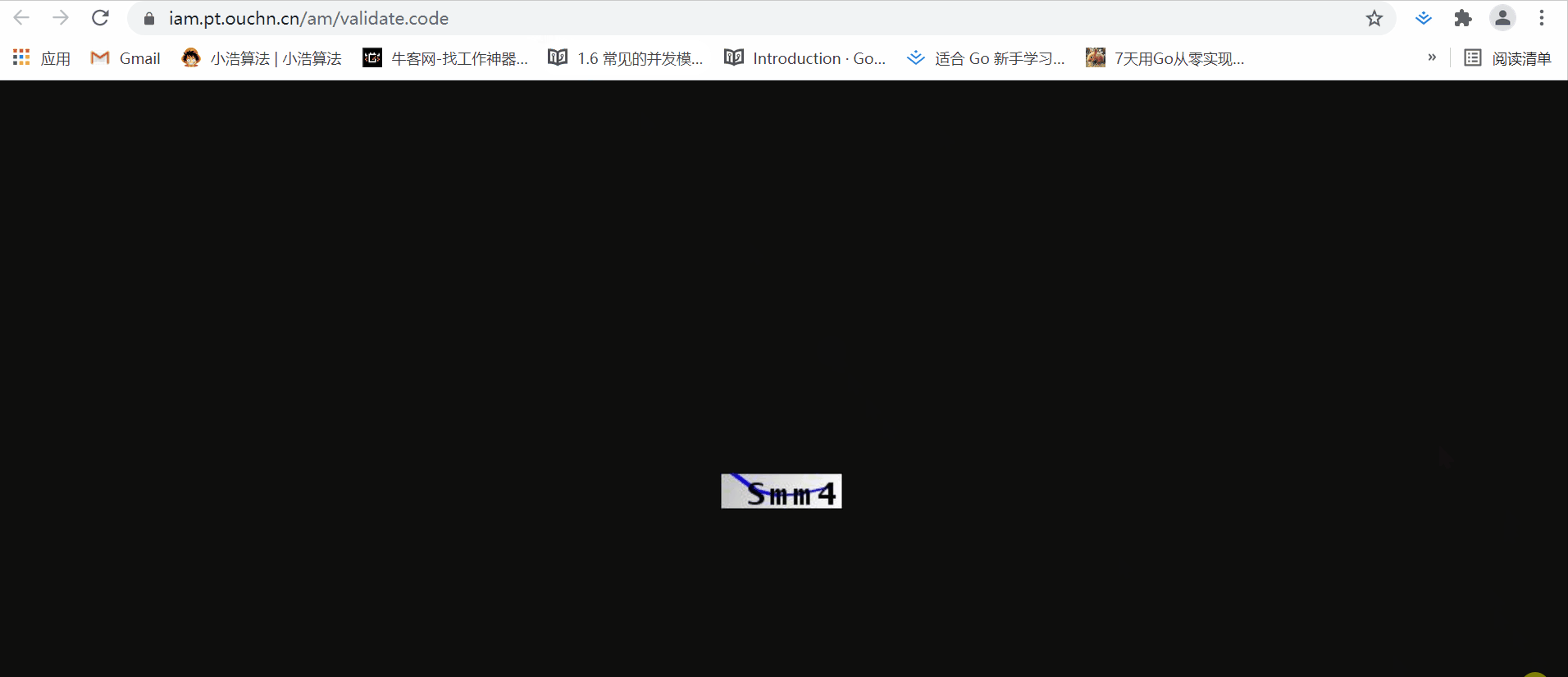
每次刷新,这个图片都会变,但是url不变。
怎么解决呢?
好在百度sdk,他不仅仅支持url,还支持图片文件和base64的图片数据。我们看看官方文档:
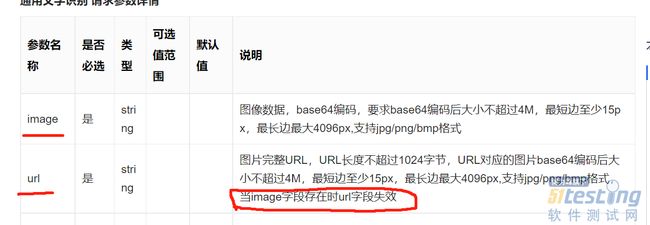
所以此时我们用图片的base64数据就行了。
再回到Selenium里面,我们怎么才能获取到验证码那张图片呢?
思考一下:
1、读取img标签的src,然后下载图片,保存图片文件再转为base64
很显然这个方法行不通,为什么呢?
因为img的src属性就是刚才这个url,你去获取一遍url,它同样会变化。
2、截图,裁剪出验证码部分,扔给百度去识别
可行是可行,但是会不会太复杂了??
如果我只对验证码的img元素进行截图,生成base64的数据是不是更方便?
其实呢,selenium作为一款老牌的自动化测试工具,很多方法供大于求了。所以它是有这样的功能的!
Selenium对指定区域截图
我们都知道,selenium有一些截图方法。
driver.get_screenshot_as_file(filename)
但其实,针对元素,也是有截图方法的。
伪代码如下:
# 通过id获取到图片
img = driver.find_element_by_id("image")
# 调用WebElement的screenshot_as_png属性方法,获取到png的数据,因为百度需要png
data = img.screenshot_as_png
接着我们就可以用这个获取到的图片数据去找百度要答案了!
完整版代码:
from aip import AipOcr
from selenium import webdriver
client = AipOcr("你的appid", "你的app_key", "你的secret_key")
driver = webdriver.Chrome()
driver.get("https://iam.pt.ouchn.cn/am/UI/Login")
img = driver.find_element_by_id("kaptchaImage")
data = img.screenshot_as_png
res = client.basicGeneral(data, {})
print(res)

更多图片识别的配置可以查看度娘文档哦!
可以看到,只识别到了CFX,而且图片没有继续变化了。
毕竟文字识别是从图片里面找文字,而且文字会有一些横线这样的干扰,所以如果一次不行,可以多试几次。
思路就是写一个while循环,不断尝试去识别验证码并登录,接着判断是否登录成功,没成功则重复上一个步骤。
以我个人的经验,一般1-10次就可以成功。
好了,以上是博主简单替大家尝试一下UI自动化过程中对于验证码的识别。主要重点在于验证码的识别和对部分区域截图。