图像分类性能提升方案
文章目录
- 数据
-
- EDA(探索性数据分析)
- 图像预处理
-
- 1.mixup
- 2.马赛克,cutmix
- 模型
-
- 第一步.开发一个baseline
- 第二步.开发一个足够大可以过拟合的模型
- 第三步.训练过程的优化
- 损失函数
-
- 1.标签平滑(label smooth)
- 2.Center Loss
- 3.ArcFace
- 4.Focal loss
- 5.SparseMax loss and Weighted cross-entropy
- 评估+错误分析
方法技巧关注方向主要为三个方面,数据,模型和损失函数。
数据
EDA(探索性数据分析)
图像预处理
1.mixup
论文:https://arxiv.org/pdf/1801.02929v2.pdf
代码:https://github.com/hongyi-zhang/mixup
开源代码中采用的是一个dataloader,和论文中说的两个DataLoader不一致,下面是代码的基本流程。
1.定义mixup的形式。在每个batch中的操作

 2,论文中实验流程和结果:
2,论文中实验流程和结果:
图像分类实验:
mixup实质是为数据提供了更加平滑的干扰因素。在数据集ImageNet2012上,mixup的图像效果如下:

和ERM进行了比较,参数保持在[0.1,0.4]之间,基本都要比ERM提高了至少一个百分点。
参数的值对应的取值分布:
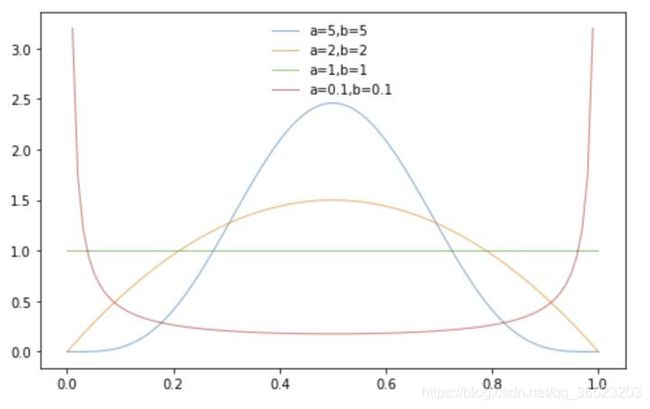
对于mixup,我们发现,与ERM相比, α \alpha α∈[0.1,0.4]能够提高性能,而对于较大的 α \alpha α, mixup会导致欠拟合。我们还发现,具有较高能力和/或较长训练时间的模型在混合中受益最大。例如,当训练90个epoch时,ResNet-101和ResNeXt-101的混合变体相比ERM类似物获得了更大的提高(0.5%到0.6%)比较小的模型如ResNet-50的提高(0.2%)要大得多。当训练200个epoch时,ResNet-50混合变量的top-1错误比90个epoch运行时进一步减少1.2%,而它的ERM模拟值保持不变。
对于混合,我们使用了五个阶段的热身期,在这个阶段我们对原始的训练例子进行训练,因为我们发现这样可以加快初始收敛速度。表4显示,在这个任务上,mixup的性能优于ERM,特别是在使用具有更大容量的模型vga -11时。
原理:实质新增了label为 λ ( l a b e l i ) + ( 1 − λ ) l a b e l j \lambda(label_i)+(1-\lambda)label_j λ(labeli)+(1−λ)labelj的样本,样本比原数据更接近分类最佳分类平面,训练时训练更严格,能学到更多的差异特征。
2.马赛克,cutmix
模型
第一步.开发一个baseline
这里,我们使用一个非常简单的架构创建一个基本的模型,没有任何正则化或dropout层,看看我们是否能超过50%的准确率基线。尽管我们不可能总能达到这个目标,但如果我们在尝试了多种合理的架构后不能超过基线,那么输入数据可能不包含模型进行预测所需的信息。backbone尝试常用的 inception ,ResNet,DenseNet等。
第二步.开发一个足够大可以过拟合的模型
一旦我们的基线模型有足够的能力超过基线分数,我们就可以增加基线模型的能力,直到它在数据集上过拟合为止,然后我们就开始应用正则化。我们可以通过以下方式增加模块容量:
- 添加跟多的层
- 使用更好的结构
- 更完善的流程训练
目前存在以下结构模块,可以改进模型的容量,但几乎没有改变计算复杂度; - Residual Networks
- Wide Residual Networks
- Inception
- EfficientNet
- Swish activation
- Residual Attention Network
大多数时候,模型容量和精度是正相关的 —— 随着容量的增加,精度也会增加,反之亦然。
第三步.训练过程的优化
以下方法用来调整模型的训练过程,通过实例项目来看看他们是如何工作的;
- Mixed-Precision Training
- Large Batch-Size Training 大尺度训练
- Cross-Validation Set 交叉验证
- Weight Initialization 权重初始化
- Self-Supervised Training (Knowledge Distillation) 自监督训练,知识蒸馏
- Learning Rate Scheduler学习率
- Learning Rate Warmup 学习率预热 先使用小的学习率训练一段,再使用较大的初始学习率
- Early Stopping早停,防止过拟合,设置停止条件
- Differential Learning Rates 差异化学习率
- Ensemble 集成学习
- Transfer Learning 迁移学习
- Fine-Tuning 微调
超参数调参
与参数不同,hyperparameters是由你在配置模型时指定的(即学习率、epoch的数量、hidden units的数量、batch size大小等)。
你可以通过使用hyperparameter调优库,比如Scikit learn Grid Search,Keras Tuner来自动化这个过程,而不是去手动配置。这些库会在你指定的范围内尝试所有的hyperparameter组合,返回表现最好的模型。
需要调优的超参数越多,过程就越慢,因此最好选择模型超参数的最小子集进行调优。
并不是所有的模型超参数都同样重要。一些超参数会对机器学习算法的行为产生巨大的影响,进而影响其性能。你应该小心地选择那些对模型性能影响最大的参数,并对它们进行调优以获得最佳性能。
损失函数
1.标签平滑(label smooth)
2.Center Loss
惩罚特征向量和类别中心在欧式空间中的距离来增强类内的紧密性,使用级联的 Softmax loss 来保证类间的分离性。但是,在训练时随着 ID 数量的增加,更新类别中心十分困难。与softmax一起使用。
对样本的特征进行相似性进行计算:
使用过程:
1,计算整体训练集中每个类的类内中心
2,训练过程中,返回每个batch的样本的特征向量和结果
3,在每个batch中,计算每个样本到该样本类别的类内中心的欧式距离作为损失函数,这样就提高了类内的聚集。
3.ArcFace
增强使用特征进行人脸分类的能力,将人脸识别的能力提高了10个点。前面还有提出的SphereFace和CosFace。
网络结构设计:
原来的softmax公式:
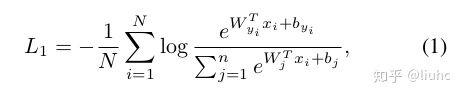
令 ∣ ∣ W j ∣ ∣ = 1 ||W_j||=1 ∣∣Wj∣∣=1,然后把 ∣ ∣ x i ∣ ∣ ||x_i|| ∣∣xi∣∣的大小缩放到s.根据向量夹角公式,上式可以变形为:
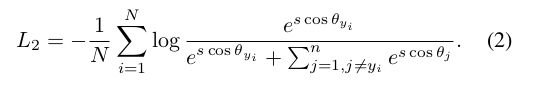
把softmax的loss,映射到了半径为s的超球面, ∣ ∣ x i ∣ ∣ ||x_i|| ∣∣xi∣∣对 ∣ ∣ W j ∣ ∣ ||W_j|| ∣∣Wj∣∣的角度。再在此角度加上m度的惩罚,如下式:
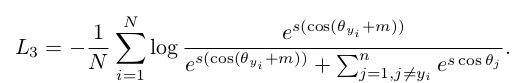
只需要把softmax进行上面几步的改造就完成了。提高类间距离,减小类内距离的效果。
论文阅读笔记:
摘要:在本文中,我们提出了一个附加角边缘损失(ArcFace),以获得高度区分特征的人脸识别。由于与超球面测地线距离的精确对应,所提出的弧面具有清晰的几何解释。
简介:
目前有两种主要的研究方向来训练DCNNs进行人脸识别。一种是训练一个多类分类器来分离训练集中的不同身份,如使用softmax分类器[33,24,6],另一种是直接学习嵌入(embedding):特征的一种表达,如triplet loss[29]。基于大规模的训练数据和精细的DCNN架构,基于softmax-loss的方法[6]和基于triplet loss的方法[29]都能获得良好的人脸识别性能。
但是不论是softmax还是triplet loss有一些缺点。对于softmax损失:(1)线性变换矩阵W∈R d×n,其大小随着identity number n线性增加;(2)学习到的特征对于闭集分类问题是可分离的,但对于开集人脸识别问题判别能力不够。对于三重值的损失:(1)特别是对于大规模数据集,面对三重值的数量出现了组合爆炸,导致迭代步骤的显著增加;(2)半硬样本挖掘对于有效的模型训练来说是一个相当困难的问题
Wen等人[38]首创了中心损失,即每个特征向量与其类中心之间的欧氏距离,以获得类内紧致性,而通过softmax损失的联合惩罚来保证类间的离散性。然而,在训练期间更新实际的训练中心是极其困难的,因为可供训练的脸部的类别的数量最近急剧增加。前面还有提出的SphereFace和CosFace效果也很好,但也自己的缺点。本文在上述的方法提出了改进;
在本文中,我们提出了一个附加的角边缘损失(ArcFace)来进一步提高人脸识别模型的识别能力和稳定训练过程。如图2所示,DCNN feature和最后一个完全连接层的点积等于feature和权值归一化后的余弦距离。我们使用arccos函数来计算当前特征和目标权重之间的角度。然后,我们给目标角添加一个附加的角边缘,然后我们通过余弦函数得到目标的对数。然后,我们根据固定的特征规范重新缩放所有的日志,随后的步骤与softmax丢失完全相同。ArcFace的优点可以总结如下:
迷人的 :利用归一化超球面中角和弧的精确对应关系,直接优化测地线距离余量。我们通过分析特征和权重之间的角度统计数据,直观地说明了512-D空间中发生了什么。
有效:ArcFace在10个人脸识别基准上取得了最先进的性能,包括大规模图像和视频数据集。
容易实现 ArcFace只需要算法1中给出的几行代码,并且非常容易在基于计算图形的深度学习框架中实现,例如。
MxNet [8], Pytorch[25]和Tensorflow[4]。此外,ArcFace不需要与其他损失函数结合就可以获得稳定的性能,并且可以很容易地收敛于任何训练数据集。
高效: ArcFace在训练过程中只增加了微不足道的计算复杂度。当前的gpu可以很容易地支持数百万个身份进行训练,而模型并行策略可以很容易地支持更多的身份
算法流程:
1.输入 x i x_i xi为1xd的向量,对该向量执行L2正则化得到 x i / ∣ ∣ x i ∣ ∣ x_i/||x_i|| xi/∣∣xi∣∣
2,向量W是dn的矩阵,n表示分类的类别数,对每一列( w j w_j wj)执行 w j / ∣ ∣ w j ∣ ∣ w_j/||w_j|| wj/∣∣wj∣∣
3,然后计算 x i / ∣ ∣ x i ∣ ∣ ∗ w j / ∣ ∣ w j ∣ ∣ ∗ c o s ( θ j ) x_i/||x_i||*w_j/||w_j||*cos(\theta_j) xi/∣∣xi∣∣∗wj/∣∣wj∣∣∗cos(θj),前两项都是为1,;
4,对输出中对应真实标签的值 c o s ( θ y i ) cos(\theta_{y_i}) cos(θyi)执行反余弦操作就得到 θ y i \theta_{y_i} θyi, y i y_i yi表示真实的标签
5,加入m参数,分别用 m 1 , m 2 , m 3 m_1,m_2,m_3 m1,m2,m3表示,三个算法整合一起就是 c o s ( m 1 θ y i + m 2 ) − m 3 cos(m_1\theta_{y_i}+m_2)-m_3 cos(m1θyi+m2)−m3
6,对得到的feature乘以scale参数放大,得到输出 s ∗ c o s ( θ j ) s*cos(\theta_j) s∗cos(θj)
7,再对输出的值送入softmax函数,得到预测输出的概率。
**arcface完成了将(11024)映射到(1*n)的过程。**使得同类特征聚集,类间差异变大,
4.Focal loss
5.SparseMax loss and Weighted cross-entropy
评估+错误分析
在这里,我们做消融研究,并分析我们的实验结果。我们确定了我们的模型的弱点和长处,并确定了未来需要改进的地方。在这个阶段,你可以使用以下技术,并在链接的示例中查看它们是如何实现的:
- Tracking metrics and Confusion matrix:https://www.kaggle.com/vincee/intel-image-classification-cnn-keras
- Grad CAM:https://arxiv.org/pdf/1610.02391v1.pdf
- Test Time Augmentation (TTA):https://www.kaggle.com/iafoss/pretrained-resnet34-with-rgby-0-460-public-lb
有许多实验跟踪和管理工具,采取最小设置为你自动保存所有数据,这使消融研究更容易。