一、前置知识
1.1 语料库(Corpus)
太长不看版: NLP任务所依赖的语言数据称为语料库。
详细介绍版: 语料库(Corpus,复数是Corpora)是组织成数据集的真实文本或音频的集合。 此处的真实是指由该语言的母语者制作的文本或音频。 语料库可以由从报纸、小说、食谱、广播到电视节目、电影和推文的所有内容组成。 在自然语言处理中,语料库包含可用于训练 AI 的文本和语音数据。
1.2 词元(Token)
为简便起见,假设我们的语料库只有三个英文句子并且均已经过处理(全部小写+去掉标点符号):
corpus = ["he is an old worker", "english is a useful tool", "the cinema is far away"]
我们往往需要将其词元化(tokenize)以成为一个序列,这里只需要简单的 split 即可:
def tokenize(corpus):
return [sentence.split() for sentence in corpus]
tokens = tokenize(corpus)
print(tokens)
# [['he', 'is', 'an', 'old', 'worker'], ['english', 'is', 'a', 'useful', 'tool'], ['the', 'cinema', 'is', 'far', 'away']]
这里我们是以单词级别进行词元化,还可以以字符级别进行词元化。
1.3 词表(Vocabulary)
词表不重复地包含了语料库中的所有词元,其实现方式十分容易:
vocab = set(sum(tokens, []))
print(vocab)
# {'is', 'useful', 'an', 'old', 'far', 'the', 'away', 'a', 'he', 'tool', 'cinema', 'english', 'worker'}
词表在NLP任务中往往并不是最重要的,我们需要为词表中的每一个单词分配唯一的索引并构建单词到索引的映射:word2idx。这里我们按照单词出现的频率来构建 word2idx。
from collections import Counter
word2idx = {
word: idx
for idx, (word, freq) in enumerate(
sorted(Counter(sum(tokens, [])).items(), key=lambda x: x[1], reverse=True))
}
print(word2idx)
# {'is': 0, 'he': 1, 'an': 2, 'old': 3, 'worker': 4, 'english': 5, 'a': 6, 'useful': 7, 'tool': 8, 'the': 9, 'cinema': 10, 'far': 11, 'away': 12}
反过来,我们还可以构建 idx2word:
idx2word = {idx: word for word, idx in word2idx.items()}
print(idx2word)
# {0: 'is', 1: 'he', 2: 'an', 3: 'old', 4: 'worker', 5: 'english', 6: 'a', 7: 'useful', 8: 'tool', 9: 'the', 10: 'cinema', 11: 'far', 12: 'away'}
对于 1.2 节中的 tokens,也可以转化为索引的表示:
encoded_tokens = [[word2idx[token] for token in line] for line in tokens] print(encoded_tokens) # [[1, 0, 2, 3, 4], [5, 0, 6, 7, 8], [9, 10, 0, 11, 12]]
这种表示方式将在后续讲解 nn.Embedding 时提到。
二、nn.Embedding 基础
2.1 为什么要 embedding?
RNN无法直接处理单词,因此需要通过某种方法把单词变成数字形式的向量才能作为RNN的输入。这种把单词映射到向量空间中的一个向量的做法称为词嵌入(word embedding),对应的向量称为词向量(word vector)。
2.2 基础参数
我们首先讲解 nn.Embedding 中的基础参数,了解它的基本用法后,再讲解它的全部参数。
基础参数如下:
nn.Embedding(num_embeddings, embedding_dim)
其中 num_embeddings 是词表的大小,即 len(vocab);embedding_dim 是词向量的维度。
我们使用第一章节的例子,此时词表大小为 12 12 12,不妨设嵌入后词向量的维度是 3 3 3(即将单词嵌入到三维向量空间中),则 embedding 层应该这样创建:
torch.manual_seed(0) # 为了复现性 emb = nn.Embedding(12, 3)
embedding 层中只有一个参数 weight,在创建时它会从标准正态分布中进行初始化:
print(emb.weight) # Parameter containing: # tensor([[-1.1258, -1.1524, -0.2506], # [-0.4339, 0.8487, 0.6920], # [-0.3160, -2.1152, 0.3223], # [-1.2633, 0.3500, 0.3081], # [ 0.1198, 1.2377, 1.1168], # [-0.2473, -1.3527, -1.6959], # [ 0.5667, 0.7935, 0.4397], # [ 0.1124, 0.6408, 0.4412], # [-0.2159, -0.7425, 0.5627], # [ 0.2596, 0.5229, 2.3022], # [-1.4689, -1.5867, 1.2032], # [ 0.0845, -1.2001, -0.0048]], requires_grad=True)
这里我们可以把 weight 当作 embedding 层的一个权重。
接下来再来看一下 nn.Embedding 的输入。直观来看,给定一个已经词元化的句子,将其中的单词输入到 embedding 层应该得到相应的词向量。事实上,nn.Embedding 接受的输入并不是词元化后的句子,而是它的索引形式,即第一章节中提到的 encoded_tokens。
nn.Embedding 可以接受任何形状的张量作为输入,但因为传入的是索引,所以张量中的每个数字都不应超过 len(vocab) - 1,否则就会报错。接下来,nn.Embedding 的作用就像一个查找表(Lookup Table)一样,通过这些索引在 weight 中查找并返回相应的词向量。
print(emb.weight) # tensor([[-1.1258, -1.1524, -0.2506], # [-0.4339, 0.8487, 0.6920], # [-0.3160, -2.1152, 0.3223], # [-1.2633, 0.3500, 0.3081], # [ 0.1198, 1.2377, 1.1168], # [-0.2473, -1.3527, -1.6959], # [ 0.5667, 0.7935, 0.4397], # [ 0.1124, 0.6408, 0.4412], # [-0.2159, -0.7425, 0.5627], # [ 0.2596, 0.5229, 2.3022], # [-1.4689, -1.5867, 1.2032], # [ 0.0845, -1.2001, -0.0048]], requires_grad=True) sentence = torch.tensor(encoded_tokens[0]) # 一共有三个句子,这里只使用第一个句子 print(sentence) # tensor([1, 0, 2, 3, 4]) print(emb(sentence)) # tensor([[-0.4339, 0.8487, 0.6920], # [-1.1258, -1.1524, -0.2506], # [-0.3160, -2.1152, 0.3223], # [-1.2633, 0.3500, 0.3081], # [ 0.1198, 1.2377, 1.1168]], grad_fn=) print(emb.weight[sentence] == emb(sentence)) # tensor([[True, True, True], # [True, True, True], # [True, True, True], # [True, True, True], # [True, True, True]])
2.3 nn.Embedding 与 nn.Linear 的区别
细心的读者可能已经看出 nn.Embedding 和 nn.Linear 似乎很像,那它们到底有什么区别呢?
回顾 nn.Linear,若不开启 bias,设输入向量为 x,nn.Linear.weight 对应的矩阵为 A(形状为 hidden_size × input_size),则计算方式为:
y=xAT
其中 x , y 均为行向量。
假如 x 是one-hot向量,第 i 个位置是 1 1 1,那么 y 就是 A T 的第 i i 行。
现给定一个单词 w ,假设它在 word2idx 中的索引就是 i ,在 nn.Embedding 中,我们根据这个索引 i 去查找 emb.weight 的第 i 行。而在 nn.Linear 中,我们则是将这个索引 i 编码成一个one-hot向量,再去乘上对应的权重矩阵得到矩阵的第 i 行。
请看下例:
torch.manual_seed(0) vocab_size = 4 # 词表大小为4 embedding_dim = 3 # 词向量维度为3 weight = torch.randn(4, 3) # 随机初始化权重矩阵 # 保持线性层和嵌入层具有相同的权重 linear_layer = nn.Linear(4, 3, bias=False) linear_layer.weight.data = weight.T # 注意转置 emb_layer = nn.Embedding(4, 3) emb_layer.weight.data = weight idx = torch.tensor(2) # 假设某个单词在word2idx中的索引为2 word = torch.tensor([0, 0, 1, 0]).to(torch.float) # 上述单词的one-hot表示 print(emb_layer(idx)) # tensor([ 0.4033, 0.8380, -0.7193], grad_fn=) print(linear_layer(word)) # tensor([ 0.4033, 0.8380, -0.7193], grad_fn= )
从中我们可以总结出:
nn.Linear接受向量作为输入,而nn.Embedding则是接受离散的索引作为输入;nn.Embedding实际上就是输入为one-hot向量,且不带bias的nn.Linear。
此外,nn.Linear 在运算过程中做了矩阵乘法,而 nn.Embedding 是直接根据索引查表,因此在该情景下 nn.Embedding 的效率显然更高。
进一步阅读: [Stack Overflow] What is the difference between an Embedding Layer with a bias immediately afterwards and a Linear Layer in PyTorch?
2.4 nn.Embedding 的更新问题
在查阅了PyTorch官方论坛和Stack Overflow的一些帖子后,发现有不少人对 nn.Embedding 中的权重 weight 是怎么更新的感到非常困惑。
nn.Embedding 的权重实际上就是词嵌入本身
事实上,nn.Embedding.weight 在更新的过程中既没有采用 Skip-gram 也没有采用 CBOW。回顾最简单的多层感知机,其中的 nn.Linear.weight 会随着反向传播自动更新。当我们把 nn.Embedding 视为一个特殊的 nn.Linear 后,其更新机制就不难理解了,无非就是按照梯度进行更新罢了。
训练结束后,得到的词嵌入是最适合当前任务的词嵌入,而非像word2vec,GloVe这种更为通用的词嵌入。
当然我们也可以在训练开始之前使用预训练的词嵌入,例如上述提到的word2vec,但此时应该考虑针对当前任务重新训练或进行微调。
假如我们已经使用了预训练的词嵌入并且不想让它在训练过程中自我更新,那么可以尝试冻结梯度,即:
emb.weight.requires_grad = False
进一步阅读:
[PyTorch Forums] How nn.Embedding trained?
[PyTorch Forums] How does nn.Embedding work?
[Stack Overflow] Embedding in pytorch
[Stack Overflow] What “exactly” happens inside embedding layer in pytorch?
三、nn.Embedding 进阶
在这一章节中,我们会讲解 nn.Embedding 的所有参数并介绍如何使用预训练的词嵌入。
3.1 全部参数
官方文档:
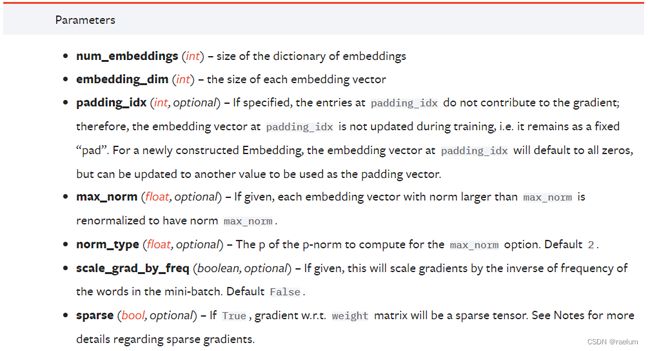
padding_idx
我们知道,nn.Embedding 虽然可以接受任意形状的张量作为输入,但绝大多数情况下,其输入的形状为 batch_size × sequence_length,这要求同一个 batch 中的所有序列的长度相同。
回顾1.2节中的例子,语料库中的三个句子的长度相同(拥有相同的单词个数),但事实上这是博主特意选取的三个句子。现实任务中,很难保证同一个 batch 中的所有句子长度都相同,因此我们需要对那些长度较短的句子进行填充。因为输入到 nn.Embedding 中的都是索引,所以我们也需要用索引进行填充,那使用哪个索引最好呢?
假设语料库为:
corpus = ["he is an old worker", "time tries truth", "better late than never"]
print(word2idx)
# {'he': 0, 'is': 1, 'an': 2, 'old': 3, 'worker': 4, 'time': 5, 'tries': 6, 'truth': 7, 'better': 8, 'late': 9, 'than': 10, 'never': 11}
print(encoded_tokens)
# [[0, 1, 2, 3, 4], [5, 6, 7], [8, 9, 10, 11]]
我们可以在 word2idx 中新增一个词元
word2idx[''] = 12
对 encoded_tokens 进行填充:
max_length = max([len(seq) for seq in encoded_tokens])
for i in range(len(encoded_tokens)):
encoded_tokens[i] += [word2idx['']] * (max_length - len(encoded_tokens[i]))
print(encoded_tokens)
# [[0, 1, 2, 3, 4], [5, 6, 7, 12, 12], [8, 9, 10, 11, 12]]
创建 embedding 层并指定 padding_idx:
emb = nn.Embedding(len(word2idx), 3, padding_idx=12) # 假设词向量维度是3 print(emb.weight) # tensor([[ 1.5017, -1.1737, 0.1742], # [-0.9511, -0.4172, 1.5996], # [ 0.6306, 1.4186, 1.3872], # [-0.1833, 1.4485, -0.3515], # [ 0.2474, -0.8514, -0.2448], # [ 0.4386, 1.3905, 0.0328], # [-0.1215, 0.5504, 0.1499], # [ 0.5954, -1.0845, 1.9494], # [ 0.0668, 1.1366, -0.3414], # [-0.0260, -0.1091, 0.4937], # [ 0.4947, 1.1701, -0.5660], # [ 1.1717, -0.3970, -1.4958], # [ 0.0000, 0.0000, 0.0000]], requires_grad=True)
可以看出填充词元对应的词向量是零向量,并且在训练过程中填充词元对应的词向量不会进行更新(始终是零向量)。
padding_idx 默认为 None,即不进行填充。
max_norm
如果词向量的范数超过了 max_norm,则将其按范数归一化至 max_norm:
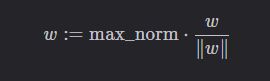
max_norm 默认为 None,即不进行归一化。
norm_type
当指定了 max_norm 时,norm_type 决定采用何种范数去计算。默认是2-范数。
scale_grad_by_freq
若将该参数设置为 True,则对词向量 w w w 进行更新时,会根据它在一个 batch 中出现的频率对相应的梯度进行缩放:
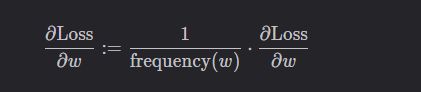
默认为 False。
sparse
若设置为 True,则与 Embedding.weight 相关的梯度将变为稀疏张量,此时优化器只能选择:SGD、SparseAdam 和 Adagrad。默认为 False。
3.2 使用预训练的词嵌入
有些情况下我们需要使用预训练的词嵌入,这时候可以使用 from_pretrained 方法,如下:
torch.manual_seed(0) pretrained_embeddings = torch.randn(4, 3) print(pretrained_embeddings) # tensor([[ 1.5410, -0.2934, -2.1788], # [ 0.5684, -1.0845, -1.3986], # [ 0.4033, 0.8380, -0.7193], # [-0.4033, -0.5966, 0.1820]]) emb = nn.Embedding(4, 3).from_pretrained(pretrained_embeddings) print(emb.weight) # tensor([[ 1.5410, -0.2934, -2.1788], # [ 0.5684, -1.0845, -1.3986], # [ 0.4033, 0.8380, -0.7193], # [-0.4033, -0.5966, 0.1820]])
如果要避免预训练的词嵌入在后续的训练过程中更新,可将 freeze 参数设置为 True:
emb = nn.Embedding(4, 3).from_pretrained(pretrained_embeddings, freeze=True)
四、最后
到此这篇关于深入理解PyTorch中的nn.Embedding的使用的文章就介绍到这了,更多相关PyTorch nn.Embedding内容请搜索脚本之家以前的文章或继续浏览下面的相关文章希望大家以后多多支持脚本之家!