Java-面试复习-整理01
目录
- 一些集合
-
-
- Map接口
-
- TreeMap
- HashMap和HashTable的异同
-
- HashMap如何解决线程安全问题?
- HashTable的put过程
- LinkedHashMap
- ConcurrentHashMap
- Set
-
- HashSet
- LinkedHashSet
- TreeSet
- ArrayList
-
- 两种拷贝
- ArrayList和数组有什么区别?
- ArrayList、LinkedList的异同点
- Priority Queue
- 迭代器
-
- TCP和UDP
-
-
- TCP和UDP的区别
-
- TCP数据可靠性的体现
- 三次握手
- 四次挥手
-
- TCP用了什么措施保证可靠性
-
- String、stringbuilder、stringbuffer
- 多线程
-
-
- 进程和线程
-
- 进程间的通信方式
- 线程间通信
- sleep()和wait()
- Java多线程的几种实现方式:
- 内存泄露和GC
-
- 一些网络
-
-
- 输入网址的请求过程
-
- OSI七层模型
- https
-
一些集合
Map接口
数据结构:哈希表
哈希表:通过关键码来映射到值的一个数据结构
哈希函数:键与值映射的一个映射关系
哈希函数:
1.直接寻址法:f(x)=kx+b(k、b都是常数)
2.除留余数法:f(x)=x%k(k<=m)[m为存储位置长度]
哈希冲突:m!=n 但是 f(m)=f(n)
解决:
1.链地址法
2.探测法(线性探测、随机探测)
TreeMap
数据有序(红黑树)
HashMap和HashTable的异同
相同点:
1.底层数据结构都为数组+链表
2.key都不能重复
3.插入元素都不能保证插入有序
4.哈希过程通过key进行hash
不同点:
1.安全性问题:
HashMap不能保证线程安全
HashTable能保证线程安全
2.继承关系:
HashMap继承自AbstractMap
HashTable继承自Dictionary
3.null值问题:
HashMap的key和value都可以为null
HashTable的key和value都不能为null
4.扩容方式:
HashMap按照2map.length(必须为2的指数)
HashTable按照2table.length+1(2倍+1)
5.默认值:
HashMap默认数组大小为16
HashTable默认数组大小为11
6.hash算法不同
7.效率不同:
HashMap在单线程效率高(是HashTable的轻量级实现,效率较高)
HashTable在单线程效率低(效率较低,但线程安全,适用于多线程)
遍历方式不同:HashTable比HashMap多一个elements方法
HashMap如何解决线程安全问题?
通过以下代码就可以使HashMap为线程安全的:
HashMap<String,Integer> hashmap = new HashMap<>();
<String,Integer> map = Collections.synchronizedMap(hashmap);
HashTable的put过程
1.判断value不能为null,若为null抛出异常
2.通过key进行hash获取到key该存储的索引位置
3.对该索引位置的链表进行遍历,获取key是否存在(key存在条件:hash相等且通过key.equals判断相等)
4.在存在该key的情况下,将value值进行更新且直接返回
5.key不存在则进行新节点插入逻辑
5.1 扩容考虑:entry节点个数大于阈值(count>threshold)进行扩容
5.2 新容量大小为:2*table.length+1
5.3 将原哈希表中的数据全部进行重新hash到新的hash表中
5.4 更新插入的key的新的位置
5.5 找到新节点位置,创建entry实体通过头插入将元素插入
LinkedHashMap
继承关系:继承了HashMap,实现了Map接口
默认值:accessOrder = false;
基本属性:Entry header
boolean accessOrder
构造函数:构造函数有5个
多了一个传有参数accessOrder的构造函数
public LinkedHashMap(int initialCapacity,float loadFactor,boolean accessOrder){
super(initialCapacity,loadFactor);
this.accessOrder = accessOrder;
}
通过以上几点研究,找到与HashMap不同的点:
插入有序
以及它的特点,存在的必要性:
慢,但效率只与实际数据有关,可以实现插入顺序排序或访问顺序排序
WeakHashMap:添加的元素随着时间的推移会减少
ConcurrentHashMap
底层采用分段的数组+链表实现,线程安全
通过把整个Map分为N个Segment,可以提供相同的线程安全,但是效率提升N倍,默认提升16倍。(读操作不加锁,由于HashEntry的value变量是volatitle的,也能保证读取到最新的值。)
HashTable的synchronized是针对整张Hash表的,即每次锁住整张表让线程独占,ConcurrentHashMap允许多个修改操作并发进行,其关键在于使用了锁分离技术。
有些方法需要跨段,比如size()和containsValue(),它们可能需要锁住整个表而不仅仅是某个段,这需要按顺序锁定所有段,操作完毕后,又按顺序释放所有段的锁。
扩容:段内扩容(段内元素超过该段对应Entry数组长度的75%触发扩容,不会对整个Map进行扩容),插入前检测需不需要扩容,有效避免无效扩容
Set
HashSet
HashSet底层实现基于HashMap实现
和HashMap的不同点:
接口不同(Map-Set)
存储对象不同(键值对-单个值)
LinkedHashSet
继承了HashSet,实现了Set接口
底层实现是LinkedHashMap
采用默认的数据插入有序
特点:实现数据的插入有序性
TreeSet
数据去重,并且排序
ArrayList
集合存在于java.util包路径下
特点:
重复性:数据可以重复
null值:可以有null值存在
有序性:能保证数据的插入有序
ArrayList底层数据结构是数组
两种拷贝
Arrays.copyOf():
参数:原数组,拷贝数组的长度
调用了重载方法,创建了新的数组,调用了System.arraycopy()方法
System.arraycopy():
参数:原数组,原数组拷贝的起始位置,目标数组,目标数组拷贝的起始位置,拷贝长度
native
从两种拷贝方式的定义来看:
System.arraycopy()使用时必须有原数组和目标数组
Arrays.copyOf()使用时只需要有原数组即可
从两种拷贝方式的底层实现来看:
System.arraycopy()是用c或c++实现的
Arrays.copyOf()是在方法中重新创建了一个数组,并调用System.arraycopy()进行拷贝
两种拷贝方式的效率分析:
由于Arrays.copyOf()不但创建了新的数组而且最终还是调用System.arraycopy(),所以System.arraycopy()的效率高于Arrays.copyOf()。
ArrayList和数组有什么区别?
初始化大小:ArrayList可以不指定大小,数组必须指定大小
存储数据类型:ArrayList只能存储引用类型,数组可以存储引用类型和基本类型
ArrayList比数组灵活:提供丰富的方法
ArrayList、LinkedList的异同点
相同点:
1.继承关系:都是List接口下的实现类,具有List提供的所有方法
2.有序性:数据都是按照插入有序
3.重复性:集合中元素是可以重复的
4.null值:都可以存储null值
5.安全性问题:都是非线程安全的集合
不同点:
1.数据结构:ArrayList底层是数组,LinkedList底层是链表(双向链表)
2.特有方法:LinkedList具有特有的方法,例如:addFirst、addLast…(实现了Deque接口)
3.效率:ArrayList查询效率高,O(1)、LinkedList添加删除效率高,O(1)
ArrayList添加元素趋近于O(1),在不扩容的情况下就是O(1)
4.应用场景不同:ArrayList在查询较高的业务场景优先考虑,LinkedList在修改、添加等操作较多的场景下优先考虑
Priority Queue
add 添加元素
offer 添加元素,不能添加null值,会抛出空指针异常
peek 方法获取队顶元素,仅获取,不删除
remove 删除队列顶部元素,队列为空则抛出异常
poll 删除队顶元素,队列为空返回null
特点:
PriorityQueue队列里元素不能为null
存储元素是可以重复的
注意点:
PriorityQueue中自定义实现类型需要实现Comparable接口,否则会抛出异常
迭代器
迭代器是一种设计模式,提供了一种方法,来对集合,容器进行遍历
不需要关注底层数据结构和数据类型,来达到底层和上层遍历解耦的目的
注意:使用时hasNext、next需要轮询出现,hasNext、remove也是一样
要自定义迭代器类,类要有iterator方法,需要实现iterable接口,需要实现implements Iterator接口
并发异常问题:ConcurrentModificationException
原因:集合本身修改会引起modCount版本号的修改,而迭代器本身的版本号副本并未改变,因此会抛出异常
fail-fast机制:快速失败机制
fail-fast机制,是一种错误检测机制,它只能被用来检测错误,因为JDK并不保证fail-fast机制一定会发生。
若在多线程环境下使用fail-fast机制的集合,建议使用“java.util.concurrent”包下的类去取代“java.util”包下的类。
fail-safe机制:安全失败机制
Iterator的安全失败是基于对底层集合做拷贝,因此,它不受源集合上修改的影响。
java.util包下面的所有的集合类都是快速失败的,而java.util.concurrent包下面的所有的类都是安全失败的,快速失败的迭代器会抛出ConcurrentModificationException异常,而安全失败的迭代器永远不会抛出这样的异常。
TCP和UDP
UDP:用户数据包协议
不可靠的数据传输
数据传输时不会进行事前的连接和事后的释放
TCP和UDP的区别
TCP:可靠的、面向连接的、流式服务
UDP:不可靠的、无连接的、数据包服务
应用场景不同:TCP适合消息可达性要求较高的场景,如微信、文件传输等
UDP适合传输效率高,可靠性要求不高的场景,如视频、直播等
流式服务:数据是一条数据源,数据是没有界限的,发送的次数和接收的次数无直接关系,接收方将数据放在缓冲区,数据一次不能接收完的情况下,可以放在缓冲区,进行二次读取
数据包服务:发送的次数和接收的次数是相等的,如果接收端一次未能读取完传输层的数据,剩余的数据则直接丢弃掉
TCP数据可靠性的体现
1.数据通信前进行连接,通信结束释放连接
2.保证数据完全到达目的端:确认应答机制和超时重传机制
3.接收方接收的数据都是有序的,在发送数据头部的序号+数据的大小,就可以确定数据的位置以及下一次接收数据的起始位置
4.数据发送和接收是完全相同的,通过头部的校验和字段来判断接收数据是否存在损坏,存在损坏则丢弃,重新接收客户端的发送
三次握手
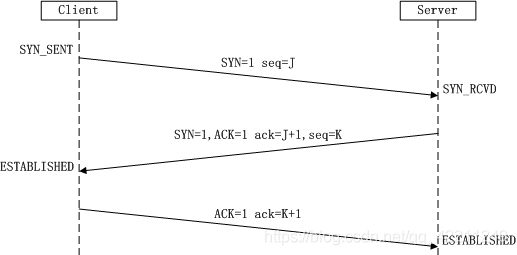
1.服务器从close被动打开,处于listen状态,客户端从close主动打开后开始连接,客户端给服务器发送SYN=1,seq = x(客户端的)
2.第一次握手后,客户端处于SYN-SENT状态,服务器给客户端发送SYN=1,ACK=1,seq=y(服务器的),ack=x+1
3.第二次握手后,服务器处于SYN-RCVD状态,客户端给服务器发送ACK=1,seq=x+1,ack=y+1
4.第三次握手后,客户端和服务器都处于ESTABLISHED状态,可以进行数据传递
为什么要进行三次握手而不是两次:
为了防止已失效的连接请求报文突然又传送到了服务器,因而产生错误。主要目的是防止server端一直等待,浪费资源。
四次挥手

1.客户端和服务器都处于ESTABLISHED状态,客户端发起主动关闭,给服务器发送FIN=1,seq=u
2.第一次客户端发出挥手后,客户端处于FIN-WAIT-1状态,服务器给客户端发送ACK=1,seq=v,ack=u+1,此时服务器可以给客户端发消息,客户端不能
3.第二次服务端发出挥手后,发起第三次挥手,服务器处于CLOSE-WAIT状态,客户端处于FIN-WAIT-2状态, 服务器给客户端发送FIN=1,ACK=1,seq=w,ack=u+1
4.第三次服务端发出挥手后,服务器处于LAST-ACK状态,客户端给服务器发送ACK=1,seq=u+1,ack=w+1
5.第四次客户端发出挥手后,客户端处于TIME-WAIT状态,服务器closed,客户端等待2MSL时间后closed
TCP用了什么措施保证可靠性
TCP是面向连接的,可靠的字节流服务
面向连接意味着两个使用TCP的应用(通常是一个客户和一个服务器)在彼此交换数据之前必须先建立一个TCP连接,在一个TCP连接中,仅有两方进行彼此通信,广播和多播不能用于TCP
1.应用数据被分割成TCP认为最合适发送的数据块(将数据截断为合理的长度)
2.发出一个段后,启动一个定时器,若不能及时收到一个确认,将重发报文段。(超时重发)
3.收到另一端的数据,会发送一个确认。这个确认不是立即发送,通常推迟几分之一秒,要对包做完整校验。(对于收到的请求,给出确认响应)
4.保持它首部和数据的校验和,检测数据在传输中的变化,如果收到段的校验和有差错,将丢弃这个报文段且不确认收到。(检验出包有错,丢弃报文段,不给出响应,等待发送端超时重发)
5.对失序数据进行重新排序,然后才交给应用层
6.对于重复数据,能够丢弃
7.流量控制,TCP接收端只允许另一端发送接收端缓冲区所能接纳的数据,这将防止较快主机导致较慢主机的缓冲区溢出(流量控制,可变大小的滑动窗口)
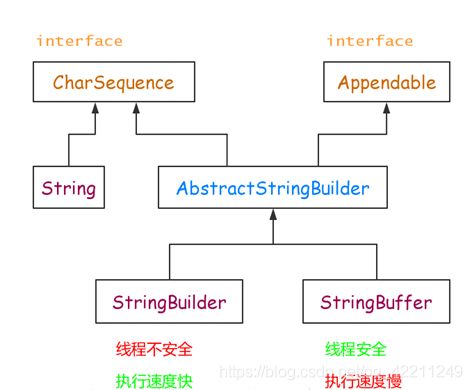
String、stringbuilder、stringbuffer
多线程
进程和线程
进程是表示资源分配的基本单位,又是调度运行的基本单位。
线程是进程中执行运算的最小单位,即执行处理机调度的基本单位。
引入线程的好处:易于调度、提高并发性、开销少、利于充分发挥多处理器的功能。
进程和线程的关系:
1.一个线程只属于一个进程,一个进程至少有一个线程。
2.资源分配给进程,同一进程的所有线程共享该进程的所有资源。
3.处理机分给线程,即真正在处理机上运行的是线程。
4.线程在执行的过程中,需要协作同步。不同进程的线程间要利用消息通信的办法实现同步。
线程是指进程内的一个执行单元,也是进程内的可调度实体。
进程间的通信方式
1.管道(pipe)及有名管道(named pipe)
2.信号(signal)
3.消息队列(message queue)
4.共享内存(shared memory)需要依靠某种同步操作,如互斥锁和信号量
5.信号量(semaphore)进程间及同一进程的不同线程间的同步和互斥手段
6.套接字(socket)可用于网络中不同机器之间的进程间通信
线程间通信
1.使用volatile关键字
2.使用Object类的wait()和notify()方法
3.使用JUC工具类CountDownLatch(java.util.concurrent包下提供)
使用ReentrantLock结合Condition
基于LockSupport实现进程间的阻塞和唤醒
sleep()和wait()
sleep()可以将一个线程睡眠,参数可以指定一个时间,而wait()可以将一个线程挂起,直到超时或者该线程被唤醒。
wait有两种形式:wait()和wait(milliseconds)。
sleep和wait的区别有:
1.这两个方法来自不同的类分别是Thread(自控)和Object(他控)
2.最主要的是sleep方法没有释放锁,而wait方法释放了锁,使得其他线程可以使用同步控制块或者方法
3.wait、notify、notifyAll只能在同步控制方法或者同步控制块里面使用,而sleep可以在任何地方使用
synchronized(x){
x.notify();
//或者wait()
}
4.sleep必须捕获异常,而wait、notify和notifyAll不需要捕获异常
Java多线程的几种实现方式:
1.继承Thread类,重写run方法
2.实现Runnable接口,重写run方法,实现Runnable接口的实现类的实例对象作为Thread构造函数的target
3.通过Callable和FutureTask创建线程
4.通过线程池创建线程
前面两种可以归结为一类:无返回值,因为通过重写run方法,run方法的返回值是void,所以没有办法返回结果
后面两种可以归结成一类:有返回值,通过Callable接口,就要实现call方法,这个方法的返回值是Object,所以返回的结果可以放在Object对象中
(线程之间的执行是相互独立的,哪一个线程优先执行取决于OS的调度)
线程的创建方式:实现runnable接口,继承Thread类,实现Callable接口
实现runnable接口:
1.创建自定义类并实现runnable接口,并实现接口中的run方法
2.实例化自定义的类
3.将自定义类的实例作为参数给Thread类,创建thread实例
4.调用thread实例的start方法,启动子线程
RunnableThreadGY03 threadGY03 = new RunnableThreadGY03();
Thread thread = new Thread(threadGY03);
thread.start();
继承Thread类方式创建新线程:
1.创建自定义的类继承Thread类,并且重写run方法
2.实例化自定义类
3.通过实例化对象调用start方法来创建新线程
ExtendThreadGY03 extendThreadGY03 = new ExtendThreadGY03();
extendThreadGY03.start();
实现Callable接口:
callable接口的实现是线程池提供的一种创建线程的方式
1.实现Callable接口,并且实现call方法
2.创建线程池(Executors工具类提供的方法创建线程池)
3.创建Callable接口实现类的实例
4.将实例对象通过线程池的submit方法提交给线程池进而创建新的线程
ExecutorService executor = Executors.newSingleThreadExecutor();
CallableThreadGY03 callableThreadGY03 = new CallableThreadGY03();
executor.submit(callableThreadGY03);
内存泄露和GC
该释放的对象没有释放,一直被某个或某些实例所持有却不再被使用导致GC不能回收
可达却无用,不会被GC回收的对象,占用内存
1.引用计数法
对对象添加引用表示,没对对象增加一个引用,引用标识+1,减少一个引用,标识-1,当标识=0的时候,说明对象不存在引用,可以被回收。
引用计数法无法处理相互引用的问题
2.可达性分析
判断对象是否存活,将堆中对象想象成一棵树,从树根(Root)开始遍历所有的对象,能够到达的对象称之为可用的对象(存活对象),不可达的称之为垃圾
垃圾回收算法:
1.标记-清除(内存碎片化,回收效率低)
2.复制算法(内存空间只用了一半、效率低,极端情况下拷贝太多、效率低,不适用于生命周期长的对象)
3.标记-整理算法
4.分代回收算法
一些网络
输入网址的请求过程
1.输入网址(存在缓存且未过期的话直接到7)
2.DNS(domain name system,域名系统)解析
3.建立tcp连接
4.客户端发送http请求
5.服务器处理请求
6.服务器响应请求
7.浏览器展示html
8.浏览器发送请求获取其在html中的资源
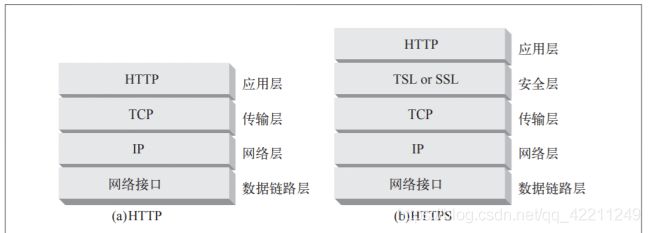
各层的作用及用到的一些协议:
应用层:网络服务于使用者应用程序间的一个接口(HTTP协议进行超文本传输、DNS、HTTPS)
传输层:用一个寻址机制来标识一个特定的应用程序(端口号,默认端口80)TCP、UDP
网络层:基于网络层地址(IP地址)进行不同网络系统间的路径选择,如路由器IP、ARP(获取目的IP地址的物理地址)
数据链路层:在物理层上建立、撤销、标识逻辑链路和链路复用,以及差错校验等功能,通过使用接收系统的硬件地址或物理地址来寻址,如网桥、交换机、网卡
物理层:建立、维护和取消物理连接,如中继器和集线器
OSI七层模型
应用层:网络服务与最终用户的一个接口
协议有:HTTP、FTP、TFTP、SMTP、DNS、TELNET、HTTPS、POP3、DHCP
表示层:数据的表示、安全、压缩(在五层模型里面已经合并到了应用层)
格式有:JPEG、ASCII、EBCDIC、加密格式等
会话层:建立、管理、终止会话(在五层模型里面已经合并到了应用层)
对应主机进程,指本地主机与远程主机正在进行的会话
传输层:定义传输数据的协议端接口,以及流量控制和差错校验
协议有:TCP、UDP,数据包一旦离开网卡即进入网络传输层
网络层:进行逻辑地址寻址,实现不同网络之间的路径选择
协议有:ICMP、IGMP、IP(IPV4、IPV6)
数据链路层:建立逻辑连接、进行硬件地址寻址、差错校验等功能(由底层网络定义协议)
将比特组合成字节进而组合成帧,错误发现但不能纠正,数据链路层协议又被分为两个子层 :逻辑链路控制(LLC)协议和媒体访问控制(MAC)协议
物理层:建立、维护、断开物理连接(由底层网络定义协议)
https
https可以将数据加密传输,也就是传输的是密文,即使黑客在传输过程中拦截到数据也无法破译,这就保证了网络通信的安全。
对称加密(私钥加密),发送方和接收方使用同一个密钥去加密和解密数据。算法公开、加密和解密数独快,适合对大数据量进行加密。私钥不能被泄露,密钥安全管理困难。
非对称加密(公钥加密),使用一对密钥,公钥和私钥,私钥自己保存,公钥是公共的,用公钥或私钥中的任何一个进行加密,用另一个进行解密。加密和解密花费时间长、速度慢,只适合对少量数据进行加密,但安全性更好。
HTTPS = HTTP + SSL/TLS 用SSL或TLS对数据进行加密和解密,用HTTP对加密后的数据进行传输
SSL(secure sockets layer,安全套接层协议)
TLS(transport layer security)安全传输层协议
https为了兼顾安全与效率,同时使用了对称加密和非对称加密。对数据进行对称加密,对称加密所要使用的密钥通过非对称加密传输。服务器端的公钥和私钥,用来进行非对称加密,客户端生成的随机密钥,用来进行对称加密。
一个https请求实际上包含了两次http传输:
1.客户端向服务器发起https请求,连接到服务器的443端口
2.服务器端有一个密钥对,进行非对称加密使用,服务器端保存私钥,公钥发给别人。
3.服务器将自己的公钥发送给客户端
4.客户端收到服务器端的证书后,验证数字证书的合法性。若公钥合格,客户端生成一个随机值,用于对称加密,称为客户端密钥。然后用服务器的公钥对客户端密钥进行非对称加密。第一次http请求结束。
5.客户端发起https中的第二个http请求,将加密之后的客户端密钥发给服务器。
6.服务器收到后,用自己的私钥进行非对称解密,得到客户端密钥,对数据进行对称加密,这样数据就变成了密文。
7.服务器将加密后的密文发送给客户端。
8.客户端收到服务器发送来的密文,用客户端密钥进行对称解密,得到数据。结束。