原文链接:http://tecdat.cn/?p=3138
原文出处:拓端数据部落公众号
随着软件包的进步,使用广义线性混合模型(GLMM)和线性混合模型(LMM)变得越来越容易。由于我们发现自己在工作中越来越多地使用这些模型,我们开发了一套R shiny工具来简化和加速与对象交互的lme4常见任务。
相关视频:线性混合效应模型(LMM,Linear Mixed Models)和R语言实现

线性混合效应模型(LMM,Linear Mixed Models)和R语言实现案例
时长12:13
shiny的应用程序和演示
演示此应用程序功能的最简单方法是使用Shiny应用程序,在此处启动一些指标以帮助探索模型。

在第一个选项卡上,该函数显示用户选择的数据的预测区间。该函数通过从固定效应和随机效应项的模拟分布中抽样并组合这些模拟估计来快速计算预测区间,以产生每个观察的预测分布。

在下一个选项卡上,固定效应和组级效果的分布在置信区间图上显示。这些对于诊断非常有用,并提供了检查各种参数的相对大小的方法。
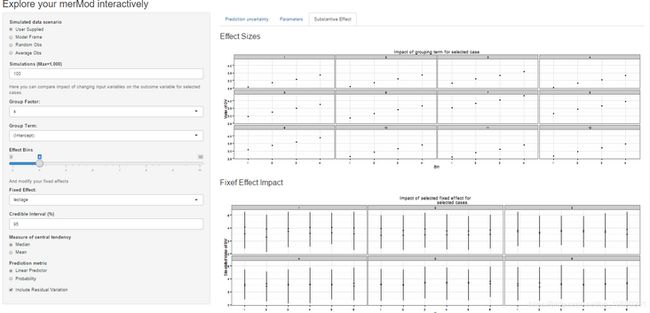
在第三个标签上有一些方便的方法,显示效果的影响或程度predictInterval。对于每种情况,最多12个,在所选数据类型中,用户可以查看更改固定效应的影响。这允许用户比较变量之间的效果大小,以及相同数据之间的模型之间的效果大小。
预测
预测像这样。
predict(m1, newdata
#> 1 2 3 4 5 6 7 8
#> 3.146336 3.165211 3.398499 3.114248 3.320686 3.252670 4.180896 3.845218
#> 9 10
#> 3.779336 3.331012预测lm和glm:
predInte(m1, newdata = Eval\[1:10, \], n.sims = 500, level = 0.9,
#> fit lwr upr
#> 1 3.074148 1.112255 4.903116
#> 2 3.243587 1.271725 5.200187
#> 3 3.529055 1.409372 5.304214
#> 4 3.072788 1.079944 5.142912
#> 5 3.395598 1.268169 5.327549
#> 6 3.262092 1.333713 5.304931预测区间较慢,因为它是模拟计算。
可视化
可视化检查对象的功能。最简单的是得到固定和随机效应参数的后验分布。
head(Sim)
#> term mean median sd
#> 1 (Intercept) 3.22673524 3.22793168 0.01798444
#> 2 service1 -0.07331857 -0.07482390 0.01304097
#> 3 lectage.L -0.18419526 -0.18451731 0.01726253
#> 4 lectage.Q 0.02287717 0.02187172 0.01328641
#> 5 lectage.C -0.02282755 -0.02117014 0.01324410我们可以这样绘制:
pltsim(sim(m1, n.sims = 100), level = 0.9, stat = 'median'
我们还可以快速制作随机效应的图:
head(Sims)
#> groupFctr groupID term mean median sd
#> 1 s 1 (Intercept) 0.15317316 0.11665654 0.3255914
#> 2 s 2 (Intercept) -0.08744824 -0.03964493 0.2940082
#> 3 s 3 (Intercept) 0.29063126 0.30065450 0.2882751
#> 4 s 4 (Intercept) 0.26176515 0.26428522 0.2972536
#> 5 s 5 (Intercept) 0.06069458 0.06518977 0.3105805plotR((m1, n.sims = 100), stat = 'median', sd = TRUE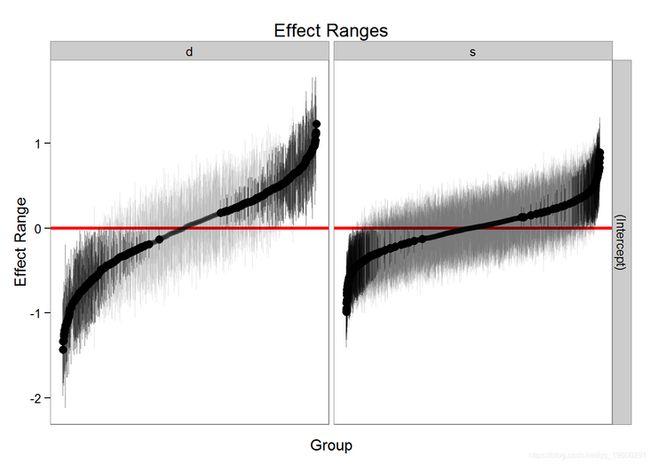
有时,随机效应可能难以解释
Rank(m1, groupFctr = "d")
head(ranks)
#> d (Intercept) (Intercept)_var ER pctER
#> 1 1866 1.2553613 0.012755634 1123.806 100
#> 2 1258 1.1674852 0.034291228 1115.766 99
#> 3 240 1.0933372 0.008761218 1115.090 99
#> 4 79 1.0998653 0.023095979 1112.315 99
#> 5 676 1.0169070 0.026562174 1101.553 98
#> 6 66 0.9568607 0.008602823 1098.049 97效果模拟
解释LMM和GLMM模型的结果很困难,尤其是不同参数对预测结果的相对影响。
impact(m1, Eval\[7, \], groupFctr = "d", breaks = 5,
n.sims = 300, level = 0.9)
#> case bin AvgFit AvgFitSE nobs
#> 1 1 1 2.787033 2.801368e-04 193
#> 2 1 2 3.260565 5.389196e-05 240
#> 3 1 3 3.561137 5.976653e-05 254
#> 4 1 4 3.840941 6.266748e-05 265
#> 5 1 5 4.235376 1.881360e-04 176结果表明yhat根据我们提供的newdata在组因子系数的大小方面,从第一个到第五个分位数的变化。
ggplot(impSim, aes(x = factor(bin), y = AvgFit, ymin = AvgFit - 1.96*AvgFitSE,
ymax = AvgFit + 1.96*AvgFitSE)) +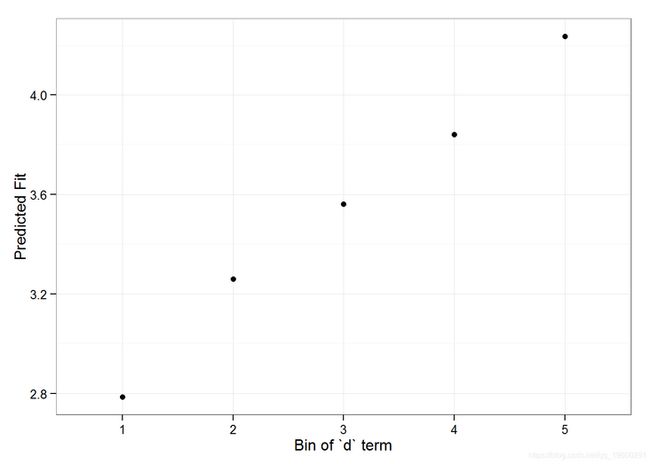
非常感谢您阅读本文,有任何问题请在下面留言!

最受欢迎的见解
2.R语言用Rshiny探索lme4广义线性混合模型(GLMM)和线性混合模型(LMM)
6.线性混合效应模型Linear Mixed-Effects Models的部分折叠Gibbs采样
8.R语言中基于混合数据抽样(MIDAS)回归的HAR-RV模型预测GDP增长回归的HAR-RV模型预测GDP增长")