一、Android分层架构
不管是早期的MVC、MVP,还是最新的MVVM和MVI架构,这些框架一直解决的都是一个数据流的问题。一个良好的数据流框架,每一层的职责是单一的。例如,我们可以在表现层(Presentation Layer)的基础上添加一个领域层(Domain Layer) 来保存业务逻辑,使用数据层(Data Layer)对上层屏蔽数据来源(数据可能来自远程服务,可能是本地数据库)。
在Android中,一个典型的Android分层架构图如下:
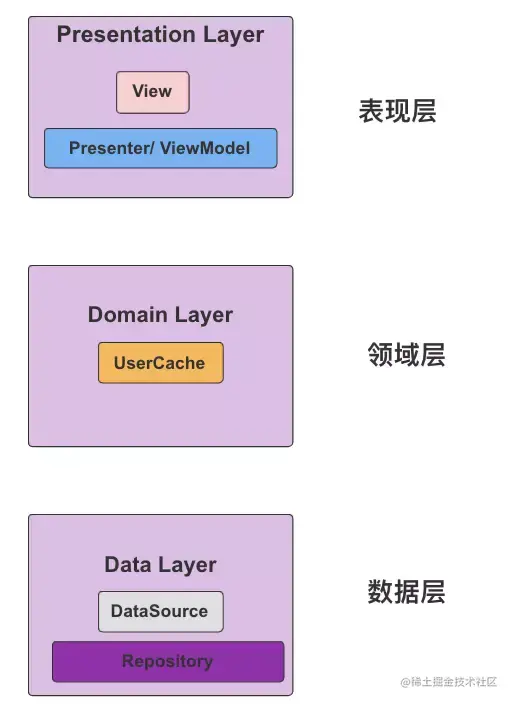
其中,我们需要重点看下Presenter 和 ViewModel, Presenter 和 ViewModel向 View 提供数据的机制是不同的。
- Presenter: Presenter通过持有 View 的引用并直接调用操作 View,以此向 View 提供和更新数据。
- ViewModel:ViewModel 通过将可观察的数据暴露给观察者来向 View 提供和更新数据。
目前,官方提供的可观察的数据组件有LiveData、StateFlow和SharedFlow。可能大家对LiveData比较熟悉,配合ViewModel可以很方便的实现数据流的流转。不过,LiveData也有很多常见的缺陷,并且使用场景也比较固定,如果网上出现了KotlinFlow 替代 LiveData的声音。那么 Flow 真的会替代 LiveData吗?Flow 真的适合你的项目吗?看完下面的分析后,你定会有所收获。
二、ViewModel + LiveData
ViewModel的作用是将视图和逻辑进行分离,Activity或者Fragment只负责UI显示部分,网络请求或者数据库操作则有ViewModel负责。ViewModel旨在以注重生命周期的方式存储和管理界面相关的数据,让数据可在发生屏幕旋转等配置更改后继续留存。并且ViewModel不持有View层的实例,通过LiveData与Activity或者Fragment通讯,不需要担心潜在的内存泄漏问题。
而LiveData 则是一种可观察的数据存储器类,与常规的可观察类不同,LiveData 具有生命周期感知能力,它遵循其他应用组件(如 Activity、Fragment 或 Service)的生命周期。这种感知能力可确保LiveData当数据源发生变化的时候,通知它的观察者更新UI界面。同时它只会通知处于Active状态的观察者更新界面,如果某个观察者的状态处于Paused或Destroyed时那么它将不会收到通知,所以不用担心内存泄漏问题。
下面是官方发布的架构组件库的生命周期的说明:

2.1 LiveData 特性
通过前面的介绍可以知道,LiveData 是 Android Jetpack Lifecycle 组件中的内容,具有生命周期感知能力。一句话概括就是:LiveData 是可感知生命周期的,可观察的,数据持有者。
特点如下:
- 观察者的回调永远发生在主线程
- 仅持有单个且最新的数据
- 自动取消订阅
- 提供「可读可写」和「仅可读」两个版本收缩权限
- 配合 DataBinding 实现「双向绑定」
观察者的回调永远发生在主线程
因为LiveData 是被用来更新 UI的,因此 Observer 接口的 onChanged() 方法必须在主线程回调。
public interface Observer{ void onChanged(T t); }
背后的道理也很简单,LiveData 的 setValue() 发生在主线程(非主线程调用会抛异常),而如果调用postValue()方法,则它的内部会切换到主线程调用 setValue()。
protected void postValue(T value) {
boolean postTask;
synchronized (mDataLock) {
postTask = mPendingData == NOT_SET;
mPendingData = value;
}
if (!postTask) {
return;
}
ArchTaskExecutor.getInstance().postToMainThread(mPostValueRunnable);
}
可以看到,postValue()方法的内部调用了postToMainThread()实现线程的切换,之后遍历所有观察者的 onChanged() 方法。
仅持有单个且最新数据
作为数据持有者,LiveData仅持有【单个且最新】的数据。单个且最新,意味着 LiveData 每次只能持有一个数据,如果有新数据则会覆盖上一个。并且,由于LiveData具备生命周期感知能力,所以观察者只会在活跃状态下(STARTED 到 RESUMED)才会接收到 LiveData 最新的数据,在非活跃状态下则不会收到。
自动取消订阅
可感知生命周期的重要优势就是可以自动取消订阅,这意味着开发者无需手动编写那些取消订阅的模板代码,降低了内存泄漏的可能性。背后的实现逻辑是在生命周期处于 DESTROYED 时,移除观察者。
@Override
public void onStateChanged(@NonNull LifecycleOwner source,
@NonNull Lifecycle.Event event) {
Lifecycle.State currentState = mOwner.getLifecycle().getCurrentState();
if (currentState == DESTROYED) {
removeObserver(mObserver);
return;
}
... //省略其他代码
}
提供「可读可写」和「仅可读」两种方式
LiveData 提供了setValue() 和 postValue()两种方式来操作实体数据,而为了细化权限,LiveData又提供了mutable(MutableLiveData) 和 immutable(LiveData) 两个类,前者「可读可写」,后者则「仅可读」。
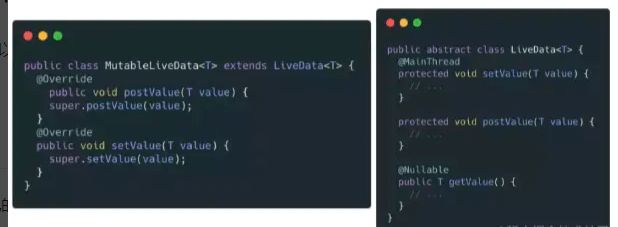
配合 DataBinding 实现「双向绑定」
LiveData 配合 DataBinding 可以实现更新数据自动驱动UI变化,如果使用「双向绑定」还能实现 UI 变化影响数据的变化功能。
2.2 LiveData的缺陷
正如前面说的,LiveData有自己的使用场景,只有满足使用场景才会最大限度的发挥它的功能,而下面这些则是在设计时将自带的一些缺陷:
- value 可以是 nullable 的
- 在 fragment 订阅时需要传入正确的 lifecycleOwner
- 当 LiveData 持有的数据是「事件」时,可能会遇到「粘性事件」
- LiveData 是不防抖的
- LiveData 的 transformation 需要工作在主线程
value 可以是 nullable 的
由于LiveData的getValue() 是可空的,所以在使用时应该注意判空,否则容易出现空指针的报错。
@Nullable
public T getValue() {
Object data = mData;
if (data != NOT_SET) {
return (T) data;
}
return null;
}
传入正确的 lifecycleOwner
Fragment 调用 LiveData的observe() 方法时传入 this 和 viewLifecycleOwner 的含义是不一样的。因为Fragment与Fragment中的View的生命周期并不一致,有时候我们需要的让observer感知Fragment中的View的生命周期而非Fragment。
粘性事件
粘性事件的定义是,发射的事件如果早于注册,那么注册之后依然可以接收到的事件,这一现象称为粘性事件。解决办法是:将事件作为状态的一部分,在事件被消费后,不再通知观察者。推荐两种解决方式:
- KunMinX/UnPeek-LiveData
- 使用kotlin 扩展函数和 typealias 封装解决「粘性」事件的 LiveData
默认不防抖
当setValue()/postValue() 传入相同的值且多次调用时,观察者的 onChanged() 也会被多次调用。不过,严格来讲,这也不算一个问题,我们只需要在调用 setValue()/postValue() 前判断一下 vlaue 与之前是否相同即可。
transformation 工作在主线程
有些时候,我们需要对从Repository 层得到的数据进行处理。例如,从数据库获得 User列表,我们需要根据 id 获取某个 User, 那么就需要用到MediatorLiveData 和 Transformatoins 来实现。
- Transformations.map
- Transformations.switchMap
并且,map 和 switchMap 内部均是使用 MediatorLiveData的addSource() 方法实现的,而该方法会在主线程调用,使用不当会有性能问题。
@MainThread publicvoid addSource(@NonNull LiveDatasource, @NonNull Observer onChanged) { Sourcee = new Source<>(source, onChanged); Source existing = mSources.putIfAbsent(source, e); if (existing != null && existing.mObserver != onChanged) { throw new IllegalArgumentException( "This source was already added with the different observer"); } if (existing != null) { return; } if (hasActiveObservers()) { e.plug(); } }
2.3 LiveData 小结
LiveData 是一种可观察的数据存储器类,与常规的可观察类不同,LiveData 具有生命周期感知能力,它遵循其他应用组件(如 Activity、Fragment 或 Service)的生命周期。这种感知能力可确保LiveData当数据源发生变化的时候,通知它的观察者更新UI界面。同时它只会通知处于Active状态的观察者更新界面,如果某个观察者的状态处于Paused或Destroyed时那么它将不会收到通知,所以不用担心内存泄漏问题。
同时,LiveData 专注单一功能,因此它的一些方法使用上是有局限性的,并且需要配合 ViewModel 使用才能显示其价值。
三、Flow
3.1 简介
Flow是Google官方提供的一套基于kotlin协程的响应式编程模型,它与RxJava的使用类似,但相比之下Flow使用起来更简单,另外Flow作用在协程内,可以与协程的生命周期绑定,当协程取消时,Flow也会被取消,避免了内存泄漏风险。
协程是轻量级的线程,本质上协程、线程都是服务于并发场景下,其中协程是协作式任务,线程是抢占式任务。默认协程用来处理实时性不高的数据,请求到结果后整个协程就结束了。比如,有下面一个例子:
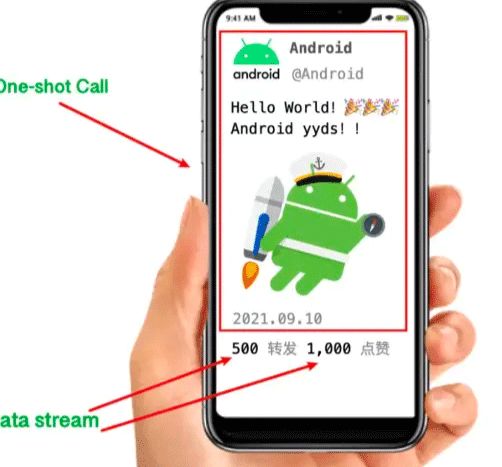
其中,红框中需要展示的内容实时性不高,而需要交互的,比如转发和点赞属于实时性很高的数据需要定时刷新。对于实时性不高的场景,直接使用 Kotlin 的协程处理即可,比如。
suspend fun loadData(): Data
uiScope.launch {
val data = loadData()
updateUI(data)
}
而对于实时性要求较高的场景,上面的方式就不起作用了,此时需要用到Kotlin提供的Flow数据流。
fun dataStream(): FlowuiScope.launch {
dataStream().collect { data ->
updateUI(data)
}
}
3.2 基本概念
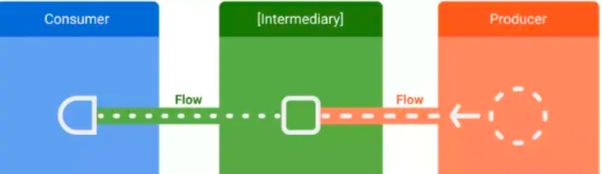
Kotlin的数据流主要由三个成员组成,分别是生产者、消费者和中介。 生产者:生成添加到数据流中的数据,可以配合得协程使用,使用异步方式生成数据。 中介(可选):可以修改发送到数据流的值,或修正数据流本身。 消费者:使用方则使用数据流中的值。
其中,中介可以对数据流中的数据进行更改,甚至可以更改数据流本身,他们的架构示意图如下。
在Kotlin中,Flow 是一种冷流,不过有一种特殊的Flow( StateFlow/SharedFlow) 是热流。什么是冷流,他和热流又有什么关系呢?
冷流:只有订阅者订阅时,才开始执行发射数据流的代码。并且冷流和订阅者只能是一对一的关系,当有多个不同的订阅者时,消息是重新完整发送的。也就是说对冷流而言,有多个订阅者的时候,他们各自的事件是独立的。 热流:无论有没有订阅者订阅,事件始终都会发生。当 热流有多个订阅者时,热流与订阅者们的关系是一对多的关系,可以与多个订阅者共享信息。
3.3 StateFlow
前面说过,冷流和订阅者只能是一对一的关系,当我们要实现一个流多个订阅者的场景时,就需要使用热流了。
StateFlow 是一个状态容器式可观察数据流,可以向其收集器发出当前状态更新和新状态更新。可以通过其 value 属性读取当前状态值,如需更新状态并将其发送到数据流,那么就需要使用MutableStateFlow。
基本使用
在Android 中,StateFlow 非常适合需要让可变状态保持可观察的类。由于StateFlow并不是系统API,所以使用前需要添加依赖:
dependencies {
... //省略其他
implementation "androidx.activity:activity-ktx:1.3.1"
implementation "androidx.fragment:fragment-ktx:1.4.1"
implementation 'org.jetbrains.kotlinx:kotlinx-coroutines-android:1.6.1'
}
接着,我们需要创建一个ViewModel,比如:
class StateFlowViewModel: ViewModel() {
val data = MutableStateFlow(0)
fun add(v: View) {
data.value++
}
fun del(v: View) {
data.value--
}
}
可以看到,我们使用MutableStateFlow包裹需要操作的数据,并添加了add()和del()两个方法。然后,我们再编写一段测试代码实现数据的修改,并自动刷新数据。
class StateFlowActivity : AppCompatActivity() {
private val viewModel by viewModels()
private val mBinding : ActivityStateFlowBinding by lazy {
ActivityStateFlowBinding.inflate(layoutInflater)
}
override fun onCreate(savedInstanceState: Bundle?) {
super.onCreate(savedInstanceState)
setContentView(mBinding.root)
initFlow()
}
private fun initFlow() {
mBinding.apply {
btnAdd.setOnClickListener {
viewModel.add(it)
}
btnDel.setOnClickListener {
viewModel.del(it)
}
}
}
}
上面代码中涉及到的布局代码如下:
上面代码中,我们使用了DataBing写法,因此不需要再手动的绑定数据和刷新数据。
3.4 SharedFlow
SharedFlow基本概念
SharedFlow提供了SharedFlow 与 MutableSharedFlow两个版本,平时使用较多的是MutableSharedFlow。它们的区别是,SharedFlow可以保留历史数据,MutableSharedFlow 没有起始值,发送数据时需要调用 emit()/tryEmit() 方法。
首先,我们来看看SharedFlow的构造函数:
public funMutableSharedFlow( replay: Int = 0, extraBufferCapacity: Int = 0, onBufferOverflow: BufferOverflow = BufferOverflow.SUSPEND ): MutableSharedFlow
可以看到,MutableSharedFlow需要三个参数:
- replay:表示当新的订阅者Collect时,发送几个已经发送过的数据给它,默认为0,即默认新订阅者不会获取以前的数据
- extraBufferCapacity:表示减去replay,MutableSharedFlow还缓存多少数据,默认为0
- onBufferOverflow:表示缓存策略,即缓冲区满了之后Flow如何处理,默认为挂起。除此之外,还支持DROP_OLDEST 和DROP_LATEST 。
//ViewModel val sharedFlow=MutableSharedFlow() viewModelScope.launch{ sharedFlow.emit("Hello") sharedFlow.emit("SharedFlow") } //Activity lifecycleScope.launch{ viewMode.sharedFlow.collect { print(it) } }
基本使用
SharedFlow并不是系统API,所以使用前需要添加依赖:
dependencies {
... //省略其他
implementation "androidx.activity:activity-ktx:1.3.1"
implementation "androidx.fragment:fragment-ktx:1.4.1"
implementation 'org.jetbrains.kotlinx:kotlinx-coroutines-android:1.6.1'
}
接下来,我们创建一个SharedFlow,由于需要一对多的进行通知,所以我们MutableSharedFlow,然后重写postEvent()方法,
代码如下:
object LocalEventBus {
private val events= MutableSharedFlow< Event>()
suspend fun postEvent(event: Event){
events.emit(event)
}
}
data class Event(val timestamp:Long)
接下来,我们再创建一个ViewModel,里面添加startRefresh()和cancelRefresh()两个方法,
如下:
class SharedViewModel: ViewModel() {
private lateinit var job: Job
fun startRefresh(){
job=viewModelScope.launch (Dispatchers.IO){
while (true){
LocalEventBus.postEvent(Event(System.currentTimeMillis()))
}
}
}
fun cancelRefresh(){
job.cancel()
}
}
前面说过,一个典型的Flow是由三部分构成的。所以,此处我们先新建一个用于数据消费的Fragment
代码如下:
class FlowFragment: Fragment() {
private val mBinding : FragmentFlowBinding by lazy {
FragmentFlowBinding.inflate(layoutInflater)
}
override fun onCreateView(
inflater: LayoutInflater, container: ViewGroup?,
savedInstanceState: Bundle?
): View? {
return mBinding.root
}
override fun onStart() {
super.onStart()
lifecycleScope.launchWhenCreated {
LocalEventBus.events.collect {
mBinding.tvShow.text=" ${it.timestamp}"
}
}
}
}
FlowFragment的主要作用就是接收LocalEventBus的数据,并显示到视图上。接下来,我们还需要创建一个数据的生产者,为了简单,我们只在生产者页面中开启协程,
代码如下:
class FlowActivity : AppCompatActivity() {
private val viewModel by viewModels()
private val mBinding : ActivityFlowBinding by lazy {
ActivityFlowBinding.inflate(layoutInflater)
}
override fun onCreate(savedInstanceState: Bundle?) {
super.onCreate(savedInstanceState)
setContentView(mBinding.root)
initFlow()
}
private fun initFlow() {
mBinding.apply {
btnStart.setOnClickListener {
viewModel.startRefresh()
}
btnStop.setOnClickListener {
viewModel.cancelRefresh()
}
}
}
}
其中,FlowActivity代码中涉及的布局如下:
最后,当我们运行上面的代码时,就会在FlowFragment的页面上显示当前的时间戳,并且页面的数据会自动进行刷新。
3.5 冷流转热流
前文说过,Kotlin的Flow是一种冷流,而StateFlow/SharedFlow则属于热流。那么有人会问:怎么将冷流转化为热流呢?答案就是kotlin提供的shareIn()和stateIn()两个方法。
首先,来看一下StateFlow的shareIn的定义:
public funFlow .stateIn( scope: CoroutineScope, started: SharingStarted, initialValue: T ): StateFlow
shareIn方法将流转换为SharedFlow,需要三个参数,我们重点看一下started参数,表示流启动的条件,支持三种:
- SharingStarted.Eagerly:无论当前有没有订阅者,流都会启动,订阅者只能接收到replay个缓冲区的值。
- SharingStarted.Lazily:当有第一个订阅者时,流才会开始,后面的订阅者只能接收到replay个缓冲区的值,当没有订阅者时流还是活跃的。
- SharingStarted.WhileSubscribed:只有满足特定的条件时才会启动。
接下来,我们在看一下SharedFlow的shareIn的定义:
public funFlow .shareIn( scope: CoroutineScope, started: SharingStarted, replay: Int = 0 ): SharedFlow
此处,我们重点看下replay参数,该参数表示转换为SharedFlow之后,当有新的订阅者的时候发送缓存中值的个数。
3.6 StateFlow与SharedFlow对比
从前文的介绍可以知道,StateFlow与SharedFlow都是热流,都是为了满足流的多个订阅者的使用场景的,一时间让人有些傻傻分不清,那StateFlow与SharedFlow究竟有什么区别呢?总结起来,大概有以下几点:
- SharedFlow配置更为灵活,支持配置replay、缓冲区大小等,StateFlow是SharedFlow的特殊化版本,replay固定为1,缓冲区大小默认为0。
- StateFlow与LiveData类似,支持通过myFlow.value获取当前状态,如果有这个需求,必须使用StateFlow。
- SharedFlow支持发出和收集重复值,而StateFlow当value重复时,不会回调collect给新的订阅者,StateFlow只会重播当前最新值,SharedFlow可配置重播元素个数(默认为0,即不重播)。
从上面的描述可以看出,StateFlow为我们做了一些默认的配置,而SharedFlow泽添加了一些默认约束。总的来说,SharedFlow相比StateFlow更灵活。
四、总结
目前,官方提供的可观察的数据组件有LiveData、StateFlow和SharedFlow。LiveData是Android早期的数据流组件,具有生命周期感知能力,需要配合ViewModel才能实现它的价值。不过,LiveData也有很多使用场景缺陷,常见的有粘性事件、不支持防抖等。
于是,Kotlin在1.4.0版本,陆续推出了StateFlow与SharedFlow两个组件,StateFlow与SharedFlow都是热流,都是为了满足流的多个订阅者的使用场景,不过它们也有微妙的区别,具体参考前面内容的说明。
到此这篇关于一文读懂Android Kotlin的数据流的文章就介绍到这了,更多相关Android Kotlin内容请搜索脚本之家以前的文章或继续浏览下面的相关文章希望大家以后多多支持脚本之家!