人工智能导论实验——基于神经网络的情感分类实验
基于神经网络的情感分类实验
一、实验目的:
理解循环神经网络RNN和LSTM、GRU的结构和原理,了解梯度传播。通过构建循环神经网络RNN和LSTM情感分类实例,熟悉循环神经网络RNN、LSTM和GRU的原理、结构和工作过程。
二、实验原理
循环神经网络RNN是一种对序列数据建模的神经网络。RNN不同于前向神经网络,它的层内、层与层之间的信息可以双向传递,更高效地存储信息,利用更复杂的方法来更新规则,通常用于处理信息序列的任务。如下图所示,循环神经网络循环接受序列的每个特征向量 ���t,并刷新内部状态向量h���,同时形成输出���t 。如果使用张量���xh 、���hh 和偏置���来参数化������网络,按照下式更新状态。
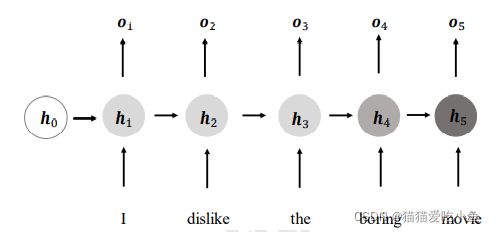
(a)展开的RNN模型
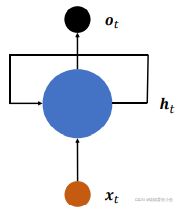
(b)折叠的RNN模型
为了能够延长循环神经网络的短时记忆,使得网络可以有效利用较大范围内的训练数据,从而提升性能。1997 年,瑞士人工智能科学家 Jürgen Schmidhuber 提出了长短时记忆网络(Long Short-Term Memory,简称 LSTM)。长短期记忆网络能够学习长期依赖关系,并可保留误差,在沿时间和层进行反向传递时,可以将误差保持在更加恒定的水平,让循环网络能够进行多个时间步的学习,从而建立远距离因果联系。LSTM 相对于基础的 RNN 网络来 说,记忆能力更强,更擅长处理较长的序列信号数据,LSTM 提出后,被广泛应用在序列预测、自然语言处理等任务中,几乎取代了基础的 RNN 模型。 相对于基础的 RNN网络只有一个状态向量h ���,LSTM 新增了一个状态向量������,同时引入了门控(Gate)机制,通过门控单元来控制信息的遗忘和刷新。

图2 LSTM结构框图
门限循环单元本质上就是一个没有输出门的长短期记忆网络,因此它在每个时间步都会将记忆单元中的所有内容写入整体网络,其结构如下图3所示。GRU 把内部状态向量和输出向量合并,统一为状态向量ht,门控数量也减少到 2 个:复位门 (Reset Gate)和更新门(Update Gate)。更新门是遗忘门和输入门的结合体。将神经元状态和隐状态合并,更新门用于控制前一时刻的状态信息被带入到当前状态中的程度,更新门的值越大说明前一时刻的状态信息带入越多。复位门/重置门用于控制忽略前一时刻的状态信息的程度,重置门的值越小说明忽略的越多。这个模型比长短期记忆网络更加简化,也变得越来越流行。
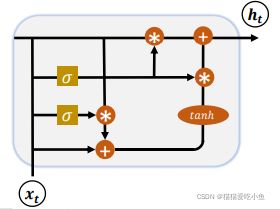
图3 GRU结构框图
三、实验条件:
python 3.6以上,TensorFlow 2.0。自主安装64位的python,以及TensorFlow、numpy等第三方库,新建一个文件夹datasets (C:\Users\A\.keras\datasets),把imdb.npz和imdb_word_index.json放入datasets文件夹里,另外解压glove.6B文件。
四、实验内容:
1.使用经典的 IMDB 影评数据集来完成情感分类任务。IMDB 影评数据集包含了50000 条用户评价,评价的标签分为消极和积极,其中 IMDB 评级<5 的用户评价标注为0,即消极;IMDB 评价>=7 的用户评价标注为 1,即积极。25000 条影评用于训练集,25,000 条用于测试集。通过 Keras 提供的数据集 datasets 工具加载 IMDB 数据集。设置批量大小batchsz为128,句子最大长度max_review_len 为80,通过 keras.preprocessing.sequence.pad_sequences()函数将大于80的句子部分截断,小于80的填充,保证到截断填充后的句子长度统一为 80,最后通过 Dataset 类包裹成数据集对象,并丢掉最后一个不够 batchsz 的 batch。
2. 构建RNN模型,包括一个Embedding 层、两 个 RNN 层和一个分类网络层对IMDB 影评数据集实现情感分类。设置词向量编码长度embedding_len = 100,然后输入序列通过 Embedding 层完成词向量编码,循环通过两个 RNN 层,提取语义特征,取最后一层的最后时间戳的状态向量输出送入分类网络,经过 Sigmoid 激活函数后得到输出概率。其次使用 Keras 的 Compile&Fit 方式训练网络,设置优化器为 Adam 优化 器,学习率为 0.001,误差函数选用 2 分类的交叉熵损失函数 BinaryCrossentropy,测试指标采用准确率。把参数设置、训练和测试结果,分别填入下表1和表2。(注:表中空白区域和?都需要填写完整)1个单词一个神经元
训练集的形状: (25000,) 218 (25000,)
测试集的形状: (25000,) 68 (25000,)
表1 RNN网络的参数
| 数据集参数 |
网络模型参数 |
训练参数 |
|||
| 批量大小 |
128 |
RNN状态向量长度 |
64 |
学习率 |
0.001 |
| 句子最大长度 |
80 |
输出神经元数 |
1 |
训练次数 |
35 |
| 词向量编码长度 |
100 |
输出激活函数 |
sigmod |
学习算法 |
RMSprop |
| 词汇表大小 |
10000 |
损失函数loss |
BinaryCrossentropy |
||
表2 RNN网络的训练、测试结果
| RNN层数 |
dropout |
训练结果(最后一次的训练损失值和正确率、验证损失值和正确率) |
测试正确率 |
总训练 时间 |
测试 时间 |
| 2 |
无 |
- loss: 0.0024 - accuracy: 0.9993 - val_loss: 2.6463 -val_accuracy: 0.6958 |
- accuracy: 0.6958 |
557s |
3s |
| 2 |
有, 断开率0.5 |
loss: 0.0210 accuracy: 0.9919 val_loss: 0.9990 val_accuracy: 0.7832 |
-accuracy:0.7832 |
498s |
4s |
RNNCell
3.分别构建2层的LSTM和GRU模型,设置参数和表1相同,把不同模型的训练和测试结果填入下表3。
这边统一取迭代次数为35.
| 不同模型 |
训练结果(最后一次的训练损失值和正确率、验证损失值和正确率) |
测试正确率 |
总训练 时间 |
测试 时间 |
| RNN模型(2层) |
- loss: 0.0210 - accuracy: 0.9919 - val_loss: 0.9990 - val_accuracy: 0.7832 |
0.7832131 |
498s |
4s |
| LSTM模型(2层) |
- loss: 0.0279 - accuracy: 0.9901 - val_loss: 0.9520 - val_accuracy: 0.8032 |
0.8032 |
941s |
8s |
| GRU模型(2层) |
-loss: 0.0253 -accuracy: 0.9922 - val_loss: 1.0059 - -val_accuracy: 0.8059 |
0.8058894 |
2566s |
21s |
4. 利用下载的预训练GloVe 词向量表,选择特征长度 100 的文件glove.6B.100d.txt,其中每个词汇使用长度为 100 的向量表示,解压即可。把通过预训练的 GloVe 模型初始化的 Embedding 层的训练结果和随机初始化的 Embedding 层的训练结果填入表4。

图4 GloVe词向量模型文件
表4不同Embedding 层的训练、测试结果
| 参数设置 |
不同模型 |
训练结果(最后一次的训练损失值和正确率、验证损失值和正确率) |
测试正确率 |
总训练 时间 |
测试 时间 |
| 训练次数为50 其它参数同表1 |
LSTM模型(2层、通过预训练的 GloVe 模型初始化的 Embedding 层) |
-loss: 0.3622 -accuracy: 0.8333 -val_loss: 0.3308 -val_accuracy: 0.8505 |
accuracy: 0.8505 |
2150s |
16s |
| LSTM模型(2层、随机初始化的 Embedding 层) |
- loss: 0.0133 - accuracy: 0.9960 - val_loss: 1.1278 - val_accuracy: 0.8065 |
- accuracy: 0.8065 |
1330s |
7s |
|
| GRU模型(2层、通过预训练的 GloVe 模型初始化的 Embedding 层) |
- loss: 0.3629 - accuracy: 0.8371 - val_loss: 0.3450 - val_accuracy: 0.8483 |
0.8483 |
2047s |
7s |
|
| GRU模型(2层、随机初始化的 Embedding 层) |
- loss: 0.0120 - accuracy: 0.9960 - val_loss: 1.1422 - val_accuracy: 0.8060 |
0.8060 |
2565s |
9s |
五、实验报告要求:
1. 按照实验内容,给出相应结果。
2.利用RNN实现情感分类任务时,分析有Dropout与无Dropout对于训练结果、测试结果等的影响。
没有dropout时,测试准确度为0.6958,有dropout时,测试准确度为0.7832,比没有dropout层高很多,模型性能提升了。
3. 比较RNN模型、LSTM模型和GRU模型的结构异同点,分析这3种模型实现同一个情感分类任务的性能差异。
RNN模型、LSTM模型和GRU模型的结构如下。
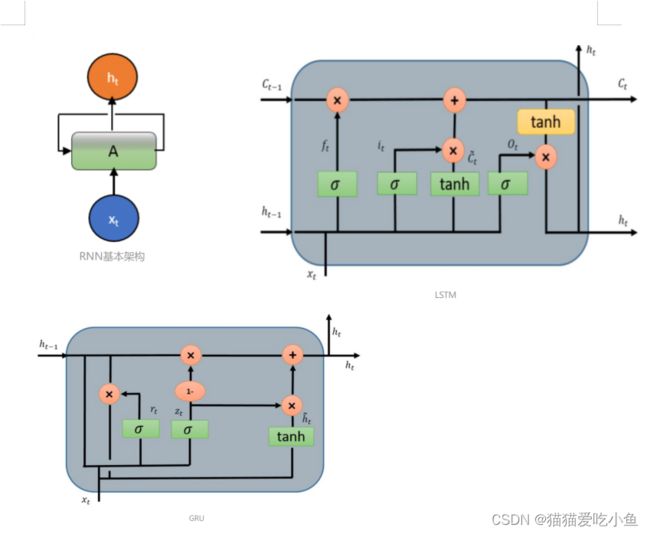
①异同点
相同点:所有 RNN,GRU和LSTM 都具有一种重复神经网络模块的链式的形式。
异同点:
1.在标准的 RNN 中,结构中重复的模块只有一个非常简单的结构,LSTM 的重复神经网络模,不同于单一神经网络层,以一种非常特殊的方式进行交互。
2.LSTM和普通的RNN模型结构的主要区别是加了几个门机制用来控制x 的输入和上一时刻hidden状态的输入。
3.GRU结构相比LSTM,由三个门合并到了两个门:重置门 r ,更新门u,相对应的也减少了一个矩阵参数。再加上还有一个矩阵参数更新 h ^ \hat{h}
,所以由LSTM的4个矩阵参数降低到了三个矩阵参数,计算量比LSTM降低。
②模型效果
GRU模型和LSTM模型训练的准确度差不多,但都比RNN模型的性能更好。GRU最终的模型比标准的 LSTM模型要简单。效果和LSTM差不多,损失值也差不多。但是训练时间长很多。
4. 以预训练的 GloVe 词向量为例,比较通过预训练的 GloVe 模型初始化的 Embedding 层的训练结果和随机初始化的 Embedding 层的训练结果,分析预训练的词向量模型对情感任务分类性能的影响。
Embedding测负责把单词编码为某个词向量,使用GloVe 模型初始化的 Embedding 层,准确率有了很大的提升。比随机化的Embedding要好很多,说明使用GloVe 模型初始化的 Embedding 层得到更好的词向量,对文本分析更加有用。
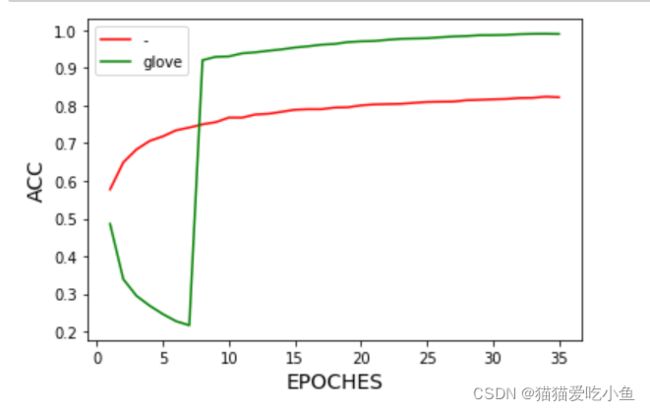
下图中LSTM模型的训练准确度变化曲线,绿色线表示使用GloVe 模型初始化的 Embedding的准确率随迭代次数的变化,红色线为随机 Embedding的变化。可以看出,加了glove初始化的模型更好。
5. 实验心得。
部分模型运行时间太长,又很占内存,但是从训练效果上来说,还是好很多的。