NLP基础知识点:BLEU(及Python代码实现)
Bleu[1]是IBM在2002提出的,用于机器翻译任务的评价
BLEU还有许多变种。根据n-gram可以划分成多种评价指标,常见的指标有BLEU-1、BLEU-2、BLEU-3、BLEU-4四种,其中n-gram指的是连续的单词个数为n。BLEU-1衡量的是单词级别的准确性,更高阶的bleu可以衡量句子的流畅性。
它的总体思想就是准确率。
这里放上准确率(查准率)的公式(摘自西瓜书)作为提醒:

准确率是被预测为正例的样本中,真正例的比例。
假如给定标准译文reference,神经网络生成的句子是candidate,句子长度为n。
candidate就是我们预测出的正例。
candidate中有m个单词出现在reference中,这一部分对应的就是真正例
bleu的1-gram的计算公式就是m/n。
改进的BLEU算法 — 分子截断计数
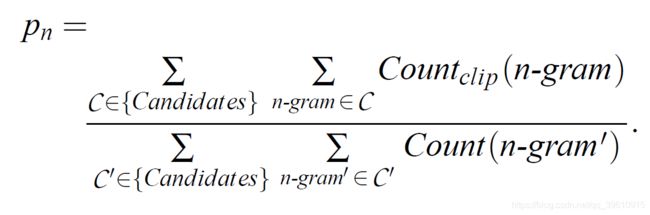
分子释义
- C o u n t c l i p = m i n ( C o u n t , M a x _ R e f _ C o u n t ) Count_{clip}= min(Count, Max\_Ref\_Count) Countclip=min(Count,Max_Ref_Count)
- min表示如果有必要,我们会截断每个单词的计数
- M a x _ R e f _ C o u n t Max\_Ref\_Count Max_Ref_Count表示n−gram在任何一个reference中出现的最大次数
- C o u n t Count Count表示n-gram在reference中出现的次数
- 第一个求和符号统计的是所有的candidate,因为计算时可能有多个句子
- 第二个求和符号统计的是一条candidate中所有的n−gram
分母释义
- 前两个求和符号和分子中的含义一样
- C o u n t ( n − g r a m ′ ) Count(n-gram') Count(n−gram′)表示 n − g r a m ′ n−gram′ n−gram′在candidate中的个数,分母是获得所有的candidate中n-gram的个数。
举例来说:
Candidate: the the the the the the the.
Reference: The cat is on the mat.
Modified Unigram Precision = 2/7
如果没有clip操作,算出的BLEU值将会是7/7,因为candidate中每个词都出现在了reference中
举一个例子来看看实际的计算:
candinate: the cat sat on the mat
reference: the cat is on the mat
计算n−gram的精度:
p 1 p_1 p1=5/6=0.83333
p 2 p_2 p2=3/5=0.6
p 3 p_3 p3=1/4=0.25
p 4 p_4 p4=0/3=0
添加对句子长度的惩罚因子
这里对原论文的描述不太理解,参考了维基百科相关内容。
在翻译时,若出现译文很短的句子时,往往会有较高的BLEU值,因此引入对短句的惩罚因子BP。
如果我们逐句计算“简短”惩罚并平均惩罚,那么短句上的长度偏差将受到严厉的惩罚。
Instead, we compute the brevity penalty over the entire corpus to allow some freedom at the sentence level.
设r为参考语料库总长度,c为翻译语料库总长度。

在多个reference的情况下,r是长度最接近候选句长度的句子长度之和。
如果有三个reference,长度分别为12、15和17个单词,并且候选翻译长度为12个单词,我们希望BP值为1。
称最接近的reference的句子长度为**“best match length”**。
通过对语料库中每个候选句子的"best match length"求和,计算出test corpus’ effective reference length r
然而,在2009年之前NIST评估使用的度量版本中,使用了最短的参考语句。[4]

- e x p ( ∑ n = 1 N w n log p n ) exp(\sum_{n=1}^N w_n \log p_n) exp(∑n=1Nwnlogpn)表示不同的n-gram的 p n p_n pn的加权求和。

In our baseline, we use N = 4 and uniform weights w n w_n wn = 1/N.
下面是一个加了惩罚因子的实例。

示例代码:
单独看不同n-gram计算出的 p n p_n pn
import jieba
from nltk.translate.bleu_score import sentence_bleu
source = r'猫坐在垫子上' # source
target = 'the cat sat on the mat' # target
inference = 'the cat is on the mat' # inference
# 分词
source_fenci = ' '.join(jieba.cut(source))
target_fenci = ' '.join(jieba.cut(target))
inference_fenci = ' '.join(jieba.cut(inference))
# reference是标准答案 是一个列表,可以有多个参考答案,每个参考答案都是分词后使用split()函数拆分的子列表
# # 举个reference例子
# reference = [['this', 'is', 'a', 'duck']]
reference = [] # 给定标准译文
candidate = [] # 神经网络生成的句子
# 计算BLEU
reference.append(target_fenci.split())
candidate = (inference_fenci.split())
score1 = sentence_bleu(reference, candidate, weights=(1, 0, 0, 0))
score2 = sentence_bleu(reference, candidate, weights=(0, 1, 0, 0))
score3 = sentence_bleu(reference, candidate, weights=(0, 0, 1, 0))
score4 = sentence_bleu(reference, candidate, weights=(0, 0, 0, 1))
reference.clear()
print('Cumulate 1-gram :%f' \
% score1)
print('Cumulate 2-gram :%f' \
% score2)
print('Cumulate 3-gram :%f' \
% score3)
print('Cumulate 4-gram :%f' \
% score4)
参考文献
[1] Papineni K , Roukos S , Ward T , et al. BLEU: a Method for Automatic Evaluation of Machine Translation. 2002.
[2] 机器翻译评测——BLEU算法详解 (新增 在线计算BLEU分值)
[3] BLEU详解
[4] 维基百科:BLEU