SpringCloud微服务架构实战:Feign+Hystrix实现RPC调用保护,Java常用面试集合
第一步为UserClient接口定义一个简单的Fallback回退处理实现类,代码如下:
package com.crazymaker.springcloud.user.info.remote.fallback;
//省略import
/**
*Feign客户端接口的Fallback回退处理类
*/
@Component
public class UserClientFallback implements UserClient
{
/**
*获取用户信息RPC失败后的回退方法
*/
@Override
public RestOut detail(Long id)
{
return RestOut.error(“failBack:user detail rest服务调用失败” );
}
}
第二步是在UserClient客户端接口的@FeignClient注解中,将Fallback属性的值配置为上一步定义的Fallback回退处理类UserClientFallback,代码如下:
package com.crazymaker.springcloud.user.info.remote.client;
//省略import
/**
*Feign客户端接口
*@description:获取用户信息的RPC接口类
*/
@FeignClient(value = “uaa-provider”,
configuration = FeignConfiguration.class,
fallback = UserClientFallback.class, #配置回退处理类 path = “/uaa-provider/api/user”)
public interface UserClient
{
@RequestMapping(value = “/detail/v1”, method = RequestMethod.GET)
RestOut detail(@RequestParam(value = “userId”) Long userId);
}
回退处理类的实现已经完成,如何进行验证呢?仍然使用前面定义的demoprovider的REST接口
/api/call/uaa/user/detail/v2,该接口通过UserClient对uaa-provider进行远程调用。具体的演示方式为:
停掉所有uaa-provider服务,然后在demo-provider的swagger-ui界面访问其REST接口
/api/call/uaa/user/detail/v2,该接口的内部代码会通过UserClient远程调用Feign接口对目标uaa-provider的REST接口/api/user/detail/v1发起FeignRPC远程调用,而uaa-provider全部服务处于宕机状态,因此Feign将会触发Hystrix回退,执行Fallback回退处理类UserClientFallback的回退实现方法,返回Fallback回退处理的内容,输出的内容如图2-17所示。
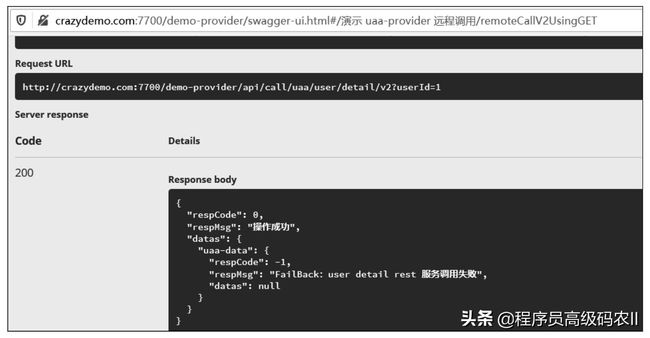
图2-17 UserClientFallback回退处理类生效后的示意图
接下来看第二种方式,定义和使用一个Fallback回退处理工厂类。
第二种方式具体的实现也可以分为两步:第一步创建一个Fallback回退处理工厂类,该工厂类需要实现Hystrix的FallbackFactory回退工厂接口,实现其抽象的create创建方法,在该方法的实现代码中,需要返回一个Feign客户端接口的实现类,方法中的具体实现即为回退处理实例,可以通过匿名类的方式创建一个新的回退处理类,并在该匿名类的每个方法的实现代码中编写好RPC回退逻辑;第二步在Feign客户端接口的关键性注解@FeignClient上配置失败处理工厂类,将fallbackFactory属性的值配置为上一步定义的FallbackFactory回退处理工厂类。
下面介绍具体的实例,演示如何定义和使用一个FallbackFactory回退处理工厂类。这里任意以uaa-client模块中的RPC调用接口UserClient为例进行演示。第一步为其定义一个简单的FallbackFactory回退处理工厂类,代码如下:
package com.crazymaker.springcloud.user.info.remote.fallback;
//省略import
/**
*Feign客户端接口的回退处理工厂类
*/
@Slf4j
@Component
public class UserClientFallbackFactory implements FallbackFactory
{
/**
*创建UserClient客户端的回退处理实例
*/
@Override
public UserClient create(final Throwable cause) {
log.error(“RPC异常了,回退!”,cause);
/**
*创建一个UserClient客户端接口的匿名回退实例
*/
return new UserClient() {
/**
*方法: 获取用户信息RPC失败后的回退方法
*/
@Override
public RestOut detail(Long userId)
{
return RestOut.error(“FallbackFactory fallback:user detail rest服务调用失败” );
}
};
}
}
第二步是在Feign客户端接口UserClient的@FeignClient注解上,将fallbackFactory属性的值配置为上一步定义的UserClientFallbackFactory回退处理工厂类,代码如下:
package com.crazymaker.springcloud.user.info.remote.client;
//省略import
/**
*Feign客户端接口
*@description:获取用户信息的RPC接口类
*/
@FeignClient(value = “uaa-provider”,
configuration = FeignConfiguration.class,
配置回退处理
厂类 fallbackFactory = UserClientFallbackFactory.class, #配置回退处理工厂类
path = “/uaa-provider/api/user”)
public interface UserClient
{
@RequestMapping(value = “/detail/v1”, method = RequestMethod.GET)
RestOut detail(@RequestParam(value = “userId”) Long userId);
}
第二种方式回退工厂类的具体验证过程与第一种方式回退类的验证相同:
停掉所有的uaa-provider服务,然后在demo-provider的swagger-ui界面访问其REST接口
/api/call/uaa/user/detail/v2,此REST接口的内部代码会通过UserClient远程调用Feign接口对目标uaa-provider的REST接口/api/user/detail/v1发起Feign RPC远程调用,而uaa-provider全部服务处于宕机状态,因此Feign将会触发Hystrix回退,执行fallback回退处理工厂类UserClientFallbackFactory的create方法创建一个回退处理类实例,并执行回退处理类实例中的回退处理逻辑,返回回退处理的结果。
在进行失败回退时,使用第一种方式的回退类和使用第二种方式的回退工厂类有什么区别呢?
答案是:在使用第一种方式的回退类时,远程调用RPC过程中所引发的异常已经被回退逻辑彻底地屏蔽掉了。应用程序不太方便干预,也看不到RPC过程中的具体异常,尽管这些异常对于问题的排除非常有帮助。在使用第二种方式的回退工厂类时,应用程序可以通过Java代码对RPC异常进行拦截和处理,包括进行日志输出。
分布式系统面临的雪崩难题
============
在分布式系统中,一个服务可能会依赖很多其他的服务,并且这些服务不可避免有失效的可能。假如一个应用运行30个Provider实例,每个实例99.99%的时间处于正常服务状态,即使只有0.01%的失败率,每个月仍然有几个小时不可用。另外,还有一个大问题:流量洪峰过来时,服务有可能被其他服务所依赖。如果这个Provider实例出现延迟响应,就会导致其他Provider发生更多级联故障,从而导致这个分布式系统不可用。
举一个简单的例子,在一个秒杀系统中,商品(goodprovider)、订单(order-provider)、秒杀(seckill-provider)3个Provider都会通过RPC远程调用到用户账号与认证(uaa-provider)的相关接口,查询用户的相关信息,如图2-18所示。
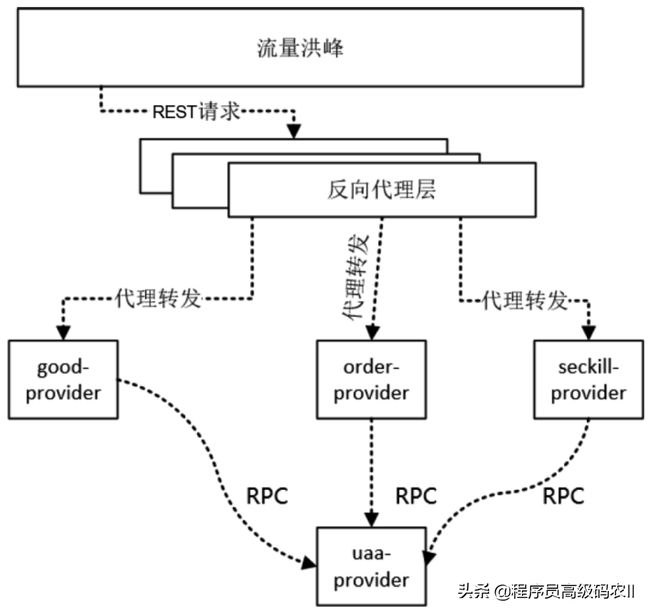
图2-18 秒杀系统中,商品、订单、秒杀、用户4个Provider之间的依 赖示意图
若在流量洪峰过来之时uaa-provider出现响应迟钝(甚至宕机),则商品、订单、秒杀3个Provider都会出现等待超时而导致响应缓慢,由于排队的请求越来越多、单个请求时间变得很长(因为内部都有超时等待),因此各服务节点的系统资源(CPU、内存等)很快会耗尽,最后进入系统性雪崩状态,如图2-19所示。
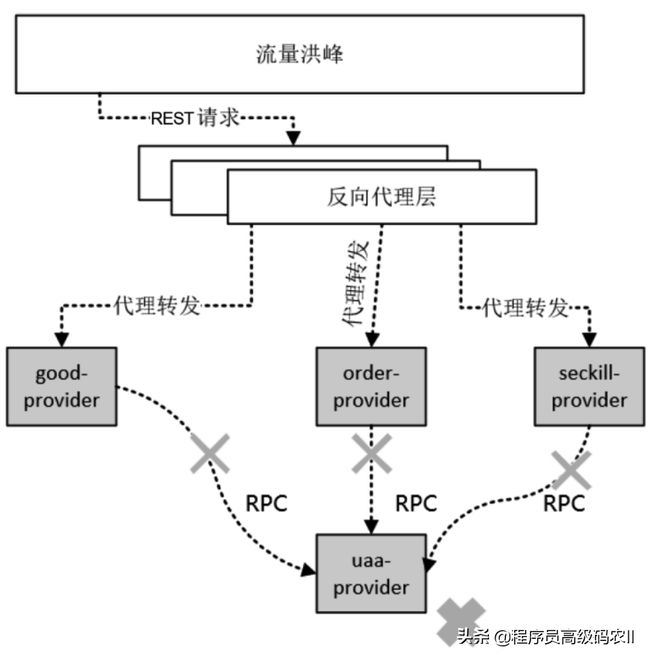
图2-19 流量洪峰过来时因uaa-provider响应缓慢导致整体雪崩
总体来说,在微服务架构中,根据业务拆分成一个个Provider微服务,由于网络原因或者自身的原因,服务并不能保证100%可用,为了保证服务提供者高可用,单个Provider服务通常会多体部署。由于Provider与Provider之间的依赖性,故障或者不可用会沿请求调用链向上传递,对整个系统造成瘫痪的灾难性后果,这就是故障的雪崩效应。
引发雪崩效应的原因比较多,下面是常见的几种:
(1)硬件故障:如服务器宕机、机房断电、光纤被挖断等。
(2)流量激增:如流量异常、巨量请求瞬时涌入(如秒杀)等。
(3)缓存穿透:一般发生在系统重启所有缓存失效时,或者发生在短时间内大量缓存失效时,前端过来的大量请求没有命中缓存,直击后端服务和数据库,造成服务提供者和数据库超负荷运行,引起整体瘫痪。
(4)程序BUG:如程序逻辑BUG导致内存泄漏等原因引发的整体瘫痪。
(5)JVM卡顿:JVM的FullGC时间较长,极端的情况长达数十秒,这段时间内JVM不能提供任何服务。
为了解决雪崩效应,业界提出了熔断器模型。通过熔断器,当一些非核心服务出现响应迟缓或者宕机等异常时,对服务进行降级并提供有损服务,以保证服务的柔性可用,避免引起雪崩效应。
Spring Cloud Hystrix熔断器
========================
在物理学上,熔断器本身是一个开关装置,用在电路上保护线路过载,当线路中有电器发生短路时,熔断器能够及时切断故障,防止发生过载、发热甚至起火等严重后果。分布式架构中的熔断器主要用于RPC接口上,为接口安装上“保险丝”,以防止RPC接口出现拥塞时导致系统压力过大而引起的系统瘫痪,当RPC接口流量过大或者目标Provider出现异常时,熔断器及时切断故障可以起到自我保护的作用。
为什么说熔断器非常重要呢?如果没有过载保护,在分布式系统中,当被调用的远程服务无法使用时,就会导致请求的资源阻塞在远程服务器上而耗尽。很多时候刚开始可能只是出现了局部小规模的故障,然而由于种种原因,故障影响范围越来越大,最终导致全局性的后果。
熔断器通常也叫作熔断器,其具体的工作机制为:统计最近RPC调用发生错误的次数,然后根据统计值中的失败比例等信息来决定是否允许后面的RPC调用继续或者快速地失败回退。
熔断器的3种状态如下:
(1)关闭(closed):熔断器关闭状态,这也是熔断器的初始状态,此状态下RPC调用正常放行。
(2)开启(open):失败比例到一定的阈值之后,熔断器进入开启状态,此状态下RPC将会快速失败,然后执行失败回退逻辑。
(3)半开启(half-open):在打开一定时间之后(睡眠窗口结束),熔断器进入半开启状态,小流量尝试进行RPC调用放行。如果尝试成功,熔断器就变为关闭状态,RPC调用正常;如果尝试失败,熔断器就变为开启状态,RPC调用快速失败。
熔断器状态之间的相互转换关系如图2-20所示。
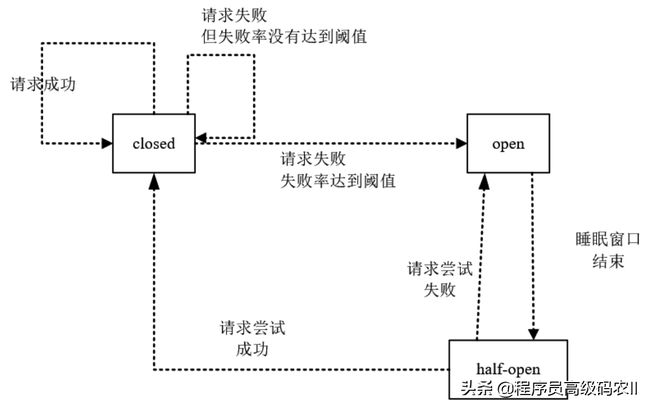
图2-20 熔断器状态之间的相互转换关系
下面重点介绍熔断器的半开启状态。在半开启状态下,允许进行一次RPC调用的尝试,如果实际调用成功,熔断器就会复位到关闭状态,回归正常的模式;但是如果这次RPC调用的尝试失败,熔断器就会返回到开启状态,一直等待到下次半开启状态。
Spring Cloud Hystrix中的熔断器默认是开启的,但是可以通过配置熔断器的参数进行定制。下面是demo-provider微服务中熔断器示例
《一线大厂Java面试题解析+后端开发学习笔记+最新架构讲解视频+实战项目源码讲义》
【docs.qq.com/doc/DSmxTbFJ1cmN1R2dB】 完整内容开源分享
的相关配置:
hystrix:
…
command:
default:
…
circuitBreaker: #熔断器相关配置
enabled: true #是否使用熔断器,默认为true
requestVolumeThreshold: 20 #窗口时间内的最小请求数
sleepWindowInMilliseconds: 5000 #打开后允许一次尝试的睡眠时间,默认配置为5秒
errorThresholdPercentage: 50 #窗口时间内熔断器开启的错误比例,默认配置为50
metrics:
rollingStats:
timeInMilliseconds: 10000 #滑动窗口时间
numBuckets: 10 #滑动窗口的时间桶数以上用到的Hystrix熔断器相关参数分为两类:熔断器相关参数和滑动窗口相关参数。对示例中用到的熔断器的相关参数大致介绍如下:
(1)
hystrix.command.default.circuitBreaker.enabled:该配置用来确定熔断器是否用于跟踪RPC请求的运行状态,或者说用于配置是否启用熔断器,默认值为true。
(2)hystrix.command.default.circuitBreaker.requestVolumeThreshold:
该配置用于设置熔断器触发熔断的最少请求次数。如果设置为20,那么当一个滑动窗口时间内(比如10秒)收到19个请求时,即使19个请求都失败,熔断器也不会打开变成open状态,默认值为20。
(3)
hystrix.command.default.circuitBreaker.errorThresholdPercentage:该配置用于设置错误率阈值,在滑动窗口时间内,当错误率超过此值时,熔断器进入open状态,所有请求都会触发失败回退(fallback),错误率阈值百分比的默认值为50。
(4)
hystrix.command.default.circuitBreaker.sleepWindowInMilliseconds:该配置用于设置熔断器的睡眠窗口,具体指的是确定熔断器打开之后多长时间才允许一次请求尝试执行,默认值为5 000毫秒,表示当熔断器打开后,5 000毫秒内会拒绝所有请求,5 000毫秒后熔断器才会进行入half-open状态。
(5)
hystrix.command.default.circuitBreaker.forceOpen:如果配置为true,熔断器就会被强制打开,所有请求将触发失败回退(Fallback),默认值为false。
熔断器的状态转换与Hystrix的滑动窗口的健康统计值(比如失败比例)相关。接下来对示例中使用到的Hystrix健康统计相关配置大致介绍如下:
(1)
hystrix.command.default.metrics.rollingStats.timeInMilliseconds:设置统计滑动窗口的持续时间(以毫秒为单位),默认值为10 000毫秒。熔断器的打开会根据一个滑动窗口的统计值来计算,若滑动窗口时间内的错误率超过阈值,则熔断器进入开启状态。滑动窗口将被进一步细分为时间桶(Bucket),滑动窗口的统计值等于窗口内所有时间桶的统计信息的累加,每个时间桶的统计信息包含请求成功(Success)、失败(Failure)、超时(Timeout)、被拒(Rejection)的次数。
(2)
hystrix.command.default.metrics.rollingStats.numBuckets:设置一个滑动窗口被划分的时间桶数量,默认值为10。若滑动窗口的持续时间为10 000毫秒,并且一个滑动窗口被划为10个时间桶,则一个时间桶的时间为1秒。所设置的numBuckets(时间桶数量)和timeInMilliseconds(滑动窗口时长)的值有一定关系,必须符合timeInMilliseconds%numberBuckets==0的规则,否则会抛出异常,例如70 000(滑动窗口70 000毫秒)%700(桶数)==0是可以的,但是70000(滑动窗口70 000毫秒)%600(桶数)==400将抛出异常。
以上有关Hystrix熔断器的配置选项使用的是hystrix.command.default前缀,这些默认配置项将对项目中所有FeignRPC接口生效,除非某个Feign RPC接口进行单独配置。如果需要对某个Feign RPC调用进行特殊的配置,配置项前缀的格式如下:
hystrix.command.类名#方法名(参数类型列表)
下面来看一个对单个接口进行特殊配置的例子,以对UserClient类中
的Feign RPC接口/detail/v1进行特殊配置为例。该接口的功能是从user-provider服务获取用户信息,在配置之前先看一下UserClient接口的代码,具体如下: