熔断器Hystrix作用
容错限流的需求
在复杂的分布式系统中通常有很多依赖,如果一个应用不能对来自依赖故障进行隔离,那么应用本身就处于被拖垮的风险中。在一个高流量的网站中,某一个单一后端一旦发生延迟,将会在数秒内导致所有的应用资源被耗尽,这也就是我们常说的雪崩效应。
比如在电商系统的下单业务中,在订单服务创建订单后同步调用库存服务进行库存的扣减,假如库存服务出现了故障,那么会导致下单请求线程会被阻塞,当有大量的下单请求时,则会占满应用连接数从而导致订单服务无法对外提供服务
容错限流的原理
对于基本的容错限流模式,主要有以下几点需要考量:
主动超时:在调用依赖时尽快的超时,可以设置比较短的超时时间,比如2s,防止长时间的等待。
限流:限制最大并发数。
熔断:错误数达到阈值时,类似于保险丝熔断。
隔离:隔离不同的依赖调用
服务降级:资源不足时进行服务降级
断路器模式
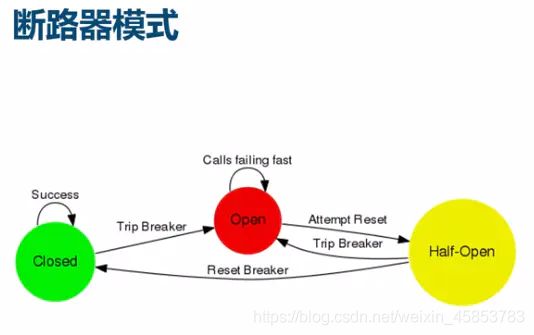
实现流程为:当断路器的开关为关闭时(对应图中的绿色),每次请求进来都是成功的,当后端服务出现问题,请求出现的错误数达到一定的阈值,则会触发断路器为打开状态(对应图中的红色),在断路器为打开状态时,进来的所有请求都会被拒绝,当然也不是一直会拒绝请求,而是弹性的,过了特定的时间后,断路器会进入半打开状态(对应图中的黄色),这是会让一部分请求通过进行尝试,如果尝试还是有问题,则继续进入打开状态,如果尝试没有问题了,则会进入关闭状态。
舱壁隔离模式

舱壁隔离模式可以对资源进行隔离,类似于船的船舱都是被隔离开来的,当其中一个或者几个船舱出现问题,比如漏水,是不会影响到其他的船舱的,从而实现一种资源隔离的效果。
容错理念
- 凡是依赖都有可能会失败。
- 凡是资源都有限制,比如CPU、Memory、Threads、Queue。
- 网络并不可靠,可能存在网络抖动等其他问题。
- 延迟是应用稳定的杀手,延迟会占据大量的资源。
什么是Hystrix
Hystrix是Netflix公司开源的一款容错框架。 它可以完成以下几件事情:
- 资源隔离,包括线程池隔离和信号量隔离,避免某个依赖出现问题会影响到其他依赖。
- 断路器,当请求失败率达到一定的阈值时,会打开断路器开关,直接拒绝后续的请求,并且具有弹性机制,在后端服务恢复后,会自动关闭断路器开关。
- 降级回退,当断路器开关被打开,服务调用超时/异常,或者资源不足(线程、信号量)会进入指定的fallback降级方法。
- 请求结果缓存,hystrix实现了一个内部缓存机制,可以将请求结果进行缓存,那么对于相同的请求则会直接走缓存而不用请求后端服务。
- 请求合并, 可以实现将一段时间内的请求合并,然后只对后端服务发送一次请求。
Hystrix核心概念
资源隔离
资源隔离的思想参考上述的舱壁隔离模式,在hystrix中提供了两种资源隔离策略:线程池隔离、信号量隔离。
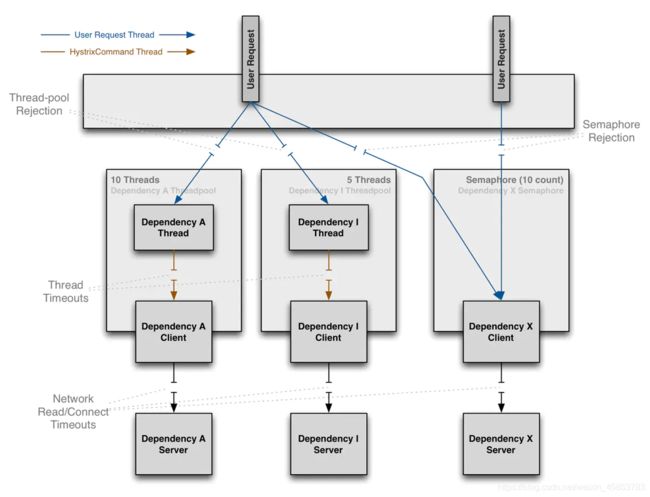
线程池隔离:线程池隔离会为每一个依赖创建一个线程池来处理来自该依赖的请求,不同的依赖线程池相互隔离,就算依赖A出故障,导致线程池资源被耗尽,也不会影响其他依赖的线程池资源。
- 优点:支持排队和超时,支持异步调用。
- 缺点:线程的创建一个调度会造成一定的性能开销。
- 适用场景:适合耗时较长的接口场景,比如接口处理逻辑复杂,且与第三方中间件有交互,因为线程池模式的请求线程与实际转发线程不是同一个,所以可以保证容器有足够的线程来处理新的请求。
信号量隔离模式: 初始化信号量currentCount=0,每进来一个请求需要先将currentCount自增,再判断currentCount的值是否小于系统最大信号量,小于则继续执行,大于则直接返回,拒绝请求。
代码如下:
public boolean tryAcquire() {
int currentCount = this.count.incrementAndGet();
if (currentCount > (Integer)this.numberOfPermits.get()) {
this.count.decrementAndGet();
return false;
} else {
return true;
}
}
- 优点:轻量,无额外的开销,只是一个简单的计数器
- 缺点:不支持任务排队和主动超时;不支持异步调用
- 适用场景:适合能快速响应的接口场景,不适合一些耗时较长的接口场景,因为信号量模式下的请求线程与转发处理线程是同一个,如果接口耗时过长有可能会占满容器的线程数。
| 隔离方式 | 是否支持超时 | 是否支持熔断 | 隔离原理 | 是否异步调用 | 资源消耗 |
|---|---|---|---|---|---|
| 线程池隔离 | 支持,可直接返回 | 支持,当线程池到达maxSize后,再请求会触发fallback接口进行熔断 | 每个服务单独用线程池,请求线程与转发处理线程不是同一个 | 可以是异步,也可以是同步。看调用的方法 | 大,大量线程的上下文切换,容易造成机器负载高 |
| 信号量隔离 | 不支持,如果阻塞,只能通过调用协议(如:socket超时才能返回) | 支持,当信号量达到maxConcurrentRequests后。再请求会触发fallback | 通过信号量的计数器,请求线程与转发处理线程是同一个 | 同步调用,不支持异步 | 小,只是个计数器 |
断路器
断路器工作原理如下:
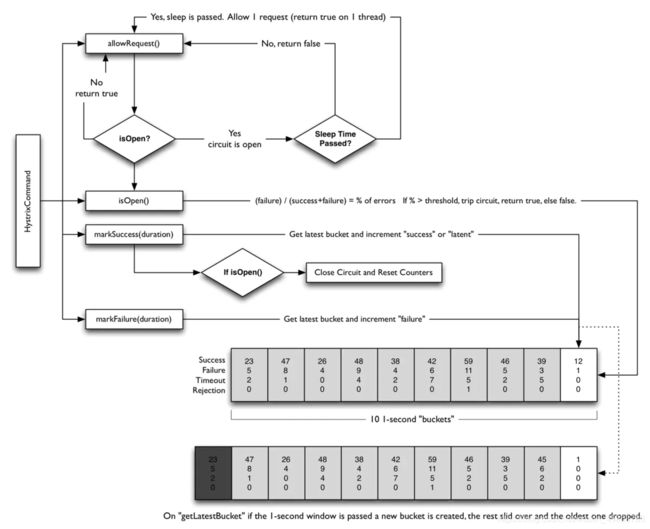
Hystrix是基于滚筒式来处理,每一秒会产生一个buckets,每产生一个新的buckets就会移除一个最老的buckets,默认是10秒一个窗口。buckets在内存中就是一种数据结构,每个buckets会记录Metrics的相关数据,比如成功、失败、超时、拒绝。
当一个HystrixCommand进来后,会先通过allowRequest()方法判断是否允许通过该次请求,allowRequest()方法会通过isOpen判断断路器是否打开。断路器关闭,则允许通过该次请求;断路器打开,则会判断是否过了睡眠周期。没有过睡眠周期则返回false,拒绝通过该次请求,过了睡眠周期则会尝试放行。
isOpen()方法会按照(failure) / (success+failure)公式计算出失败率,如果失败率大于阈值,则会触发熔断。公式中的成功、失败的数据就来源于每10秒中一个窗口的滚筒数据。
对于一个依赖调用,要么调用成功,要么调用失败(包括异常、超时、拒绝),这些调用结果都会记录到buckets中。对于调用成功结果来说,还会判断断路器开关是否打开,如果是打开状态的话,则会关闭断路器并重置相关的计数器。
降级回退
降级,通常指事务高峰期,为了保证核心服务正常运行,需要停掉一些不太重要的业务,或者某些服务不可用时,执行备用逻辑从故障服务中快速失败或快速返回,以保障主体业务不受影响。 Hystrix提供的降级主要是为了容错,保证当前服务不受依赖服务故障的影响,从而提高服务的健壮性。
- 哪些情况会进入降级逻辑
- 断路器打开
- 线程池/信号量资源不足
- 执行依赖调用超时
- 执行依赖调用异常
- 降级回退方式
- Fail Fast快速失败
快速失败是最普通的命令执行方法,命令没有重写降级逻辑。 如果命令执行发生任何类型的故障,它将直接抛出异常 - Fail Fast无声失败
指在降级方法中通过返回null,空Map,空List或其他类似的响应来完成。 - FallBack:Static
指在降级方法中返回静态默认值。 这不会导致服务以“无声失败”的方式被删除,而是导致默认行为发生。如:应用根据命令执行返回true / false执行相应逻辑,但命令执行失败,则默认为true。 - FallBack:Stubbed
当命令返回一个包含多个字段的复合对象时,适合以Stubbed 的方式回退。 - FallBack:Cache via Network
有时,如果调用依赖服务失败,可以从缓存服务(如redis)中查询旧数据版本。由于又会发起远程调用,所以建议重新封装一个Command,使用不同的ThreadPoolKey,与主线程池进行隔离。 - Primary+Secondary with FallBack
有时系统具有两种行为- 主要和次要,或主要和故障转移。主要和次要逻辑涉及到不同的网络调用和业务逻辑,所以需要将主次逻辑封装在不同的Command中,使用线程池进行隔离。为了实现主从逻辑切换,可以将主次command封装在外观HystrixCommand的run方法中,并结合配置中心设置的开关切换主从逻辑。由于主次逻辑都是经过线程池隔离的HystrixCommand,因此外观HystrixCommand可以使用信号量隔离,而没有必要使用线程池隔离引入不必要的开销。
请求结果缓存
实际应用场景很少,不予过多介绍,有机会补齐。
请求合并
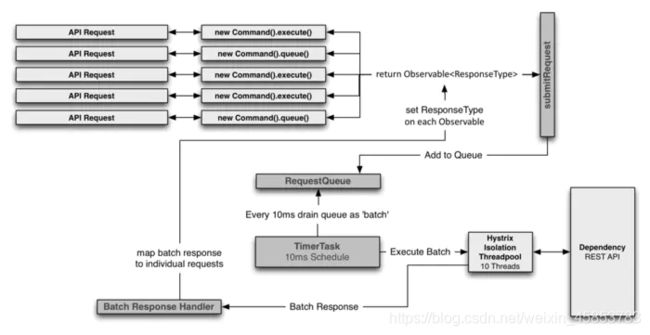
实际应用场景很少,不予过多介绍。
Hystrix工作流程
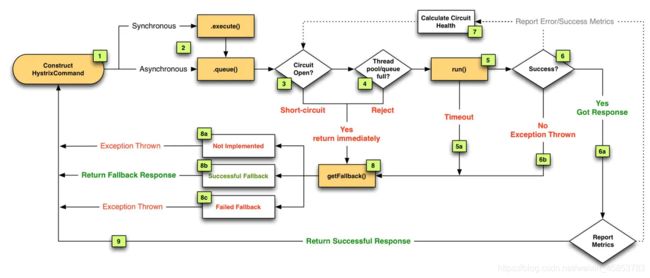
对于一次依赖调用,会被封装在一个HystrixCommand对象中,调用的执行有两种方式,一种是调用execute()方法同步调用,另一种是调用queue()方法进行异步调用。
执行时会判断断路器开关是否打开,如果断路器打开,则进入getFallback()降级逻辑;如果断路器关闭,则判断线程池/信号量资源是否已满,如果资源满了,则进入getFallback()降级逻辑;如果没满,则执行run()方法。再判断执行run()方法是否超时,超时则进入getFallback()降级逻辑,run()方法执行失败,则进入getFallback()降级逻辑,执行成功则报告Metrics。Metrics中的数据包括执行成功、超时、失败等情况的数据,Hystrix会计算一个断路器的健康值,也就是失败率,当失败率超过阈值后则会触发断路器开关打开。
getFallback()逻辑为:如果没有实现fallback()方法,则直接抛出异常,另外fallback降级也是需要资源的,在fallback时需要获取一个针对fallback的信号量,只有获取成功才能fallback,获取信号量失败,则抛出异常,获取信号量成功,才会执行fallback方法并且会响应fallback方法中的内容。
参考
杨波老师的《微服务架构实战160讲》
https://github.com/Netflix/Hystrix/wiki
https://www.jianshu.com/p/87be11fac98