我是怎么设计一个消息推送接口的?
今天要做的就是实现austin-api和austin-api-impl模块的部分代码,这块完成了之后模块之间的一整条链路就打通咯
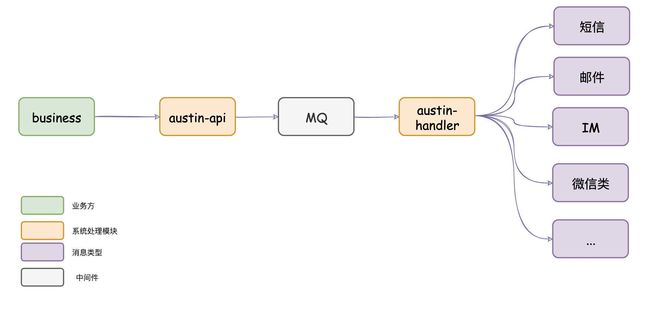
austin项目核心功能:发送消息

项目出现意义:只要公司内有发送消息的需求,都应该要有类似austin的项目,对各类消息进行统一发送处理。这有利于对功能的收拢,以及提高业务需求开发的效率

不多BB,开始今天的正题
01、接口设计
在austini-api模块下定义发送消息的接口,在austin-api-impl下实现具体的逻辑。我的接口实现定义:
public interface SendService {
/**
* 单模板单文案发送接口
* @param sendRequest
* @return
*/
SendResponse send(SendRequest sendRequest);
/**
* 单模板多文案发送接口
* @param batchSendRequest
* @return
*/
SendResponse batchSend(BatchSendRequest batchSendRequest);
}
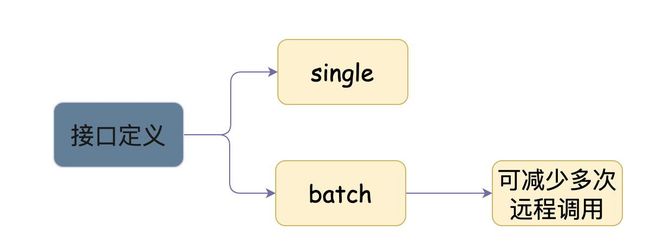
对外提供的接口,除了需要提供Single接口,最好还提供个Batch接口。因为很有可能业务方是需要一次批量执行的(如果只有Single接口,那就需要多次远程调用,这样对业务而言就不太合适了)
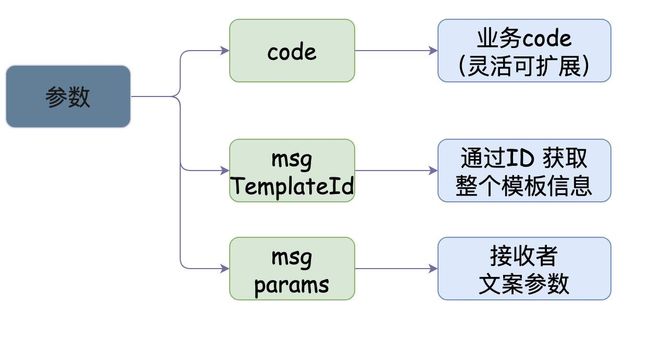
 我所定义的接口参数如下:
我所定义的接口参数如下:
public class SendRequest {
/**
* 执行业务类型
*/
private String code;
/**
* 消息模板Id
*/
private Long messageTemplateId;
/**
* 消息相关的参数
*/
private MessageParam messageParam;
}
通过messageTemplateId可以去数据库查出整个模板的信息,而MessageParam则是业务自行传入的参数(重要的是接收者以及文案的参数信息),而code则代表着当前请求要执行什么业务类型的(可基于该code扩展,后面会继续聊到)
02、代码实现
从流程可以看到,austin-api接收到请求之后,是把消息发到MQ的
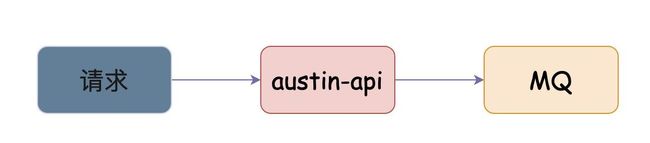
这样做有什么好处呢?假设某消息的服务超时,austin-api如果是直接调用下发接口服务,那可能会存在超时风险,拖垮整个接口性能。MQ在这是为了做异步和解耦,并且在一定程度上抗住业务流量。
对于绝大多数发送的消息而言,业务方也不太关心是不是能在接口调用时就知道发送结果,并且某些渠道在发送的时候也不知道发送的结果(最后的结果是异步告知的,比如短信和PUSH推送)
基于以上的原因,引入MQ来承载接口的流量以及做异步,是非常合理的事。

前两天我在博客平台上发了一篇文章《面试官:系统需求多变时如何设计? 》,有网友评论了一把:
面试官:我懂了,回去等通知吧。 …… leader:小王,咱们那个可变系统的重构计划写的怎么样了? 小王:没问题了,首先按找咱们的业务区分出责任链,然后在每个具体的步骤中部署脚本,上层再增加一个服务编排的接口统一管理…… leader:听起来有点意思,今天的候选人怎么样? 小王:别提了,嘴上说5年经验有大型系统设计,连redis都没用过。这不是快招聘季了吗,招两个实习生工具人进来给我打打下手就够了。 leader:好,把时间节点和里程碑划分一下,confluence上立项开干吧。 小王:好嘞。
在这次实现中,我也是用了责任链模式,具体完整的代码大家就去Gitee拉就好了。很多同学拉完代码发现看不懂了,大家可以按照下面的图去梳理下责任链的各个角色。如果实在看不懂,建议翻下我以前写过的责任链文章(已经投稿过两篇了)

回到代码实现吧,这次我实现的业务是:参数前置检查->参数拼装->发送消息

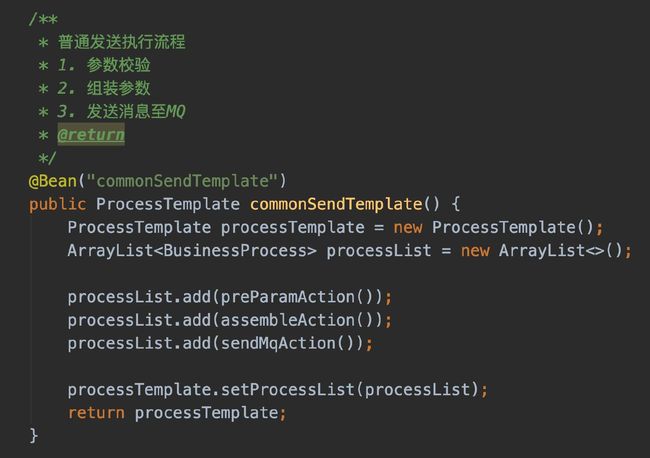
呀,都画了这么多图了,先点个赞,关注一波先咯。
在这几个流程中,可能你下次拉代码的时候,会看到有“后置检查”,或者别的什么的。但不管怎么样,加这种逻辑我再也不用在同一个类上写各种if else啦。只要在某个节点处添加一个Action就完事了。
(注:这是第一版实现,后面肯定会在基础上添加逻辑或注释的,其实已经在写了,但我一般是有个小阶段再push代码,所以记得star下gitee方便看最新的代码)
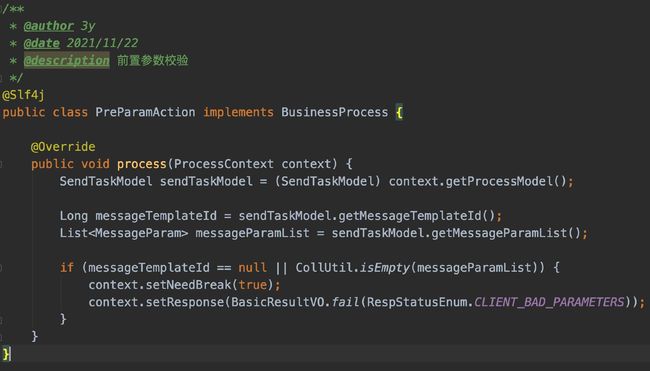
先来说前置检查吧,主要就判断模板ID是否有传入,消息参数是否有传入(对参数的常规检查,如果有问题,直接break掉链路,返回告诉调用方有问题)
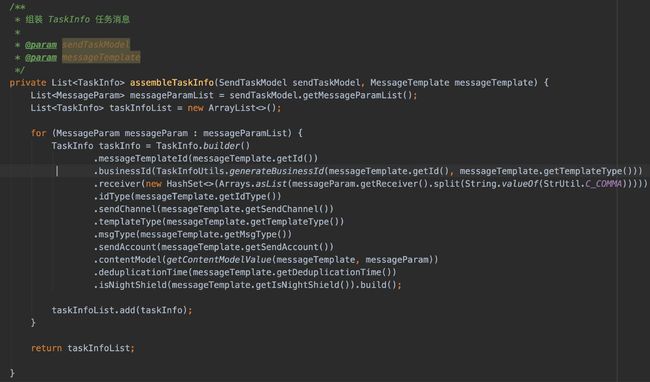
接着来看参数拼装,这块主要就是通过模板ID去查整个模板的内容,然后根据业务入参拼装出自己的TaskInfo(任务消息)。

可能有同学会有疑问❓:为什么不能直接用模板的POJO呢?反而需要拼装成TaskInfo?
其实还是比较好理解的,模板是作为给用户去配置该消息的信息,这是最最原始的信息。但是我们发送的时候是需要做处理的。比如,我要在用户写好的URL链接上拼接参数,我要对占位符进行替换真实的值,我要在模板的基础上增加业务ID进而追踪数据 等等等。
说白了,TaskInfo是基于模板的,在模板的基础上添加了某些平台性的字段(businessId),解析出用户设置的模板而想要发送的真实内容等等。
在这里,值得要说明的是msgContent该字段的说明。在模板中,该字段我在数据库注释所下的定义是(这个字段存入数据库一定是JSON格式的):
`msg_content` varchar(600) COLLATE utf8mb4_unicode_ci NOT NULL DEFAULT '' COMMENT '消息内容 占位符用{$var}表示',
不同的渠道的JSON结构还不一样:
- 短信:{“content”:“”,“url”:“”}
- 邮件:{“content”:“”,“subTitle”:“”}
- Push:{“content”:“”,“subTitle”:“”,“phoneImgUrl”:“”}
- 小程序:{“content”:“”,“pagePath”:“” …}
第一反应,我是想把所有渠道可能用到的字段都定义在TaskInfo下。后来感觉这样不太好看,于是我就定义了各种Model(不同的发送渠道拥有着自己的内容模型)

于是,我在组装TaskInfo的时候利用反射来进行映射,替换占位符则借助的是PropertyPlaceholderHelper
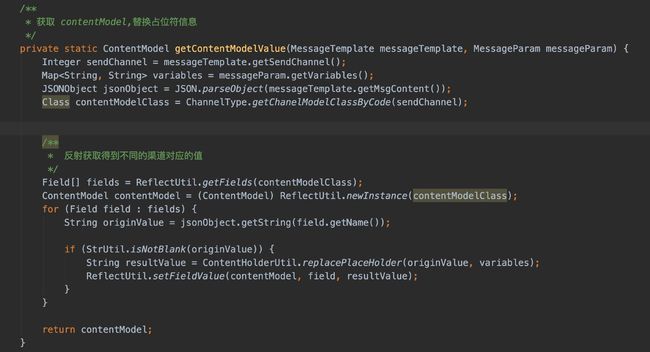
而发送则很简单了,我是直接把TaskInfo序列化为JSON,然后读取的时候再反序列化就好了。
值得注意的是,因为TaskInfo用的是ContentModel来存储着内容模型,所以我们在序列化JSON的时候需要把"类信息"写进去,不然在反序列的时候是拿不到子类的数据的。

03、总结
对于有源码的项目,其实我是不太愿意每一步讲解我写的代码的。因为我认为我本身写得也没那么复杂,也没有炫技的成分在内。
但自从push了代码以后,在群里提醒各位跟着做项目的小伙伴后,有好几位向我反馈看不太懂,所以这篇我就单独拎出来讲讲。
再回过头看,其实在austin-api层接收到请求之后,在发送消息至MQ之前,在这里的操作都是非常简单。其实是可以把通用业务做在这(比如说通用去重的功能),但经我考虑之后,还是不太合适。
austin-api算是一个接入层,到目前为止它只是通过id去数据库读取配置,就没有耗时的操作(这意味着他能承载的并发是极大的)。假设通过ID去数据库读取将来存在瓶颈,我们还可以考虑将配置从Redis甚至本地内存里取。
这是由业务可以决定的:一个模板的变更往往并不多,即便缓存存在强一致性的问题,但就那点点时间是完全可接受的。
Question :为什么发个消息需要MQ?
Answer:发送消息实际上是调用各个服务提供的API,假设某消息的服务超时,austin-api如果是直接调用服务,那存在超时风险,拖垮整个接口性能。MQ在这是为了做异步和解耦,并且在一定程度上抗住业务流量。
Question:能简单说下接入层做了什么事吗?
Answer:

开源项目地址:
Gitee链接:https://gitee.com/austin
GitHub链接:https://github.com/austin