上周,XX保险面试,凉了!!!
上周,一位群里的朋友去平安保险面试了,结果有些遗憾,蛮可惜的,但希望你不要气馁,正如你所说的,面试中遇到的问题,基本上都是可以通过背面试题解决的,所以请加油!
另外,有问题欢迎随时找我探讨,共同进步。
不扯远了,咱们进入主题,下面是这位同学整理的技术面试题和参考答案。
Java中有哪些线程安全的类?
Vector、Hashtable、StringBuffer。都是在其方法上加了同步锁来实现线程安全的。
另外,还有JUC包下所有的集合类
ArrayBlockingQueue 、ConcurrentHashMap、ConcurrentLinkedQueue、ConcurrentLinkedDeque等,这些也是线程安全的。
幸好这么回答就算结束了,面试官也没再问了,不然JUC下的这几个我真回答不上来。
Java创建对象有几种方式?
这个问题相对还是简单的,能说上个123应该都没问题了。
Java中提供了以下四种创建对象的方式:
-
new创建新对象
-
通过反射机制
-
采用clone机制
-
通过序列化机制
Object 有哪些常用方法?
这个问题,回答的不是很好,当时只记得toString、equals、hashCode、wait、notify、notifyAll。其他的没有想起来。面试官还是不断点头,给人感觉是应该还行。
java.lang.Object

下面是对应方法的含义。
clone 方法
保护方法,实现对象的浅复制,只有实现了 Cloneable 接口才可以调用该方法,否则抛出 CloneNotSupportedException 异常,深拷贝也需要实现 Cloneable,同时其成员变量为引用类型的也需要实现 Cloneable,然后重写 clone 方法。
finalize 方法
该方法和垃圾收集器有关系,判断一个对象是否可以被回收的最后一步就是判断是否重写了此方法。
equals 方法
该方法使用频率非常高。一般 equals 和 == 是不一样的,但是在 Object 中两者是一样的。子类一般都要重写这个方法。
hashCode 方法
该方法用于哈希查找,重写了 equals 方法一般都要重写 hashCode 方法,这个方法在一些具有哈希功能的 Collection 中用到。
一般必须满足 obj1.equals(obj2)==true。可以推出 obj1.hashCode()==obj2.hashCode(),但是 hashCode 相等不一定就满足 equals。不过为了提高效率,应该尽量使上面两个条件接近等价。
-
JDK 1.6、1.7 默认是返回随机数;
-
JDK 1.8 默认是通过和当前线程有关的一个随机数 + 三个确定值,运用 Marsaglia’s xorshift scheme 随机数算法得到的一个随机数。
wait 方法
配合 synchronized 使用,wait 方法就是使当前线程等待该对象的锁,当前线程必须是该对象的拥有者,也就是具有该对象的锁。wait() 方法一直等待,直到获得锁或者被中断。wait(long timeout) 设定一个超时间隔,如果在规定时间内没有获得锁就返回。
调用该方法后当前线程进入睡眠状态,直到以下事件发生。
-
其他线程调用了该对象的 notify 方法;
-
其他线程调用了该对象的 notifyAll 方法;
-
其他线程调用了 interrupt 中断该线程;
-
时间间隔到了。
此时该线程就可以被调度了,如果是被中断的话就抛出一个 InterruptedException 异常。
notify 方法
配合 synchronized 使用,该方法唤醒在该对象上等待队列中的某个线程(同步队列中的线程是给抢占 CPU 的线程,等待队列中的线程指的是等待唤醒的线程)。
notifyAll 方法
配合 synchronized 使用,该方法唤醒在该对象上等待队列中的所有线程。
hashCode方法和equals方法有什么关系
有点连环炮的意思了,问到这里,感觉面试官有些怀疑我的基础了,但这个问题还是能回答的。
如果a.equals(b)返回“true”,那么a和b的hashCode()必须相等。
如果a.equals(b)返回“false”,那么a和b的hashCode()有可能相等,也有可能不等。
hashcode的作用
真的是连环炮,一个接一个问,回答的不是很理想,但也是扯到一些。
Java的集合有两类,一类是List,还有一类是Set。前者有序可重复,后者无序不重复。当我们在set中插入的时候怎么判断是否已经存在该元素呢,可以通过equals方法。但是如果元素太多,用这样的方法就会比较满。
于是有人发明了哈希算法来提高集合中查找元素的效率。这种方式将集合分成若干个存储区域,每个对象可以计算出一个哈希码,可以将哈希码分组,每组分别对应某个存储区域,根据一个对象的哈希码就可以确定该对象应该存储的那个区域。
hashCode方法可以这样理解:它返回的就是根据对象的内存地址换算出的一个值。这样一来,当集合要添加新的元素时,先调用这个元素的hashCode方法,就一下子能定位到它应该放置的物理位置上。如果这个位置上没有元素,它就可以直接存储在这个位置上,不用再进行任何比较了;如果这个位置上已经有元素了,就调用它的equals方法与新元素进行比较,相同的话就不存了,不相同就散列其它的地址。这样一来实际调用equals方法的次数就大大降低了,几乎只需要一两次。
说说Spring Boot的自动装配原理
这个问题,也是因为我简历上写了
Spring Boot,所以被问到也是正常的,不过我面试前还是看过一些,回答的还行,面试官说差不多是这个意思。
在Spring Boot中有个很关键的注解@SpringBootApplication ,其中这个注解又可以等同于
- @SpringBootConfiguration
- @EnableAutoConfiguration
- @ComponentScan
其中@EnableAutoConfiguration是关键(启用自动配置),内部实际上就去加载META-INF/spring.factories文件的信息,然后筛选出以EnableAutoConfiguration为key的数据,加载到IOC容器中,实现自动配置功能!
数据库事务的隔离级别有哪些?
这种问题,背背八股文,网上一堆堆。
数据库事务的隔离级别有4种,由低到高分别为Read uncommitted 、Read committed、Repeatable read、Serializable。
-
未提交读(
READ UNCOMMITTED):这个隔离级别下,其他事务可以看到本事务没有提交的部分修改,因此会造成脏读的问题(读取到了其他事务未提交的部分,而之后该事务进行了回滚); -
已提交读(
READ COMMITTED):其他事务只能读取到本事务已经提交的部分,这个隔离级别有不可重复读的问题,在同一个事务内的两次读取,拿到的结果竟然不一样,因为另外一个事务对数据进行了修改;" -
可重复读(
REPEATABLE READ)。可重复读隔离级别解决了上面不可重复读的问题,但是仍然有一个新问题,就是幻读。当你读取id> 10 的数据行时,对涉及到的所有行加上了读锁,此时例外一个事务新插入了一条id=11的数据,因为是新插入的,所以不会触发上面的锁的排斥,那么进行本事务进行下一次的查询时会发现有一条id=11的数据,而上次的查询操作并没有获取到,再进行插入就会有主键冲突的问题; -
可串行化(
SERIALIZABLE)。这是最高的隔离级别,可以解决上面提到的所有问题,因为他强制将所以的操作串行执行,这会导致并发性能极速下降,因此也不是很常用。
说说你对MySQL中索引的理解
这个问题,还好,知道多少说多少。看每个人准备情况,我当时准备的还行。自我感觉回答的还行,我把索引的优缺点一并回答上来了。
索引是一种数据结构,使得Mysql能够高效获取数据的数据结构。更通俗的说,数据库索引好比是一本书前面的目录,能加快数据库的查询速度。
优点
-
可以保证数据库表中每一行的数据的唯一性
-
可以大大加快数据的索引速度
-
加速表与表之间的连接,特别是在实现数据的参考完整性方面特别有意义
-
在使用分组和排序子句进行数据检索时,同样可以显著减少查询中分组和排序的时间
-
通过使用索引,可以在时间查询的过程中,使用优化隐藏器,提高系统的性能
缺点
-
创建索引和维护索引要耗费时间,这种时间随着数据量的增加而增加
-
索引需要占物理空间,除了数据表占用数据空间之外,每一个索引还要占用一定的物理空间,如果需要建立聚簇索引,那么需要占用的空间会更大
-
以表中的数据进行增、删、改的时候,索引也要动态的维护,这就降低了整数的维护速度
熟悉哪些SQL优化方法?
1、查询语句中不要使用select *
2、尽量减少子查询,使用关联查询(left join,right join,inner join)替代
3、减少使用IN或者NOT IN ,使用exists,not exists或者关联查询语句替代
4、or 的查询尽量用 union或者union all 代替(在确认没有重复数据或者不用剔除重复数据时,union all会更好)
5、应尽量避免在 where 子句中使用!=或<>操作符,否则将引擎放弃使用索引而进行全表扫描。
6、应尽量避免在 where 子句中对字段进行 null 值判断,否则将导致引擎放弃使用索引而进行全表扫描,如:select id from t where num is null 可以在num上设置默认值0,确保表中num列没有null值,然后这样查询:select id from t where num=0
在 MySQL 中一条查询 SQL 是如何执行的?
比如下面这条SQL语句(面试官现场给的SQL):
select 字段1,字段2 from 表 where id=996
-
取得链接,使用使用到 MySQL 中的连接器。
-
查询缓存,key 为 SQL 语句,value 为查询结果,如果查到就直接返回。不建议使用次缓存,在 MySQL 8.0 版本已经将查询缓存删除,也就是说 MySQL 8.0 版本后不存在此功能。
-
分析器,分为词法分析和语法分析。此阶段只是做一些 SQL 解析,语法校验。所以一般语法错误在此阶段。
-
优化器,是在表里有多个索引的时候,决定使用哪个索引;或者一个语句中存在多表关联的时候(join),决定各个表的连接顺序。
-
执行器,通过分析器让 SQL 知道你要干啥,通过优化器知道该怎么做,于是开始执行语句。执行语句的时候还要判断是否具备此权限,没有权限就直接返回提示没有权限的错误;有权限则打开表,根据表的引擎定义,去使用这个引擎提供的接口,获取这个表的第一行,判断 id 是都等于 1。如果是,直接返回;如果不是继续调用引擎接口去下一行,重复相同的判断,直到取到这个表的最后一行,最后返回。
我在想,996是什么含义,是你们公司就是996吗?还是随口一说
JVM中堆与栈有什么区别?
二者本质区别:栈是线程私有,而堆是线程共享的。
栈是运行时单位,代表着逻辑,一个栈对应着一个线程,内含基本数据类型和堆中对象引用,所在区域连续,没有碎片;
堆是存储单位,代表着数据,可被多个栈共享(包括成员中基本数据类型、引用和引用对象),所在区域不连续,会有碎片。
1)、功能不同
栈内存用来存储局部变量和方法调用,而堆内存用来存储Java中的对象。无论是成员变量,局部变量,还是类变量,它们指向的对象都存储在堆内存中。
2)、共享性不同
栈内存是线程私有的。堆内存是所有线程共有的。
3)、异常错误不同
如果栈内存或者堆内存不足都会抛出异常。
栈空间不足:java.lang.StackOverFlowError。
堆空间不足:java.lang.OutOfMemoryError。
4)、空间大小
栈的空间大小远远小于堆的。
熟悉类加载机制吗?
这都是背背面试题就差不多了
JVM类加载分为5个过程:加载,验证,准备,解析,初始化,使用,卸载,如下图所示:
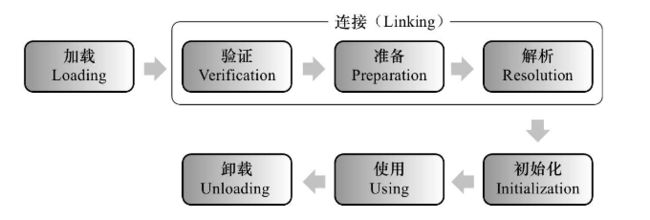
下面来看看加载,验证,准备,解析,初始化这5个过程的具体动作。
加载
加载主要是将.class文件(并不一定是.class。可以是ZIP包,网络中获取)中的二进制字节流读入到JVM中。在加载阶段,JVM需要完成3件事:1)通过类的全限定名获取该类的二进制字节流;2)将字节流所代表的静态存储结构转化为方法区的运行时数据结构;3)在内存中生成一个该类的java.lang.Class对象,作为方法区这个类的各种数据的访问入口。
连接
验证
验证是连接阶段的第一步,主要确保加载进来的字节流符合JVM规范。验证阶段会完成以下4个阶段的检验动作:1)文件格式验证 2)元数据验证(是否符合Java语言规范) 3)字节码验证(确定程序语义合法,符合逻辑) 4)符号引用验证(确保下一步的解析能正常执行)
准备
主要为静态变量在方法区分配内存,并设置默认初始值。
解析
是虚拟机将常量池内的符号引用替换为直接引用的过程。
初始化
初始化阶段是类加载过程的最后一步,主要是根据程序中的赋值语句主动为类变量赋值。注:1)当有父类且父类为初始化的时候,先去初始化父类;2)再进行子类初始化语句。
能够触发条件 Full GC 有哪些?
有点跳跃性,还以为会问垃圾回收算法之类,结果居然问到这里了。这个没准备好,随便说了两个,明显感觉到面试官很不满意,哎,就这样吧,回去好好准备吧。
通常触发Full GC的场景有如下5种场景:
(1)调用System.gc时,系统建议执行Full GC,但是不必然执行
(2)老年代空间不足
(3)方法去空间不足
(4)通过Minor GC后进入老年代的平均大小 > 老年代的可用内存
(5)由Eden区、From Space区向To Space区复制时,对象大小大于To Space可用内存,则把该对象转存到老年代,且老年代的可用内存小于该对象大小。即老年代无法存放下新年代过度到老年代的对象的时候,会触发Full GC。
线上系统CPU飙高,怎么办?
这个问题,回答的也不是很满意,我知道田哥整理过一份文档,但是我还没有看到那里去,回家的路上看了后发现,这也是可以背的面试题,居然我没回答上来,回去加油吧。面试官来了一句:OK,今天咱们面试就到这里,我这边去和HR汇报一下,你在这里等一下。
过一会漂亮的HR走过来,面带微笑,(我以为问题不大了),结果.....。
您是"YY吧,面试官反馈了面试情况,我们这边要再总和考量一下,您先回去,后续有结果,我们会电话通知您"。
(⊙o⊙)…,后面过了n多天,没消息,果然凉凉了。
常规操作是:
1. top oder by with P:1040 // 首先按进程负载排序找到 axLoad(pid)
2. top -Hp 进程PID:1073 // 找到相关负载 线程PID
3. printf “0x%x\n”线程PID:0x431 // 将线程PID转换为 16进制,为后面查找 jstack 日志做准备
4. jstack 进程PID | vim +/十六进制线程PID - // 例如:jstack 1040|vim +/0x431 -
总结
整个面试过程还是相对轻松的,面试官也还挺好的,只是怪自己没有准备好,作为一个工作两年的我,有些问题确实是没见过,但面试官问得问题貌似都可以实现准备好的(背面试题),也不是一定要亲身经历过。
也许这就是:面试造火箭,.....
以上便是这位同学的本次面试总结
如果本文对你有帮助,别忘记给我个3连 ,点赞,转发,评论,
咱们下期见!答案获取方式:已赞 已评 已关~
学习更多知识与技巧,关注与私信博主(03)