python爬虫(三)requests模块和urllib的post请求
urllib发送post请求
案例:制作简易翻译软件
- 学习目标:使用urllib发送post
- 用户需求:通过python制作简易版的小翻译软件
Response(响应)我们向URL发送的请求,得到的响应的原始数据是在Response里,但是里面的数据过长,不方便查看,可以到Preview(预览)里去查看,Preview里数据格式比较清晰,跟Response里的数据一样。
页面分析
利用有道翻译,输入“奥运会”,进行翻译。处理的过程中首先要先确定数据在哪,是静态加载还是动态加载出来的,点右键–>查看网页源码,没有找到“奥运会”的字样,可以判断是动态加载的。点右键–>检查–>Network–>XHR中去筛选,这里面的数据少方便去找(若找不到,回到All里去找)。
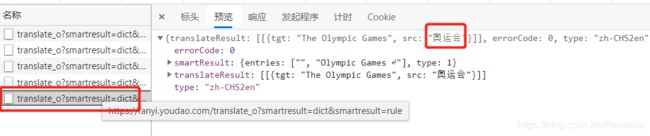
在XHR中,点击在左侧的名称下点击translate文件,在Preview中找到如图所示的带“奥运会”字样的信息,被翻译成了“The Olympic Games”。这样的话我们就可以确定向Headers–>General–>Request URL里的:https://fanyi.youdao.com/translate_o?smartresult=dict&smartresult=rule发送POST请求就可以了,可以得到翻译出来的数据。我们可以从Headers里的Form Data里有奥运会等一系列的参数,我们在发送请求的时候需要携带上所有的参数的。
- 目标url:https://fanyi.youdao.com/translate_o?smartresult=dict&smartresult=rule
- 请求方式:post
- 要携带这些数据:
要携带这些数据:
i: 奥运会
from: AUTO
to: AUTO
smartresult: dict
client: fanyideskweb
salt: 16282514891344
sign: af688b091ae35b8aa6fca61de6417e58
lts: 1628251489134
bv: 5b3e307b66a6c075d525ed231dcc8dcd
doctype: json
version: 2.1
keyfrom: fanyi.web
action: FY_BY_REALTlME
向目标url发送请求 得到一个响应数据(在Response里复制):
{“translateResult”:[[{“tgt”:“The Olympic Games”,“src”:“奥运会”}]],“errorCode”:0,“type”:“zh-CHS2en”,“smartResult”:{“entries”:["",“Olympic Games\r\n”],“type”:1}}
拿到数据之后 就要做数据解析:
eg.奥运会–>The Olympic Games
这样的话,简易版的小翻译软件就制作成功了。
实现步骤
在代码实现的时候需要把携带的数据转为字典格式的,在pycham中新建文件,打开CTRL+r,复制上面的“要携带的数据”,勾选Regex正则匹配或者右边的齿轮,在框里分别输入如下内容, (.*?): (.*), ‘$1’: ‘$2’,如图所示:

json.loads()可以将json类型的字符串转换为python类型的字典
要注意:要复制代码里面的": ",以免出错,然后点击Replace all 就转换完成了
'i': '奥运会',
'from': 'AUTO',
'to': 'AUTO',
'smartresult': 'dict',
'client': 'fanyideskweb',
'salt': '16282514891344',
'sign': 'af688b091ae35b8aa6fca61de6417e58',
'lts': '1628251489134',
'bv': '5b3e307b66a6c075d525ed231dcc8dcd',
'doctype': 'json',
'version': '2.1',
'keyfrom': 'fanyi.web',
'action': 'FY_BY_REALTlME',
下面开始进行代码的实现
from urllib import request
from urllib import parse #-->从urllib中导入 request,parse
key = input("请输入要翻译的内容:") #-->用户输入翻译的内容
url = 'https://fanyi.youdao.com/translate?smartresult=dict&smartresult=rule' #-->翻译的网址,去掉了原网址中的“-o”
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/92.0.4515.107 Safari/537.36 Edg/92.0.902.62'
} #--> 请求头
data = {
'i': key,
'from': 'AUTO',
'to': 'AUTO',
'smartresult': 'dict',
'client': 'fanyideskweb',
'salt': '16282514891344',
'sign': 'af688b091ae35b8aa6fca61de6417e58',
'lts': '1628251489134',
'bv': '5b3e307b66a6c075d525ed231dcc8dcd',
'doctype': 'json',
'version': '2.1',
'keyfrom': 'fanyi.web',
'action': 'FY_BY_REALTlME'
} #--> 翻译需要携带的数据
data = parse.urlencode(data) #--> 把输入的内容(主要是中文)转%+十六进制,从urllib中导入,就不需要用urllib.开头了
data = bytes(data, encoding="utf-8") #--> 把十六进制转为字节的形式
req = request.Request(url, data=data, headers=headers) #-->创建请求对象
res = request.urlopen(req) #--> 发送请求,获取响应
html = res.read().decode("utf-8") #--> 获取响应对象的内容
print(html) #--> 打印获取的内容,跟在Response里复制的内容一样
print(type(html)) #--> **输出第一次结果**查看打印数据的类型,是json类型的字符串,
# json.loads()可以将json类型的字符串转换为python类型的字典
trans_dict = json.loads(html)
# print(type(trans_dict), trans_dict) #-->打印出的数据类型是字典,就可以通过关键字取出带翻译的内容
# 得到的内容{'type': 'ZH_CN2EN', 'errorCode': 0, 'elapsedTime': 15, 'translateResult': [[{'src': '奥运会', 'tgt': 'The Olympic Games'}]]}
# 要得到 [[{'src': '奥运会', 'tgt': 'The Olympic Games'}]]},通过字典的关键字提取
TransalteR = trans_dict['translateResult']
# print(TransalteR) #-->[[{'src': '奥运会', 'tgt': 'The Olympic Games'}]]
# print(TransalteR[0]) #-->列表中只有一个元素,下标为0,[{'src': '奥运会', 'tgt': 'The Olympic Games'}]
# print(TransalteR[0][0]) #-->同样的方法,再拨开一层{'src': '奥运会', 'tgt': 'The Olympic Games'}
# print(TransalteR[0][0]['tgt']) #--> 利用下标取出翻译的值 The Olympic Games
print(f"{key}翻译的结果是:{TransalteR[0][0]['tgt']}") #--> 格式化字符串输出
依次输出的结果;
{"type":"ZH_CN2EN","errorCode":0,"elapsedTime":1,"translateResult":[[{"src":"奥运会","tgt":"The Olympic Games"}]]}
<class 'str'>
json转换之后变为python类型的字典
<class 'dict'> {'type': 'ZH_CN2EN', 'errorCode': 0, 'elapsedTime': 1, 'translateResult': [[{'src': '奥运会', 'tgt': 'The Olympic Games'}]]}
利用关键字’translateResult’,取出字典中’translateResult’对应的内容
[[{'src': '奥运会', 'tgt': 'The Olympic Games'}]]
用剥洋葱的形式对取到的列表逐层剥开,列表中只有一个元素,所以下标为0,通过两次从列表中取值,得到一个字典,再从字典中以关键字’tgt’取值,得到想要的翻译结果:The Olympic Games
[{'src': '奥运会', 'tgt': 'The Olympic Games'}]
{'src': '奥运会', 'tgt': 'The Olympic Games'}
The Olympic Games
最后格式化字符串,打印最后的输出结果。可以尝试输入其他的内容进行翻译,输入中英文均可,简易版的翻译小软件的程序就完成了。
请输入要翻译的内容:奥运会
奥运会翻译的结果是:The Olympic Games
总结
1、如果用urllib发送post请求要携带数据 有中文要提前处理 携带的数据类型必须是bytes 还要注意编码
2、目标url 去掉_o(现在记住就好 以后学的)
3、json来解析数据 json类型的字符串str 转换成字典,然后一层一层的剥开
import json
json.loads() 可以将json类型的字符串 转换为python类型的字典
trans_dict = json.loads(html)
requests
是第三方的http请求模块 需要安装的,pip install requests,如果安装速度太慢或者安装失败(有时候打开国外的网站很慢,比如打开微软、HP等网站超级慢),就可以换源安装
pip install requests -i https://pypi.tuna.tsinghua.edu.cn/simple/(换成清华源)
pip install requests -i http://pypi.douban.com/simple/(换成豆瓣源)
两者选其一即可
除了在cmd里安装,在pycham里也可以进行第三方模块的安装

在pycham下面,选择Terminal,在光标后 进行安装即可,安装完成后,可以新建一个python file ,在里面输入 import requests ,然后敲回车键,如果没有报错,则安装成功,安装其他模块类似,只需要改一下模块名字即可。
request常用方法
requests.get(网址)
响应对象response的方法
response.text 返回unicode格式的数据(str)
response.content 返回字节流数据(二进制)
response.content.decode(‘utf-8’) 手动进行解码
response.url 返回url
response.encode() = ‘编码’
urllib vs requests
按着CTRL+鼠标左键 点击 requests,进入requests的源码,可以看到requests的请求语法很简单,get与post的区别在于需不需要传递参数,也不需要对post携带的data参数进行额外的处理
Basic GET usage:
>>> import requests
>>> r = requests.get('https://www.python.org')
POST:
>>> payload = dict(key1='value1', key2='value2')
>>> r = requests.post('https://httpbin.org/post', data=payload)
用requests发送get请求爬取奥运会百度贴吧
import requests
# 奥运会 贴吧的第二页,https://tieba.baidu.com/f是固定的,后面的内容跟爬取的主题和页面有关系,“=utf-8”可不用
# url = 'https://tieba.baidu.com/f?kw=%E5%A5%A5%E8%BF%90%E4%BC%9A&ie=utf-8&pn=50'
# 第一种方式,通过键值对传参,最原始的请求方式
url = 'https://tieba.baidu.com/f?' # 后面的内容用传参的形式,以键值对的形式放在字典格式里
params = {
"kw":"奥运会",
"pn":"50"
}
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/92.0.4515.107 Safari/537.36 Edg/92.0.902.62'
} #--> 请求头
# requests 发送请求的格式,url为基准的url,不包含任何参数的,也可以用url关键字传参
# 以键值对的形式添加url后面的参数,headers 把自己伪装成浏览器进行访问
# 跟urllib的区别,不需要把中文进行处理。用关键字传参,可以改变几个参数的位置
r = requests.get(url, params=params, headers=headers)
print(r) # --> 打印出来的是对象,对象里有很多方法,,代表访问成功
# 用方法提取出里面的内容
print(r.text)
# 第二种方式,直接访问
url = 'https://tieba.baidu.com/f?kw=%E5%A5%A5%E8%BF%90%E4%BC%9A&ie=utf-8&pn=50'
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/92.0.4515.107 Safari/537.36 Edg/92.0.902.62'
}
res = requests.get(url, headers=headers)
print(res.text)
爬取指定网站图片
# 爬取网站图片
url = 'https://qq.yh31.com/zjbq/2920180.html' #表情包图片网站
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/92.0.4515.107 Safari/537.36 Edg/92.0.902.62'
}
res = requests.get(url, headers=headers)
# print(type(res.text), res.text) # 返回的是字符串,但是有乱码 ,但是我们看不懂
print(type(res.content.decode('utf-8')), res.content.decode('utf-8')) # 通过转码变为字符串,乱码的问题解决了
res.content 直接从网站抓取数据,没有做任何的处理,没有解码,是二进制的形式,可以后面加.decode(‘utf-8’)进行解码,推荐用这一种。
res.text 是requests模块将res.content解码之后得到的字符串,会随机采用一种解码方式,有可能解码的我们能看懂,有可能看到的是乱码。如果要使用这种方式,可以 先指定 res.encoding = ‘utf-8’,再 print(type(res.text),res.text))
总结:
1、requests不需要处理中文
2、requests不需要拼接url地址
3、requests直接用get方式就可以传递headers
requests 发送post请求制作翻译软件
跟文章开头的方法相比,用requests就不需要对中文进行处理,url,headers,data 跟之前的都一样,获取响应对象的方法简单了,后面的逐层剥开也是一样的
import requests
import json
key = input("请输入要翻译的内容:") #-->用户输入翻译的内容
url = 'https://fanyi.youdao.com/translate?smartresult=dict&smartresult=rule' #-->翻译的网址,去掉了原网址中的“-o”
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/92.0.4515.107 Safari/537.36 Edg/92.0.902.62'
} #--> 请求头
data = {
'i': key,
'from': 'AUTO',
'to': 'AUTO',
'smartresult': 'dict',
'client': 'fanyideskweb',
'salt': '16282514891344',
'sign': 'af688b091ae35b8aa6fca61de6417e58',
'lts': '1628251489134',
'bv': '5b3e307b66a6c075d525ed231dcc8dcd',
'doctype': 'json',
'version': '2.1',
'keyfrom': 'fanyi.web',
'action': 'FY_BY_REALTlME'
} #--> 翻译需要携带的数据
res = requests.post(url, data=data, headers=headers)
html = res.content.decode('utf-8')
# 提取数据
trans_d = json.loads(html)
TransalteR = trans_d['translateResult']
print(f"{key}翻译的结果是:{TransalteR[0][0]['tgt']}")
运行结果
请输入要翻译的内容:奥运会
奥运会翻译的结果是:The Olympic Games
requests设置代理ip
相比较,requests应用的范围稍微广泛一点。
爬取百度贴吧,开发者的本意是想要用户去访问的,编写程序去访问,违背了开发者的初衷,给服务器造成了负担,如果不是必须的网站,访问一直很卡,后续就不会再访问这个网站了,给网站造成了不好的影响。
代理IP 服务器把你真实的IP转换成不同的IP地址,再对服务器访问,服务器发现异常,封的是代理的IP,真是的IP被伪装起来
代理IP的代码格式是固定的,网上能用的代理IP并不多
作用:
1、隐藏真实的ip,以免IP被封
2、反爬策略
代理ip的匿名度:
1、透明 服务器知道你使用了代理ip 也知道你的真实ip
2、匿名 知道你使用了代理ip 但不知道你的真实ip
3、高匿 不知道使用了代理ip 也不知道真实ip
如何查ip:
1、cmd–>ipconfig 内网ip 私有的地址 局域网内地址(学校,公司里)
2、https://www.ipip.net/ 外网 能够用于上网的ip http://httpbin.org/ip 也能查出来外网地址
利用代码实现的步骤
import requests
url = 'http://httpbin.org/ip'
res = requests.get(url)
print(res.text)
返回的是你电脑的真实ip地址
可以利用 ”快代理“ 网站上免费的代理ip进行代理
使用ip代理
import requests
url = 'http://httpbin.org/ip'
# 设置代理ip,传递的是字典格式,key值是http,value值是代理的ip:端口号
proxy = {
'http': '106.45.105.43:3256'
}
res = requests.get(url, proxies=proxy)
print(res.text)
多个代理IP的设置
多个代理IP的设置
import requests
import random
url = 'http://httpbin.org/ip'
ips = [('182.84.144.127:3256'), ('110.43.136.72:3128'), ('121.237.27.76:3000'),
('223.244.179.119:3256'), ('47.98.179.39:8080')] #把5个ip放到列表中
for i in range(5):
try:
proxy = random.choice(ips)
res = requests.get(url, proxies={'http':proxy}, timeout = 0.3)
print(res.text)
except Exception as e:
print("出现异常:", e)
另外,https://h.wandouip.com/ 这个网站里面每天可以免费提取20个 代理IP,登陆后可以先添加白名单(绑定终端IP,给使用的代理IP授权,防止代理IP被滥用,提高服务质量)把自己电脑的IP添加进去,选择工具–>提取API,数据选为TXT格式,生产API链接,打开API链接就可以获取免费的IP