Transformer 这么强,该从何学起?
Transformer 作为一种基于注意力的编码器 - 解码器架构,不仅彻底改变了自然语言处理(NLP)领域,还在计算机视觉(CV)领域做出了一些开创性的工作。与卷积神经网络(CNN)相比,视觉 Transformer(ViT)依靠出色的建模能力,在 ImageNet、COCO 和 ADE20k 等多个基准上取得了非常优异的性能。
正如德克萨斯大学奥斯汀分校的计算机科学家 Atlas Wang 说:我们有充分的理由尝试在整个 AI 任务范围内尝试使用 Transformer。
因此,无论是学术界的研究人员,还是工业界的相关从业者,都有必要对Transformer技术深入了解,并且紧跟Transformer的前沿研究,以此来夯实自己技术积累。
AI是一门入门简单,但想深入却很难的学科,这也是为什么AI高端人才一直非常紧缺的重要原因。
在工作中:
你是否能够按照实际的场景灵活提出新的模型?
或者提出对现有模型的改造?
实际上这些是核心竞争力,同时是走向高端人才必须要经历的门槛。虽然很有挑战,但一旦过了这个门槛你就会发现你是市场中的TOP5%.
所以我们设计了这样的一门课程,目的就是一个:让你有机会成为市场中的TOP5%。在课程中,我们将由浅入深的讲解Transformer在NLP和CV领域的模型原理、实现方法以及应用技巧等,全面细致的讲解联邦学习的理论知识体系及其在隐私计算与金融领域的应用。学习过程中,可以通过六大实战项目,拓展思路,融会贯通,从而真正提高自己解决问题能力。
课程亮点
全面的内容讲解:涵盖当今应用和科研领域最热门的Transformer与联邦学习,包括70+Transformer模型串讲,三大联邦学习类型+应用案例。
深入的技术剖析:深入剖析Transformer与联邦学习模型与框架技术细节及各模块所涵盖最前沿模型原理技术。
六大实战项目:每个模块均设置项目,包含对话系统、文本生成、图像识别、目标检测、隐私计算、金融风控,在应用中提升学生的理论和实践能力。
大牛级导师团队:每个模块均由各自领域内多年一线从业经验科学家或科研学者、工程师讲授,并配有背景优秀经验丰富的助教,致力于带来最优质的学习体验。
你将收获
▶全面掌握Transformer与联邦学习领域的知识,灵活应用在自己工作中
▶能够了解Transformer模型与联邦学习框架的实现方式,并熟练掌握其关键技术与方法
▶深入理解前沿的Transformer与联邦学习技术,拓宽工作和研究的技术视野
▶短期内对一个领域有全面且系统的认识,大大节省学习时间
▶认识一群拥有同样兴趣的人、相互交流、相互学习
助你成为行业TOP10%的工程师
对课程有意向的同学
扫描二维码咨询

下面对每个部分的内容详细做了介绍,感兴趣的朋友们可以来咨询更多。
NLP Tranformer
![]()
01
全面技术讲解
课程内容涵盖 ELMo/ GPT3 Codex /Alpha-Code/ UniLM v2/ BERT/ RoBERTa /XLM/ Span BERT 等60余个模型的讲解。
项目实践,学以致用
学员使用Transformer模型,练习NLP领域应用最广泛的对话系统和文本生成任务。
专业团队严格打磨的课程内容,前沿且深入
课程内容经过前期数百小时的打磨设计,保证内容和项目节点设置合理,真正做到学有所得。
就业导向,目标明确
顺利完课后,优秀学员可获得字节、阿里、腾讯、美团等各互联网大厂,及商汤、旷视等AI独角兽公司的合作内推面试机会。
内容大纲
Week1
主题:自回归语言模型中的Transformer
本节课将回顾自然语言处理领域的重要概念:语言模型。并介绍基于Transformer的自回归语言模型。
课程提纲:
ELMo
GPT/GPT2/GPT3
Codex/Alpha-Code
UniLM/UniLM v2
NLP模型中的Tokenizer(wordpiece,BPE)
Week2
主题:知识蒸馏优化、低秩分解优化
本节课将讲解神经网络知识蒸馏优化、神经网络计算低秩分解加速计算方法。
课程提纲:
知识蒸馏方法介绍
知识蒸馏原理和步骤介绍
知识蒸馏训练方法缩减网络的实际分类网络演示
低秩分解原理
低秩分解加速计算在神经网络推理中的应用
Week3
主题:全排列语言模型中的Transformer结构
本节课将介绍全排列语言模型(Permutation Language Model)任务,并介绍基于该任务对Transformer模型的修改。
课程提纲:
Transformer-XL
Relative Positional Embedding
Permutation Language Model
XLNet
MPNet
Week4
主题:结合对比学习的Transformer模型
本节课将对比学习框架简介。在对比学习框架中应用Transformer模型:如何设计对比学习中的正负例。
课程提纲:
对比学习中的常见损失函数
词粒度的对比:ELECTRA
句子粒度的对比:ALBERT,StructBERT
其他对比学习结构
Week5
主题:Transformer模型在知识建模中的应用
本节课主要介绍如何将Transformer模型应用于知识建模中,包括如何为模型注入知识,如何更好地利用模型中的知识等。
课程提纲:
ERNIE/ERNIE2.0/ERNIE3.0
KnowBERT
K-BERT
SentiLR
KEPLER
WKLM
CoLAKE
Week6
主题:多语言应用中的Transformer以及适用于中文的Transformer
本节课将介绍在多语言应用中如何改进transformer,以及如何更好的在中文中应用Transformer模型。
课程提纲:
多语言理解:mBERT,Unicoder,XLM-R,MultiFit
多语言生成:MASS,mBART,XNLG
处理中文的Transformer:BERT-wwm-Chinese,NEZHA,ZEN
适用于其他语言的Transformer:BERTje,CamemBERT,FlauBERT,RobBERT
Week7
主题:Transformer在对话和摘要任务中的应用
本节课将介绍Transformer在对话任务中的应用以及Transformer在文本摘要任务中的应用。
课程提纲:
对话中的Transformer模型:TransferTransfo,DialoGPT,Blender Bot,Meena,PLATO,LaMDa,GALAXY
文本摘要中的Transformer模型:BART,Pegasus
Week8
主题:Transformer进阶:更快,更大或更小
本节课将介绍Transformer结构中的实用技巧,如何实现更快的attention,如何增大Transformer的参数量,如何减少Transformer的参数量。
课程提纲:
更快:Multi-query Attention, Sparse Attention,performer,fastformer
更大:Mixture of Expert (MoE)
更小: CompressingBERT, Q-BERT, ALBERT, DistillBERT, TinyBERT,MiniLM, BERT-of-Theseus。
项目介绍
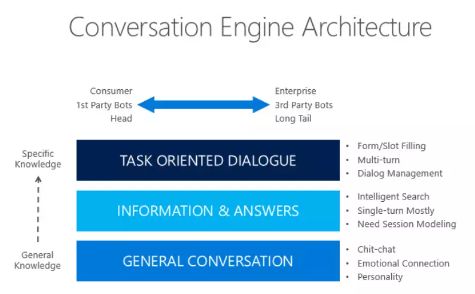
项目1:基于Transformer的客服对话系统
项目内容描述:
在本项目中,我们会带领大家实现基于Transformer模型实现自然语言理解(NLU)模块和自然语言生成(NLG)模块。客服对话系统主要实现了自动与用户进行对话的功能,并且帮助用户完成特定的任务,如订机票、酒店、餐馆等。客服对话系统是任务导向对话系统(Task-oriented Dialogue System)中最广泛的一种应用。客服对话系统中最重要的两个模块即为自然语言理解(NLU)模块和自然语言生成(NLG)模块。
项目使用的算法:
TextCNN/LSTM
BERT/RoBERTa
CRF
对比学习(Contrastive Loss/Triplet Loss)
项目使用的工具:
Python
pytorch
Elasticsearch
Transformers
项目预期结果:
使用基于Transformer的预训练模型实现意图识别模块:
a)熟练掌握基于CNN/LSTM的文本分类/序列标注模型
b)熟练掌握基于Transformer的预训练模型的微调方法
c)掌握模型压缩的方法
使用基于Transformer的预训练模型实现检索式对话模型:
a)掌握基于Elasticsearch的粗筛模块开发
b)熟练掌握基于Transformer的预训练模型的文本匹配算法
项目对应第几周的课程:1~4周
项目2:基于Transformer文本生成模型
项目内容描述:
在本项目中,我们会带领大家实现基于Transformer模型的生成式NLG模型。虽然这种类型的NLG模型存在一定的不可控性,但是随着预训练模型技术的发展,我们已经可以得到非常令人振奋的生成效果。甚至在某些特定领域,基于预训练Transformer模型所构建的文本生成已经开始创造巨大的商业价值(如文本摘要,代码生成,心理咨询等)。
项目使用的算法:
自回归语言模型(Auto-regressive Language Model)
Multi-input Self-Attention
Top-K/Unclear Sampling
Beam Search
Copy Mechanism
项目使用的工具:
Python
Pytorch
项目预期结果:
1.实现基于预训练Transformer的生成式NLG模型
2.了解文本生成模型的常用技术,包括
a)自回归语言模型中的MLE loss
b)文本生成模型中的各种解码技术
c)使用数据并行的方式利用多张GPU训练模型
3.有能力独立开发和优化基于预训练模型的文本生成模块。
项目对应第几周的课程:第1、2、5、6、7周。
助你成为行业TOP10%的工程师
对课程有意向的同学
扫描二维码咨询

CV Tranformer
![]()
02
全面的技术知识讲解
课程内容涵盖Bert/ViT/SegFormer/DETR/UP-DETR/ TimeSformer/ DeiT/Mobile-Transformer/Efficient Transformer/SwinTransformer/Point
Transformer/MTTR/MMT/Uniformer等10余个模型的讲解。
项目实践,学以致用
学员使用Transformer模型,练习CV领域应用最广泛的图像识别和目标检测任务。
专业团队严格打磨的课程内容,前沿且深入
课程内容经过前期数百小时的打磨设计,保证内容和项目节点设置合理,真正做到学有所得。
就业导向,目标明确
顺利完课后,优秀学员可获得字节、阿里、腾讯、美团等各互联网大厂,及商汤、旷视等AI独角兽公司的合作内推面试机会。
内容大纲
Week1
主题:NLP 中Transformer/Bert 知识梳理讲解
本节课将带领大家回顾NLP领域中Transformer/Bert技术。以此深入了解Transformer/Bert技术细节,算法优势。方便学生进一步学习Transformer 技术在其他领域的应用。
课程提纲:
NLP中Transformer中Self-Attention 机制、并行化原理等。
Transformer进阶Bert基本原理。
Week2
主题:Transformer 在图像分类、语义分割中的应用: ViT与SegFormer技术探究
基于第一节课的内容,进一步研究如何将Transformer思想迁移到两个计算机视觉中分类问题的应用: 图像分类,图像语义分割。以两个经典结构ViT, SegFormer为例,让学生体会如何将Transformer应用到视觉领域的思想。
课程提纲:
如何将Transformer设计思想应用到图像分类,语义分割问题中。
ViT
SegFormer
Week3
主题:Transformer在目标检测中的应用: DETR, UP-DETR技术探究
本节课将进一步学习如何将Transformer技术应用到目标检测任务重。特别是如何设计Transformer网络结构让神经网络能够同时学习到目标的类别信息与位置信息。
课程提纲:
深入理解Transformer 应用到object detection的设计思想。l
DETR
UP-DETR
Week4
主题:Transformer 在视频Video理解中的应用: TimeSformer 技术探究
本节课将进一步学习如何将Transformer技术应用到视频理解应用中,让Transformer能够同时学习时序上空间上的相关性。以TimeSformer为例,让学生能够深刻体会其中设计思想。
课程提纲:
将Transformer设计思想扩展到时序空间上相关性建模问题上应该注意的问题
TimeSformer
Week5
主题:Efficient Transformer 设计探讨:DeiT, Mobile-Transformer技术探究
高效的Transformer一直是研究者孜孜不倦的追求目标。这次课程将讨论如何设计高效的Transformer 网络结构。本节课将以DeiT, Mobile-Transformer为例,深入学习高效设计网络过程中需要注意的事项。
课程提纲:
Efficient Transformer设计中需要注意的问题,以及可以优化Transformer角度的探讨
DeiT
Mobile-Transformer
Week6
主题:经典Transformer网络结构学习: SwinTransformer 模型家族学习
本次课程将以SwinTransformer 模型为例,系统性学习SwinTransformer以及其变种模型。目的是让学生能够进一步体会将Transformer应用到视觉任务的网络设计过程中需要注意的问题,有哪些巧妙的思想以及如何通过合理的设计做到并行计算。
课程提纲:
SwinTransformer 模型家族
SwinTransformer设计思想。思考需要设计Transformer解决新的问题时需要注意的问题
Week7
主题:Transformer in Point Cloud
本节课将跟大家分享3D Point Cloud中的Transformer应用。根据3D Point Cloud数据特点,我们将深入探讨如何设计合适的Transformer网络来处理海量、无结构的点云数据。同时如何进一步修改Transformer结构如何对点云进行分割,聚类等任务。
课程提纲:
探讨设计Transformer处理点云数据时需要注意的事项
Point Transformer
Week8
主题:多模态应用中的Transformer设计
本节课我们将学习multi-modality 中Transformer设计问题。Transformer 在不同的领域得到了很好的应用。最近的工作在探究如何设计合适的Transformer结构处理多模态的数据。我们将以MTTR, MMT, Uniformer等相关Transformer为例子做讲解。
课程提纲:
探究设计Transformer处理multi-modal 数据时需要注意的问题
如何设计合适的Transformer来处理multi-modal相关问题:MTTR, MMT, Uniformer
项目介绍
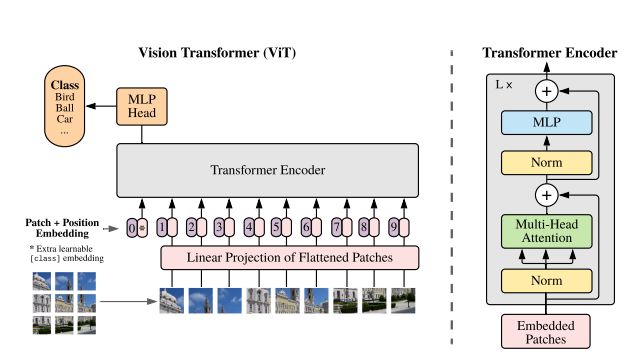
项目一:基于ViT 模型的图像识别系统
项目内容描述:作为Transformer在视觉领域的一个经典应用案例,ViT模型第一次将NLP领域中Transformer思想应用到图像领域,为后续的一系列Transformer in Vision 设计工作都提供了很好的思路启发。追根溯源,我们将以ViT模型做图像分类任务为例,开启一段如何将Transformer思想应用到视觉领域之旅。
项目使用的算法:
ViT model
Cross-entropy loss
Multi-label/multi-class classification
Self-attention
LSTM/GRU
项目使用的工具:
Python
pytorch
OpenCV
ViT
项目预期结果:
首先让学生自己动手实现ViT模型,在数据集上测试结果。然后根据官方的实现做对比,如果差异较大需要自己查找原因。
掌握如何将Transformer中token, self-attention 思想应用到图像领域。触类旁通,希望学生能够在深刻理解的基础上,能够学生将Transformer思想用到其他相关问题中去。
掌握ViT的训练方法,让学生跑完这个pipeline。从数据准备,模型训练,参数调节,到模型测试,指标计算等。
项目对应第几周的课程:1-3周。
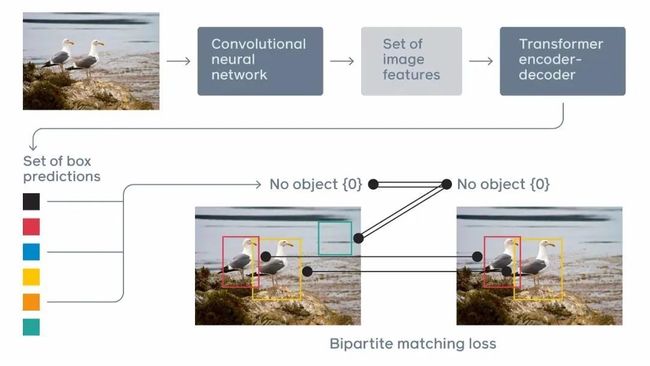
项目二:基于SwinTransformer 模型的图像分类,目标检测任务
项目内容描述:我们在上一个项目中学习了ViT模型,一个成功将Transformer应用到视觉分类问题的视觉Transformer模型。但是ViT模型的设计还是比较单一,存在一些不足。尤其是对图像中存在的问题,例如尺度变换问题没有很好的解决,并且没有考虑到效率问题。在本项目中,我们将学习另一个进阶版的视觉Transformer模型: SwinTransformer模型。
项目使用的算法:
SwinTransformer
Cross-Entropy Loss
Regression Loss
Forward-Backward Propagation
项目使用的工具:
Python
pytorch
OpenCV
项目预期结果:
学生自己实现SwinTransformer代码(也可参照官方实现),并且参照官方实现优化自己的实现,如果实验效果差异较大,学生需要查找原因。
体会用SwinTransformer来做目标检测的思想。
掌握如何从代码角度优化实现SwinTransformer的self-attention机制从局部扩展到全局。
学生掌握如何将Transformer思想应用到自己工作或者学习中的实际问题中去。
项目对应第几周的课程:6~7周。
助你成为行业TOP10%的工程师
对课程有意向的同学
扫描二维码咨询

联邦学习与隐私计算
![]()
03
全面的技术知识讲解
课程内容涵盖横向联邦学习、纵向联邦学习、联邦迁移学习三大模型架构,包含联邦学习在视觉、医疗、金融、隐私计算、政务服务等应用案例的讲解。
项目实践,学以致用
学员使用联邦学习框架与算法,实践金融领域隐私计算与风险检测的任务。
专业团队严格打磨的课程内容,前沿且深入
课程内容经过前期数百小时的打磨设计,保证内容和项目节点设置合理,真正做到学有所得。
就业导向,目标明确
顺利完课后,优秀学员可获得京东、百度等互联网大厂联邦学习工程师岗位的合作内推面试机会。
内容大纲
Week1
主题:初识联邦学习与隐私计算
讲解联邦学习定义、联邦学习分类、联邦学习的研究进展、联邦学习开源平台、联邦学习中使用的隐私保护技术、隐私计算基础知识等内容。
课程提纲:
联邦学习系统架构
联邦学习分类
联邦学习常用开源平台
联邦学习中的隐私保护技术
隐私计算定义与分类
同态加密
差分隐私
安全多方计算
Week2
主题:分布式机器学习
讲解分布式机器学习的定义、分布式机器学习算法、分布式机器学习到联邦学习的演进等内容。
课程提纲:
分布式机器学习定义
分布式机器学习平台
大规模机器学习
隐私保护机器学习方案
分布式机器学习算法
Week3
主题:横向联邦学习
讲解横向联邦学习的定义、横向联邦学习架构、横向联邦学习算法、横向联邦学习的优化等内容。
课程提纲:
横向联邦学习定义
横向联邦学习架构
联邦平均算法
横向联邦学习算法
Week4
主题:使用隐私计算构建金融领域风控模型
讲解使用隐私计算构建金融领域风控模型的流程、分析等内容。
课程提纲:
横向联邦学习构建流程
横向联邦学习结果分析
Week5
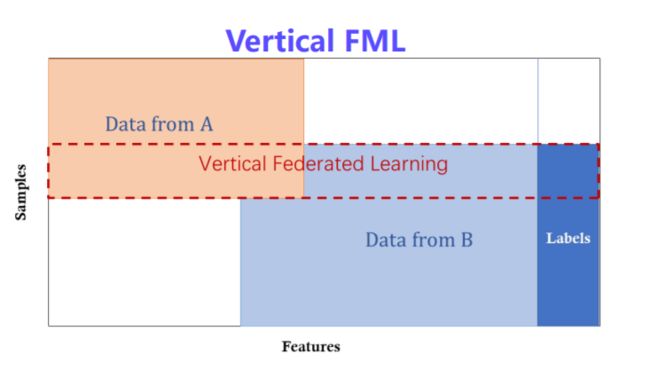
主题:纵向联邦学习
讲解纵向联邦学习的定义、纵向联邦学习架构、纵向联邦学习算法、纵向联邦学习的优化等内容。
课程提纲:
纵向联邦学习定义
纵向联邦学习架构
纵向联邦线性回归
纵向联邦决策树
Week6
主题:联邦迁移学习
讲解联邦迁移学习的定义、联邦迁移学习架构、联邦迁移学习算法、联邦迁移学习的优化等内容。
课程提纲:
联邦迁移学习定义
联邦迁移学习框架
联邦迁移学习训练与预测
联邦迁移学习中的同态加密
联邦迁移学习中的秘密共享
Week7
主题:隐私计算、联邦学习在不同领域的应用及前沿研究
讲解隐私计算和联邦学习在不同领域的应用案例、研究内容、面临问题等内容。例如计算机视觉领域的联邦学习目标检测网络;政务领域的差分隐私数据共享;智能物联网中的联邦学习用户行为预测;医疗领域的联邦学习健康分析、同态加密基因分析;金融领域的联邦学习反欺诈、隐私求教联合风控等。
课程提纲:
联邦学习应用案例(计算机视觉领域的联邦学习目标检测网络,政务领域的差分隐私数据共享,智能物联网中的联邦学习用户行为预测,医疗领域的联邦学习健康分析等)
联邦学习研究及面临问题
隐私计算应用案例
隐私计算研究及面临问题
Week8
主题:使用联邦学习构建金融领域风险监测模型
讲解使用联邦学习构建金融领域风险监测模型的流程、结果分析等内容。
课程提纲:
金融领域风险监测模型构建流程
金融领域风险监测模型结果分析
项目介绍
项目一:金融隐私计算实战
项目内容描述:讲解联邦学习和隐私计算相关的概念、联邦学习和隐私计算的发展、联邦学习的基础技术(隐私保护技术和分布式学习技术)、横向联邦学习定义、横向联邦学习架构及算法详解,最终使用隐私计算构建金融领域风控模型。
项目使用的算法:
横向联邦学习
项目使用的工具:
FATE/examples/data,开源数据集
项目预期结果:
熟悉联邦学习和隐私计算相关知识和基本概念,熟悉横向联邦学习定义及架构,学会横向联邦学习算法并基于隐私计算实现金融领域风险监测。
项目对应第几周的课程:1~4周

项目二:基于联邦学习的金融领域风险监测实战
项目内容描述:讲解纵向联邦学习定义、纵向联邦学习架构及算法详解,讲解联邦迁移学习定义、联邦迁移学习架构及算法详解,讲解联邦学习在业界的应用现状和典型案例,最终使用开源框架FATE实现一个金融领域风险监测模型的构建。
项目使用的算法:
联邦学习
项目使用的工具:
Python、开源框架FATE
项目预期结果:
熟悉纵向联邦学习、联邦迁移学习定义及架构,学会纵向联邦学习、联邦迁移学习算法,并基于开源框架FATE实现一个金融领域风险监测模型。
项目对应第几周的课程:5-8周
助你成为行业TOP10%的工程师
对课程有意向的同学
扫描二维码咨询

适合人群
大学生
编程及深度学习基础良好,为了想进入AI行业发展
对于Transformer或联邦学习有浓厚兴趣,希望进行实践
在职人士
工作中需要应用机器学习,深度学习等技术
想进入AI算法行业成为AI算法工程师
想通过掌握AI高阶知识,拓宽未来职业路径
导师团队
郑老师
NLP主讲老师
清华大学计算机科学与人工智能研究部博士后
美国劳伦斯伯克利国家实验室访问学者
主要从事自然语言处理,对话领域的先行研究与商业化
先后在AAAI,NeurIPS,ACM,EMNLP等国际顶会及期刊发表高水平论文十余篇

Jackson
CV主讲老师
牛津大学计算机博士
曾在BAT等多家公司任职算法科学家
从事计算机视觉,深度学习,语音信号处理相关研究
先后在CVPR, ICML, AAAI, ICRA等国际顶会及期刊发表多篇论文

完颜老师
联邦学习主讲老师
北京航空航天大学信号与信息处理博士
某金融央企研究院副高级工程师
在SCI Q1、EI、核心等不同级别的国内外著名期刊发表论文十余篇,受理及授权发明专利5项,软件著作权3项
参与国家863计划、公安部应用创新计划等科研课题,主持绿色发展大数据决策北京市重点实验室、北航金华北斗应用研究院、清华联合研究院等多项科研课题

Jerry Yuan
课程研发顾问
美国微软(总部)推荐系统部负责人
美国亚马逊(总部)资深工程师
美国新泽西理工大学博士
14年人工智能, 数字图像处理和推荐系统领域研究和项目经验
先后在AI相关国际会议上发表20篇以上论文

李文哲
贪心科技CEO
美国南加州大学博士
曾任独角兽金科集团首席数据科学家、美国亚马逊和高盛的高级工程师
金融行业开创知识图谱做大数据反欺诈的第一人
先后在AAAI、KDD、AISTATS、CHI等国际会议上发表过15篇以上论文
授课方式
基础知识讲解
前沿论文解读
该知识内容的实际应用
该知识的项目实战
该方向的知识延申及未来趋势讲解
助你成为行业TOP10%的工程师
对课程有意向的同学
扫描二维码咨询
