自然语言处理中的预训练模型-邱锡鹏老师
自然语言处理中的预训练模型
视频地址(https://www.bilibili.com/video/av883626347
参考https://blog.csdn.net/qq_37388085/article/details/108463269
1、自然语言表示学习
1.1 什么是自然语言处理(NLP)
自然语言≈人类语言,不同于人工语言(如程序语言);
1.2 NLP的基础:语言表示
如何在计算机中表示语言的语义?
知识库规则
分布式表示
句子嵌入
1.3 自然语言处理任务
序列到类别-情感分类/文本蕴含
同步的序列到序列-中文分词
异步的序列到序列-机器翻译
1.4 NLP的语义组合
语言的性质:层次性/递归性/序列性
语义组合:句子的语义可以词组成/长程依赖
1.5 NLP模型演变
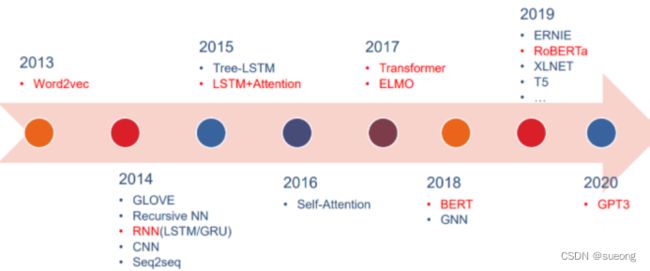
1.6 NLP中的三大模型

卷积模型:通过卷积核进行信息读取整理;
序列模型:同一层模型之间存在信息传递;
全连接图模型:h1的上下文表示依赖输入的所有词,这就是全连接,全连接用虚线表示其权重是动态计算的
这样远距离依赖会丢失 前两个问题难以处理长距离依赖问题。可以通过加深层数来解决,但是这样参数也会更难学。
1.7 注意力机制:自注意力模型、多头自注意力模型

给定序列"The weather is nice today",假设现在需要知道"The"的上下文表示,"The"有可能需要依赖序列中的非局部信息,因此我们将其与输入的所有词进行链接;为了得到对应每个词的权重,将"The"与其它所有词计算相似度获得对应的权重,最后进行累加得到"The"的上下文向量表示。
自注意力机制:就是说它的query来自内部 求the 的上下文 :加权组合和累计求和
Q K计算相似度矩阵 X是转置 V用来做加权汇总 使得模型学习能力更强

多头自注意力:模型将自注意力模型进行重复叠加操作,得到多组不同的上下文表示,可以理解为在不同空间中的语组关系,将其拼接起来,最后再使用一个参数矩阵W将其变换为输入时对应的向量维度。得到更强的上学文表示
1.8 Transformer
可能是目前为止最适合NLP的模型;
广义的Transformer指一种基于自注意力的全连接神经网络
核心组件:自注意力(self-attention)
仅仅有自注意力还不够(例如没有考虑位置信息),还包括其它操作:
- 位置编码
- 层归一化
- 直连边
- 逐位的FNN

直连边 使得位置更好的回传
2、预训练模型
2.1 预训练模型之前
如果要训练一个比较好的NLP模型,需要改变原来的训练方法,即从端到端从零开始学习转变为进行"数据增强"、"迁移学习"、"多任务学习"
- 数据增强:引入外部知识,比如增加人工的辅助损失函数等;
- 迁移学习:在大语料上把数据训练好,然后再迁移到目标任务中;
- 多任务学习:一个任务的数据可能很少,可以把多个任务的数据拼接到一起进行模型训练;
2.2 为什么要预训练
- 获得通用的语言表示;其实语言表示不需要和任务相关
- 获得一个好的初始化(Hinton在2006年使用玻尔兹曼机初始化深度神经网络);没有预训练 随机初始化效率低
- 预训练可以看做一种正则化方法(避免在小数据集上过拟合),由于模型比较复杂,当训练数据较小时很容易导致过拟合;在一个通用模型后继续训练(fine-tune) 不至于导致过拟合
2.3 预训练任务
预训练带来一个问题,怎么获取大量的预训练语料?主要有以下三种方法:
- 监督学习 —— 机器翻译有大量语料;
- 无监督学习 —— 使用语言模型进行预训练,不需要标签信息;
- 自监督学习 —— 掩码语言模型(masked language model, MLM),掩码语言模型不依赖标注数据,是一种伪监督任务,其目的是学习数据中的可泛化知识;
预训练任务汇总:
Seq2seqMLM:假设xi-xj部分扣掉 送入encoder 在送入decoder 输出xi-xj
除了lm有明确任务 其他都是人工的构造任务 任务可能在实际中不存在 是伪任务
但是可以让模型隐含的学到在数据中隐含的知识

2.4 典型模型
预训练模型分类体系

不含上下文(只训word embedding)和含上下文(word embedding 连encoder一起训练)
2.4.1 Bert
监督信号加在cls结点上。Bert有两个训练任务,第一个任务是预测被mask的单词,第二个任务是句子级任务——句对预测。
图片中有两个特殊的地方,在句子输入中添加了[CLS]和[SEP],[SEP]的作用是区分两句话,[CLS]用于捕捉全局信息;
当使用Bert进行分类任务时,直接在Bert上拼接一个分类器就能执行分类任务;

Bert训练方式决定了ta很适合做句子对的预测。它不仅可以处理句子内的预测,还可以跨句捕捉词之间的依赖关系。
Bert不太适合做异步到异步序列的任务 如机器翻译
2.4.2 SpanBert
2.4.3 StructBert
2.4.4 XLNet
Xlnet解决了bert在训练有masked 而应用场景是没有masked的问题 不是从头到尾预测 是打乱预测,相当于是打乱前n-1的词,预测第n个词
2.4.5 T5
所有任务都转成 序列到序列的任务 加前缀来区分任务

2.4.6 GPT-3
3、预训练模型的扩展
3.1 Knowledge-Enriched PTMs
3.2 Multilingual and Language-Specific PTMs
3.3 模型压缩
4、迁移到下游任务
4.1 选择适当的预训练任务,模型架构和语料库
4.2 选择合适的预训练模型的神经网络层
4.3 预训练模型的参数是否微调

Bert主体不变 加了两个自适应模块

不仅判断整体句子的好坏 还判断内部每个实体的好坏
4.4 句子分类变为句子对分类
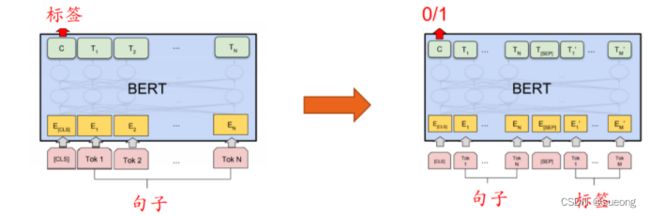
4.5 集成Bert

不同时间步的bert集成在一起 得到的平均bert更好

4.6 Self-Ensembel and Self-Distillation
5、未来展望
5.1 预训练模型的上界
5.2 预训练模型的架构
5.3 任务定向的预训练和模型压缩
5.4 除了微调之外的知识迁移
特征提取;
知识蒸馏;将数据迁移到更小的模型上
数据增强;bert生成负样例 再训练
将预训练模型作为额外知识;整个bert作为外部知识 只要给它正确的query
5.5 预训练模型的可解释性和可靠性
如何微调?

