贡献者:飞龙
本文来自【ApacheCN Java 译文集】,自豪地采用谷歌翻译。
本章包括涉及 Java 并发的 13 个问题,涉及 Fork/Join 框架、CompletableFuture、ReentrantLock、ReentrantReadWriteLock、StampedLock、原子变量、任务取消、可中断方法、线程局部、死锁等方面。对于任何开发人员来说,并发性都是必需的主题之一,在工作面试中不能被忽视。这就是为什么这一章和最后一章如此重要。读完本章,您将对并发性有相当的了解,这是每个 Java 开发人员都需要的。
问题
使用以下问题来测试您的并发编程能力。我强烈建议您在使用解决方案和下载示例程序之前,先尝试一下每个问题:
- 可中断方法:编写一个程序,举例说明处理可中断方法的最佳方法。
- Fork/Join 框架:编写一个依赖 Fork/Join 框架对列表元素求和的程序。编写一个依赖 Fork/Join 框架的程序来计算给定位置的斐波那契数(例如,
F(12) = 144)。另外,编写一个程序来举例说明CountedCompleter的用法。 - Fork/Join 和
compareAndSetForkJoinTaskTag():编写一个程序,将 Fork/Join 框架应用到一组相互依存的任务,只需执行一次(例如任务 D 依赖于任务 C 和任务 B,但任务 C 依赖于任务 B 也一样,因此任务 B 只能执行一次,不能执行两次。 CompletableFuture:通过CompletableFuture写几个代码片段来举例说明异步代码。- 组合多个
CompletableFuture对象:写几段代码举例说明组合多个CompletableFuture对象的不同解决方案。 - 优化忙等待:写一个概念证明来举例说明通过
onSpinWait()优化忙等待技术。 - 任务取消:写一个概念证明,举例说明如何使用
volatile变量来保存进程的取消状态。 ThreadLocal:写一个概念证明,举例说明ThreadLocal的用法。- 原子变量:使用多线程应用(
Runnable编写一个从 1 到 1000000 的整数计数程序。 ReentrantLock:编写一个程序,使用ReentrantLock将整数从 1 递增到 1000000。ReentrantReadWriteLock:通过ReentrantReadWriteLock编写模拟读写过程编排的程序。StampedLock:通过StampedLock编写模拟读写过程编排的程序。- 死锁(哲学家就餐):编写一个程序,揭示并解决著名餐饮哲学家问题中可能出现的死锁(循环等待或致命拥抱)。
以下各节介绍上述问题的解决方案。记住,通常没有一个正确的方法来解决一个特定的问题。另外,请记住,这里显示的解释仅包括解决问题所需的最有趣和最重要的细节。下载示例解决方案以查看更多详细信息,并在这个页面中试用程序。
213 可中断方法
所谓可中断方法,是指可以抛出InterruptedException的阻塞方法,例如Thread.sleep()、BlockingQueue.take()、BlockingQueue.poll(long timeout, TimeUnit unit)等。阻塞线程通常处于阻塞、等待或定时等待状态,如果被中断,则该方法尝试尽快抛出InterruptedException。
因为InterruptedException是一个检查过的异常,所以我们必须捕获它和/或抛出它。换句话说,如果我们的方法调用了抛出InterruptedException的方法,那么我们必须准备好处理这个异常。如果我们可以抛出它(将异常传播给调用方),那么它就不再是我们的工作了。打电话的人必须进一步处理。所以,当我们必须抓住它的时候,让我们把注意力集中在这个案子上。当我们的代码在Runnable内运行时,就会出现这种情况,因为它不能抛出异常。
让我们从一个简单的例子开始。试图通过poll(long timeout, TimeUnit unit)从BlockingQueue获取元素可以写为:
try {
queue.poll(3000, TimeUnit.MILLISECONDS);
} catch (InterruptedException ex) {
...
logger.info(() -> "Thread is interrupted? "
+ Thread.currentThread().isInterrupted());
}尝试轮询队列中的元素可能会导致InterruptedException。有一个 3000 毫秒的窗口可以中断线程。在中断的情况下(例如,Thread.interrupt()),我们可能会认为调用catch块中的Thread.currentThread().isInterrupted()将返回true。毕竟,我们处在一个InterruptedException catch街区,所以相信这一点是有道理的。实际上,它会返回false,答案在poll(long timeout, TimeUnit unit)方法的源代码中,如下所示:
1: public E poll(long timeout, TimeUnit unit)
throws InterruptedException {
2: E e = xfer(null, false, TIMED, unit.toNanos(timeout));
3: if (e != null || !Thread.interrupted())
4: return e;
5: throw new InterruptedException();
6: }更准确地说,答案在第 3 行。如果线程被中断,那么Thread.interrupted()将返回true,并将导致第 5 行(throw new InterruptedException()。但是除了测试之外,如果当前线程被中断,Thread.interrupted()清除线程的中断状态。请查看以下连续调用中断线程:
Thread.currentThread().isInterrupted(); // true
Thread.interrupted() // true
Thread.currentThread().isInterrupted(); // false
Thread.interrupted() // false注意,Thread.currentThread().isInterrupted()测试这个线程是否被中断,而不影响中断状态。
现在,让我们回到我们的案子。所以,我们知道线程在捕捉到InterruptedException后就中断了,但是中断状态被Thread.interrupted()清除了。这也意味着我们代码的调用者不会意识到中断。
我们有责任成为好公民,通过调用interrupt()方法恢复中断。这样,我们代码的调用者就可以看到发出了中断,并相应地采取行动。正确的代码如下:
try {
queue.poll(3000, TimeUnit.MILLISECONDS);
} catch (InterruptedException ex) {
...
Thread.currentThread().interrupt(); // restore interrupt
}根据经验,在捕捉到InterruptedException之后,不要忘记通过调用Thread.currentThread().interrupt()来恢复中断。
让我们来解决一个突出显示忘记恢复中断的问题。假设一个Runnable只要当前线程没有中断就可以运行(例如,while (!Thread.currentThread().isInterrupted()) { ... }。
在每次迭代中,如果当前线程中断状态为false,那么我们尝试从BlockingQueue中获取一个元素。
实现代码如下:
Thread thread = new Thread(() -> {
// some dummy queue
TransferQueue queue = new LinkedTransferQueue<>();
while (!Thread.currentThread().isInterrupted()) {
try {
logger.info(() -> "For 3 seconds the thread "
+ Thread.currentThread().getName()
+ " will try to poll an element from queue ...");
queue.poll(3000, TimeUnit.MILLISECONDS);
} catch (InterruptedException ex) {
logger.severe(() -> "InterruptedException! The thread "
+ Thread.currentThread().getName() + " was interrupted!");
Thread.currentThread().interrupt();
}
}
logger.info(() -> "The execution was stopped!");
}); 作为调用者(另一个线程),我们启动上面的线程,睡眠 1.5 秒,只是给这个线程时间进入poll()方法,然后我们中断它。如下代码所示:
thread.start();
Thread.sleep(1500);
thread.interrupt();这将导致InterruptedException。
记录异常并恢复中断。
下一步,while计算Thread.currentThread().isInterrupted()到false并退出。
因此,输出如下:
[18:02:43] [INFO] For 3 seconds the thread Thread-0
will try to poll an element from queue ...
[18:02:44] [SEVERE] InterruptedException!
The thread Thread-0 was interrupted!
[18:02:45] [INFO] The execution was stopped!现在,让我们对恢复中断的行进行注释:
...
} catch (InterruptedException ex) {
logger.severe(() -> "InterruptedException! The thread "
+ Thread.currentThread().getName() + " was interrupted!");
// notice that the below line is commented
// Thread.currentThread().interrupt();
}
...这一次,while块将永远运行,因为它的保护条件总是被求值为true。
代码不能作用于中断,因此输出如下:
[18:05:47] [INFO] For 3 seconds the thread Thread-0
will try to poll an element from queue ...
[18:05:48] [SEVERE] InterruptedException!
The thread Thread-0 was interrupted!
[18:05:48] [INFO] For 3 seconds the thread Thread-0
will try to poll an element from queue ...
...根据经验,当我们可以接受中断(而不是恢复中断)时,唯一可以接受的情况是我们可以控制整个调用栈(例如,extend Thread)。
否则,捕获的InterruptedException也应该包含Thread.currentThread().interrupt()。
214 Fork/Join 框架
我们已经在“工作线程池”一节中介绍了 Fork/Join 框架。
Fork/Join 框架主要用于处理一个大任务(通常,通过大,我们可以理解大量的数据)并递归地将其拆分为可以并行执行的小任务(子任务)。最后,在完成所有子任务后,它们的结果将合并(合并)为一个结果。
下图是 Fork/Join 流的可视化表示:
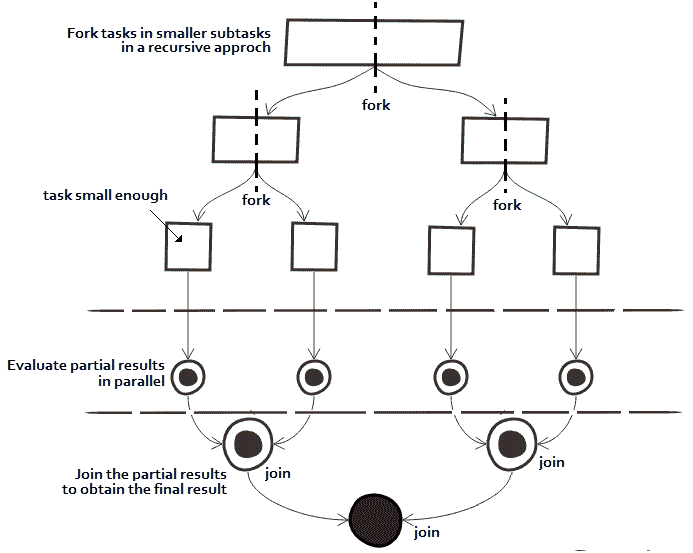
在 API 方面,可以通过java.util.concurrent.ForkJoinPool创建叉/连接。
JDK8 之前,推荐的方法依赖于public static变量,如下所示:
public static ForkJoinPool forkJoinPool = new ForkJoinPool();从 JDK8 开始,我们可以按如下方式进行:
ForkJoinPool forkJoinPool = ForkJoinPool.commonPool();这两种方法都避免了在单个 JVM 上有太多池线程这一令人不快的情况,这是由创建它们自己的池的并行操作造成的。
对于自定义的ForkJoinPool,依赖于此类的构造器。JDK9 添加了迄今为止最全面的一个(详细信息见文档)。
AForkJoinPool对象操作任务。ForkJoinPool中执行的任务的基本类型为ForkJoinTask。更确切地说,执行以下任务:
RecursiveAction对于void任务RecursiveTask对于返回值的任务CountedCompleter对于需要记住挂起任务计数的任务
这三种类型的任务都有一个名为compute()的抽象方法,在这个方法中任务的逻辑是成形的。
向ForkJoinPool提交任务可以通过以下方式完成:
execute()和submit()invoke()派生任务并等待结果invokeAll()用于分叉一堆任务(例如,集合)fork()用于安排在池中异步执行此任务,join()用于在完成时返回计算结果
让我们从一个通过RecursiveTask解决的问题开始。
通过RecursiveTask计算总和
为了演示框架的分叉行为,我们假设我们有一个数字列表,并且我们要计算这些数字的总和。为此,我们使用createSubtasks()方法递归地拆分(派生)这个列表,只要它大于指定的THRESHOLD。每个任务都被添加到List中。最后通过invokeAll(Collection方式将该列表提交给ForkJoinPool。这是使用以下代码完成的:
public class SumRecursiveTask extends RecursiveTask {
private static final Logger logger
= Logger.getLogger(SumRecursiveTask.class.getName());
private static final int THRESHOLD = 10;
private final List worklist;
public SumRecursiveTask(List worklist) {
this.worklist = worklist;
}
@Override
protected Integer compute() {
if (worklist.size() <= THRESHOLD) {
return partialSum(worklist);
}
return ForkJoinTask.invokeAll(createSubtasks())
.stream()
.mapToInt(ForkJoinTask::join)
.sum();
}
private List createSubtasks() {
List subtasks = new ArrayList<>();
int size = worklist.size();
List worklistLeft
= worklist.subList(0, (size + 1) / 2);
List worklistRight
= worklist.subList((size + 1) / 2, size);
subtasks.add(new SumRecursiveTask(worklistLeft));
subtasks.add(new SumRecursiveTask(worklistRight));
return subtasks;
}
private Integer partialSum(List worklist) {
int sum = worklist.stream()
.mapToInt(e -> e)
.sum();
logger.info(() -> "Partial sum: " + worklist + " = "
+ sum + "\tThread: " + Thread.currentThread().getName());
return sum;
}
} 为了测试它,我们需要一个列表和ForkJoinPool如下:
ForkJoinPool forkJoinPool = ForkJoinPool.commonPool();
Random rnd = new Random();
List list = new ArrayList<>();
for (int i = 0; i < 200; i++) {
list.add(1 + rnd.nextInt(10));
}
SumRecursiveTask sumRecursiveTask = new SumRecursiveTask(list);
Integer sumAll = forkJoinPool.invoke(sumRecursiveTask);
logger.info(() -> "Final sum: " + sumAll); 可能的输出如下:
...
[15:17:06] Partial sum: [1, 3, 6, 6, 2, 5, 9] = 32
ForkJoinPool.commonPool-worker-9
...
[15:17:06] Partial sum: [1, 9, 9, 8, 9, 5] = 41
ForkJoinPool.commonPool-worker-7
[15:17:06] Final sum: 1084用递归运算计算斐波那契函数
斐波那契数通常表示为F(n),是一个遵循以下公式的序列:
F(0) = 0,
F(1) = 1,
...,
F(n) = F(n-1) + F(n-2), n > 1斐波那契数的快照是:
0, 1, 1, 2, 3, 5, 8, 13, 21, 34, 55, 89, 144, ...通过RecursiveAction实现斐波那契数可以如下完成:
public class FibonacciRecursiveAction extends RecursiveAction {
private static final Logger logger =
Logger.getLogger(FibonacciRecursiveAction.class.getName());
private static final long THRESHOLD = 5;
private long nr;
public FibonacciRecursiveAction(long nr) {
this.nr = nr;
}
@Override
protected void compute() {
final long n = nr;
if (n <= THRESHOLD) {
nr = fibonacci(n);
} else {
nr = ForkJoinTask.invokeAll(createSubtasks(n))
.stream()
.mapToLong(x -> x.fibonacciNumber())
.sum();
}
}
private List createSubtasks(long n) {
List subtasks = new ArrayList<>();
FibonacciRecursiveAction fibonacciMinusOne
= new FibonacciRecursiveAction(n - 1);
FibonacciRecursiveAction fibonacciMinusTwo
= new FibonacciRecursiveAction(n - 2);
subtasks.add(fibonacciMinusOne);
subtasks.add(fibonacciMinusTwo);
return subtasks;
}
private long fibonacci(long n) {
logger.info(() -> "Number: " + n
+ " Thread: " + Thread.currentThread().getName());
if (n <= 1) {
return n;
}
return fibonacci(n - 1) + fibonacci(n - 2);
}
public long fibonacciNumber() {
return nr;
}
} 为了测试它,我们需要以下ForkJoinPool对象:
ForkJoinPool forkJoinPool = ForkJoinPool.commonPool();
FibonacciRecursiveAction fibonacciRecursiveAction
= new FibonacciRecursiveAction(12);
forkJoinPool.invoke(fibonacciRecursiveAction);
logger.info(() -> "Fibonacci: "
+ fibonacciRecursiveAction.fibonacciNumber());F(12)的输出如下:
[15:40:46] Number: 5 Thread: ForkJoinPool.commonPool-worker-3
[15:40:46] Number: 5 Thread: ForkJoinPool.commonPool-worker-13
[15:40:46] Number: 4 Thread: ForkJoinPool.commonPool-worker-3
[15:40:46] Number: 4 Thread: ForkJoinPool.commonPool-worker-9
...
[15:40:49] Number: 0 Thread: ForkJoinPool.commonPool-worker-7
[15:40:49] Fibonacci: 144使用CountedCompleter
CountedCompleter是 JDK8 中增加的ForkJoinTask类型。
CountedCompleter的任务是记住挂起的任务计数(不能少,不能多)。我们可以通过setPendingCount()设置挂起计数,也可以通过addToPendingCount(int delta)用显式的delta递增。通常,我们在分叉之前调用这些方法(例如,如果我们分叉两次,则根据具体情况调用addToPendingCount(2)或setPendingCount(2))。
在compute()方法中,我们通过tryComplete()或propagateCompletion()减少挂起计数。当调用挂起计数为零的tryComplete()方法或调用无条件complete()方法时,调用onCompletion()方法。propagateCompletion()方法与tryComplete()类似,但不调用onCompletion()。
CountedCompleter可以选择返回计算值。为此,我们必须重写getRawResult()方法来返回一个值。
下面的代码通过CountedCompleter对列表的所有值进行汇总:
public class SumCountedCompleter extends CountedCompleter {
private static final Logger logger
= Logger.getLogger(SumCountedCompleter.class.getName());
private static final int THRESHOLD = 10;
private static final LongAdder sumAll = new LongAdder();
private final List worklist;
public SumCountedCompleter(
CountedCompleter c, List worklist) {
super(c);
this.worklist = worklist;
}
@Override
public void compute() {
if (worklist.size() <= THRESHOLD) {
partialSum(worklist);
} else {
int size = worklist.size();
List worklistLeft
= worklist.subList(0, (size + 1) / 2);
List worklistRight
= worklist.subList((size + 1) / 2, size);
addToPendingCount(2);
SumCountedCompleter leftTask
= new SumCountedCompleter(this, worklistLeft);
SumCountedCompleter rightTask
= new SumCountedCompleter(this, worklistRight);
leftTask.fork();
rightTask.fork();
}
tryComplete();
}
@Override
public void onCompletion(CountedCompleter caller) {
logger.info(() -> "Thread complete: "
+ Thread.currentThread().getName());
}
@Override
public Long getRawResult() {
return sumAll.sum();
}
private Integer partialSum(List worklist) {
int sum = worklist.stream()
.mapToInt(e -> e)
.sum();
sumAll.add(sum);
logger.info(() -> "Partial sum: " + worklist + " = "
+ sum + "\tThread: " + Thread.currentThread().getName());
return sum;
}
} 现在,让我们看看一个潜在的调用和输出:
ForkJoinPool forkJoinPool = ForkJoinPool.commonPool();
Random rnd = new Random();
List list = new ArrayList<>();
for (int i = 0; i < 200; i++) {
list.add(1 + rnd.nextInt(10));
}
SumCountedCompleter sumCountedCompleter
= new SumCountedCompleter(null, list);
forkJoinPool.invoke(sumCountedCompleter);
logger.info(() -> "Done! Result: "
+ sumCountedCompleter.getRawResult()); 输出如下:
[11:11:07] Partial sum: [7, 7, 8, 5, 6, 10] = 43
ForkJoinPool.commonPool-worker-7
[11:11:07] Partial sum: [9, 1, 1, 6, 1, 2] = 20
ForkJoinPool.commonPool-worker-3
...
[11:11:07] Thread complete: ForkJoinPool.commonPool-worker-15
[11:11:07] Done! Result: 1159215 Fork/Join 框架和compareAndSetForkJoinTaskTag()
现在,我们已经熟悉了 Fork/Join 框架,让我们看看另一个问题。这次让我们假设我们有一组相互依赖的对象。下图可以被视为一个用例:

以下是前面图表的说明:
TaskD有三个依赖项:TaskA、TaskB、TaskC。TaskC有两个依赖项:TaskA和TaskB。TaskB有一个依赖关系:TaskA。TaskA没有依赖关系。
在代码行中,我们将对其进行如下塑造:
ForkJoinPool forkJoinPool = ForkJoinPool.commonPool();
Task taskA = new Task("Task-A", new Adder(1));
Task taskB = new Task("Task-B", new Adder(2), taskA);
Task taskC = new Task("Task-C", new Adder(3), taskA, taskB);
Task taskD = new Task("Task-D", new Adder(4), taskA, taskB, taskC);
forkJoinPool.invoke(taskD);Adder是一个简单的Callable,每个任务只能执行一次(因此,对于TaskD、TaskC、TaskB、TaskA执行一次)。Adder由以下代码启动:
private static class Adder implements Callable {
private static final AtomicInteger result = new AtomicInteger();
private Integer nr;
public Adder(Integer nr) {
this.nr = nr;
}
@Override
public Integer call() {
logger.info(() -> "Adding number: " + nr
+ " by thread:" + Thread.currentThread().getName());
return result.addAndGet(nr);
}
}我们已经知道如何将 Fork/Join 框架用于具有非循环和/或不可重复(或者我们不关心它们是否重复)完成依赖关系的任务。但是如果我们用这种方式实现,那么每个任务都会多次调用Callable。例如,TaskA作为其他三个任务的依赖项出现,因此Callable将被调用三次。我们只想要一次。
JDK8 中添加的一个非常方便的特性ForkJoinPool是用short值进行原子标记:
short getForkJoinTaskTag():返回该任务的标签。short setForkJoinTaskTag(short newValue):自动设置此任务的标记值,并返回旧值。boolean compareAndSetForkJoinTaskTag(short expect, short update):如果当前值等于expect并且更改为update,则返回true。
换句话说,compareAndSetForkJoinTaskTag()允许我们将任务标记为VISITED。一旦标记为VISITED,则不执行。让我们在以下代码行中看到它:
public class Task extends RecursiveTask {
private static final Logger logger
= Logger.getLogger(Task.class.getName());
private static final short UNVISITED = 0;
private static final short VISITED = 1;
private Set> dependencies = new HashSet<>();
private final String name;
private final Callable callable;
public Task(String name, Callable callable,
Task ...dependencies) {
this.name = name;
this.callable = callable;
this.dependencies = Set.of(dependencies);
}
@Override
protected Integer compute() {
dependencies.stream()
.filter((task) -> (task.updateTaskAsVisited()))
.forEachOrdered((task) -> {
logger.info(() -> "Tagged: " + task + "("
+ task.getForkJoinTaskTag() + ")");
task.fork();
});
for (Task task: dependencies) {
task.join();
}
try {
return callable.call();
} catch (Exception ex) {
logger.severe(() -> "Exception: " + ex);
}
return null;
}
public boolean updateTaskAsVisited() {
return compareAndSetForkJoinTaskTag(UNVISITED, VISITED);
}
@Override
public String toString() {
return name + " | dependencies=" + dependencies + "}";
}
} 可能的输出如下:
[10:30:53] [INFO] Tagged: Task-B(1)
[10:30:53] [INFO] Tagged: Task-C(1)
[10:30:53] [INFO] Tagged: Task-A(1)
[10:30:53] [INFO] Adding number: 1
by thread:ForkJoinPool.commonPool-worker-3
[10:30:53] [INFO] Adding number: 2
by thread:ForkJoinPool.commonPool-worker-3
[10:30:53] [INFO] Adding number: 3
by thread:ForkJoinPool.commonPool-worker-5
[10:30:53] [INFO] Adding number: 4
by thread:main
[10:30:53] [INFO] Result: 10216 CompletableFuture
JDK8 通过用CompletableFuture增强Future,在异步编程领域迈出了重要的一步。Future的主要限制是:
- 它不能显式地完成。
- 它不支持对结果执行操作的回调。
- 它们不能链接或组合以获得复杂的异步管道。
- 它不提供异常处理。
CompletableFuture没有这些限制。一个简单但无用的CompletableFuture可以写如下:
CompletableFuture completableFuture
= new CompletableFuture<>(); 通过阻断get()方法可以得到结果:
completableFuture.get();除此之外,让我们看几个在电子商务平台上下文中运行异步任务的示例。我们将这些示例添加到名为CustomerAsyncs的助手类中。
运行异步任务并返回void
用户问题:打印某个客户订单。
因为打印是一个不需要返回结果的过程,所以这是一个针对runAsync()的作业。此方法可以异步运行任务,并且不返回结果。换句话说,它接受一个Runnable对象并返回CompletableFuture,如下代码所示:
public static void printOrder() {
CompletableFuture cfPrintOrder
= CompletableFuture.runAsync(new Runnable() {
@Override
public void run() {
logger.info(() -> "Order is printed by: "
+ Thread.currentThread().getName());
Thread.sleep(500);
}
});
cfPrintOrder.get(); // block until the order is printed
logger.info("Customer order was printed ...\n");
} 或者,我们可以用 Lambda 来写:
public static void printOrder() {
CompletableFuture cfPrintOrder
= CompletableFuture.runAsync(() -> {
logger.info(() -> "Order is printed by: "
+ Thread.currentThread().getName());
Thread.sleep(500);
});
cfPrintOrder.get(); // block until the order is printed
logger.info("Customer order was printed ...\n");
} 运行异步任务并返回结果
用户问题:获取某客户的订单汇总。
这一次,异步任务必须返回一个结果,因此runAsync()没有用处。这是supplyAsync()的工作。取Supplier返回CompletableFuture。T是通过get()方法从该供应器处获得的结果类型。在代码行中,我们可以如下解决此问题:
public static void fetchOrderSummary() {
CompletableFuture cfOrderSummary
= CompletableFuture.supplyAsync(() -> {
logger.info(() -> "Fetch order summary by: "
+ Thread.currentThread().getName());
Thread.sleep(500);
return "Order Summary #93443";
});
// wait for summary to be available, this is blocking
String summary = cfOrderSummary.get();
logger.info(() -> "Order summary: " + summary + "\n");
} 运行异步任务并通过显式线程池返回结果
用户问题:取某客户的订单摘要。
默认情况下,与前面的示例一样,异步任务在从全局ForkJoinPool.commonPool()获取的线程中执行。通过简单地记录Thread.currentThread().getName(),我们可以看到ForkJoinPool.commonPool-worker-3。
但是我们也可以使用显式的Executor自定义线程池。所有能够运行异步任务的CompletableFuture方法都提供了一种采用Executor的风格。
下面是使用单线程池的示例:
public static void fetchOrderSummaryExecutor() {
ExecutorService executor = Executors.newSingleThreadExecutor();
CompletableFuture cfOrderSummary
= CompletableFuture.supplyAsync(() -> {
logger.info(() -> "Fetch order summary by: "
+ Thread.currentThread().getName());
Thread.sleep(500);
return "Order Summary #91022";
}, executor);
// wait for summary to be available, this is blocking
String summary = cfOrderSummary.get();
logger.info(() -> "Order summary: " + summary + "\n");
executor.shutdownNow();
} 附加处理异步任务结果并返回结果的回调
用户问题:取某客户的订单发票,然后计算总金额并签字。
依赖阻塞get()对此类问题不是很有用。我们需要的是一个回调方法,当CompletableFuture的结果可用时,该方法将被自动调用。
所以,我们不想等待结果。当发票准备就绪时(这是CompletableFuture的结果),回调方法应该计算总值,然后,另一个回调应该对其签名。这可以通过thenApply()方法实现。
thenApply()方法可用于CompletableFuture结果到达时的处理和转换。它以Function为参数。让我们在工作中看看:
public static void fetchInvoiceTotalSign() {
CompletableFuture cfFetchInvoice
= CompletableFuture.supplyAsync(() -> {
logger.info(() -> "Fetch invoice by: "
+ Thread.currentThread().getName());
Thread.sleep(500);
return "Invoice #3344";
});
CompletableFuture cfTotalSign = cfFetchInvoice
.thenApply(o -> o + " Total: $145")
.thenApply(o -> o + " Signed");
String result = cfTotalSign.get();
logger.info(() -> "Invoice: " + result + "\n");
} 或者,我们可以将其链接如下:
public static void fetchInvoiceTotalSign() {
CompletableFuture cfTotalSign
= CompletableFuture.supplyAsync(() -> {
logger.info(() -> "Fetch invoice by: "
+ Thread.currentThread().getName());
Thread.sleep(500);
return "Invoice #3344";
}).thenApply(o -> o + " Total: $145")
.thenApply(o -> o + " Signed");
String result = cfTotalSign.get();
logger.info(() -> "Invoice: " + result + "\n");
} 同时检查applyToEither()和applyToEitherAsync()。当这个或另一个给定的阶段以正常方式完成时,这两个方法将返回一个新的完成阶段,并将结果作为提供函数的参数执行。
附加处理异步任务结果并返回void的回调
用户问题:取某客户订单打印。
通常,不返回结果的回调充当异步管道的终端操作。
这种行为可以通过thenAccept()方法获得。取Consumer返回CompletableFuture。此方法可以对CompletableFuture的结果进行处理和转换,但不返回结果。因此,它可以接受一个订单,它是CompletableFuture的结果,并按下面的代码片段打印出来:
public static void fetchAndPrintOrder() {
CompletableFuture cfFetchOrder
= CompletableFuture.supplyAsync(() -> {
logger.info(() -> "Fetch order by: "
+ Thread.currentThread().getName());
Thread.sleep(500);
return "Order #1024";
});
CompletableFuture cfPrintOrder = cfFetchOrder.thenAccept(
o -> logger.info(() -> "Printing order " + o +
" by: " + Thread.currentThread().getName()));
cfPrintOrder.get();
logger.info("Order was fetched and printed \n");
} 或者,它可以更紧凑,如下所示:
public static void fetchAndPrintOrder() {
CompletableFuture cfFetchAndPrintOrder
= CompletableFuture.supplyAsync(() -> {
logger.info(() -> "Fetch order by: "
+ Thread.currentThread().getName());
Thread.sleep(500);
return "Order #1024";
}).thenAccept(
o -> logger.info(() -> "Printing order " + o + " by: "
+ Thread.currentThread().getName()));
cfFetchAndPrintOrder.get();
logger.info("Order was fetched and printed \n");
} 同时检查acceptEither()和acceptEitherAsync()。
附加在异步任务之后运行并返回void的回调
用户问题:下订单通知客户。
通知客户应在交付订单后完成。这只是一条亲爱的客户,您的订单已经在今天送达之类的短信,所以通知任务不需要知道任何关于订单的信息。这类任务可以通过thenRun()来完成。此方法取Runnable,返回CompletableFuture。让我们在工作中看看:
public static void deliverOrderNotifyCustomer() {
CompletableFuture cfDeliverOrder
= CompletableFuture.runAsync(() -> {
logger.info(() -> "Order was delivered by: "
+ Thread.currentThread().getName());
Thread.sleep(500);
});
CompletableFuture cfNotifyCustomer
= cfDeliverOrder.thenRun(() -> logger.info(
() -> "Dear customer, your order has been delivered today by:"
+ Thread.currentThread().getName()));
cfNotifyCustomer.get();
logger.info(() -> "Order was delivered
and customer was notified \n");
} 为了进一步的并行化,thenApply()、thenAccept()和thenRun()伴随着thenApplyAsync()、thenAcceptAsync()和thenRunAsync()。其中每一个都可以依赖于全局ForkJoinPool.commonPool()或自定义线程池(Executor。当thenApply/Accept/Run()在与之前执行的CompletableFuture任务相同的线程中执行时(或在主线程中),可以在不同的线程中执行thenApplyAsync/AcceptAsync/RunAsync()(来自ForkJoinPool.commonPool()或自定义线程池(Executor)。
通过exceptionally()处理异步任务的异常
用户问题:计算订单总数。如果出了问题,就抛出IllegalStateException。
以下屏幕截图举例说明了异常是如何在异步管道中传播的;在某个点发生异常时,不会执行矩形中的代码:

以下截图显示了thenApply()和thenAccept()中的异常:

因此,在supplyAsync()中,如果发生异常,则不会调用以下回调。此外,Future将得到解决,但这一异常除外。相同的规则适用于每个回调。如果第一个thenApply()出现异常,则不调用以下thenApply()和thenAccept()。
如果我们试图计算订单总数的结果是一个IllegalStateException,那么我们可以依赖exceptionally()回调,这给了我们一个恢复的机会。此方法接受一个Function,并返回一个CompletionStage,因此返回一个CompletableFuture。让我们在工作中看看:
public static void fetchOrderTotalException() {
CompletableFuture cfTotalOrder
= CompletableFuture.supplyAsync(() -> {
logger.info(() -> "Compute total: "
+ Thread.currentThread().getName());
int surrogate = new Random().nextInt(1000);
if (surrogate < 500) {
throw new IllegalStateException(
"Invoice service is not responding");
}
return 1000;
}).exceptionally(ex -> {
logger.severe(() -> "Exception: " + ex
+ " Thread: " + Thread.currentThread().getName());
return 0;
});
int result = cfTotalOrder.get();
logger.info(() -> "Total: " + result + "\n");
} 异常情况下,输出如下:
Compute total: ForkJoinPool.commonPool-worker-3
Exception: java.lang.IllegalStateException: Invoice service
is not responding Thread: ForkJoinPool.commonPool-worker-3
Total: 0让我们看看另一个问题。
用户问题:取发票,计算合计,签字。如有问题,则抛出IllegalStateException,停止处理。
如果我们用supplyAsync()取发票,用thenApply()计算合计,用另一个thenApply()签字,那么我们可以认为正确的实现如下:
public static void fetchInvoiceTotalSignChainOfException()
throws InterruptedException, ExecutionException {
CompletableFuture cfFetchInvoice
= CompletableFuture.supplyAsync(() -> {
logger.info(() -> "Fetch invoice by: "
+ Thread.currentThread().getName());
int surrogate = new Random().nextInt(1000);
if (surrogate < 500) {
throw new IllegalStateException(
"Invoice service is not responding");
}
return "Invoice #3344";
}).exceptionally(ex -> {
logger.severe(() -> "Exception: " + ex
+ " Thread: " + Thread.currentThread().getName());
return "[Invoice-Exception]";
}).thenApply(o -> {
logger.info(() -> "Compute total by: "
+ Thread.currentThread().getName());
int surrogate = new Random().nextInt(1000);
if (surrogate < 500) {
throw new IllegalStateException(
"Total service is not responding");
}
return o + " Total: $145";
}).exceptionally(ex -> {
logger.severe(() -> "Exception: " + ex
+ " Thread: " + Thread.currentThread().getName());
return "[Total-Exception]";
}).thenApply(o -> {
logger.info(() -> "Sign invoice by: "
+ Thread.currentThread().getName());
int surrogate = new Random().nextInt(1000);
if (surrogate < 500) {
throw new IllegalStateException(
"Signing service is not responding");
}
return o + " Signed";
}).exceptionally(ex -> {
logger.severe(() -> "Exception: " + ex
+ " Thread: " + Thread.currentThread().getName());
return "[Sign-Exception]";
});
String result = cfFetchInvoice.get();
logger.info(() -> "Result: " + result + "\n");
} 好吧,这里的问题是,我们可能面临如下输出:
[INFO] Fetch invoice by: ForkJoinPool.commonPool-worker-3
[SEVERE] Exception: java.lang.IllegalStateException: Invoice service
is not responding Thread: ForkJoinPool.commonPool-worker-3
[INFO] Compute total by: ForkJoinPool.commonPool-worker-3
[INFO] Sign invoice by: ForkJoinPool.commonPool-worker-3
[SEVERE] Exception: java.lang.IllegalStateException: Signing service
is not responding Thread: ForkJoinPool.commonPool-worker-3
[INFO] Result: [Sign-Exception]即使发票拿不到,我们也会继续计算总数并签字。显然,这没有道理。如果无法提取发票,或者无法计算总额,则我们希望中止该过程。当我们可以恢复并继续时,这个实现可能是一个很好的选择,但它绝对不适合我们的场景。对于我们的场景,需要以下实现:
public static void fetchInvoiceTotalSignException()
throws InterruptedException, ExecutionException {
CompletableFuture cfFetchInvoice
= CompletableFuture.supplyAsync(() -> {
logger.info(() -> "Fetch invoice by: "
+ Thread.currentThread().getName());
int surrogate = new Random().nextInt(1000);
if (surrogate < 500) {
throw new IllegalStateException(
"Invoice service is not responding");
}
return "Invoice #3344";
}).thenApply(o -> {
logger.info(() -> "Compute total by: "
+ Thread.currentThread().getName());
int surrogate = new Random().nextInt(1000);
if (surrogate < 500) {
throw new IllegalStateException(
"Total service is not responding");
}
return o + " Total: $145";
}).thenApply(o -> {
logger.info(() -> "Sign invoice by: "
+ Thread.currentThread().getName());
int surrogate = new Random().nextInt(1000);
if (surrogate < 500) {
throw new IllegalStateException(
"Signing service is not responding");
}
return o + " Signed";
}).exceptionally(ex -> {
logger.severe(() -> "Exception: " + ex
+ " Thread: " + Thread.currentThread().getName());
return "[No-Invoice-Exception]";
});
String result = cfFetchInvoice.get();
logger.info(() -> "Result: " + result + "\n");
} 这一次,在任何隐含的CompletableFuture中发生的异常将停止该过程。以下是可能的输出:
[INFO ] Fetch invoice by: ForkJoinPool.commonPool-worker-3
[SEVERE] Exception: java.lang.IllegalStateException: Invoice service
is not responding Thread: ForkJoinPool.commonPool-worker-3
[INFO ] Result: [No-Invoice-Exception]从 JDK12 开始,异常情况可以通过exceptionallyAsync()进一步并行化,它可以使用与引起异常的代码相同的线程或给定线程池(Executor中的线程)。举个例子:
public static void fetchOrderTotalExceptionAsync() {
ExecutorService executor = Executors.newSingleThreadExecutor();
CompletableFuture totalOrder
= CompletableFuture.supplyAsync(() -> {
logger.info(() -> "Compute total by: "
+ Thread.currentThread().getName());
int surrogate = new Random().nextInt(1000);
if (surrogate < 500) {
throw new IllegalStateException(
"Computing service is not responding");
}
return 1000;
}).exceptionallyAsync(ex -> {
logger.severe(() -> "Exception: " + ex
+ " Thread: " + Thread.currentThread().getName());
return 0;
}, executor);
int result = totalOrder.get();
logger.info(() -> "Total: " + result + "\n");
executor.shutdownNow();
} 输出显示导致异常的代码是由名为ForkJoinPool.commonPool-worker-3的线程执行的,而异常代码是由给定线程池中名为pool-1-thread-1的线程执行的:
Compute total by: ForkJoinPool.commonPool-worker-3
Exception: java.lang.IllegalStateException: Computing service is
not responding Thread: pool-1-thread-1
Total: 0JDK12 exceptionallyCompose()
用户问题:通过打印服务获取打印机 IP 或回退到备份打印机 IP。或者,一般来说,当这个阶段异常完成时,应该使用应用于这个阶段异常的所提供函数的结果来合成。
我们有CompletableFuture获取打印服务管理的打印机的 IP。如果服务没有响应,则抛出如下异常:
CompletableFuture cfServicePrinterIp
= CompletableFuture.supplyAsync(() -> {
int surrogate = new Random().nextInt(1000);
if (surrogate < 500) {
throw new IllegalStateException(
"Printing service is not responding");
}
return "192.168.1.0";
}); 我们还有获取备份打印机 IP 的CompletableFuture:
CompletableFuture cfBackupPrinterIp
= CompletableFuture.supplyAsync(() -> {
return "192.192.192.192";
}); 现在,如果没有打印服务,那么我们应该依靠备份打印机。这可以通过 JDK12exceptionallyCompose()实现,如下所示:
CompletableFuture printInvoice
= cfServicePrinterIp.exceptionallyCompose(th -> {
logger.severe(() -> "Exception: " + th
+ " Thread: " + Thread.currentThread().getName());
return cfBackupPrinterIp;
}).thenAccept((ip) -> logger.info(() -> "Printing at: " + ip)); 调用printInvoice.get()可能会显示以下结果之一:
- 如果打印服务可用:
[INFO] Printing at: 192.168.1.0- 如果打印服务不可用:
[SEVERE] Exception: java.util.concurrent.CompletionException ...
[INFO] Printing at: 192.192.192.192对于进一步的并行化,我们可以依赖于exceptionallyComposeAsync()。
通过handle()处理异步任务的异常
用户问题:计算订单总数。如果出现问题,则抛出一个IllegalStateException。
有时我们希望执行一个异常代码块,即使没有发生异常。类似于try-catch块的finally子句。这可以使用handle()回调。无论是否发生异常,都会调用此方法,它类似于一个catch+finally。它使用一个函数来计算返回的CompletionStage, BiFunction的值并返回CompletionStage(U是函数的返回类型)。
让我们在工作中看看:
public static void fetchOrderTotalHandle() {
CompletableFuture totalOrder
= CompletableFuture.supplyAsync(() -> {
logger.info(() -> "Compute total by: "
+ Thread.currentThread().getName());
int surrogate = new Random().nextInt(1000);
if (surrogate < 500) {
throw new IllegalStateException(
"Computing service is not responding");
}
return 1000;
}).handle((res, ex) -> {
if (ex != null) {
logger.severe(() -> "Exception: " + ex
+ " Thread: " + Thread.currentThread().getName());
return 0;
}
if (res != null) {
int vat = res * 24 / 100;
res += vat;
}
return res;
});
int result = totalOrder.get();
logger.info(() -> "Total: " + result + "\n");
} 注意,res将是null;否则,如果发生异常,ex将是null。
如果我们需要在异常下完成,那么我们可以通过completeExceptionally()继续,如下例所示:
CompletableFuture cf = new CompletableFuture<>();
...
cf.completeExceptionally(new RuntimeException("Ops!"));
...
cf.get(); // ExecutionException : RuntimeException 取消执行并抛出CancellationException可以通过cancel()方法完成:
CompletableFuture cf = new CompletableFuture<>();
...
// is not important if the argument is set to true or false
cf.cancel(true/false);
...
cf.get(); // CancellationException 显式完成CompletableFuture
CompletableFuture可以使用complete(T value)、completeAsync(Supplier supplier)和completeAsync(Supplier supplier, Executor executor)显式完成。T是get()返回的值。这里是一个创建CompletableFuture并立即返回它的方法。另一个线程负责执行一些税务计算并用相应的结果完成CompletableFuture:
public static CompletableFuture taxes() {
CompletableFuture completableFuture
= new CompletableFuture<>();
new Thread(() -> {
int result = new Random().nextInt(100);
Thread.sleep(10);
completableFuture.complete(result);
}).start();
return completableFuture;
} 我们称这个方法为:
logger.info("Computing taxes ...");
CompletableFuture cfTaxes = CustomerAsyncs.taxes();
while (!cfTaxes.isDone()) {
logger.info("Still computing ...");
}
int result = cfTaxes.get();
logger.info(() -> "Result: " + result); 可能的输出如下:
[14:09:40] [INFO ] Computing taxes ...
[14:09:40] [INFO ] Still computing ...
[14:09:40] [INFO ] Still computing ...
...
[14:09:40] [INFO ] Still computing ...
[14:09:40] [INFO ] Result: 17如果我们已经知道了CompletableFuture的结果,那么我们可以调用completedFuture(U value),如下例所示:
CompletableFuture completableFuture
= CompletableFuture.completedFuture("How are you?");
String result = completableFuture.get();
logger.info(() -> "Result: " + result); // Result: How are you? 同时检查whenComplete()和whenCompleteAsync()的文件。
217 组合多个CompletableFuture实例
在大多数情况下,组合CompletableFuture实例可以使用以下方法完成:
thenCompose()thenCombine()allOf()anyOf()
通过结合CompletableFuture实例,我们可以形成复杂的异步解决方案。这样,多个CompletableFuture实例就可以合并它们的能力来达到一个共同的目标。
通过thenCompose()的组合
假设在名为CustomerAsyncs的助手类中有以下两个CompletableFuture实例:
private static CompletableFuture
fetchOrder(String customerId) {
return CompletableFuture.supplyAsync(() -> {
return "Order of " + customerId;
});
}
private static CompletableFuture computeTotal(String order) {
return CompletableFuture.supplyAsync(() -> {
return order.length() + new Random().nextInt(1000);
});
} 现在,我们要获取某个客户的订单,一旦订单可用,我们就要计算这个订单的总数。这意味着我们需要调用fetchOrder(),然后调用computeTotal()。我们可以通过thenApply()实现:
CompletableFuture> cfTotal
= fetchOrder(customerId).thenApply(o -> computeTotal(o));
int total = cfTotal.get().get(); 显然,这不是一个方便的解决方案,因为结果是CompletableFuture类型的。为了避免嵌套CompletableFuture实例,我们可以依赖thenCompose()如下:
CompletableFuture cfTotal
= fetchOrder(customerId).thenCompose(o -> computeTotal(o));
int total = cfTotal.get();
// e.g., Total: 734
logger.info(() -> "Total: " + total); 当我们需要从一系列的CompletableFuture实例中获得一个平坦的结果时,我们可以使用thenCompose()。这样我们就避免了嵌套的CompletableFuture实例。
使用thenComposeAsync()可以获得进一步的并行化。
通过thenCombine()的合并
thenCompose()用于链接两个依赖的CompletableFuture实例,thenCombine()用于链接两个独立的CompletableFuture实例。当两个CompletableFuture实例都完成时,我们可以继续。
假设我们有以下两个CompletableFuture实例:
private static CompletableFuture computeTotal(String order) {
return CompletableFuture.supplyAsync(() -> {
return order.length() + new Random().nextInt(1000);
});
}
private static CompletableFuture packProducts(String order) {
return CompletableFuture.supplyAsync(() -> {
return "Order: " + order
+ " | Product 1, Product 2, Product 3, ... ";
});
} 为了交付客户订单,我们需要计算总金额(用于发出发票),并打包订购的产品。这两个动作可以并行完成。最后,我们把包裹寄了,里面有订购的产品和发票。通过thenCombine()实现此目的,可如下:
CompletableFuture cfParcel = computeTotal(order)
.thenCombine(packProducts(order), (total, products) -> {
return "Parcel-[" + products + " Invoice: $" + total + "]";
});
String parcel = cfParcel.get();
// e.g. Delivering: Parcel-[Order: #332 | Product 1, Product 2,
// Product 3, ... Invoice: $314]
logger.info(() -> "Delivering: " + parcel); 给thenCombine()的回调函数将在两个CompletableFuture实例完成后调用。
如果我们只需要在两个CompletableFuture实例正常完成时做一些事情(这个和另一个),那么我们可以依赖thenAcceptBoth()。此方法返回一个新的CompletableFuture,将这两个结果作为所提供操作的参数来执行。这两个结果是此阶段和另一个给定阶段(它们必须正常完成)。下面是一个示例:
CompletableFuture voidResult = CompletableFuture
.supplyAsync(() -> "Pick")
.thenAcceptBoth(CompletableFuture.supplyAsync(() -> " me"),
(pick, me) -> System.out.println(pick + me)); 如果不需要这两个CompletableFuture实例的结果,则runAfterBoth()更为可取。
通过allOf()的组合
假设我们要下载以下发票列表:
List invoices = Arrays.asList("#2334", "#122", "#55"); 这可以看作是一堆可以并行完成的独立任务,所以我们可以使用CompletableFuture来完成,如下所示:
public static CompletableFuture
downloadInvoices(String invoice) {
return CompletableFuture.supplyAsync(() -> {
logger.info(() -> "Downloading invoice: " + invoice);
return "Downloaded invoice: " + invoice;
});
}
CompletableFuture [] cfInvoices = invoices.stream()
.map(CustomerAsyncs::downloadInvoices)
.toArray(CompletableFuture[]::new); 此时,我们有一个CompletableFuture实例数组,因此,还有一个异步计算数组。此外,我们希望并行运行它们。这可以通过allOf(CompletableFuture... cfs)方法实现。结果由一个CompletableFuture组成,如下所示:
CompletableFuture cfDownloaded
= CompletableFuture.allOf(cfInvoices);
cfDownloaded.get(); 显然,allOf()的结果不是很有用。我们能用CompletableFuture做什么?在这个并行化过程中,当我们需要每次计算的结果时,肯定会遇到很多问题,因此我们需要一个获取结果的解决方案,而不是依赖于CompletableFuture。
我们可以通过thenApply()来解决这个问题,如下所示:
List results = cfDownloaded.thenApply(e -> {
List downloaded = new ArrayList<>();
for (CompletableFuture cfInvoice: cfInvoices) {
downloaded.add(cfInvoice.join());
}
return downloaded;
}).get(); join()方法类似于get(),但是,如果基础CompletableFuture异常完成,则抛出非受检异常。
由于我们在所有相关CompletableFuture完成后调用join(),因此没有阻塞点。
返回的List包含调用downloadInvoices()方法得到的结果,如下所示:
Downloaded invoice: #2334
Downloaded invoice: #122
Downloaded invoice: #55通过anyOf()的组合
假设我们想为客户组织一次抽奖活动:
List customers = Arrays.asList(
"#1", "#4", "#2", "#7", "#6", "#5"
); 我们可以通过定义以下琐碎的方法开始解决这个问题:
public static CompletableFuture raffle(String customerId) {
return CompletableFuture.supplyAsync(() -> {
Thread.sleep(new Random().nextInt(5000));
return customerId;
});
} 现在,我们可以创建一个CompletableFuture实例数组,如下所示:
CompletableFuture[] cfCustomers = customers.stream()
.map(CustomerAsyncs::raffle)
.toArray(CompletableFuture[]::new); 为了找到抽奖的赢家,我们要并行运行cfCustomers,第一个完成的CompletableFuture就是赢家。因为raffle()方法阻塞随机数秒,所以将随机选择获胜者。我们对其余的CompletableFuture实例不感兴趣,所以应该在选出获胜者后立即完成。
这是anyOf(CompletableFuture... cfs)的工作。它返回一个新的CompletableFuture,当涉及的任何CompletableFuture实例完成时,这个新的CompletableFuture就完成了。让我们在工作中看看:
CompletableFuture