【数据结构】字典树TrieTree图文详解
问题引入
现在,我给你n个单词,然后进行q次询问,每一次询问一个单词b,问你b是否出现在n个单词中,你会如何去求呢?
暴力搜索?但是我们如果这么做的话时间复杂度一下就高上去了。大家都是成熟的ACMer了,不要再惦记着暴力的方法啦,要优雅。
你想想,问题的描述像不像查字典的操作?你平时是怎么查字典的?想想看?
如果你要在字典中查找单词“Avalon”,你是不是先找到首字母为‘A’的部分,然后再找第二个单词为‘V’的部分······最后,你可能可以找到这个单词,当然,也有可能这本词典并没有这个单词。
你想想看,你这样子的查单词的方式是不是比你从词典第一页开始查询到最后一页寻找单词“Avalon”要高效多了?那我们可不可以也建一本"字典"呢?
字典树介绍
概念:字典树(TrieTree),是一种树形结构,典型应用是用于统计,排序和保存大量的字符串(但不仅限于字符串,如01字典树)。主要思想是利用字符串的公共前缀来节约存储空间。很好地利用了串的公共前缀,节约了存储空间。字典树主要包含两种操作,插入和查找。
比如,我们要怎么用树存下单词"abc",“abb”,“bca”,"bc"呢?见图

在图中,红点代表有一个以此节点为终点的单词。然后,我们如果要查找某个单词如s=“abc”,就可以这样
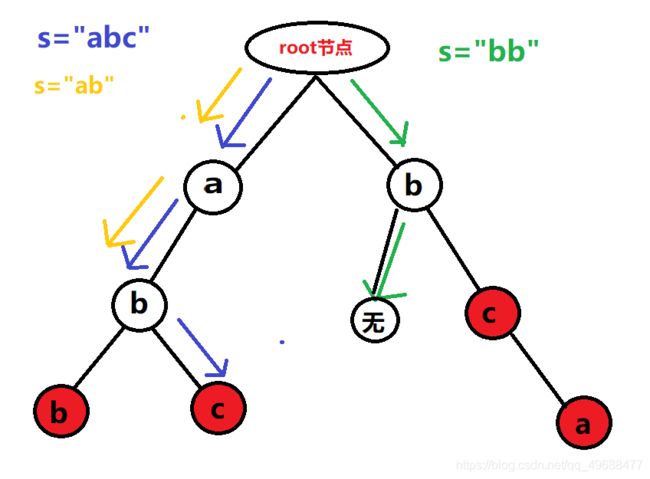
在这里,s=“abc” 的每一个字母都在树中被查到了,并且最后一个点是红色代表有一个在此结束的单词,查询成功。而 s=“bb” 的第二个字母没有在相应位置被查到,因此"bb"不在字典中。至于s=“ab” 虽然单词中每个点都被查到了,但是由于结尾的字母在树中没有标红,因此也是不在字典中。
对于字典树的每次查找,时间复杂度为log级别,比暴力快多了。
字典树代码实现方法
在用代码实现字典树时,我们主要需要实现两种操作:即录入单词和查找单词,这里我们用两个函数来实现,然后我们用一个二维数组来实现字典树的建树。先把代码写出来,之后再解释。
const int N = 1000050;
int trie[N][26];
int cnt[N];
int id;
void insert(string s)
{
int p = 0;
for (int i = 0; i < s.size(); i++)
{
int x = s[i] - 'a';
if (trie[p][x] == 0) trie[p][x] = ++id;
p = trie[p][x];
}
cnt[p]++;
}
int find(string s)
{
int p = 0;
for (int i = 0; i < s.size(); i++)
{
int x = s[i] - 'a';
if (trie[p][x] == 0)return 0;
p = trie[p][x];
}
return cnt[p];
}
这里我们用到了几个变量,这里分别一一解释
1.变量id: id代表字典树中每一个节点的编号,id的大小只与插入字典树的先后顺序有关,它的作用在下面会讲到。
2.trie[N][26]: 每个trie代表一条边,字典树其中1~N为边上方节点的编号,0代表root节点,1~26为连在i节点下方的26个字母。如果trie[i][x]=0,则代表字典树中目前没有这个点,而trie[i][x]的值代表这个点下方连有的点的编号,例如:trie[i][3]=9代表第i号点和的下方连有一个点‘c’,并且那个点的编号是9,为什么是c呢?因为 ‘c’-‘a’=3
3.cnt[N]: cnt[i]==0代表编号为i的点不是一个单词的结束点,在上面的图中代表这个点不是空点,但是没有标红,cnt[i]!=0代表编号为i的点是一个单词的结束点,即红点。cnt[i]不一定只为0或1,因为有可能多次输入了同一个单词。
4.(难点)两个函数中的变量p:
p代表查询与插入时的不断变化的当前节点编号,初始化为0,代表初始节点,在函数的循环中,我们首先用x确定接下来要找的字母,再通过变量x确定了接下来我们需要查找当前节点下是否有连接着目标字母的节点。通过每次确定的x,我们通过trie[p][x] 查找连着目标字母的节点的编号,如果目标节点存在,就把p更新成目标节点的编号(p = trie[p][x])。而如果trie[p][x] == 0,代表字典树中没有这个点,如果是查找就代表没有这个单词,查找失败。而如果是插入函数,我们就用 ++id 来把这个点存进字典树。我们在两个函数的最后用cnt[p]来涂红节点或返回节点值。
我们先后插入单词"abc",“abb”,“bca”,“bc”,那编号就是这样

trie[上节点编号][下方连接的字母]=下方连接的字母的节点编号
trie[0][0]=1;trie[0][1]=5;
trie[1][1]=2;
trie[2][1]=4;trie[2][2]=3;
trie[5][2]=6;
trie[6][0]=7;
其余trie[i][j]都为0,即空节点;
cnt[4]=cnt[3]=cnt[6]=cnt[7]=1;
如果我再往字典树中插入"bcd",字典树就更新为

新增
trie[6][3]=8;cnt[8]=1
让我们试着查询看看"abc"与"bb"
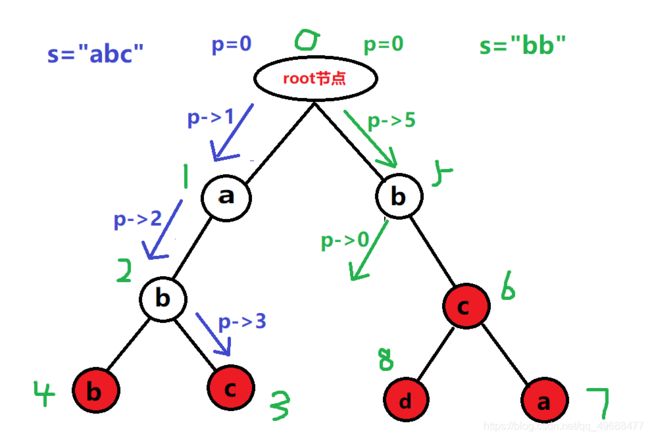
最后,我们查到了"abc",但没查到"bb"
那么字典树到这里就介绍完毕啦。
作者:Avalon Demerzel,喜欢我的博客就点个赞吧,更多图论与数据结构知识点请见作者专栏《图论与数据结构》