【机器学习】从电影数据集到推荐系统
作者 | Amine Zaamoun
编译 | VK
来源 | Towards Data Science
最初是一个数据集,现在是一个由Amine Zaamoun开发的电影推荐系统:

为什么是推荐系统?
你们可能曾经花上几分钟甚至几个小时去选择一部电影单独看或者和家人一起看,不幸的是没有成功?你希望有人在这种时候替你做决定,这正是推荐系统的作用。
推荐系统是网易和亚马逊巨头目前取得成功的主要原因之一。我设计这篇文章是为了向你展示,任何在数据科学和编程方面有一点创造力和经验的人,都可以通过遵循我将要描述的几个步骤来实现他们自己的推荐系统。
我在德国电信公司(DEUTSCHE TELEKOM AG)数据科学创新中心(IHUB)8个月的实习期间实现了这个项目。我们的想法也是把重点放在实践方面,而不是放在理论和数学方面,你可以在互联网上找到科学文献。
系统概述和体系结构

本文介绍的推荐系统分四个主要步骤实现:
第1步:计算每部电影的加权平均分,以便向最终用户推荐最受欢迎的100部电影的目录
第2步:使用机器学习算法建立5部“流行”电影的推荐:使用Scikit learn的k近邻(kNN)
第3步:建立5部由深度学习算法推荐的“鲜为人知”电影的推荐:使用Tensorflow和Keras的深度神经矩阵分解(DNMF)实现
第4步:使用来自Flask(python web开发框架)部署最终系统
我们使用的数据集中,用户对他们看过的电影进行了评分。
协同过滤方法
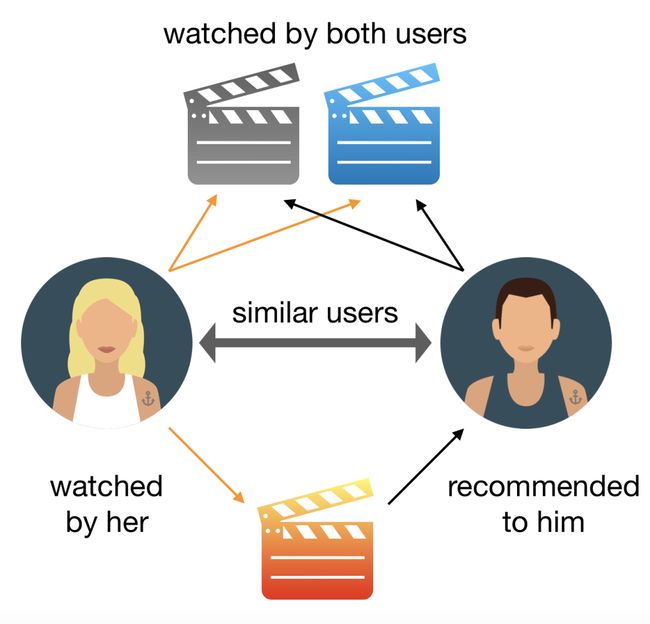
这种方法可以基于用户过去的行为和其他用户做出的类似决策来构建模型。
事实上,它是基于在数据集中选择的电影和这些电影的评分。然后,通过预测这些电影的收视率,使用该模型来预测用户可能感兴趣的电影。
MovieLens’ ratings.csv 数据集
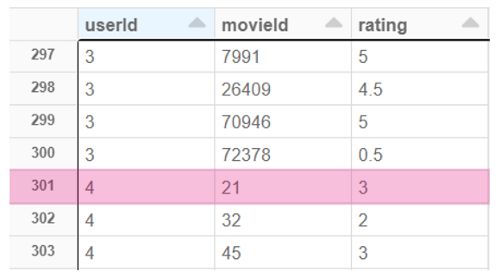
这个数据集中突出显示的一行内容如下:4号用户观看了21号电影,并将其评分为3.0/5.0。
有关此数据集的所有信息可以直接从以下链接:https://grouplens.org/datasets/movielens/latest/的README.html得到
“这个数据集[1](ml-latest-small)描述了电影推荐服务MovieLens的评分(满分5分)和文本信息。它包含100836个收视率和3683个标签,涵盖9742部电影。这些数据由610名用户在1996年3月29日至2018年9月24日期间创建。该数据集于2018年9月26日生成。
用户是随机选择的。所有选定的用户都对至少20部电影进行了评分。不包括人口统计信息。每个用户都由一个id表示,不提供其他信息。”
另外请注意,对于本文介绍的推荐系统,只使用了电影的评分,而没有使用标签。
第1步:计算每部电影的加权平均分
这第一步的目标是为我们推荐系统的最终用户提供一个流行电影的目录,他们可以从中选择自己喜欢的电影。
代码本身是非常不言自明的,唯一值得注意的元素是使用PySpark来执行此计算。
实际上,这个库允许使用SQL语言固有的“mean”和“col”函数,从而促进代码的组织和可读性。然而,同样的计算在pandas库也是完全可行的,因为pandas库在数据科学初学者中更受欢迎。
我们电影推荐系统实现的第一步代码
import os
from pyspark.sql.functions import mean, col
"""路径设置"""
data_path = os.environ['DATA_PATH']
movies_datapath = os.path.join(data_path, 'Movies/MovieLens/movies_data-100k')
trained_datapath = os.path.join(movies_datapath, 'Already_Trained')
"""加载数据集"""
ratings = spark.read.load(os.path.join(movies_datapath, 'ratings.csv'), format='csv', header=True, inferSchema=True).drop("timestamp")
movies = spark.read.load(os.path.join(movies_datapath, 'movies.csv'), format='csv', header=True, inferSchema=True)
"""计算每部电影的平均评分和评分数量"""
df = ratings.join(movies, on="movieId")
number_ratings = df.groupBy('movieId').count()
average_ratings = df.groupBy('movieId').avg('rating')
df_ratings = average_ratings.join(number_ratings, on="movieId")
df = df.join(df_ratings, on="movieId")
mostRatedMovies = df.where("count >= 50")
"""计算每部电影的加权平均分"""
# 我们必须将'vote_count'列从字符串类型转换为double类型(数值型),以便计算分位数
changedTypedf = mostRatedMovies.withColumn("vote_count", df["count"].cast("double"))
quantile_df = changedTypedf.approxQuantile("count", [0.75], 0)
m = quantile_df[0]
# collect()用于在驱动程序中以数组的形式返回数据集的所有元素。
mean_df = mostRatedMovies.select(mean(col('avg(rating)')).alias('mean')).collect()
C = mean_df[0]['mean']
movies_cleaned_df = mostRatedMovies.withColumn("weighted_average", ((mostRatedMovies['avg(rating)']*mostRatedMovies['count']) + (C*m)) / (mostRatedMovies['count']+m))
"""将表保存到CSV文件中以供以后访问"""
movies_cleaned_pd.to_csv(os.path.join(trained_datapath, 'MostPopularMovies.csv'), index=False)
第2步:使用k近邻(kNN)设置5部“流行”电影的推荐
第2步的目标是向最终用户推荐一系列可以称为“流行”的电影。
首先,它帮助用户放心,因为他至少会认出推荐的电影之一。事实上,如果他不认识任何推荐的电影,他可能会拒绝我们系统的有用性。不幸的是,这一心理和人的因素是无法量化的。这也证明,如果不考虑文化方面,最好的数学和统计模型可能不适合一些用户。
其次,使用kNN算法推荐的电影都是“流行”的,这是在训练机器学习模型之前对数据进行预先过滤的直接结果。
事实上,我们数据集中的评估频率遵循“长尾”分布。这意味着大多数电影的收视率非常低,而“少数压倒性”的收视率远远高于其他电影的总和。因此,这个过滤器只允许使用最流行的电影来训练kNN算法,因此得到的推荐也只能是流行电影。
该算法还具有易于理解和解释的优点。对于非技术人员来说尤其如此,比如你公司的销售团队,或者仅仅是你的朋友和家人,他们不一定对数据科学十分理解。
Kevin Liao在文章中所解释的:“当KNN对一部电影进行推断时,KNN将计算目标电影与其数据库中其他每部电影之间的‘距离’,然后对其距离进行排序,并返回前K个最近邻居电影作为最相似的电影推荐”。
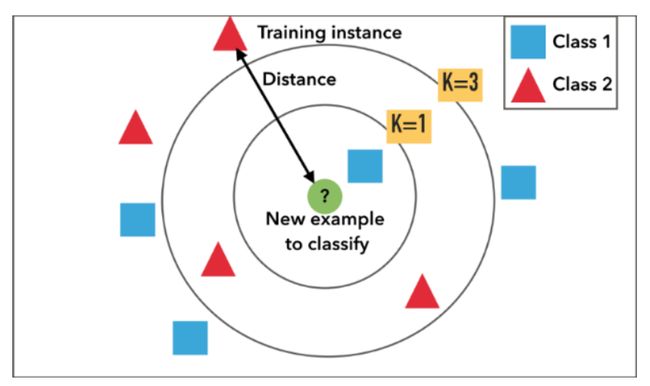

正如你在本例中所看到的,与“钢铁侠(2008)”最接近的电影是“黑暗骑士(2008)”,其余弦相似性(或简称“距离”)约为0.33。
这个结果,从主观和个人的角度来看,似乎非常连贯的意义上说,他们是两个超级英雄电影。我们还可以注意到《阿凡达(2009)》和《盗梦空间(2010)》这两部科幻电影的出现。
我感谢有必要注意到机器学习算法的魔力,因为正如我提醒你的那样,只使用了1.0到5.0的评分。事实上,这些电影的类型并没有被用来提供这些建议。
下面是相关的代码片段,向你展示如何使用Scikit学习库实现此算法,并根据选定的电影标题获取建议
我们的电影推荐系统实现的第2步中的kNN算法片段:
from scipy.sparse import csr_matrix
from sklearn.neighbors import NearestNeighbors
import numpy as np
import pandas as pd
"""创建透视表"""
movies_pivot = mostRatedMovies.groupBy('title').pivot('userId').sum('rating').fillna(0)
movie_features_df = movies_pivot.toPandas().set_index('title')
movie_features_df_matrix = csr_matrix(movie_features_df.values)
"""使用整个数据集拟合最终的无监督模型,以找到每一个最相似的电影"""
model_knn = NearestNeighbors(metric='cosine', algorithm='brute', n_neighbors=11, n_jobs=-1)
model_knn.fit(movie_features_df_matrix)
# 选择一个标题
favoriteMovie = 'Iron Man (2008)'
query_index = movie_features_df.index.get_loc(favoriteMovie)
distances, indices = model_knn.kneighbors(movie_features_df.loc[favoriteMovie,:].values.reshape(1, -1), n_neighbors=11)
# 根据kNN模型打印10部最相似的电影
for i in range(0, len(distances.flatten())):
if i == 0:
print('Recommendations for {0}:\n'.format(movie_features_df.index[query_index]))
else:
print('{0}: {1}, with distance of {2}:'.format(i, movie_features_df.index[indices.flatten()[i]], distances.flatten()[i]))
第3步:使用深层神经矩阵分解(DNMF)建立5部“鲜为人知”电影的推荐
第3步的目的和该算法的选择是向最终用户推荐一系列往往“鲜为人知”的电影。
不需要过多的细节,只需要记住,不需要预先过滤,而且电影可以用作训练数据,而不管它的受欢迎程度如何。
实际上,这个算法在数学上非常复杂,它结合了数据科学中常用的两个模型。第一个模型是矩阵分解,例如,交替最小二乘(ALS)算法。另一个模型是深层神经网络的一个例子,例如多层感知器(MLP)。
写一整篇文章来正确地解释它必要的,但正如我之前已经宣布,目标是是偏向于实现。因此,我让你阅读这两篇已经很好地解释了这些概念的参考资料:(https://towardsdatascience.com/prototyping-a-recommender-system-step-by-step-part-2-alternating-least-square-als-matrix-4a76c58714a1;https://towardsdatascience.com/building-a-deep-learning-model-using-keras-1548ca149d37)
第3步中使用的深层神经矩阵分解算法(DNMF)具有以下体系结构:
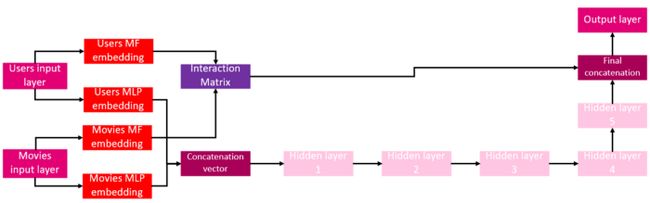
该算法的原理与经典的矩阵分解相同。使用这个模型,我们试图预测某个用户对某部电影的评价。我指定了“他会给出”的评分,因为这个算法填充了当前数据存在的空白值。
让我解释一下:即使是一个大影迷也可能没有看过或评价过我们数据集中的所有9742部电影。这样一来,他就可以给自己还没有打分的电影打分,以此来决定自己是否喜欢这些电影。这正是我们算法的矩阵分解部分所做的。
神经网络的加入使得进一步提高模型的预测性能成为可能,从而减少预测和实际评分之间的误差。下面是一个代码片段,向你展示如何使用Tensorflow和Keras库实现这样的模型。我们将使用它来预测与一对不存在的(userId,movieId)的评分。
我们的电影推荐系统实现的第三步中的DNMF算法片段
import numpy as np
import pandas as pd
from tensorflow import keras
"""计算不同userid和movieid的数量,创建输入用户和电影向量和潜在因子的数量"""
n_users = len(df_ratings_reduced["userId"].unique())
n_movies = len(df_ratings_reduced["movieId"].unique())
userIds_vector = np.asarray(df_ratings.userId).astype(np.int32)
movieIds_vector = np.asarray(df_ratings.movieId).astype(np.int32)
n_latent_factors = 20
"""实现模型架构,并使其拟合到输入用户和电影向量"""
# 用户矩阵分解和多层感知机嵌入路径
users_input = keras.layers.Input(shape=[1], dtype='int32', name="users_input")
users_mf_embedding = keras.layers.Embedding(input_dim=n_users + 1, output_dim=n_latent_factors, name='users_mf_embedding')
users_flattened_mf = keras.layers.Flatten()(users_mf_embedding(users_input))
users_mlp_embedding = keras.layers.Embedding(input_dim=n_users + 1, output_dim=n_latent_factors, name='users_mlp_embedding')
users_flattened_mlp = keras.layers.Flatten()(users_mlp_embedding(users_input))
# 矩阵分解和多层感知机嵌入路径
movies_input = keras.layers.Input(shape=[1], dtype='int32', name="movies_input")
movies_mf_embedding = keras.layers.Embedding(input_dim=n_movies + 1, output_dim=n_latent_factors, name='movies_mf_embedding')
movies_flattened_mf = keras.layers.Flatten()(movies_mf_embedding(movies_input))
movies_mlp_embedding = keras.layers.Embedding(input_dim=n_movies + 1, output_dim=n_latent_factors, name='movies_mlp_embedding')
movies_flattened_mlp = keras.layers.Flatten()(movies_mlp_embedding(movies_input))
# 用户与电影的点积矩阵分解嵌入和连接用户与电影的多层感知机嵌入
interaction_matrix = keras.layers.Dot(name="interaction_matrix", axes=1)([movies_flattened_mf, users_flattened_mf])
concatenation_vector = keras.layers.Concatenate(name="concatenation_vector")([movies_flattened_mlp, users_flattened_mlp])
# 添加全连接层,矩阵分解和多层感知机部分的连接和输出层
dense_1 = keras.layers.Dense(50, activation='elu', kernel_initializer="he_normal")(concatenation_vector)
dense_2 = keras.layers.Dense(25, activation='elu', kernel_initializer="he_normal")(dense_1)
dense_3 = keras.layers.Dense(12, activation='elu', kernel_initializer="he_normal")(dense_2)
dense_4 = keras.layers.Dense(6, activation='elu', kernel_initializer="he_normal")(dense_3)
dense_5 = keras.layers.Dense(3, activation='elu', kernel_initializer="he_normal")(dense_4)
final_concatenation = keras.layers.Concatenate(name="final_concatenation")([interaction_matrix, dense_5])
output_layer = keras.layers.Dense(1)(final_concatenation)
# 拼接输入输出,编译模型
dnmf_model_final = keras.models.Model(inputs=[users_input, movies_input], outputs=output_layer)
dnmf_model_final.compile(loss="mean_squared_error", optimizer=keras.optimizers.SGD(lr=0.01, momentum=0.9, nesterov=True, clipvalue=1.0), metrics=[keras.metrics.RootMeanSquaredError()])
# 拟合模型
history = dnmf_model_final.fit([userIds_vector, movieIds_vector], ratings_vector, epochs=100)
"""生成与尚未存在的(userId, movieId)的预测评分,将用于进一步的推荐"""
# 选择一个不存在于ratings.csv文件中的(userId, movieId)对,例如(1,10)
userIdChosed_vector = np.asarray([1]).astype(np.int32)
movieIdChosed_vector = np.asarray([10]).astype(np.int32)
# 根据DNMF模型预测userid_chosen将给movieid_chosen的评分
predicted_rating = dnmf_model_final.predict([userIdChosed_vector, movieIdChosed_vector])
print(predicted_rating)
现在,我们可以按照同样的逻辑来预测我们数据库中所有尚未存在的(userId,movieId)。以用户401为例,通过DNMF算法计算出前10位如下:

现在,我们可以将使用此模型生成的两个表的结果保存在两个不同的csv文件中:为每个电影推荐的前10个用户和为每个用户推荐的前10个电影。
pdUserRecs.to_csv(os.path.join(trained_datapath, 'DNMF_MovieRecommendationsForAllUsers.csv'), index=False)
pdMovieRecs.to_csv(os.path.join(trained_datapath, 'DNMF_UserRecommendationsForAllMovies.csv'), index=False)
第4步:使用Flask部署最终系统
我们终于到了最后一步,这一步需要对web开发略知一二。
将系统作为一个真正的应用程序进行适当的部署将非常有用。在这个web应用程序中,我们将链接本文前面步骤中完成的所有工作。
实际上,用户将从100部最受欢迎电影的目录中选择3部电影开始,并且这些电影是根据第一步中这些电影的加权平均分计算出来的。
这3部电影将作为我们的2个模型的输入数据,以获得10部电影的最终推荐,其中5部来自kNN,5部来自DNMF。
此外,为了给最终用户提供快速而流畅的体验,已经预先计算了DNMF模型将给出的预测。
这意味着对于选中的3部电影中的每一部,系统都会在“DNMF_UserRecommendationsForAllMovies”中进行搜索。根据预测得分“匹配”5个用户:

然后,系统将使用此匹配的用户列表重复与前面相同的过程。
换言之,它将在另一个列表中添加每个用户最喜爱的5部电影,其中5部将使用另一个表保存在最后。
这允许我们基于类似的用户配置文件向用户提供电影推荐。另一个非常重要的一点是,这些建议已经快速和准确地给出,而不必等待数小时的模型进行重新训练,因此预先计算DNMF结果十分有用。
@app.route('/recommended_movies', methods=['POST'])
def make_recommendations():
finalRecommendations = []
popular_movies_list = show_popular_movies(mostPopularMovies)
favorite_movieTitles = request.form.getlist('cb')
favorite_ids = get_movieIds(movies, favorite_movieTitles)
popular_movieIds_list = get_movieIds(movies, popular_movies_list)
# 对于用户选择的每一部最喜欢的电影,将他们最近的10部电影添加到kNN_recommendations列表中,随机保留5部
kNN_recommendations = []
for i in range(3):
userMovie = favorite_movieTitles[i]
query_index = kNNmovieMatrix.index.get_loc(userMovie)
distances, indices = loaded_kNN_model.kneighbors(kNNmovieMatrix.iloc[query_index,:].values.reshape(1, -1), n_neighbors = 11)
for j in range(1, len(distances.flatten())):
movieTitle = kNNmovieMatrix.index[indices.flatten()[j]]
distance = distances.flatten()[j]
if (movieTitle not in popular_movies_list) and (movieTitle not in kNN_recommendations) and (movieTitle not in favorite_movieTitles):
kNN_recommendations.append(movieTitle)
final_kNN_recommendations = random.sample(kNN_recommendations, 5)
kNN_recommendedIds = get_movieIds(movies, final_kNN_recommendations)
# 对于用户选择的每个最喜欢的电影,将他们推荐的前5个用户添加到DNMF_usersRecommendation列表中
DNMF_usersRecommendation = []
for i in range(3):
movieChosed = favorite_ids[i]
for j in range(5):
userRecommended = pdMovieRecs[pdMovieRecs.movieId == movieChosed]["userRecommendations"].iloc[0][j]
predictedMatch = pdMovieRecs[pdMovieRecs.movieId == movieChosed]["userRatings"].iloc[0][j]
if (userRecommended not in DNMF_usersRecommendation):
DNMF_usersRecommendation.append(userRecommended)
# 对于模型推荐的每个用户,将他们推荐的前5部电影添加到DNMF_moviesRecommendation列表中,并随机保留5部
DNMF_moviesRecommendation = []
for i in range(len(DNMF_usersRecommendation)):
userChosed = DNMF_usersRecommendation[i]
for j in range(5):
movieRecommended = pdUserRecs[pdUserRecs.userId == userChosed]["movieRecommendations"].iloc[0][j]
predictedRating = pdUserRecs[pdUserRecs.userId == userChosed]["movieRatings"].iloc[0][j]
if (movieRecommended not in DNMF_moviesRecommendation) and (movieRecommended not in kNN_recommendedIds) and (movieRecommended not in favorite_ids) and (movieRecommended not in popular_movieIds_list):
DNMF_moviesRecommendation.append(movieRecommended)
final_DNMF_recommendations = random.sample(DNMF_moviesRecommendation, 5)
recommendedMovieTitles = get_movieTitles(movies, final_DNMF_recommendations)
# 加入两个列表,以便从kNN模型给出5部电影推荐和从DNMF模型给出5部电影推荐
finalRecommendations = final_kNN_recommendations + recommendedMovieTitles
recommendedMoviePosters = get_moviePosters(movies, finalRecommendations)
return render_template('index.html',
choose_message="Here is a list of the most popular movies in our database, please choose 3 :",
favorite_movies_message="Your 3 favorite movies are :",
favorite_movies_list=favorite_movieTitles,
recommendations_message="We recommend you the following movies :",
recommendations_list=finalRecommendations,
recommendations_posters=recommendedMoviePosters)
正如你所注意到的,当用户选择了他的3部电影并按下按钮以获得他的推荐时,POST请求被发送到服务器。处理此请求时,呈现的函数将返回几个与“模板”关联的变量。下面是如何在index.html读取变量:
{{ favorite_movies_message}}
{% for favorite_movie in favorite_movies_list %}
- {{ favorite_movie }}
{% endfor %}
{{ recommendations_message }}
{% if (recommendations_list is defined) and (recommendations_posters is defined) %}
{{ recommendations_list[0] }}
{{ recommendations_list[1] }}
{{ recommendations_list[2] }}
{{ recommendations_list[3] }}
{{ recommendations_list[4] }}
{{ recommendations_list[5] }}
{{ recommendations_list[6] }}
{{ recommendations_list[7] }}
{{ recommendations_list[8] }}
{{ recommendations_list[9] }}
{% endif %}
以下是最终结果:

就这样!你现在可以尝试实现你自己的系统版本了。
总结
在本文中,我们共同了解了如何使用Python编程语言将一个简单的数据集转换为一个真正的电影推荐系统,并将其部署为一个web应用程序。
我们还了解到,推荐系统通常基于不同的互连算法。这对于为每种类型的产品(无论是“流行的”还是“鲜为人知的”)提供建议确实很有用。
我尽我所能以一种更实际而非理论的方式来表达这个话题,这样任何人都能理解我在说什么,希望你喜欢。源代码可以在我的GitHub找到:https://github.com/Zaamine/Movie_Recommender_System-Python
参考引用
[1] F. Maxwell Harper and Joseph A. Konstan. The MovieLens Datasets: History and Context (2015), ACM Transactions on Interactive Intelligent Systems (TiiS) 5, 4: 19:1–19:19.

往期精彩回顾
适合初学者入门人工智能的路线及资料下载机器学习及深度学习笔记等资料打印机器学习在线手册深度学习笔记专辑《统计学习方法》的代码复现专辑
AI基础下载机器学习的数学基础专辑温州大学《机器学习课程》视频
本站qq群851320808,加入微信群请扫码: