Python机器学习实战教学——基于协同过滤的电影推荐系统(超详细教学,算法分析)
- 注重版权,转载请注明原作者和原文链接
- 作者:Yuan-Programmer
结尾处有效果展示
文章目录
-
- 引言
- 一、技术原理
-
-
- (一)推荐算法介绍
- (二)主流距离计算法
- (三)余弦距离计算法
-
- 二、数据介绍
-
-
- (一)数据来源
- (二)数据展示
-
- 三、数据预处理
-
-
- (一)分离数据
- (二)预处理代码
-
- 四、Neo4j图形数据库
-
-
- (一)介绍
- (二)展示
-
- 五、创建实体图和关系图
-
-
- (一)原理
- (二)代码
-
- 六、搭建推荐系统
-
-
- (一)原理
- (二)代码
-
- 七、结果演示
引言
推荐系统的兴起与互联网的发展息息相关。最早的自动化协同过滤系统可以追溯到1994年,明尼苏达大学双城分校计算机系的GroupLens研究组设计了名为GroupLens 的新闻推荐系统。该工作不仅首次提出了协同过滤的思想,并且为推荐问题建立了一个形式化的模型,为随后几十年推荐系统的发展带来了巨大影响。该研究组后来创建了MovieLens推荐网站,一个推荐引擎的学术研究平台,其包含的数据集是迄今为止推荐领域引用量最大的数据集。
一、技术原理
(一)推荐算法介绍
当今最流行的推荐算法有五个,分别如下
- (1)基于流行度的算法
基于流行度的算法非常简单粗暴,类似于各大新闻、微博热榜等,根据PV、UV、日均PV或分享率等数据来按某种热度排序来推荐给用户
- (2)基于协同过滤的算法
协同过滤算法(Collaborative Filtering, CF)是很常用的一种算法,在很多电商网站上都有用到。CF算法包括基于用户的CF(User-based CF)和基于物品的CF(Item-based CF)
- (3)基于内容的推荐
基于内容的推荐算法 (Content-BasedRecommendations) 是基于标的物相关信息、用户相关信息及用户对标的物的操作行为来构建推荐算法模型,为用户提供推荐服务
- (4)基于模型的推荐
基于模型的方法使用一些机器学习算法来对物品的向量(针对—个特定的用户)来训练,然后建立模型来预测用户对于新的物品的得分。流行的基于模型的技术是贝叶斯网络、奇异值分解和隐含概率语义分析
- (5)混合算法
机器学习中有所谓的集 成学习(EnsembleLearning),广泛应用于分类和回归问题,本质上是利用多个分类或者回归算法,通过这些算法的有效整合获得更好的分类或者预测双果。通过不同的算法组合可以有效地降低系统性误差(方差)
(二)主流距离计算法
本次推荐系统采用的是协同过滤的方法,计算用户相似度是必不可少的,我们通过计算距离来决定用户之间的相似度高低,当今主流的距离计算法有六个,如下
- (1)欧式距离计算法
- (2)曼哈顿距离计算法
- (3)切比雪夫距离计算法
- (4)余弦距离计算法
- (5)皮尔森系数计算法
- (6)杰夫德距离计算法
这里我就不一一介绍每个距离计算法的原理了,我只介绍本次有用到的余弦距离计算法,其他有想了解的伙伴可以网上找找资料,有很多介绍的
(三)余弦距离计算法
余弦距离,也称为余弦相似度,是用向量空间中两个向量夹角的余弦值作为衡量两个个体间差异的大小的度量。
余弦值越接近1,就表明夹角越接近0度,也就是两个向量越相似,这就叫"余弦相似性"。

上图两个向量a,b的夹角很小可以说a向量和b向量有很高的的相似性,极端情况下,a和b向量完全重合。如下图:

余弦公式

在向量表示的三角形中,假设a向量是(x1, y1),b向量是(x2, y2),那么可以将余弦定理改写成下面的形式:
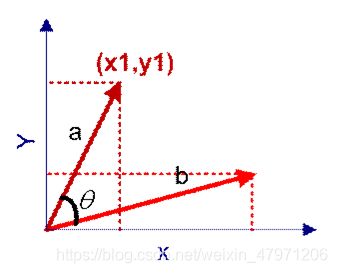

我们转换为多维就能得到如下公式

技术原理讲完了,就正式开始讲解代码了
二、数据介绍
(一)数据来源
本次项目所有的数据均来源于 Kaggle平台 https://www.kaggle.com/
用到的有三个数据集,如下
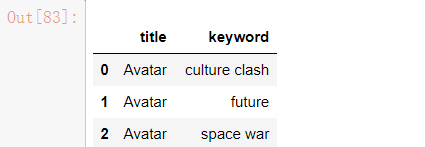
tmdb_5000_movies.csv 电影数据集,来源 https://www.kaggle.com/tmdb/tmdb-movie-metadata
movie_titles.csv 电影属性集,来源 https://www.kaggle.com/netflix-inc/netflix-prize-data?select=movie_titles.csv
combined_data_1.txt 用户电影评分数据集,来源 https://www.kaggle.com/netflix-inc/netflix-prize-data?select=combined_data_1.txt
(二)数据展示
-
tmdb_5000_movies.csv 电影数据集
有电影的编号、类型、导演、公司、关键词······

-
movie_titles.csv 电影属性集
有电影的年份和电影名

- combined_data_1.txt 用户电影评分数据集

三、数据预处理
在上述中我们可以看到非常多的数据,但不是所有的数据我们都用的到,只需要把我们所需要的数据分离出来。同时多种数据不统一,我们需要规划到一起,这就是预处理操作
(一)分离数据
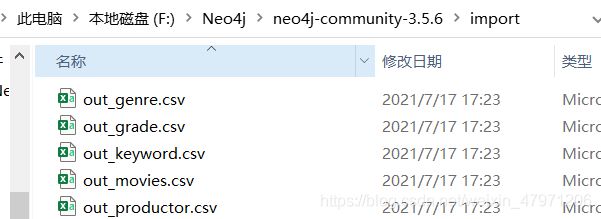
我们一共分离出五个数据集,分别如下
-
out_genre.csv 电影类型数据集
-

-
out_grade.csv 用户评分数据集

-
out_keyword.csv 电影关键词数据集
-
out_movies.csv 电影名称数据集

-
out_productor.csv 电影制作方数据集

(二)预处理代码
import pandas as pd
import json
import re
def Netflix():
print("Loading Netflix-data...")
print()
MAX_USER = 1000 # 读取一千个用户
d_movie = dict() #字典集
s_movie = set() #集合(无序不重复)
#====================================================================================== 生成 movies.csv数据集(电影名称)
out_movies = open("handle-data/out_movies.csv","w")
out_movies.write("title\n")
for line in open("base-data/movie_titles.csv","r",encoding = 'ISO-8859-1'):
line = line.strip().split(',') #通过“,”字符进行切割
movie_id = int(line[0])
title = line[2].replace("\"","") #将“\”字符去掉
title = "\"" + title + "\""
d_movie[movie_id] = title
if title in s_movie:
continue
s_movie.add(title)
out_movies.write(f"{title}\n") #读入数据
print("out_movies.csv Create Success...")
out_movies.close() #关闭
#====================================================================================== 生成 grade数据集(评分)
out_grade = open("handle-data/out_grade.csv","w")
out_grade.write("user_id,title,grade\n")
files = ["base-data/combined_data_1.txt"]
for f in files:
movie_id = -1
for line in open(f,"r"):
pos = line.find(":")
if pos != -1:
movie_id = int(line[:pos])
continue
line = line.strip().split(",")
user_id = int(line[0]) #用户编号
rating = int(line[1]) #评分
if user_id > MAX_USER: #获取1000个用户(看自己需求)
continue
out_grade.write(f"{user_id},{d_movie[movie_id]},{rating}\n")
print("out_greade.csv Create Success...")
out_grade.close()
#=======================================================================================================
"""
genre.csv数据集(电影类型)
keyword.csv数据集(电影关键词)
productor.csv数据集(电影导演及公司)
"""
def TMDB():
print("Loading TMDB-data...")
print()
#============================================================== 写入表格列名标题
pattern = re.compile("[A-Za-z0-9]+")
out_genre = open("handle-data/out_genre.csv","w",encoding="utf-8")
out_genre.write("title,genre\n")
out_keyword = open("handle-data/out_keyword.csv","w",encoding="utf-8")
out_keyword.write("title,keyword\n")
out_productor = open("handle-data/out_productor.csv","w",encoding="utf-8")
out_productor.write("title,productor\n")
#============================================================== 读入数据
df = pd.read_csv("base-data/tmdb_5000_movies.csv",sep=",")
json_columns = ['genres', 'keywords', 'production_companies']
for column in json_columns:
df[column] = df[column].apply(json.loads) # 处理字典
df = df[["genres", "keywords", "original_title", "production_companies"]]
for _, row in df.iterrows():
title = row["original_title"]
if not pattern.fullmatch(title): #匹配
continue
title = "\"" + title + "\""
#====================================================================================== 生成out_genre.csv数据集(电影类型)
for g in row["genres"]:
genre = g["name"]
genre = "\"" + genre + "\""
out_genre.write(f"{title},{genre}\n")
#====================================================================================== 生成out_keyword数据集(电影关键词)
for g in row["keywords"]:
keyword = g["name"]
keyword = "\"" + keyword + "\""
out_keyword.write(f"{title},{keyword}\n")
#====================================================================================== 生成out_productor.csv数据集(电影制片人)
for g in row["production_companies"]:
productor = g["name"]
productor = "\"" + productor + "\""
out_productor.write(f"{title},{productor}\n")
print("out_genre.csv Create Success...")
print("out_keyword.csv Create Success...")
print("out_productor.csv Create Success...")
out_genre.close()
out_keyword.close()
out_productor.close()
#=======================================================================================================
if __name__ == "__main__":
Netflix()
print("="*40)
TMDB()
四、Neo4j图形数据库
注意:如果没有安装Neo4j数据库和python库的可以去我上一篇文章或者点击下方链接查看安装教程https://blog.csdn.net/weixin_47971206/article/details/119860728
(一)介绍
作为图数据库,Neo4j最大的特点是关系数据的存储,图数据库除了能够像普通的数据库一样存储一行一行的数据之外,还可以很方便的存储数据之间的关系信息。
例如,对于一个社交网络的用户数据库,你除了要存储每个用户的姓名、性别、喜好这些基本信息外你还需要存储一个用户和哪些用户是朋友,和哪个用户是情侣这些关系数据,这个时候Neo4j这样的图数据就可以派上用场啦!
通过下图,大家可以了解下什么是图数据库以及什么是关系数据
在上图中,包含两个标签为“人”的数据节点,分别代表Ann和Dan两个用户。这两个数据节点还包含姓名、出生地等属性信息,用于表示两个用户的基本信息,就如同常规数据库中的两行数据。
除此之外,两个数据节点之间还包含两条关系数据,即Ann嫁给了Dan,Ann和Dan同居。利用这些关系数据,你就可以方便的作出基于关系的查询,例如你可以查询Ann跟谁结婚了,这就是图数据库的优势。
(二)展示
左边有两部分
一个是Node Labels,翻译过来是节点标签,它是一个实体图的展示。
一个是Relationship Types,翻译过来就是关系类型,它是一个实体间的关系图展示。
最上方的白色输入框是指令输入,Neo4j数据库包含大部分的SQL语法,本身也有自己的语法结构,有兴趣的可以去学学

五、创建实体图和关系图
注意:需要将分离出来的五个csv数据集复制到Neo4j数据库解压文件目录下的 import 文件夹里面
(一)原理
通过指令 pip install neo4j 安装neo4j库,导入 GraphDatabase 模块,通过调用内部的 driver 方法进行连接数据库,再通过 session 操作数据库
(二)代码
from neo4j import GraphDatabase
import pandas as pd
# 连接Neo4j数据库
uri = "bolt://localhost:7687" #本地地址
driver = GraphDatabase.driver(uri,auth=("neo4j","ydw18778450107")) #自己的账号和密码
# 相关设置及参数
k = 10
movies_common = 3
user_common = 2
threshold_sim = 0.9
def load_data():
with driver.session() as session:
session.run("""MATCH ()-[r]->() DELETE r""")
session.run("""MATCH (r) DELETE r""")
#================================================================================ 创建电影名称数据实体图
print("Loading movies...")
session.run("""
LOAD CSV WITH HEADERS FROM "file:///out_movies.csv" AS csv
CREATE (:Movie {title: csv.title})
""")
#================================================================================ 创建用户评分实体图
print("Loading gradings...")
session.run("""
LOAD CSV WITH HEADERS FROM "file:///out_grade.csv" AS csv
MERGE (m:Movie {title: csv.title})
MERGE (u:User {id: toInteger(csv.user_id)})
CREATE (u)-[:RATED {grading : toInteger(csv.grade)}]->(m)
""")
#================================================================================ 创建电影类型实体图
print("Loading genres...")
session.run("""
LOAD CSV WITH HEADERS FROM "file:///out_genre.csv" AS csv
MERGE (m:Movie {title: csv.title})
MERGE (g:Genre {genre: csv.genre})
CREATE (m)-[:HAS_GENRE]->(g)
""")
#================================================================================ 创建电影关键词实体图
print("Loading keywords...")
session.run("""
LOAD CSV WITH HEADERS FROM "file:///out_keyword.csv" AS csv
MERGE (m:Movie {title: csv.title})
MERGE (k:Keyword {keyword: csv.keyword})
CREATE (m)-[:HAS_KEYWORD]->(k)
""")
#================================================================================ 创建电影导演、公司等实体图
print("Loading productors...")
session.run("""
LOAD CSV WITH HEADERS FROM "file:///out_productor.csv" AS csv
MERGE (m:Movie {title: csv.title})
MERGE (p:Productor {name: csv.productor})
CREATE (m)-[:HAS_PRODUCTOR]->(p)
""")
#================================================================================ 主函数
if __name__ == "__main__":
if int(input("是否需要重新加载并创建知识图谱?(输入0或1)")):
load_data()
print("创建完毕...")
六、搭建推荐系统
(一)原理
前面已经介绍了余弦距离计算法的原理,搭建推荐系统的核心就是用户相似度的计算,本次项目采用的是协同过滤的算法,用余弦距离计算法计算用户间的相似度,原理是通过用户对电影的评分来匹配拥有相同爱好的用户,在相似度高的一群用户中,给用户一推荐电影,那么就可以把用户二评分过电影且用户一没评分过的推荐给用户一。
- (1)推荐用户
选择需要推荐的用户,给出选择是否过滤不喜欢的电影类型 - (2)计算相似度
计算用户和用户之间的相似度,用过余弦距离计算法计算两者的相似度,筛选出>0.9的用户 - (3)推荐电影
通过相似用户给推荐的用户推荐电影
(二)代码
下面代码是计算用户间的相似度的,用过余弦距离计算法求得用户间的相似度,然后筛选出相似度大于0.9的高相似度用户。

下面代码是过滤的操作,用户可以过滤掉自己不喜欢的电影类型

整体代码
def queries():
while True:
userid = input("请输入要为哪位用户推荐电影,输入其ID即可(回车结束):")
if userid == "":
break
userid = int(userid)
m = int(input("为该用户推荐多少个电影呢?"))
genres = []
if int(input("是否需要过滤不喜欢的类型?(输入0或1)")):
with driver.session() as session:
try:
q = session.run(f"""MATCH (g:Genre) RETURN g.genre AS genre""")
result = []
for i,r in enumerate(q):
result.append(r["genre"])
df = pd.DataFrame(result, columns={"genre"})
print()
print(df)
inp = input("输入不喜欢的类型索引即可,例如:1 2 3")
if len(inp) != 0:
inp = inp.split(" ")
genres = [df["genre"].iloc[int(x)] for x in inp]
except:
print("Error")
# 找到当前ID
with driver.session() as session:
q = session.run(f"""
MATCH (u1:User {{id : {userid}}})-[r:RATED]-(m:Movie)
RETURN m.title AS title, r.grading AS grade
ORDER BY grade DESC
""")
print()
print("Your ratings are the following(你的评分如下):")
result = []
for r in q:
result.append([r["title"], r["grade"]])
if len(result) == 0:
print("No ratings found")
else:
df = pd.DataFrame(result, columns=["title", "grade"])
print()
print(df.to_string(index=False))
print()
session.run(f"""
MATCH (u1:User)-[s:SIMILARITY]-(u2:User)
DELETE s
""")
# 找到当前用户评分的电影以及这些电影被其他用户评分的用户,with是吧查询集合当做结果方便后面用where余弦相似度计算
"""
Cosine相似度计算法(Cosine Similarity)
"""
session.run(f"""
MATCH (u1:User {{id : {userid}}})-[r1:RATED]-(m:Movie)-[r2:RATED]-(u2:User)
WITH
u1, u2,
COUNT(m) AS movies_common,
SUM(r1.grading * r2.grading)/(SQRT(SUM(r1.grading^2)) * SQRT(SUM(r2.grading^2))) AS sim
WHERE movies_common >= {movies_common} AND sim > {threshold_sim}
MERGE (u1)-[s:SIMILARITY]-(u2)
SET s.sim = sim
""")
# 过滤操作
Q_GENRE = ""
if (len(genres) > 0):
Q_GENRE = "AND ((SIZE(gen) > 0) AND a"
Q_GENRE += "(ANY(x IN " + str(genres) + " WHERE x in gen))"
Q_GENRE += ")"
# 找到相似的用户,然后看他们喜欢什么电影Collect,将所有值收集到一个集合List中
"""
s:SIMILARITY通过关系边查询
ORDER BY 降序排列
"""
q = session.run(f"""
MATCH (u1:User {{id : {userid}}})-[s:SIMILARITY]-(u2:User)
WITH u1, u2, s
ORDER BY s.sim DESC LIMIT {k}
MATCH (m:Movie)-[r:RATED]-(u2)
OPTIONAL MATCH (g:Genre)--(m)
WITH u1, u2, s, m, r, COLLECT(DISTINCT g.genre) AS gen
WHERE NOT((m)-[:RATED]-(u1)) {Q_GENRE}
WITH
m.title AS title,
SUM(r.grading * s.sim)/SUM(s.sim) AS grade,
COUNT(u2) AS num,
gen
WHERE num >= {user_common}
RETURN title, grade, num, gen
ORDER BY grade DESC, num DESC
LIMIT {m}
""")
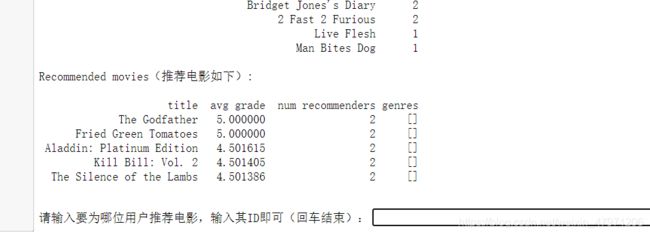
print("Recommended movies(推荐电影如下):")
result = []
for r in q:
result.append([r["title"],r["grade"],r["num"],r["gen"]])
if len(result) == 0:
print("No recommendations found(没有找到适合推荐的)")
print()
continue
df = pd.DataFrame(result, columns=["title", "avg grade", "num recommenders", "genres"])
print()
print(df.to_string(index=False))
print()
if __name__ == "__main__":
queries()
七、结果演示

相关资源:
Python期末大作业——采用Neo4j的基于协同过滤电影推荐系统.zip
Python实现自动百度搜索图片并下载(内附exe文件,不需要软件即可运行).zip
BmobLoginService.zip
- 本次文章分享就到这,有什么疑问或有更好的建议可在评论区留言,也可以私信我
- 感谢阅读~