ES的基本使用
1、简介
elasticSearch【分布式开源搜索与分析引擎,适用于所有类型的数据,包括文本,数字,地理空间,结构化和非结构化数据, 秒级从海量数据从检索出我们所需要的数据,而mysql单表如果达到了百万级数据,检索很慢】
用途:
1、应用程序搜索
2、网站搜索
3、企业搜索
4、日志处理和分析
5、基础设施指标和容器检测
6、应用程序性能检测
7、地理空间数据分析和可视化
8、安全分析和业务分析 mysql【数据的持久化管理curd】
2、基本概念
1、Index(索引),相当于mysql的insert操作,插入(索引)一条数据到数据库;名词形式相当于mysql的database; 2、Type(类型),在索引中,可以定义一个或者多个类型,类似于mysql的table,每一种类型的数据放到一起; 3、Document(文档),保存在某个索引(Index)下,某种类型(Type)的一个数据(Document),文档是Json格式的,Document就像是Mysql中的某个table里边的内容; ES集群 google microsoft megacorp 索引 employee product employee product 类型 {id:1,name:张三} 文档,一条记录 {id:2,name:李四} id被称为属性,==列 ES的概念2:倒排索引;Mysql中保存一条数据,可能是正向索引; 在ES中,会维护一张倒排索引表; 词 记录位置 红海 1,2,3,4,5 行动 1,2,3 特工 5
会有一个相关性得分:3号记录命中了两个单词;
3、基本环境搭建
docker pull elasticsearch
docker pull libana ##可视化检索数据
mkdir -p /mydata/elasticsearch/config #挂载到外部,方便修改
mkdir -p /mydata/elasticsearch/data #挂载到外部,方便修改
echo "http.host:0.0.0.0">> /mydata/elasticsearch/config/elasticsearch.yml #标识ES的机器,可以被远程任何机器访问,写入到yml里边
cat elasticsearch.yml
docker run --name elasticsearch -p 9200:9200 -p 9300:9300 \ #9200是restAPI的时候给9200发送请求,9300是ES在分布式集群下节点之间的通信端口
-e "discovery.type = single-node" \#单节点模式运行
-e ES_JAVA_OPTS = "-Xms64m -Xmx128m" \ #真正上线之后,内存都是32G左右的
-v /mydata/elasticsearch/config/elasticsearch.yml:/usr/share/elasticsearch/config/elasticsearch.yml \ #这是进行挂载配置文件
-v /mydata/elasticsearch/data:/usr/share/elasticsearch/data \ #这是挂载数据
-v /mydata/elasticsearch/plugins:/usr/share/elasticsearch/plugins \ #这是挂载插件目录
-d elasticsearch:latest
#查看镜像版本:
docker image inspect nginx:latest | grep -i version
生成elasticsearch容器[完整,有时行,有时不行,看内存好像,elasticsearch,默认好像占用全部内存,不要脸。]:
docker run --name elasticsearch -p 9200:9200 -p 9300:9300 \
-e "discovery.type=single-node" \
-e ES_JAVA_OPTS="-Xms512m -Xmx1024m" \
-v /mydata/elasticsearch/config/elasticsearch.yml:/usr/share/elasticsearch/elasticsearch.yml \
-v /mydata/elasticsearch/data:/usr/share/elasticsearch/data \
-v /mydata/elasticsearch/plugins:/usr/share/elasticsearch/plugins \
-d elasticsearch:latest
生成之后,容器2秒后死亡,扩大运行内存试试??【不管用,那就多分配点资源,不设置最小内存了】
docker run --name elasticsearch -p 9200:9200 -p 9300:9300 \
-e "discovery.type=single-node" \
-v /mydata/elasticsearch/config/elasticsearch.yml:/usr/share/elasticsearch/elasticsearch.yml \
-v /mydata/elasticsearch/data:/usr/share/elasticsearch/data \
-v /mydata/elasticsearch/plugins:/usr/share/elasticsearch/plugins \
-d elasticsearch
free -m 查看使用的虚拟机内存
启动Kibana
##docker run --name kibana -e ELASTICSEARCH_HOSTS=192.168.52.130:9200 -p 5601:5601 -d kibana:latest
docker run --name kibana -e ELASTICSEARCH_URL=http://192.168.52.130:9200 -p 5601:5601 -d kibana:latest
http://192.168.52.130:5601/app/kibana#?_g=()
/elastic/elasticsearch/master/docs/src/test/resources/accounts.json
--删除容器:
docker stop elasticsearch
docker rm elasticsearch
查看错误日志:
docker logs elasticsearch
--挂载的文件需要有读写权限:任何用户任何组都有执行权限;
chmod -R 777 /mydata/elasticsearch
执行前:
ll
drwxr-xr-x
执行后:
ll
drwxrwxrwx
elasticsearch的镜像启动成功之后,访问下:
http://192.168.52.130:9200/
{
"name" : "ZeFr4rR",
"cluster_name" : "elasticsearch",
"cluster_uuid" : "Hg9BNYkUQCy650XP26sYkw",
"version" : {
"number" : "5.6.12",
"build_hash" : "cfe3d9f",
"build_date" : "2018-09-10T20:12:43.732Z",
"build_snapshot" : false,
"lucene_version" : "6.6.1"
},
"tagline" : "You Know, for Search"
}相关DSL的语句使用
es查询节点相关信息
http://192.168.52.130:9200/_cat
=^.^=
/_cat/allocation
/_cat/shards
/_cat/shards/{index}
/_cat/master
/_cat/nodes
/_cat/tasks
/_cat/indices
/_cat/indices/{index}
/_cat/segments
/_cat/segments/{index}
/_cat/count
/_cat/count/{index}
/_cat/recovery
/_cat/recovery/{index}
/_cat/health
/_cat/pending_tasks
/_cat/aliases
/_cat/aliases/{alias}
/_cat/thread_pool
/_cat/thread_pool/{thread_pools}
/_cat/plugins
/_cat/fielddata
/_cat/fielddata/{fields}
/_cat/nodeattrs
/_cat/repositories
/_cat/snapshots/{repository}
/_cat/templates
http://192.168.52.130:9200/_cat/nodes
127.0.0.1 12 62 0 0.01 0.07 0.12 mdi * ZeFr4rR 【在集群状态下,哪个节点标了*,说明他是主节点】
http://192.168.52.130:9200/_cat/health --查看es的健康状况
1647341114 10:45:14 elasticsearch green 1 1 0 0 0 0 0 0 - 100.0% 【中间的一些数字是集群分片信息】
http://192.168.52.130:9200/_cat/master --查看主节点
ZeFr4rRZQz-w3ZK80Vuv0Q 127.0.0.1 127.0.0.1 ZeFr4rR
http://192.168.52.130:9200/_cat/indices --查看所有索引 show databases
2、索引一个文档(保存)
保存一个数据,保存在那个索引类型下,指定用哪个唯一索引
在customer索引下的external类型下保存1号数据为
PUT请求方式,必须得带上id
http://192.168.52.130:9200/customer/external/1
body里边的json
{
"name":"pansd"
}
返回信息:
{
"_index": "customer",
"_type": "external",
"_id": "1",
"_version": 1, +1
"result": "created", --updated,
"_shards": { --分片,集群环境下介绍;
"total": 2,
"successful": 1,
"failed": 0
},
"created": true
}
分析返回数据:带_的都是元数据。put请求,第一次是请求时创建操作,以后的请求是更新操作。
如果是post请求方式,不指定id;
{
"_index": "customer",
"_type": "external",
"_id": "AX-NOVshrEj9CP_oy5eV", --自动生成id,多次发送请求,每次都会产生唯一的id;
"_version": 1,
"result": "created",
"_shards": {
"total": 2,
"successful": 1,
"failed": 0
},
"created": true
}
--如果带上了id,就和put一样了。
es的查询:
Get方式: customer/external/1
http://192.168.52.130:9200/customer/external/1
{
"_index": "customer",
"_type": "external",
"_id": "1",
"_version": 1,
"_seq_no":1, -- 此版本的镜像没有,每次更新就会+1,用来做乐观锁。
"_primary_term":1, -- 此版本的镜像没有,主分片重新分配,如果重启,就会发生变化。
"found": true,
"_source": {
"name": "pansd"
}
}
并发更新es的的时候,要带上乐观锁,进行并发控制。或者带上版本号,进行并发控制。
比如:
put请求:http://192.168.52.130:9200/customer/external/1?if_seq_no=1&if_primary_term=1
使用update更新:
post请求方式:http://192.168.52.130:9200/customer/external/1_update
{
"doc":{
"name":"pshdhx"
}
}
1、第一次更新,版本号会改变;若在发送相同的请求,版本号和锁序列号不会改变了。【简言之:update会对比原来的数据】
删除文档索引:
delete customer/external/1
{
"found": true,
"_index": "customer",
"_type": "external",
"_id": "1",
"_version": 2,
"result": "deleted",
"_shards": {
"total": 2,
"successful": 1,
"failed": 0
}
}
再搜索:
{
"_index": "customer",
"_type": "external",
"_id": "1",
"found": false
}
delete customer 【删除索引,但是es中是不能单独删除类型的;或者是把索引下所有的数据都给清空了,这样也相当于是删除了类型。】
批量导入API
此时批量操作json格式不对,使用text的换行又不对了,所以得使用kibana了。
1、首先必须post请求
2、customer/external/_bulk
action
body
具体展示为:每两行一个操作;批量插入两行数据;在kibana中的dev tools中添加如下代码;
post /customer/external/_bulk
{"index":{"_id":"1"}}
{"name":"pansd"}
{"index":{"_id":"2"}}
{"name":"pshdhx"}
返回值为:
{
"took": 62,
"errors": false,
"items": [
{
"index": {
"_index": "customer",
"_type": "external",
"_id": "1",
"_version": 1,
"result": "created",
"_shards": {
"total": 2,
"successful": 1,
"failed": 0
},
"created": true,
"status": 201
}
},
{
"index": {
"_index": "customer",
"_type": "external",
"_id": "2",
"_version": 1,
"result": "created",
"_shards": {
"total": 2,
"successful": 1,
"failed": 0
},
"created": true,
"status": 201
}
}
]
}复杂DSL语句
复杂操作:
post /_bulk
{"delete":{"_index":"website","_type":"blog","_id":"123"}}
{"create":{"_index":"website","_type":"blog","_id":"123"}}
{"title":"my first blog"}
{"index":{"_index":"website","_type":"blog"}}
{"title":"my second blog"}
{"update":{"_index":"website","_type":"blog","_id":"123"}}
{"doc":{"title":"my updated blog post"}}
返回了:
{
"took": 24,
"errors": false,
"items": [
{
"delete": {
"found": true,
"_index": "website",
"_type": "blog",
"_id": "123",
"_version": 6,
"result": "deleted",
"_shards": {
"total": 2,
"successful": 1,
"failed": 0
},
"status": 200
}
},
{
"create": {
"_index": "website",
"_type": "blog",
"_id": "123",
"_version": 7,
"result": "created",
"_shards": {
"total": 2,
"successful": 1,
"failed": 0
},
"created": true,
"status": 201
}
},
{
"index": {
"_index": "website",
"_type": "blog",
"_id": "AX-OHvjg4kOgKKwsJNF9",
"_version": 1,
"result": "created",
"_shards": {
"total": 2,
"successful": 1,
"failed": 0
},
"created": true,
"status": 201
}
},
{
"update": {
"_index": "website",
"_type": "blog",
"_id": "123",
"_version": 8,
"result": "updated",
"_shards": {
"total": 2,
"successful": 1,
"failed": 0
},
"status": 200
}
}
]
}
批量新增的数据地址:https://github.com/elastic/elasticsearch/blob/5.0/docs/src/test/resources/accounts.json
post /bank/account/_bulk
.....
新增成功后:使用高级检索:
docker update ... --restart=always
https://www.elastic.co/guide/index.html 参照官方文档:
https://www.elastic.co/guide/en/elastic-stack-get-started/7.5/index.html
https://www.elastic.co/guide/en/elasticsearch/reference/7.5/getting-started-search.html
GET bank/_search?q=*&sort=account_number:asc
该响应还提供有关搜索请求的以下信息:
took– Elasticsearch 运行查询需要多长时间,以毫秒为单位
timed_out– 搜索请求是否超时
_shards– 搜索了多少分片,以及多少分片成功、失败或被跳过的细分。
max_score– 找到的最相关文档的分数
hits.total.value- 找到了多少匹配的文档
hits.sort- 文档的排序位置(不按相关性分数排序时)
hits._score- 文档的相关性分数(使用时不适用match_all)
total": 1000,但是实际上hits里边只有10条,这是分页的结果。
##match_all的查询;全文检索
GET /bank/_search
{
"query": { "match_all": {} },
"sort": [
{ "account_number":{
"order": "desc"
}
}
],
"from": 0,
"size": 20,
"_source": ["balance","firstname"]
}
##match查询;按条件模糊查询
GET /bank/_search
{
"query": {
"match": {
"address": "mill lane" ##凡是有mill或者是lane的,都返回
}
}
}
##只返回这样的mill lane;短语查询;
GET /bank/_search
{
"query": { "match_phrase": { "address": "mill lane" } }
}
must和must_not;满足should的得分高;
GET /bank/_search
{
"query": {
"bool": {
"must": [
{ "match": { "age": "40" } }
],
"must_not": [
{ "match": { "state": "ID" } }
],
"should": [
{
"match": {
"address": "MILL"
}
}
]
}
}
}
##filter不会计算相关性得分。must会计算相关性得分。
GET /bank/_search
{
"query": {
"bool": {
"must": { "match_all": {} },
"filter": {
"range": {
"balance": {
"gte": 20000,
"lte": 30000
}
}
}
}
}
}
##多字段匹配
get bank/_search
{
"query":{
"multi_match": {
"query": "mill",
"fields": ["state","address"]
}
}
}
使用term检索精确字段的值;与match正好相反(match适用于全文检索)
get bank/_search
{
"query":{
"term": {
"age": {
"age": "20"
}
}
}
}
##查询精确值 这是精确匹配
get bank/_search
{
"query":{
"match": {
"address.keyword": "MILL"
}
}
}聚合函数
众所周知:elasticsearch是一个搜索与分析的引擎,下面是它的分析的用法。
Analyze results with aggregations
搜索address中包含mill的所有人的年龄分布以及平均年龄;
get bank/_search
{
"query":{
"match":{
"address":"mill"
}
},
"aggs":{
"ageAgg":{
"terms": {
"field": "age",
"size": 10
}
},
"ageAvg":{
"avg": {
"field": "age"
}
},
"balanceAvg":{
"avg": {
"field": "balance"
}
}
},
##不显示hits的结果,只显示个数。
"size":0
}
"aggregations": {
"ageAgg": {
"doc_count_error_upper_bound": 0,
"sum_other_doc_count": 0,
"buckets": [
{
"key": 38,
"doc_count": 2
},
{
"key": 28,
"doc_count": 1
},
{
"key": 32,
"doc_count": 1
}
]
}
}
##按照年龄进行聚合,并且请求这些年龄的这些人的平均薪资
get bank/_search
{
"query":{
"match_all": {}
},
"aggs":{
"ageAgg":{
"terms": {
"field": "age",
"size": 10
},
"aggs":{
"balanceAvg":{
"avg": {
"field": "balance"
}
}
}
}
}
}
返回值:
"aggregations": {
"ageAgg": {
"doc_count_error_upper_bound": 0,
"sum_other_doc_count": 463,
"buckets": [
{
"key": 31,
"doc_count": 61,
"balanceAvg": {
"value": 28312.918032786885
}
},
{
"key": 39,
"doc_count": 60,
"balanceAvg": {
"value": 25269.583333333332
}
},
##查出所有年龄分布,并且这些年龄段中男性的平均薪资和女性的平均薪资,还有总体的平均薪资
get bank/_search
{
"query":{
"match_all": {}
},
"aggs":{
"ageAgg":{
"terms": {
"field": "age",
"size": 10
},
"aggs": {
"genderAgg": {
"terms": {
"field": "gender.keyword",
"size": 10
},
"aggs": {
"balanceAgg": {
"avg": {
"field": "balance"
}
}
}
},
"balanceAvgAll":{
"avg": {
"field": "balance"
}
}
}
}
}
}
返回值:
"buckets": [ 31岁的人 有 61个; 35个男的,26个女的; 男的的平均薪资是29565.628571428573 女性的平均薪资是26626.576923076922
{
"key": 31,
"doc_count": 61,
"genderAgg": {
"doc_count_error_upper_bound": 0,
"sum_other_doc_count": 0,
"buckets": [
{
"key": "M",
"doc_count": 35,
"balanceAgg": {
"value": 29565.628571428573
}
},
{
"key": "F",
"doc_count": 26,
"balanceAgg": {
"value": 26626.576923076922
}
}
]
},
"balanceAvgAll": {
"value": 28312.918032786885
}
},
mapping映射
elasticsearch的mapping方式:7.x之后,去除了type;预计8.x取消type的支持。为了防止不同的type的字段名称相同。
get bank/_mapping
关于ES中的数据类型:https://www.elastic.co/guide/en/elasticsearch/reference/7.5/mapping-types.html
string
text and keyword
Numeric
long, integer, short, byte, double, float, half_float, scaled_float
Date
date
Date nanoseconds
date_nanos
Boolean
boolean
Binary
binary
Range
integer_range, float_range, long_range, double_range, date_range
还有复杂数据类型。
关于映射:很恶心,不同的版本不一样,看对应版本的文档都对应不起来。
get bank/_mapping
PUT my_index
{
"mappings": {
"user": {
"_all": {
"enabled": false
},
"properties": {
"title": {
"type": "text"
},
"name": {
"type": "text"
},
"age": {
"type": "integer"
}
}
}
}
}
PUT twitter
{
"mappings": {
"user": {
"properties": {
"name": { "type": "text" },
"user_name": { "type": "keyword" },
"email": { "type": "keyword" }
}
},
"tweet": {
"properties": {
"content": { "type": "text" },
"user_name": { "type": "keyword" },
"tweeted_at": { "type": "date" }
}
}
}
}
PUT twitter/user/kimchy
{
"name": "Shay Banon",
"user_name": "kimchy",
"email": "shay@kimchy.com"
}
PUT twitter/tweet/1
{
"user_name": "kimchy",
"tweeted_at": "2017-10-24T09:00:00Z",
"content": "Types are going away"
}
GET twitter/tweet/_search
{
"query": {
"match": {
"user_name": "kimchy"
}
}
}
PUT twitter
{
"mappings": {
"doc": {
"properties": {
"type": { "type": "keyword" },
"name": { "type": "text" },
"user_name": { "type": "keyword" },
"email": { "type": "keyword" },
"content": { "type": "text" },
"tweeted_at": { "type": "date" }
}
}
}
}ES的映射修改和数据迁移
##创建一个索引,并指定映射规则
PUT /my_index
{
"mappings": {
"properties": {
"age":{"type": "integer"},
"email":{"type": "keyword"},
"name":{"type": "text"}
}
}
}
##修改索引下的映射规则,【新增字段】
PUT /my_index/_mapping
{
"properties":{
"employee-id":{"type":"keyword","index":false}
}
}
GET /my_index/_mapping
##对于已经存在的映射字段,我们是不能更新的,只能添加;因为如果修改映射,那么可能存在已有的数据;我们
可以创建一个新的索引,重新reindex原来的数据。【数据迁移】
##创建新的索引,来改变老的索引的映射类型
PUT /newBank
{
"mappings": {
"properties": {
}
}
}
##数据迁移
POST _reindex
{
"source": {
"index": "bank",
"type": "account"
},
"dest": {
"index": "newBank"
}
}
4、ES的分词器
关于ES的分词:
一个tokenizer(分词器)接收一个字符流,将之分割为独立的tokens(词元,通常是独立的单词),然后输出token流。
例如:whitespace tokenizer遇到空格字符时分割文本。它会将文本"Quick brown fox"分割为 【quick,brown,fox】
该tokenizer(分词器)还负责记录各个term(词条)的顺序或者是position位置(用于phrase短语和word proximity词近邻查询),以及term词条所
代表的原始word的start和end的字符偏移量。(用于高亮显示搜索的内容)
ES提供了很多内置的分词器,可以用来构建custom analyzers(自定义分词器)
4.1、安装ik分词器:
ES的分词器:7.4.2
链接:https://pan.baidu.com/s/1DpWUZEFicNiYOJDCSDidVA
提取码:pshd
--来自百度网盘超级会员V2的分享
POST _analyze
{
"analyzer": "whitespace",
"text": "The quick brown fox."
}
安装下中文分词器:ik;github到plugins;
进入容器内部:
docker exec -it elasticsearch /bin/bash
pwd
ls
exit退出容器
先下载wget :用yum下载下载器;
yum install wget
设置root登录:
vi /etc/ssh/sshd_config
修改:passwordAuthentication yes/no
重启服务:service sshd restart
1、必须安装ES对应版本的IK分词器;
2、放入的plugins目录下;
3、重启容器;
4、测试分词:
POST _analyze
{
"analyzer": "ik_smart", ## ik_max_word
"text": "尚硅谷电商项目"
}
返回值:
{
"tokens": [
{
"token": "尚",
"start_offset": 0,
"end_offset": 1,
"type": "CN_CHAR",
"position": 0
},
{
"token": "硅谷",
"start_offset": 1,
"end_offset": 3,
"type": "CN_WORD",
"position": 1
},
{
"token": "电",
"start_offset": 3,
"end_offset": 4,
"type": "CN_CHAR",
"position": 2
},
{
"token": "商",
"start_offset": 4,
"end_offset": 5,
"type": "CN_CHAR",
"position": 3
},
{
"token": "项目",
"start_offset": 5,
"end_offset": 7,
"type": "CN_WORD",
"position": 4
}
]
}
有些词语分词器不识别,需要创建自定义分词:
1、先设置网卡:
添加GATEWAY=xxxxx.1
DNS1=114.114.114.114
DNS2=8.8.8.8
使用了match之后,会有一个max_score最大得分;查询数字是精确查询;查询字符串是模糊查询【全文检索】;
关于自定义分词器:
4.2、安装nginx
安装nginx,把词库的地址放到nginx里边;
docker container cp nginx:/etc/nginx .
mv nginx conf #文件夹改名
mv conf nginx/ #把conf挪移到nginx文件夹里边
docker stop nginx;
docker rm nginx;
docker run -p 80:80 --name nginx \
-v /mydata/nginx/conf/html:/usr/share/nginx/html \
-v /mydata/nginx/conf/logs:/var/log/nginx \
-v /mydata/nginx/conf:/etc/nginx \
-d nginx:1.10
docker run -p80:80 --name nginx -v/mydata/nginx/html:/usr/share/nginx/html -v/mydata/nginx/logs:/var/log/nginx -v /mydata/nginx/conf:/etc/nginx -d nginx:1.10 ##【正确】
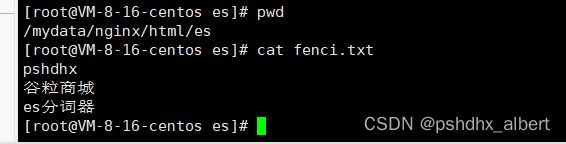
在nginx里边自定义fenci.txt
配置ik分词器的词库地址http://192.168.52.130/es/fenci.txt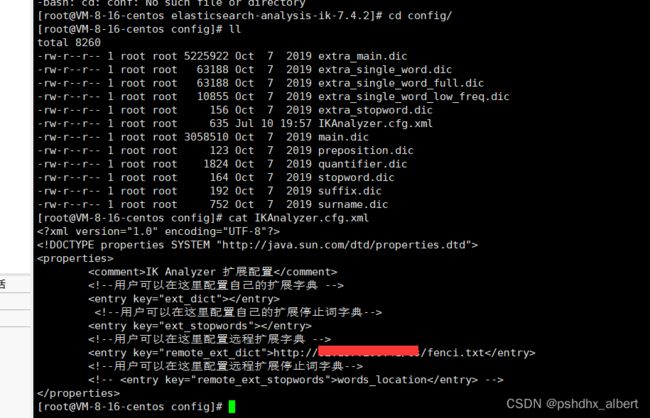
5、 java代码交互elasticsearch
5.1、pom.xml
7.4.2
org.elasticsearch.client
elasticsearch-rest-high-level-client
7.4.2
5.2、配置文件configuration
package com.pshdhx.elasticsearch.config;
import org.apache.http.HttpHost;
import org.elasticsearch.client.RequestOptions;
import org.elasticsearch.client.RestClient;
import org.elasticsearch.client.RestClientBuilder;
import org.elasticsearch.client.RestHighLevelClient;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
/**
* @author pshdhx
* @date 2022-03-28 15:09
*/
@Configuration
public class ElasticSearchConfiguration {
public static final RequestOptions COMMON_OPTIONS;
static {
RequestOptions.Builder builder = RequestOptions.DEFAULT.toBuilder();
//addHeader();
//setHttpAsyncResponseCounsumerFactory
COMMON_OPTIONS = builder.build();
}
@Bean
public RestHighLevelClient EsRestClient(){
RestClientBuilder restClientBuilder = RestClient.builder(new HttpHost("82.xx.xx.xxxx", 9200, "http"));
RestHighLevelClient client = new RestHighLevelClient(restClientBuilder);
return client;
}
}
5.3、测试文件
package com.pshdhx.elasticsearch;
import com.alibaba.fastjson.JSON;
import lombok.AllArgsConstructor;
import lombok.Data;
import org.elasticsearch.action.index.IndexRequest;
import org.elasticsearch.client.RestHighLevelClient;
import org.elasticsearch.common.xcontent.XContentType;
import org.junit.jupiter.api.Test;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.boot.test.context.SpringBootTest;
import org.springframework.test.context.junit4.SpringRunner;
@SpringBootTest
public class GulimallElasticsearchApplicationTests {
@Autowired
private RestHighLevelClient restHighLevelClient;
@Test
public void contextLoads() {
System.out.println("哈哈");
System.out.println(restHighLevelClient);
}
@Test
public void indexData(){
IndexRequest indexRequest = new IndexRequest("users");
indexRequest.id("1");
indexRequest.source("userName","zhangsan","age",18,"gender","男");
User user = new User("pshdhx",18,"man");
String jsonString = JSON.toJSONString(user);
IndexRequest index = indexRequest.source(jsonString, XContentType.JSON);
System.out.println(index);
}
@Data
@AllArgsConstructor
class User{
private String userName;
private Integer age;
private String gender;
}
}