我们了解互斥量和条件变量之前,我们先来看一下为什么要有互斥量和条件变量这两个东西,了解为什么有这两东西之后,理解起来后面的东西就简单很多了!!!
先来看下面这段简单的代码:
int g_num = 0;
void print(int id)
{
for (int i = 0; i < 5; i++)
{
++g_num;
cout << "id = " << id << "==>" << g_num << endl;
std::this_thread::sleep_for(std::chrono::seconds(1));
}
}
int main()
{
thread tha(print, 0);
thread thb(print, 1);
tha.join();
thb.join();
return 0;
}
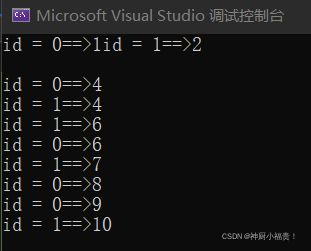
上述代码功能大致就是在线程tha和thb中运行函数print,每个线程对g_num进行加加一次,最后加出来的g_num的值应该是10,那么我们现在来看结果:

我们看到运行结果,为什么打印结果最后,按理来说两个线程各加五次,最后结果应该是10呀,怎么会是9呢?
如上图所示,是因为++这个运算符不是原子操作(不会被线程调度机制打断的操作),我们可以将g_num设置为原子数,改为atomic_int g_num = 0;
atomic_int g_num = 0; //将g_num设置为原子操作数 //atomicg_num = 0;这个和上面是一样的 下面这行是模板化之后的 void print(int id) { for (int i = 0; i < 5; i++) { ++g_num; cout << "id = " << id << "==>" << g_num << endl; std::this_thread::sleep_for(std::chrono::seconds(1)); } } int main() { thread tha(print, 0); thread thb(print, 1); tha.join(); thb.join(); return 0; }
将g_num设置为原子操作数之后,在++阶段就不会被线程调度机制给打断,我们来看运行结果:
运行结果是我所期望的但是中间那块又出了一点小状况连着打着两个4,两个6,这种情况该怎么办呢?
下面就该说道我们的互斥锁了:
互斥锁:
在上述代码中我们使用了共享资源----->全局量g_num,两个线程同时对g_num进行++操作,为了保护共享资源,在线程里也有这么一把锁——互斥锁(mutex),互斥锁是一种简单的加锁的方法来控制对共享资源的访问,互斥锁只有两种状态,即上锁( lock )和解锁( unlock )。
来看下面代码:
int g_num = 0;
std::mutex mtx; //创建锁对象
void print(int id)
{
for (int i = 0; i < 5; i++)
{
mtx.lock(); //上锁
++g_num;
cout << "id = " << id << "==>" << g_num << endl;
mtx.unlock(); //解锁
std::this_thread::sleep_for(std::chrono::microseconds(500));
}
}
int main()
{
thread tha(print, 0);
thread thb(print, 1);
tha.join();
thb.join();
return 0;
}
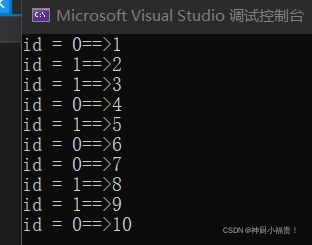
我们来看运行结果:符合我们最初的预期。
打开官方文档,可以看到

创建锁对象只有这个方法,拷贝构造被删除了 。
std::mutex::try_lock
对于互斥锁的lock和unlock我们都很熟悉了,下面来说一下std::mutex::try_lock这个成员函数!
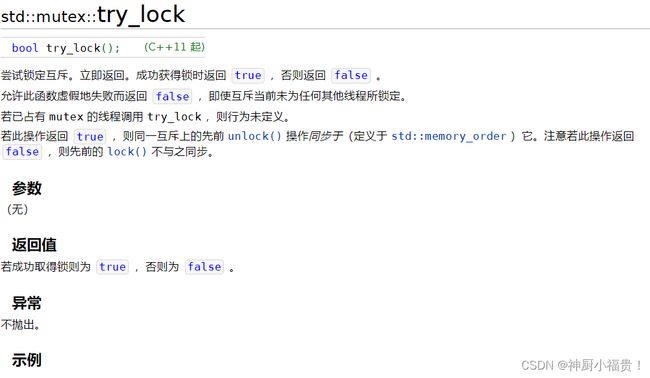
try_lock字面意思就是说尝试上锁,如果上锁成功,返回true,上锁失败则返回false,但是如果上锁失败,他还是会接着往下运行,不会像lock哪运被阻塞在上锁那块,所以try_lock必须得在循环中使用:
int g_num = 0;
std::mutex mtx;
void print(int id)
{
for (int i = 0; i < 5; i++)
{
mtx.try_lock(); //代码只是将lock换成了try_lock且没把try_lock扔在循环中执行
++g_num;
cout << "id = " << id << "==>" << g_num << endl;
mtx.unlock();
std::this_thread::sleep_for(std::chrono::microseconds(500));
}
}
int main()
{
thread tha(print, 0);
thread thb(print, 1);
tha.join();
thb.join();
return 0;
}
我们来看运行结果:

unlock of unowned mutex,这玩意思就是说你在给个没上锁的互斥锁解锁,所以报这错误,因此try_lock搁在普通语句中,会有很大的问题,现命我们演示一下将这玩意放到循环中去弄一边:
int g_num = 0;
std::mutex mtx;
void print(int id)
{
for (int i = 0; i < 5; i++)
{
while (!mtx.try_lock()) //try_lock失败时为false 前面加了!,所以失败时为true 然后打印尝试加锁
{ //然后再次尝试加锁,只有加锁成功了,才能出这个while循环
cout << "try lock" << endl;
}
++g_num;
cout << "id = " << id << "==>" << g_num << endl;
mtx.unlock();
std::this_thread::sleep_for(std::chrono::microseconds(500));
}
}
int main()
{
thread tha(print, 0);
thread thb(print, 1);
tha.join();
thb.join();
return 0;
}
我们来看运行结果:

运行结果符合我们的预期,但是try_lock这个函数有个不好处是太损耗资源了,当它加锁失败时,一直尝试加锁一直尝试加锁,损耗CPU资源。
条件变量:condition_variable

框住这三个函数较为重要,下面着重来说下面这三个函数: 这里顺便说一下,下面代码将会是条件变量和互斥锁的结合使用,至于为什么要将互斥锁和条件变量一起使用,原因就是互斥锁状态太单一了,而条件变量允许阻塞,接收信号量等刚好弥补了互斥锁的缺陷所以这些一起使用!!!
这三个函数呢,通过一个小实验来实现,通过多线程分别打印123一直到100:
std::mutex mtx;
std::condition_variable cv;
int isReady = 0;
const int n = 100;
void print_A()
{
std::unique_lock lock(mtx); //unique_lock相当于线程中的智能制造 自动解锁,不需要再unlock
int i = 0;
while (i < n)
{
while (isReady != 0)
{
cv.wait(lock);//互斥锁和信号量一起使用 wait参数为锁对象
}
cout << "A" ;
isReady = 1;
++i;
std::this_thread::sleep_for(std::chrono::microseconds(100));
cv.notify_all(); //当isReady等于0时print_B 和 print_C 处于阻塞状态
//该函数就是唤醒所有等待的函数,然后通过isReady来进行判断要进行那个函数的运行
}
}
void print_B()
{
std::unique_lock lock(mtx); //unique_lock相当于线程中的智能制造 自动解锁,不需要再unlock
int i = 0;
while (i < n)
{
while (isReady != 1)
{
cv.wait(lock);
}
cout << "B" ;
isReady = 2;
++i;
std::this_thread::sleep_for(std::chrono::microseconds(100));
cv.notify_all();
}
}
void print_C()
{
std::unique_lock lock(mtx); //unique_lock相当于线程中的智能制造 自动解锁,不需要再unlock
int i = 0;
while (i < n)
{
while (isReady != 2)
{
cv.wait(lock);
}
cout << "C" ;
isReady = 0;
++i;
std::this_thread::sleep_for(std::chrono::microseconds(100));
cv.notify_all();
}
}
int main()
{
thread tha(print_A);
thread thb(print_B);
thread thc(print_C);
tha.join();
thb.join();
thc.join();
return 0;
}
上面代码解析:

运行结果:
![]()
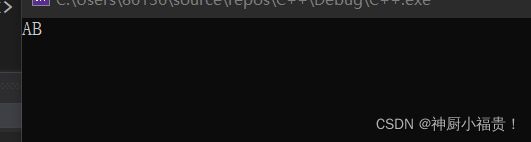
我们可以看到上述代码最后唤醒其他线程使用的是notify_all()函数,notify_all()函数作用就是环球其他阻塞的函数,然后因为isready这个数的存在,所以就会选择合适的线程来进行执行,如果我们使用notify_one()呢,先来说下notify_one()函数的作用是什么。notify_one()函数是唤醒其他线程(随机唤醒,这道题中不适合,因为如果打印完A之后唤醒了C线程那么就会一直阻塞在那块)
我们试一下notify_one()函数,可以发现这玩意确实会堵塞在那块:
总结
本篇文章就到这里了,希望能够给你带来帮助,也希望您能够多多关注脚本之家的更多内容!