机器学习算法——手动搭建朴素贝叶斯分类器(附代码)
朴素贝叶斯分类器实战
- 朴素贝叶斯分类器原理
- 分类器实现
- 使用鸢尾花数据集检验
朴素贝叶斯分类器原理
(1) X = ( x 1 , x 2 , ⋯ , x D ) X=\left( x_{1},x_{2},\cdots ,x_{D}\right) X=(x1,x2,⋯,xD) 表示含有 D D D 维属性的数据对象。训练集 S S S 含有 k k k 个类别,表示为 Y = ( y 1 , y 2 , ⋯ , y k ) Y=\left( y_{1},y_{2},\cdots ,y_{k}\right) Y=(y1,y2,⋯,yk)。
(2)已知待分类数据对象 x x x 预测 x x x 所属类别,计算方式如下:
y k = arg max y k ∈ y ( P ( y k ∣ x ) ) y_{k}=\arg \max_{y_{k}\in y} \left( P\left( y_{k}\mid x\right) \right) yk=argyk∈ymax(P(yk∣x))
所得 y k y_{k} yk 即为 x x x 所属类别。上式表示,已知待分类数据对象 x x x 的情况下,分别计算 x x x 属于 y 1 y_{1} y1、 y 2 y_{2} y2、…、 y k y_{k} yk 的概率,选取其中概率的最大值,此时所对应的 y k y_{k} yk,即为 x x x 所属类别。
(3)根据贝叶斯定理, P ( y k ∣ x ) P\left( y_{k}\mid x\right) P(yk∣x) 计算方式如下:
P ( y k ∣ x ) = P ( x ∣ y k ) × P ( y k ) P ( x ) P\left( y_{k}\mid x\right) =\frac{P\left( x\mid y_{k}\right) \times P\left( y_{k}\right) }{P\left( x\right) } P(yk∣x)=P(x)P(x∣yk)×P(yk)
计算过程中, P ( x ) P(x) P(x) 对于 P ( y k ∣ x ) P\left( y_{k}\mid x\right) P(yk∣x) ,相当于常数。因此,若想得到 P ( y k ∣ x ) P\left( y_{k}\mid x\right) P(yk∣x) 最大值,只需计算 P ( x ∣ y k ) × P ( y k ) P\left( x\mid y_{k}\right) \times P\left( y_{k}\right) P(x∣yk)×P(yk) 最大值。如果类别的先验概率未知,即 P ( y k ) P\left( y_{k}\right) P(yk) 未知,则通常假定这些类别是等概率的,即 P ( y 1 ) = P ( y 2 ) = . . . = P ( y k ) P\left( y_{1}\right)=P\left( y_{2}\right)=...=P\left( y_{k}\right) P(y1)=P(y2)=...=P(yk)。
(4)假设数据对象的各属性之间相互独立, P ( x ∣ y k ) P\left( x\mid y_{k}\right) P(x∣yk)计算方式如下:
P ( x ∣ y k ) = ∏ d = 1 D P ( x d ∣ y k ) P\left( x\mid y_{k}\right) =\prod^{D}_{d=1} P\left( x_{d}\mid y_{k}\right) P(x∣yk)=d=1∏DP(xd∣yk)
(5)其中, P ( x d ∣ y k ) P\left( x_{d}\mid y_{k}\right) P(xd∣yk) 的计算方式如下:
- 如果属性 d d d 是离散属性或分类属性。训练集中属于类别 y d y_{d} yd 的数据对象在属性 d d d 下的相异属性值共有 n n n 个;训练集中属于类别 y k y_{k} yk,且在属性 d d d 下的属性值为 x d x_{d} xd 的数据对象共有 m m m 个。则 P ( x d ∣ y k ) P\left( x_{d}\mid y_{k}\right) P(xd∣yk) 计算方式如下:
P ( x d ∣ y k ) = m n P\left( x_{d}\mid y_{k}\right) =\frac{m}{n} P(xd∣yk)=nm - 如果属性 d d d 是连续属性。通常假设连续属性均服从均值为 μ \mu μ、标准差为 σ \sigma σ 的高斯分布, 即
G ( x d , μ , σ ) = 1 2 π σ e − ( x − μ ) 2 2 σ 2 G\left( x_{d},\mu ,\sigma \right) =\frac{1}{\sqrt{2\pi } \sigma } e^{-\frac{\left( x-\mu \right)^{2} }{2\sigma^{2} } } G(xd,μ,σ)=2πσ1e−2σ2(x−μ)2
于是 P ( x d ∣ y k ) = G ( x d , μ , σ ) P\left( x_{d}\mid y_{k}\right)=G\left( x_{d},\mu ,\sigma \right) P(xd∣yk)=G(xd,μ,σ)。
其中, μ \mu μ、 σ \sigma σ 表示训练集中属于类别 y k y_{k} yk 的数据对象在属性 d d d 下的均值和标准差。
分类器实现
导入模块
import numpy as np
import pandas as pd
from random import seed
from random import randrange
from math import sqrt
from math import exp
from math import pi
import plotly.express as px
from plotly.offline import init_notebook_mode
init_notebook_mode(connected=True)
方法定义
def str_column_to_int(dataset, column):
"""
将类别转化为int型
@dataset: 数据
@column: 需要转化的列
"""
class_values = [row[column] for row in dataset]
unique = set(class_values)
lookup = dict()
for i, value in enumerate(unique):
lookup[value] = i
for row in dataset:
row[column] = lookup[row[column]]
print(lookup)
return lookup
def cross_validation_split(dataset, n_folds):
"""
使用交叉检验方法验证算法
@dataset: 数据
@n_folds: 想要划分的折数
"""
dataset_split = list()
dataset_copy = list(dataset)
fold_size = int(len(dataset) / n_folds) # 一个fold的大小
for _ in range(n_folds):
fold = list()
while len(fold) < fold_size:
index = randrange(len(dataset_copy))
fold.append(dataset_copy.pop(index))
dataset_split.append(fold)
return dataset_split
def accuracy_metric(actual, predicted):
"""
计算准确率
@actual: 真实值
@predicted: 预测值
"""
correct = 0
for i in range(len(actual)):
if actual[i] == predicted[i]:
correct += 1
return correct / float(len(actual)) * 100.0
def evaluate_algorithm(dataset, algorithm, n_folds, *args):
"""
评估使用的分类算法(基于交叉检验)
@dataset: 数据
@algorithm: 使用的算法
@n_folds: 选择要划分的折数
@*args: 根据使用的分类算法而定,在朴素贝叶斯里面不需要其他的参数
"""
folds = cross_validation_split(dataset, n_folds)
scores = list()
for i in range(len(folds)):
train_set = np.delete(folds, i, axis=0)
# print(train_set)
test_set = list()
for row in folds[i]:
row_copy = list(row)
test_set.append(row_copy)
row_copy[-1] = None
predicted = algorithm(train_set, test_set, *args)
actual = [row[-1] for row in folds[i]]
accuracy = accuracy_metric(actual, predicted)
scores.append(accuracy)
return scores
def separate_by_class(dataset):
"""
将数据集根据类别进行分类
@dataset: 数据
"""
separated = dict()
dataset = dataset.reshape((-1,5))
for i in range(len(dataset)):
vector = dataset[i]
class_value = vector[-1]
if (class_value not in separated):
separated[class_value] = list()
separated[class_value].append(vector)
return separated
def summarize_dataset(dataset):
"""
计算每一个特征的统计性指标,这是为了后续计算条件概率
@dataset: 数据
"""
summaries = [(np.mean(column), np.std(column), len(column)) for column in zip(*dataset)]
del(summaries[-1])
return summaries
def summarize_by_class(dataset):
"""
将数据集根据类别分割,然后分别计算统计量
@dataset: 数据
"""
separated = separate_by_class(dataset)
summaries = dict()
for class_value, rows in separated.items():
summaries[class_value] = summarize_dataset(rows)
return summaries
def calculate_probability(x, mean, stdev):
"""
根据统计量计算某一个特征的正态分布概率分布函数
@x: 特征数据
@mean: 均值
@stdev: 标准差
"""
exponent = exp(-((x-mean)**2 / (2 * stdev**2 )))
return (1 / (sqrt(2 * pi) * stdev)) * exponent
def calculate_class_probabilities(summaries, row):
"""
根据后验概率来计算先验概率
@summaries: 统计量
@row: 一行数据
"""
total_rows = sum([summaries[label][0][2] for label in summaries])
probabilities = dict()
for class_value, class_summaries in summaries.items():
probabilities[class_value] = summaries[class_value][0][2]/float(total_rows)
for i in range(len(class_summaries)):
mean, stdev, _ = class_summaries[i]
probabilities[class_value] *= calculate_probability(row[i], mean, stdev)
return probabilities
def predict(summaries, row):
"""
预测
@summaries: 统计量
@row: 一行数据
"""
probabilities = calculate_class_probabilities(summaries, row)
best_label, best_prob = None, -1
for class_value, probability in probabilities.items():
if best_label is None or probability > best_prob:
best_prob = probability
best_label = class_value
return best_label
def naive_bayes(train, test):
"""
朴素贝叶斯分类器
@train: 训练集
@test: 测试集
"""
summarize = summarize_by_class(train)
predictions = list()
for row in test:
output = predict(summarize, row)
predictions.append(output)
return(predictions)
使用鸢尾花数据集检验
以上便实现了朴素贝叶斯分类器,接下来我们使用鸢尾花数据集进行校验。
seed(1)
filename = 'iris.csv'
dataset = pd.read_csv(filename).values
str_column_to_int(dataset, len(dataset[0])-1)
n_folds = 10
scores = evaluate_algorithm(dataset, naive_bayes, n_folds)
print('某个折上的准确率: %s' % scores)
print('算法的平均准确率: %.3f%%' % (sum(scores)/float(len(scores))))
结果为:
{'Iris-versicolor': 0, 'Iris-setosa': 1, 'Iris-virginica': 2}
某个折上的准确率: [86.66666666666667, 100.0, 93.33333333333333, 100.0, 100.0, 100.0, 100.0, 86.66666666666667, 86.66666666666667, 100.0]
算法的平均准确率: 95.333%
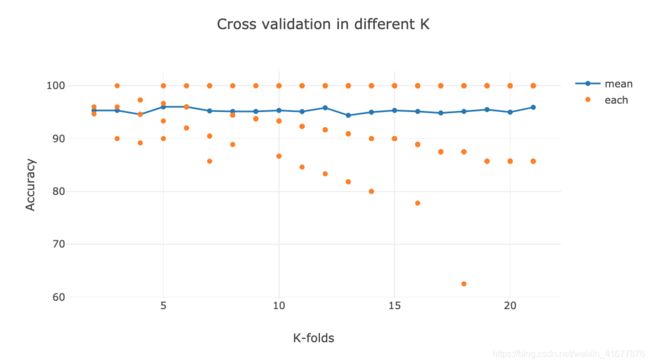
在不同的fold数下的结果:
scores, index, acc = [], [], []
for i in range(2, 22):
score = evaluate_algorithm(dataset, naive_bayes, i)
scores.append(list(score))
acc.append(sum(score)/float(len(score)))
index.append([i for j in range(i)])
fig = go.Figure(layout_title_text="Cross validation in different K")
fig.add_trace(go.Scatter(x=[i + 2 for i in range(20)], y=acc,
mode='lines+markers',
name='mean'))
fig.add_trace(go.Scatter(x=sum(index, []), y=sum(scores, []),
mode='markers',
name='each'))
fig.update_layout(template='none',
xaxis_title="K-folds",
yaxis_title="Accuracy",)
fig.show()