VGG16识别MNIST数据集(Pytorch实战)
文章目录
- 1.导入相关库
- 2.获取数据集
-
- 数据集简单介绍
- 3.创建VGG16模型
-
- 简单查看一下网络结构
- 4.开启训练
-
- 训练结果
- 训练损失和测试损失关系图
- 训练精度和测试精度关系图
- 5.测试阶段
- 6.查看效果图
1.导入相关库
import time
import os
import numpy as np
import torch
import torch.nn.functional as F
import torch.nn as nn
from torch.utils.data import Dataset
from torch.utils.data import DataLoader
from torchvision import transforms
from PIL import Image
import matplotlib.pyplot as plt
DEVICE = torch.device("cuda" if torch.cuda.is_available() else "cpu")
2.获取数据集
数据集简单介绍
MNIST包含70,000张手写数字图像: 60,000张用于培训,10,000张用于测试。图像是灰度的,28x28像素的,并且居中的,以减少预处理和加快运行。
为了方便,直接下载已经做好的数据集。原先mnist数据集为[1,28,28],这里对其修改尺寸,修改之后的[1,64,64]。
Batch_size = 64
custom_transform1 = transforms.Compose([transforms.Resize([64, 64]),
transforms.ToTensor()])
train_dataset = torchvision.datasets.MNIST(
root='./MNIST',
train=True,
download=True,
transform=custom_transform1
)
test_dataset = torchvision.datasets.MNIST(
root='./MNISt',
train=False,
download=True,
transform=custom_transform1
)
# define train loader
train_loader = Data.DataLoader(
dataset=train_dataset,
shuffle=True,
batch_size=Batch_size
)
test_loader = Data.DataLoader(
dataset=test_dataset,
shuffle=True,
batch_size=Batch_size
)
3.创建VGG16模型
class VGG16(torch.nn.Module):
def __init__(self, num_classes):
super(VGG16, self).__init__()
# calculate same padding:
# (w - k + 2*p)/s + 1 = o
# => p = (s(o-1) - w + k)/2
self.block_1 = nn.Sequential(
nn.Conv2d(in_channels=1,
out_channels=64,
kernel_size=(3, 3),
stride=(1, 1),
# (1(32-1)- 32 + 3)/2 = 1
padding=1),
nn.ReLU(),
nn.Conv2d(in_channels=64,
out_channels=64,
kernel_size=(3, 3),
stride=(1, 1),
padding=1),
nn.ReLU(),
nn.MaxPool2d(kernel_size=(2, 2),
stride=(2, 2))
)
self.block_2 = nn.Sequential(
nn.Conv2d(in_channels=64,
out_channels=128,
kernel_size=(3, 3),
stride=(1, 1),
padding=1),
nn.ReLU(),
nn.Conv2d(in_channels=128,
out_channels=128,
kernel_size=(3, 3),
stride=(1, 1),
padding=1),
nn.ReLU(),
nn.MaxPool2d(kernel_size=(2, 2),
stride=(2, 2))
)
self.block_3 = nn.Sequential(
nn.Conv2d(in_channels=128,
out_channels=256,
kernel_size=(3, 3),
stride=(1, 1),
padding=1),
nn.ReLU(),
nn.Conv2d(in_channels=256,
out_channels=256,
kernel_size=(3, 3),
stride=(1, 1),
padding=1),
nn.ReLU(),
nn.Conv2d(in_channels=256,
out_channels=256,
kernel_size=(3, 3),
stride=(1, 1),
padding=1),
nn.ReLU(),
nn.Conv2d(in_channels=256,
out_channels=256,
kernel_size=(3, 3),
stride=(1, 1),
padding=1),
nn.ReLU(),
nn.MaxPool2d(kernel_size=(2, 2),
stride=(2, 2))
)
self.block_4 = nn.Sequential(
nn.Conv2d(in_channels=256,
out_channels=512,
kernel_size=(3, 3),
stride=(1, 1),
padding=1),
nn.ReLU(),
nn.Conv2d(in_channels=512,
out_channels=512,
kernel_size=(3, 3),
stride=(1, 1),
padding=1),
nn.ReLU(),
nn.Conv2d(in_channels=512,
out_channels=512,
kernel_size=(3, 3),
stride=(1, 1),
padding=1),
nn.ReLU(),
nn.Conv2d(in_channels=512,
out_channels=512,
kernel_size=(3, 3),
stride=(1, 1),
padding=1),
nn.ReLU(),
nn.MaxPool2d(kernel_size=(2, 2),
stride=(2, 2))
)
self.block_5 = nn.Sequential(
nn.Conv2d(in_channels=512,
out_channels=512,
kernel_size=(3, 3),
stride=(1, 1),
padding=1),
nn.ReLU(),
nn.Conv2d(in_channels=512,
out_channels=512,
kernel_size=(3, 3),
stride=(1, 1),
padding=1),
nn.ReLU(),
nn.Conv2d(in_channels=512,
out_channels=512,
kernel_size=(3, 3),
stride=(1, 1),
padding=1),
nn.ReLU(),
nn.Conv2d(in_channels=512,
out_channels=512,
kernel_size=(3, 3),
stride=(1, 1),
padding=1),
nn.ReLU(),
nn.MaxPool2d(kernel_size=(2, 2),
stride=(2, 2))
)
self.classifier = nn.Sequential(
nn.Linear(512*2*2, 4096),
nn.ReLU(),
nn.Linear(4096, 4096),
nn.ReLU(),
nn.Linear(4096, num_classes)
)
for m in self.modules():
if isinstance(m, torch.nn.Conv2d):
#n = m.kernel_size[0] * m.kernel_size[1] * m.out_channels
#m.weight.data.normal_(0, np.sqrt(2. / n))
m.weight.detach().normal_(0, 0.05)
if m.bias is not None:
m.bias.detach().zero_()
elif isinstance(m, torch.nn.Linear):
m.weight.detach().normal_(0, 0.05)
m.bias.detach().detach().zero_()
def forward(self, x):
x = self.block_1(x)
x = self.block_2(x)
x = self.block_3(x)
x = self.block_4(x)
x = self.block_5(x)
logits = self.classifier(x.view(-1, 512*2*2))
probas = F.softmax(logits, dim=1)
return logits,probas
因为mnist数据是1通道的。所有这里将模型里面最开始的输入进行相应的修改:3通道改为1通道。或者可以将mnist数据改为3通道也是可以的。
简单查看一下网络结构
net = VGG16(10)
print(net)
print(net(torch.randn([1,1,64,64])))
VGG16(
(block_1): Sequential(
(0): Conv2d(1, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(1): ReLU()
(2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(3): ReLU()
(4): MaxPool2d(kernel_size=(2, 2), stride=(2, 2), padding=0, dilation=1, ceil_mode=False)
)
(block_2): Sequential(
(0): Conv2d(64, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(1): ReLU()
(2): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(3): ReLU()
(4): MaxPool2d(kernel_size=(2, 2), stride=(2, 2), padding=0, dilation=1, ceil_mode=False)
)
(block_3): Sequential(
(0): Conv2d(128, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(1): ReLU()
(2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(3): ReLU()
(4): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(5): ReLU()
(6): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(7): ReLU()
(8): MaxPool2d(kernel_size=(2, 2), stride=(2, 2), padding=0, dilation=1, ceil_mode=False)
)
(block_4): Sequential(
(0): Conv2d(256, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(1): ReLU()
(2): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(3): ReLU()
(4): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(5): ReLU()
(6): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(7): ReLU()
(8): MaxPool2d(kernel_size=(2, 2), stride=(2, 2), padding=0, dilation=1, ceil_mode=False)
)
(block_5): Sequential(
(0): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(1): ReLU()
(2): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(3): ReLU()
(4): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(5): ReLU()
(6): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(7): ReLU()
(8): MaxPool2d(kernel_size=(2, 2), stride=(2, 2), padding=0, dilation=1, ceil_mode=False)
)
(classifier): Sequential(
(0): Linear(in_features=2048, out_features=4096, bias=True)
(1): ReLU()
(2): Linear(in_features=4096, out_features=4096, bias=True)
(3): ReLU()
(4): Linear(in_features=4096, out_features=10, bias=True)
)
)
(tensor([[11053.0107, -1402.9390, 858.1477, 2369.4268, -4733.3818, -7400.0156,
-8052.2051, -6403.5723, -7135.7681, -7110.0879]],
grad_fn=<AddmmBackward>), tensor([[1., 0., 0., 0., 0., 0., 0., 0., 0., 0.]], grad_fn=<SoftmaxBackward>))
原先这里选用SGD训练,但是效果很差,换成Adam优化就好了
NUM_EPOCHS = 6
model = VGG16(num_classes=10)
model = model.to(DEVICE)
#原先这里选用SGD训练,但是效果很差,换成Adam优化就好了
optimizer = torch.optim.Adam(model.parameters(), lr=0.001)
4.开启训练
valid_loader = test_loader
def compute_accuracy_and_loss(model, data_loader, device):
correct_pred, num_examples = 0, 0
cross_entropy = 0.
for i, (features, targets) in enumerate(data_loader):
features = features.to(device)
targets = targets.to(device)
logits, probas = model(features)
cross_entropy += F.cross_entropy(logits, targets).item()
_, predicted_labels = torch.max(probas, 1)
num_examples += targets.size(0)
correct_pred += (predicted_labels == targets).sum()
return correct_pred.float()/num_examples * 100, cross_entropy/num_examples
start_time = time.time()
train_acc_lst, valid_acc_lst = [], []
train_loss_lst, valid_loss_lst = [], []
for epoch in range(NUM_EPOCHS):
model.train()
for batch_idx, (features, targets) in enumerate(train_loader):
### PREPARE MINIBATCH
features = features.to(DEVICE)
targets = targets.to(DEVICE)
### FORWARD AND BACK PROP
logits, probas = model(features)
cost = F.cross_entropy(logits, targets)
optimizer.zero_grad()
cost.backward()
### UPDATE MODEL PARAMETERS
optimizer.step()
### LOGGING
if not batch_idx % 120:
print (f'Epoch: {epoch+1:03d}/{NUM_EPOCHS:03d} | '
f'Batch {batch_idx:03d}/{len(train_loader):03d} |'
f' Cost: {cost:.4f}')
# no need to build the computation graph for backprop when computing accuracy
model.eval()
with torch.set_grad_enabled(False):
train_acc, train_loss = compute_accuracy_and_loss(model, train_loader, device=DEVICE)
valid_acc, valid_loss = compute_accuracy_and_loss(model, valid_loader, device=DEVICE)
train_acc_lst.append(train_acc)
valid_acc_lst.append(valid_acc)
train_loss_lst.append(train_loss)
valid_loss_lst.append(valid_loss)
print(f'Epoch: {epoch+1:03d}/{NUM_EPOCHS:03d} Train Acc.: {train_acc:.2f}%'
f' | Validation Acc.: {valid_acc:.2f}%')
elapsed = (time.time() - start_time)/60
print(f'Time elapsed: {elapsed:.2f} min')
elapsed = (time.time() - start_time)/60
print(f'Total Training Time: {elapsed:.2f} min')
由于GPU资源有限,稍微意思了一下。。。
训练结果
Epoch: 001/006 | Batch 000/938 | Cost: 6423.1440
Epoch: 001/006 | Batch 120/938 | Cost: 0.2032
Epoch: 001/006 | Batch 240/938 | Cost: 0.1645
Epoch: 001/006 | Batch 360/938 | Cost: 0.2633
Epoch: 001/006 | Batch 480/938 | Cost: 0.0435
Epoch: 001/006 | Batch 600/938 | Cost: 0.1830
Epoch: 001/006 | Batch 720/938 | Cost: 0.0199
Epoch: 001/006 | Batch 840/938 | Cost: 0.3196
Epoch: 001/006 Train Acc.: 96.06% | Validation Acc.: 96.22%
Time elapsed: 1.74 min
Epoch: 002/006 | Batch 000/938 | Cost: 0.1152
Epoch: 002/006 | Batch 120/938 | Cost: 0.0301
Epoch: 002/006 | Batch 240/938 | Cost: 0.0871
Epoch: 002/006 | Batch 360/938 | Cost: 0.0694
Epoch: 002/006 | Batch 480/938 | Cost: 0.2224
Epoch: 002/006 | Batch 600/938 | Cost: 0.0476
Epoch: 002/006 | Batch 720/938 | Cost: 0.0289
Epoch: 002/006 | Batch 840/938 | Cost: 0.0069
Epoch: 002/006 Train Acc.: 97.30% | Validation Acc.: 97.44%
Time elapsed: 3.48 min
Epoch: 003/006 | Batch 000/938 | Cost: 0.0963
Epoch: 003/006 | Batch 120/938 | Cost: 0.0753
Epoch: 003/006 | Batch 240/938 | Cost: 0.0183
Epoch: 003/006 | Batch 360/938 | Cost: 0.0921
Epoch: 003/006 | Batch 480/938 | Cost: 0.0316
Epoch: 003/006 | Batch 600/938 | Cost: 0.0291
Epoch: 003/006 | Batch 720/938 | Cost: 0.0726
Epoch: 003/006 | Batch 840/938 | Cost: 0.0138
Epoch: 003/006 Train Acc.: 97.65% | Validation Acc.: 97.51%
Time elapsed: 5.22 min
Epoch: 004/006 | Batch 000/938 | Cost: 0.1318
Epoch: 004/006 | Batch 120/938 | Cost: 0.1341
Epoch: 004/006 | Batch 240/938 | Cost: 0.0067
Epoch: 004/006 | Batch 360/938 | Cost: 0.0009
Epoch: 004/006 | Batch 480/938 | Cost: 0.0164
Epoch: 004/006 | Batch 600/938 | Cost: 0.0025
Epoch: 004/006 | Batch 720/938 | Cost: 0.0049
Epoch: 004/006 | Batch 840/938 | Cost: 0.0191
Epoch: 004/006 Train Acc.: 98.42% | Validation Acc.: 98.14%
Time elapsed: 6.97 min
Epoch: 005/006 | Batch 000/938 | Cost: 0.0046
Epoch: 005/006 | Batch 120/938 | Cost: 0.0064
Epoch: 005/006 | Batch 240/938 | Cost: 0.0507
Epoch: 005/006 | Batch 360/938 | Cost: 0.1420
Epoch: 005/006 | Batch 480/938 | Cost: 0.0056
Epoch: 005/006 | Batch 600/938 | Cost: 0.0630
Epoch: 005/006 | Batch 720/938 | Cost: 0.0924
Epoch: 005/006 | Batch 840/938 | Cost: 0.0584
Epoch: 005/006 Train Acc.: 98.30% | Validation Acc.: 97.94%
Time elapsed: 8.71 min
Epoch: 006/006 | Batch 000/938 | Cost: 0.0997
Epoch: 006/006 | Batch 120/938 | Cost: 0.0192
Epoch: 006/006 | Batch 240/938 | Cost: 0.1529
Epoch: 006/006 | Batch 360/938 | Cost: 0.0133
Epoch: 006/006 | Batch 480/938 | Cost: 0.0196
Epoch: 006/006 | Batch 600/938 | Cost: 0.0559
Epoch: 006/006 | Batch 720/938 | Cost: 0.0380
Epoch: 006/006 | Batch 840/938 | Cost: 0.0143
Epoch: 006/006 Train Acc.: 98.54% | Validation Acc.: 98.32%
Time elapsed: 10.45 min
Total Training Time: 10.45 min
训练损失和测试损失关系图
推荐学习:https://blog.csdn.net/w372845589/article/details/84303498
plt.plot(range(1, NUM_EPOCHS+1), train_loss_lst, label='Training loss')
plt.plot(range(1, NUM_EPOCHS+1), valid_loss_lst, label='Validation loss')
plt.legend(loc='upper right')
plt.ylabel('Cross entropy')
plt.xlabel('Epoch')
plt.show()

训练精度和测试精度关系图
plt.plot(range(1, NUM_EPOCHS+1), train_acc_lst, label='Training accuracy')
plt.plot(range(1, NUM_EPOCHS+1), valid_acc_lst, label='Validation accuracy')
plt.legend(loc='upper left')
plt.ylabel('Cross entropy')
plt.xlabel('Epoch')
plt.show()

5.测试阶段
model.eval()
with torch.set_grad_enabled(False): # save memory during inference
test_acc, test_loss = compute_accuracy_and_loss(model, test_loader, DEVICE)
print(f'Test accuracy: {test_acc:.2f}%')
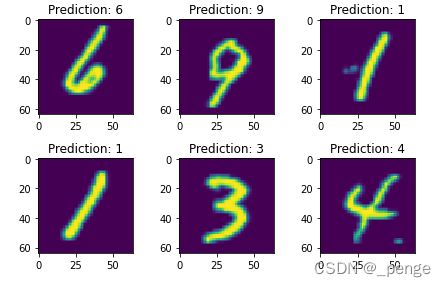
6.查看效果图
test_loader = DataLoader(dataset=train_dataset,
batch_size=64,
shuffle=True)
for features, targets in test_loader:
break
_, predictions = model.forward(features[:8].to(DEVICE))
predictions = torch.argmax(predictions, dim=1)
print(features.size())
fig = plt.figure()
for i in range(6):
plt.subplot(2,3,i+1)
plt.tight_layout()
plt.imshow(features[i][0],interpolation='none')
plt.title("Prediction: {}".format(predictions[i]))
plt.show()
另外,又提供了类似的VGG16模型用于二分类问题。
class VGG16(torch.nn.Module):
def __init__(self, num_classes):
super(VGG16, self).__init__()
# calculate same padding:
# (w - k + 2*p)/s + 1 = o
# => p = (s(o-1) - w + k)/2
self.block_1 = nn.Sequential(
nn.Conv2d(in_channels=1,
out_channels=64,
kernel_size=(3, 3),
stride=(1, 1),
# (1(32-1)- 32 + 3)/2 = 1
padding=1),
nn.BatchNorm2d(num_features=64),
nn.ReLU(),
nn.Conv2d(in_channels=64,
out_channels=64,
kernel_size=(3, 3),
stride=(1, 1),
padding=1),
nn.BatchNorm2d(num_features=64),
nn.ReLU(),
nn.MaxPool2d(kernel_size=(2, 2),
stride=(2, 2))
)
self.block_2 = nn.Sequential(
nn.Conv2d(in_channels=64,
out_channels=128,
kernel_size=(3, 3),
stride=(1, 1),
padding=1),
nn.BatchNorm2d(num_features=128),
nn.ReLU(),
nn.Conv2d(in_channels=128,
out_channels=128,
kernel_size=(3, 3),
stride=(1, 1),
padding=1),
nn.BatchNorm2d(num_features=128),
nn.ReLU(),
nn.MaxPool2d(kernel_size=(2, 2),
stride=(2, 2))
)
self.block_3 = nn.Sequential(
nn.Conv2d(in_channels=128,
out_channels=256,
kernel_size=(3, 3),
stride=(1, 1),
padding=1),
nn.BatchNorm2d(num_features=256),
nn.ReLU(),
nn.Conv2d(in_channels=256,
out_channels=256,
kernel_size=(3, 3),
stride=(1, 1),
padding=1),
nn.BatchNorm2d(num_features=256),
nn.ReLU(),
nn.Conv2d(in_channels=256,
out_channels=256,
kernel_size=(3, 3),
stride=(1, 1),
padding=1),
nn.BatchNorm2d(num_features=256),
nn.ReLU(),
nn.Conv2d(in_channels=256,
out_channels=256,
kernel_size=(3, 3),
stride=(1, 1),
padding=1),
nn.BatchNorm2d(num_features=256),
nn.ReLU(),
nn.MaxPool2d(kernel_size=(2, 2),
stride=(2, 2))
)
self.block_4 = nn.Sequential(
nn.Conv2d(in_channels=256,
out_channels=512,
kernel_size=(3, 3),
stride=(1, 1),
padding=1),
nn.BatchNorm2d(num_features=512),
nn.ReLU(),
nn.Conv2d(in_channels=512,
out_channels=512,
kernel_size=(3, 3),
stride=(1, 1),
padding=1),
nn.BatchNorm2d(num_features=512),
nn.ReLU(),
nn.Conv2d(in_channels=512,
out_channels=512,
kernel_size=(3, 3),
stride=(1, 1),
padding=1),
nn.BatchNorm2d(num_features=512),
nn.ReLU(),
nn.Conv2d(in_channels=512,
out_channels=512,
kernel_size=(3, 3),
stride=(1, 1),
padding=1),
nn.BatchNorm2d(num_features=512),
nn.ReLU(),
nn.MaxPool2d(kernel_size=(2, 2),
stride=(2, 2))
)
self.block_5 = nn.Sequential(
nn.Conv2d(in_channels=512,
out_channels=512,
kernel_size=(3, 3),
stride=(1, 1),
padding=1),
nn.BatchNorm2d(num_features=512),
nn.ReLU(),
nn.Conv2d(in_channels=512,
out_channels=512,
kernel_size=(3, 3),
stride=(1, 1),
padding=1),
#归一化处理,这使得数据在进行Relu之前不会因为数据过大而导致网络性能的不稳定
nn.BatchNorm2d(num_features=512),
nn.ReLU(),
nn.Conv2d(in_channels=512,
out_channels=512,
kernel_size=(3, 3),
stride=(1, 1),
padding=1),
nn.BatchNorm2d(num_features=512),
nn.ReLU(),
nn.Conv2d(in_channels=512,
out_channels=512,
kernel_size=(3, 3),
stride=(1, 1),
padding=1),
nn.BatchNorm2d(num_features=512),
nn.ReLU(),
nn.MaxPool2d(kernel_size=(2, 2),
stride=(2, 2))
)
self.classifier = nn.Sequential(
nn.Linear(512*2*2, 4096),
nn.ReLU(),
#加Relu后面加上dropout函数,防止过拟合
nn.Dropout(0.5),
nn.Linear(4096, 4096),
nn.ReLU(),
nn.Dropout(0.5),
nn.Linear(4096, num_classes)
)
def forward(self, x):
x = self.block_1(x)
x = self.block_2(x)
x = self.block_3(x)
x = self.block_4(x)
x = self.block_5(x)
logits = self.classifier(x.view(-1, 512*2*2))
probas = F.softmax(logits, dim=1)
return logits,probas
改动点
1.