解开机器学习模型黑盒的 4 种方法(终极指南)
这是解释机器学习模型输出的终极指南

更多机器学习系列请看:芯媒机器学习系列文章和资料
许多人都认为机器学习模型的输出是莫名其妙的,模型预测或决策可能是可靠的,但你无法知道模型是根据什么做出的决策。
这对于调试、为未来的数据工程提供信息、更好地指导未来的数据收集、为人类决策提供信息以及建立与业务利益相关者和非技术背景人员沟通的信任很有价值。
1.调试
调试是数据科学中最有价值的技能之一。了解模型发现的模式将有助于确定您对现实世界了解的可能性,这通常是追踪错误的第一步。错误的来源可能是不可靠的、杂乱无章的数据,并且通常是脏数据。除此之外,潜在的噪声是由数据预处理步骤引起的。
2.通知特征工程
特征工程是提高模型性能的最有效方法之一。特征工程涉及特征转换,创建原始特征的新特征。了解模型的工作方式可以更好地改进特征工程,从而提高模型性能。
3.指导未来的数据收集
基于模型的洞察力使您能够很好地了解您当前拥有的功能的价值,这将帮助您推断哪些新价值可能最有帮助。这可以帮助指导未来的数据收集,以提高模型性能。
4.为人类决策提供信息
一些决策是由模型自动做出的。然而,许多重要的决定都是由人类做出的。这些决定、洞察力可能比预测更有价值。
5.建立信任
许多人不会认为他们可以在不验证一些基本事实的情况下信任您的模型来做出重要决策。考虑到数据错误的频率,这是一个明智的预防措施。在实践中,展示符合他们对问题的一般理解的见解将有助于建立信任,即使在对数据科学知之甚少的人或没有技术背景的人之间也是如此。

在本文中,介绍了四种机器学习可扩展性的方法。这些方法是排列重要性、部分图、SHAP 值和 LIME 值。我们将使用汽车数据集来解释这些方法。
数据加载和预处理可以在这个notebook中找到。为简短起见,此处不再赘述。
数据的连续数值特征为:
-
长度
-
宽度
-
整备重量
-
引擎尺寸
-
马力
-
城市-mpg
-
高速公路-mpg
-
轴距
-
孔
分类变量:
-
驱动轮
1
排列重要性
排列重要性试图回答这个重要问题:哪些特征对预测的影响最大?
排列重要性是回答这个问题的首选方法,因为它是:
-
快速计算
-
广泛使用和理解
排列重要性如下:如果我随机打乱数据的单个列,将目标和所有其他列留在原处,这将如何影响现在打乱的数据中预测的准确性?排列重要性是在模型拟合后计算的。因此,我们不会更改模型或更改对于给定的发动机尺寸、马力等值我们会得到的预测。
随机重新排序单个列会导致预测不准确,因为结果数据不再对应于现实世界中观察到的任何内容。如果我们对模型严重依赖于预测的列进行洗牌,模型准确性尤其会受到影响。
总结一下过程:
-
获得训练有素的模型。
-
将单个列中的值打乱,使用结果数据集进行预测。使用这些预测和真实的目标值来计算损失函数遭受洗牌的程度。性能恶化衡量了您刚刚洗牌的变量的重要性。
-
将数据返回到原始顺序(撤消步骤 2 中的随机播放)。现在对数据集中的下一列重复步骤 2,直到计算出每一列的重要性。
将其应用于我们上面提到的汽车数据。我们将使用线性回归模型来预测汽车的价格。下面的代码用于从数据中提取重要特征和 one-hot 编码,然后拟合模型并将置换重要函数应用于拟合模型。
首先,导入置换重要性函数
然后提取特征并训练线性回归模型
应用排列重要性函数,置换重要性函数的输出:

排列重要性输出
朝向顶部的值是最重要的特征,朝向底部的值最不重要。每行中的第一个数字显示了使用“准确性”作为性能指标的随机洗牌降低了多少模型性能。±后面的数字衡量性能如何从一次改组到下一次改组。
您可以看到置换重要性有负值。在这些情况下,对混洗(或嘈杂)数据的预测恰好比真实数据更准确。当特征无关紧要时会发生这种情况(应该具有接近 0 的重要性),但随机机会导致对打乱数据的预测更加准确。这对于小型数据集更为常见,例如本例中的数据集,因为有更多的运气/机会空间。
在我们的示例中,最重要的特征是发动机尺寸,然后是马力。这是相当合理的,因为汽车的价格主要取决于它们。
2
部分依赖图
部分依赖图 (PDP) 显示特征如何影响预测。因此,例如控制所有其他汽车功能,发动机尺寸对预测的汽车价格有什么影响。直观地说,我们可以将部分依赖解释为作为感兴趣输入特征的函数的预期目标响应。
我们将使用拟合模型来预测我们的结果,在我们的例子中是汽车价格。但是我们会反复改变一个变量的值来做出一系列预测。我们将把它应用到汽车发动机尺寸特征上。我们可以预测汽车的发动机尺寸只有 100 的结果。然后我们预测他们的发动机尺寸为 150。然后再次预测 160。依此类推。当我们从控球的小值转移到大的值(在水平轴上)时,我们追踪预测的结果(在垂直轴上)。
PDP 的代码如下所示,代码的输出如下所示:
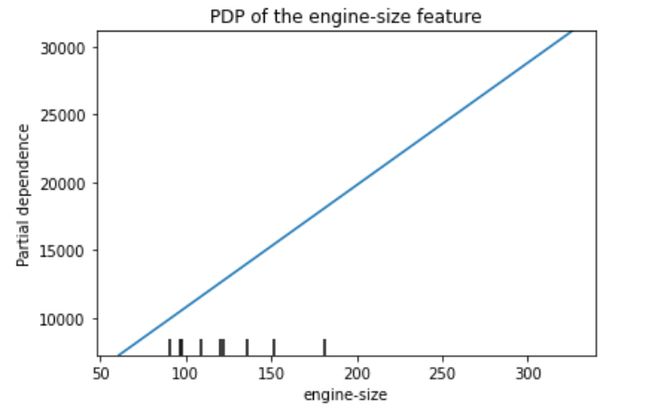
PDP 用于引擎大小的功能
从图中可以看出,发动机尺寸特征与预测汽车价格之间的关系是线性的。这也与排列重要性的发现相吻合。最重要的特征也是发动机尺寸。
3
SHAP 价值观
虽然系数可以很好地告诉我们当我们改变输入特征的值时会发生什么,但它们本身并不是衡量特征整体重要性的好方法。这是因为每个系数的值取决于输入特征的规模。SHAP 值(来自 SHapley Additive exPlanations 的首字母缩写词)分解预测以显示每个特征的影响。
你可以在哪里使用这个?
-
一个模型说银行不应该借钱给别人,法律要求银行解释每次贷款拒绝的依据。
-
医疗保健提供者希望确定哪些因素导致每位患者患某种疾病的风险,以便他们可以通过有针对性的健康干预直接解决这些风险因素。
SHAP 值解释了给定特征具有特定值的影响,与我们所做的预测相比,如果该特征采用一些基线值。
要将其绘制为单行,我们可以使用以下代码,其输出如下图所示:
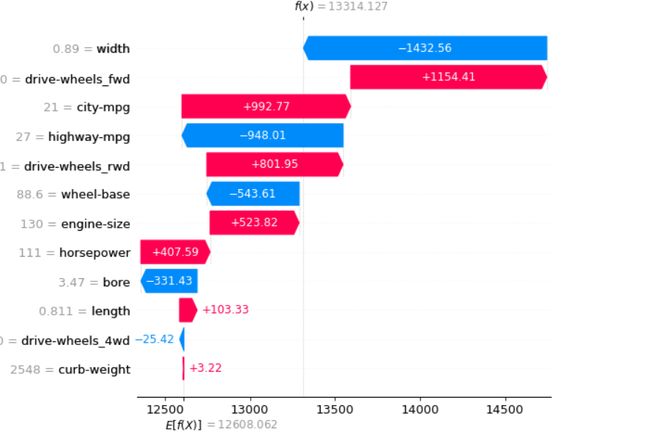
这些是第二行的 SHAP 值图。第一条垂直线是所有特征取平均值时的预测目标值(在我们的示例中为汽车价格)。此值为 12608.062,而第二条垂直线是实际特征值的预测目标值。在这种情况下是 13314.127。
它们之间的差异是由于特征值从平均值到实际值的变化。箭头的颜色(红色和蓝色)显示了特征值变化的效果。红色会增加预测的目标值,而蓝色会减少它。箭头的长度显示了它会产生多大的影响。箭头越长,该特征对预测目标值的影响就越大。
为了能够更清楚地解释它,首先,我们应该看一下每个特征的平均值。

每个特征的平均值。
让我们看一下引擎尺寸特征,以更好地了解 SHAP 值。发动机尺寸特征的平均值为 126.87,对于数据样本,我们绘制的 SHAP 值为 130。这种差异使汽车的价格增加了 523.82。这可以应用于其他功能。
SHAP 总结图为我们提供了特征重要性及其驱动因素的鸟瞰图。我们将介绍汽车数据的示例图。下面的代码用于 SHAP 总结图
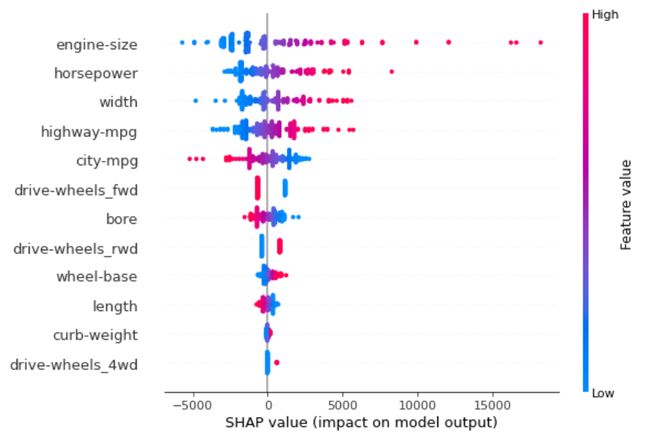
SHAP 总结图
与仅针对一个数据样本(行)绘制的 SHAP 值图相比,SHAP 汇总图适用于所有数据集。该图由许多点组成。每个点具有三个特征:
-
垂直位置显示它所描绘的特征
-
颜色显示该特征对于数据集的该行是高还是低。
-
水平位置显示该值的影响是否导致更高或更低的预测。
例如,引擎大小特征是最重要的特征,我们已经从计算的排列重要性中知道了这一点。除此之外,随着发动机尺寸的增加,它会增加汽车的价格,而随着它的减小,汽车的价值就会下降。这也与 PDP 的调查结果一致,其中汽车价格与发动机尺寸之间的关系是线性的。整备质量和drive-wheels_4wd功能似乎不会影响价格,因为大多数点都为零,除了 drive-wheels_4wd 的非常高的值,它对汽车价格的影响很小。
最后注意计算 SHAP 值可能很慢。这不是问题,因为这个数据集很小。但是在运行这些以使用合理大小的数据集进行绘图时,您需要小心。例外情况是使用XGBoost 模型时,SHAP 对其进行了一些优化,因此速度更快。
4
LIME 价值观
LIME(Local Interpretable Model-Agnostic Explanations)与模型无关,这意味着它可以应用于任何机器学习模型。该技术试图通过扰乱数据样本的输入并理解预测如何变化来理解模型。
LIME 提供本地模型可解释性。它通过调整特征值来修改单个数据样本,并观察由此产生的对输出的影响。通常,这也与人类在观察模型输出时感兴趣的内容有关。最常见的问题可能是:为什么做出这个预测或哪些变量导致了预测?
LIME 是在Marco Tulio Ribeiro、Sameer Singh、Carlos Guestrin于 2016 年 8 月发表的论文“我为什么要相信你?”:解释任何分类器的预测中提出的。它有一个适用于 Python 和 R 的库。
LIME 不关心您(现在或将来)使用的 ML 模型。它将把它当作一个黑匣子,并专注于解释本地结果。
它是如何工作的?
-
首先 LIME 获取一个数据样本并基于它创建一个假数据集。然后对假数据集进行置换。
-
计算伪造的生成数据和原始数据集之间的距离(或相似性度量)。这将使我们知道假生成的数据集与原始数据集的相似程度。Python中的lime库为我们提供了不同的相似函数。
-
然后,它使用适合原始数据的模型对置换后的假数据集进行预测。
-
然后它选择最能描述我们的模型在置换假数据上的性能的特征。石灰库让我们提供了多少功能可供选择。
-
然后,它训练一个简单的模型(如线性或逻辑回归),将置换的假数据与前面步骤中计算的选定 m 个特征相结合。石灰库让我们提供了一个我们想要使用的简单模型。
-
然后,它使用从每个特征的简单模型派生的权重来解释在使用原始复杂模型进行预测时,每个特征如何有助于对该样本进行预测。
lime_tabular模块有一个名为 LimeTabularExplainer 的类,它将作为输入的火车数据和生成的解释器对象,然后可以用来解释单个预测。
要使用lime_tabular,我们应该使用下面的代码下载lime包
之后,我们将使用以下代码创建石灰表格解释器:
要创建 LIME 图,我们将使用以下代码:
其输出如下图所示:

下面我们调用了该as_pyplot_figure()方法来生成该样本的特征贡献条形图。

我们可以看到,它从为第二个数据样本计算的 SHAP 值中给出了类似的结果。其中汽车的宽度对预测的影响最大。
LIME 是解释机器学习分类器(或模型)在做什么的好工具。它与模型无关,利用简单易懂的想法,运行起来不需要太多努力。与往常一样,即使使用 LIME,正确解释输出仍然很重要。
谢谢阅读!如果您喜欢它,请务必在LinkedIn上与我联系,并在Medium上关注我,以随时了解我的新文章。本文中使用的所有代码都可以在这个GitHub 呼吸中找到。

参考
[1]https://www.kaggle.com/learn/machine-learning-explainability
[2]https://scikit-learn.org/stable/modules/partial_dependence.html
[3]https://shap.readthedocs.io/en/latest/example_notebooks/overviews/An%20introduction%20to%20explainable%20AI%20with%20Shapley%20values.html#linear_regression
[4]https://towardsdatascience.com/understanding-model-predictions-with-lime-a582fdff3a3b
[5]https://medium.com/analytics-vidhya/model-interpretability-lime-part-2-53c0f5e76b6a
[6]
https://coderzcolumn.com/tutorials/machine-learning/how-to-use-lime-to-understand-sklearn-models-predictions